Strategi umum yang digunakan mesin database SQL Server untuk menjaga tampilan yang diindeks disinkronkan dengan tabel dasarnya – yang saya jelaskan lebih detail di posting terakhir saya – adalah melakukan pemeliharaan tambahan tampilan setiap kali operasi pengubahan data terjadi terhadap salah satu tabel yang dirujuk dalam tampilan. Secara umum, idenya adalah untuk:
- Kumpulkan informasi tentang perubahan tabel dasar
- Terapkan proyeksi, filter, dan gabungan yang ditentukan dalam tampilan
- Menggabungkan perubahan per tampilan terindeks kunci berkerumun
- Tentukan apakah setiap perubahan harus menghasilkan penyisipan, pembaruan, atau penghapusan terhadap tampilan
- Hitung nilai yang akan diubah, ditambahkan, atau dihapus dalam tampilan
- Terapkan perubahan tampilan
Atau, bahkan lebih ringkas (walaupun dengan risiko penyederhanaan kasar):
- Hitung efek tampilan tambahan dari modifikasi data asli;
- Terapkan perubahan tersebut pada tampilan
Ini biasanya merupakan strategi yang jauh lebih efisien daripada membangun kembali seluruh tampilan setelah setiap perubahan data yang mendasarinya (opsi yang aman tetapi lambat), tetapi ini bergantung pada logika pembaruan inkremental yang benar untuk setiap perubahan data yang mungkin, terhadap setiap definisi tampilan terindeks yang mungkin.
Seperti judulnya, artikel ini berkaitan dengan kasus menarik di mana logika pembaruan inkremental rusak, menghasilkan tampilan terindeks yang rusak yang tidak lagi cocok dengan data yang mendasarinya. Sebelum kita membahas bug itu sendiri, kita perlu meninjau agregat skalar dan vektor dengan cepat.
Agregat Skalar dan Vektor
Jika Anda tidak terbiasa dengan istilah tersebut, ada dua jenis agregat. Agregat yang diasosiasikan dengan klausa GROUP BY (walaupun grup menurut daftar kosong) dikenal sebagai agregat vektor . Agregat tanpa klausa GROUP BY dikenal sebagai agregat skalar .
Sedangkan agregat vektor dijamin menghasilkan satu baris keluaran untuk setiap kelompok yang ada dalam kumpulan data, agregat skalar sedikit berbeda. Agregat skalar selalu menghasilkan satu baris keluaran, meskipun set masukan kosong.
Contoh agregat vektor
Contoh AdventureWorks berikut menghitung dua agregat vektor (jumlah dan hitungan) pada set input kosong:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Kueri ini menghasilkan keluaran berikut (tanpa baris):

Hasilnya sama, jika kita mengganti klausa GROUP BY dengan set kosong (membutuhkan SQL Server 2008 atau yang lebih baru):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Rencana eksekusi juga identik dalam kedua kasus. Ini adalah rencana eksekusi untuk kueri penghitungan:
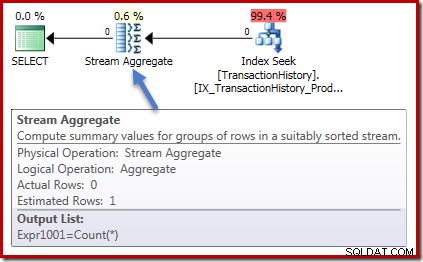
Nol baris masuk ke Stream Aggregate, dan nol baris keluar. Rencana eksekusi jumlah terlihat seperti ini:

Sekali lagi, nol baris ke dalam agregat, dan nol baris keluar. Sejauh ini semua hal sederhana yang bagus.
Agregat skalar
Sekarang lihat apa yang terjadi jika kita menghapus klausa GROUP BY dari kueri sepenuhnya:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Alih-alih hasil kosong, COUNT agregat menghasilkan nol, dan SUM mengembalikan NULL:
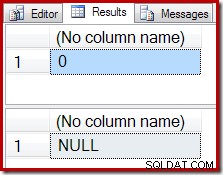
Rencana eksekusi hitungan mengonfirmasi bahwa nol baris input menghasilkan satu baris output dari Stream Aggregate:
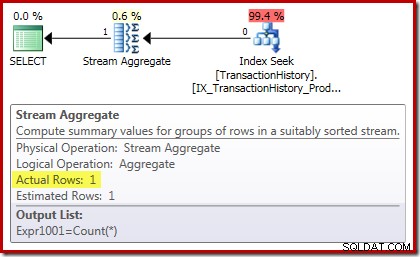
Rencana eksekusi jumlah bahkan lebih menarik:
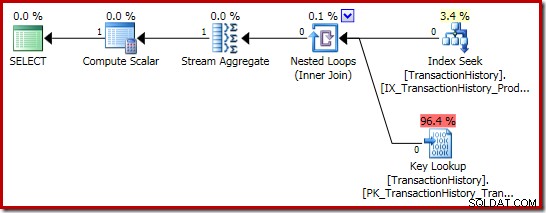
Properti Stream Agregate menunjukkan jumlah agregat yang dihitung selain jumlah yang kami minta:
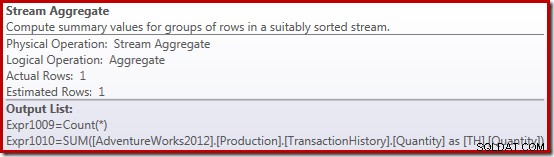
Operator Compute Scalar yang baru digunakan untuk mengembalikan NULL jika jumlah baris yang diterima oleh Stream Aggregate adalah nol, jika tidak maka akan mengembalikan jumlah data yang ditemukan:
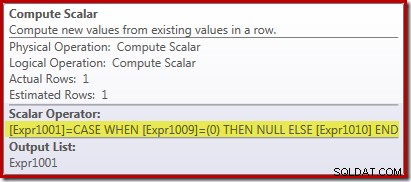
Ini semua mungkin tampak agak aneh, tapi beginilah cara kerjanya:
- Agregat vektor dari nol baris menghasilkan nol baris;
- Agregat skalar selalu menghasilkan tepat satu baris output, bahkan untuk input kosong;
- Jumlah skalar dari nol baris adalah nol; dan
- Jumlah skalar dari baris nol adalah NULL (bukan nol).
Poin penting untuk tujuan kita saat ini adalah bahwa agregat skalar selalu menghasilkan satu baris keluaran, bahkan jika itu berarti membuat satu dari tidak ada. Juga, jumlah skalar dari baris nol adalah NULL, bukan nol.
Omong-omong, semua perilaku ini "benar". Hal-hal seperti itu karena SQL Standard awalnya tidak mendefinisikan perilaku agregat skalar, menyerahkannya pada implementasi. SQL Server mempertahankan implementasi aslinya untuk alasan kompatibilitas mundur. Agregat vektor selalu memiliki perilaku yang terdefinisi dengan baik.
Tampilan Terindeks dan Agregasi Vektor
Sekarang pertimbangkan tampilan terindeks sederhana yang menggabungkan beberapa agregat (vektor):
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Kueri berikut menampilkan konten tabel dasar, hasil kueri tampilan yang diindeks, dan hasil menjalankan kueri tampilan pada tabel yang mendasari tampilan:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Hasilnya adalah:
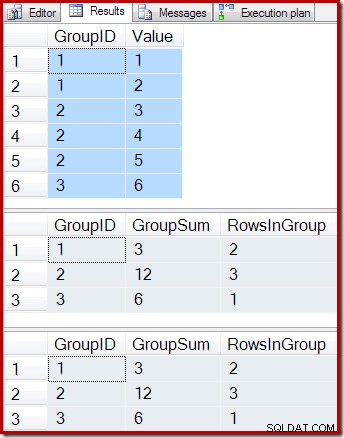
Seperti yang diharapkan, tampilan yang diindeks dan kueri yang mendasarinya mengembalikan hasil yang sama persis. Hasilnya akan terus disinkronkan setelah setiap dan semua kemungkinan perubahan pada tabel dasar T1. Untuk mengingatkan diri kita sendiri bagaimana semua ini bekerja, pertimbangkan kasus sederhana menambahkan satu baris baru ke tabel dasar:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Rencana eksekusi untuk sisipan ini berisi semua logika yang diperlukan untuk menjaga sinkronisasi tampilan yang diindeks:
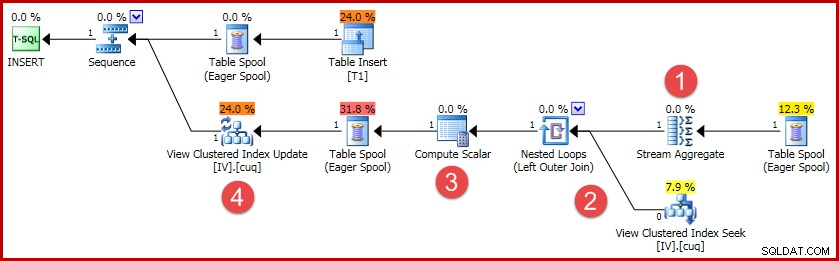
Kegiatan utama dalam rencana tersebut adalah:
- Stream Aggregate menghitung perubahan per kunci tampilan yang diindeks
- Gabungan Luar ke tampilan menautkan ringkasan perubahan ke baris tampilan target, jika ada
- Compute Scalar memutuskan apakah setiap perubahan memerlukan penyisipan, pembaruan, atau penghapusan terhadap tampilan, dan menghitung nilai yang diperlukan.
- Operator pembaruan tampilan secara fisik melakukan setiap perubahan pada indeks pengelompokan tampilan.
Ada beberapa perbedaan rencana untuk operasi perubahan yang berbeda terhadap tabel dasar (misalnya pembaruan dan penghapusan), tetapi gagasan luas di balik menjaga agar tampilan tetap disinkronkan tetap sama:menggabungkan perubahan per kunci tampilan, temukan baris tampilan jika ada, lalu lakukan kombinasi operasi penyisipan, pembaruan, dan penghapusan pada indeks tampilan seperlunya.
Apa pun perubahan yang Anda buat pada tabel dasar dalam contoh ini, tampilan yang diindeks akan tetap disinkronkan dengan benar – kueri NOEXPAND dan EXPAND VIEWS di atas akan selalu mengembalikan kumpulan hasil yang sama. Beginilah seharusnya segala sesuatunya berjalan.
Tampilan Terindeks dan Agregasi Skalar
Sekarang coba contoh ini, di mana tampilan yang diindeks menggunakan agregasi skalar (tidak ada klausa GROUP BY dalam tampilan):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Ini adalah tampilan yang diindeks secara legal; tidak ada kesalahan yang ditemui saat membuatnya. Namun, ada satu petunjuk bahwa kita mungkin melakukan sesuatu yang sedikit aneh:ketika tiba saatnya untuk mewujudkan tampilan dengan membuat indeks berkerumun unik yang diperlukan, tidak ada kolom yang jelas untuk dipilih sebagai kunci. Biasanya, kami akan memilih kolom pengelompokan dari klausa GROUP BY tampilan, tentu saja.
Script di atas secara sewenang-wenang memilih kolom NumRows. Pilihan itu tidak penting. Jangan ragu untuk membuat indeks berkerumun unik apa pun yang Anda pilih. Tampilan akan selalu berisi tepat satu baris karena agregat skalar, jadi tidak ada kemungkinan pelanggaran kunci unik. Dalam hal ini, pilihan kunci indeks tampilan berlebihan, namun tetap diperlukan.
Menggunakan kembali kueri pengujian dari contoh sebelumnya, kita dapat melihat bahwa tampilan yang diindeks berfungsi dengan benar:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
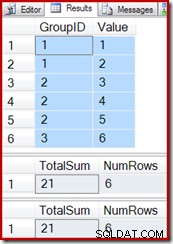
Menyisipkan baris baru ke tabel dasar (seperti yang kita lakukan dengan tampilan pengindeksan agregat vektor) juga terus berfungsi dengan benar:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Rencana eksekusi serupa, tetapi tidak persis sama:
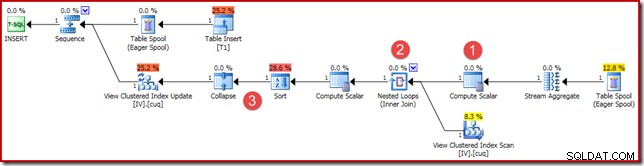
Perbedaan utamanya adalah:
- Skalar Hitung baru ini ada untuk alasan yang sama seperti ketika kita membandingkan hasil agregasi vektor dan skalar sebelumnya:ini memastikan jumlah NULL dikembalikan (bukan nol) jika agregat beroperasi pada himpunan kosong. Ini adalah perilaku yang diperlukan untuk jumlah skalar tanpa baris.
- Gabungan Luar yang terlihat sebelumnya telah digantikan oleh Penggabungan Dalam. Akan selalu ada tepat satu baris dalam tampilan yang diindeks (karena agregasi skalar) sehingga tidak ada pertanyaan tentang perlunya gabungan luar untuk menguji apakah baris tampilan cocok atau tidak. Satu baris yang ada dalam tampilan selalu mewakili seluruh kumpulan data. Inner Join ini tidak memiliki predikat, sehingga secara teknis merupakan cross join (ke tabel dengan satu baris yang dijamin).
- Operator Sortir dan Ciutkan hadir karena alasan teknis yang dibahas dalam artikel saya sebelumnya tentang pemeliharaan tampilan terindeks. Mereka tidak memengaruhi operasi yang benar dari pemeliharaan tampilan terindeks di sini.
Faktanya, banyak jenis operasi pengubahan data yang berbeda dapat dilakukan dengan sukses terhadap tabel dasar T1 dalam contoh ini; efeknya akan tercermin dengan benar dalam tampilan yang diindeks. Operasi perubahan berikut terhadap tabel dasar semuanya dapat dilakukan sambil menjaga tampilan yang diindeks tetap benar:
- Hapus baris yang ada
- Perbarui baris yang ada
- Sisipkan baris baru
Ini mungkin tampak seperti daftar yang lengkap, tetapi sebenarnya tidak.
Bug Terungkap
Masalahnya agak halus, dan berhubungan (seperti yang Anda harapkan) dengan perilaku yang berbeda dari vektor dan agregat skalar. Poin kuncinya adalah bahwa agregat skalar akan selalu menghasilkan baris keluaran, bahkan jika tidak menerima baris pada inputnya, dan jumlah skalar dari himpunan kosong adalah NULL, bukan nol.
Untuk menimbulkan masalah, yang perlu kita lakukan hanyalah menyisipkan atau menghapus baris di tabel dasar.
Pernyataan itu tidak segila kedengarannya pada awalnya.
Intinya adalah bahwa kueri penyisipan atau penghapusan yang tidak memengaruhi baris tabel dasar akan tetap memperbarui tampilan, karena scalar Stream Aggregate di bagian pemeliharaan tampilan terindeks dari rencana kueri akan menghasilkan baris keluaran meskipun disajikan tanpa masukan. Skalar Hitung yang mengikuti Agregat Aliran juga akan menghasilkan jumlah NULL saat jumlah baris adalah nol.
Skrip berikut menunjukkan bug yang sedang beraksi:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Output dari skrip tersebut adalah sebagai berikut:
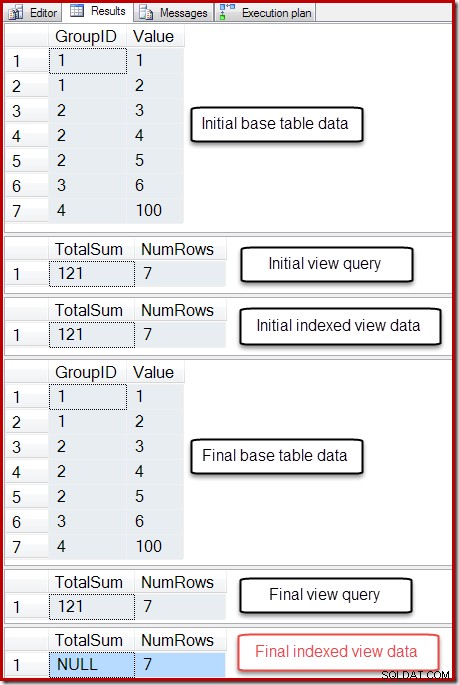
Status akhir kolom Jumlah Total tampilan yang diindeks tidak cocok dengan kueri tampilan yang mendasari atau data tabel dasar. Jumlah NULL telah merusak tampilan, yang dapat dikonfirmasi dengan menjalankan DBCC CHECKTABLE (pada tampilan yang diindeks).
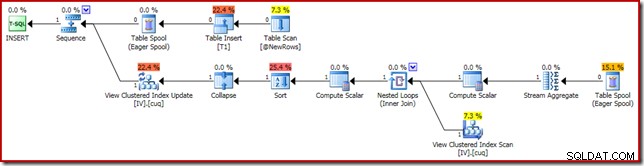
Rencana eksekusi yang bertanggung jawab atas korupsi ditunjukkan di bawah ini:
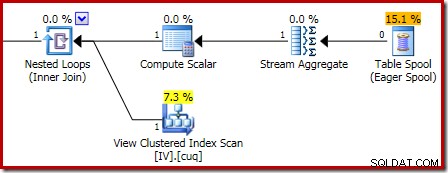
Memperbesar menunjukkan input nol baris ke Stream Aggregate dan output satu baris:
Jika Anda ingin mencoba skrip korupsi di atas dengan menghapus alih-alih menyisipkan, berikut ini contohnya:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Penghapusan tidak memengaruhi baris tabel dasar, tetapi tetap mengubah kolom jumlah tampilan yang diindeks menjadi NULL.
Menggeneralisasi Bug
Anda mungkin dapat membuat sejumlah sisipan, dan menghapus kueri tabel dasar yang tidak memengaruhi baris, dan menyebabkan kerusakan tampilan yang diindeks ini. Namun, masalah dasar yang sama berlaku untuk kelas masalah yang lebih luas daripada sekadar menyisipkan dan menghapus yang tidak memengaruhi baris tabel dasar.
Dimungkinkan, misalnya, untuk menghasilkan korupsi yang sama menggunakan sisipan yang melakukannya menambahkan baris ke tabel dasar. Bahan penting adalah tidak ada baris tambahan yang memenuhi syarat untuk tampilan . Ini akan menghasilkan input kosong ke Stream Aggregate, dan output baris NULL penyebab korupsi dari Compute Scalar berikut.
Salah satu cara untuk mencapainya adalah dengan menyertakan klausa WHERE dalam tampilan yang menolak beberapa baris tabel dasar:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Mengingat pembatasan baru pada ID grup yang disertakan dalam tampilan, sisipan berikut akan menambahkan baris ke tabel dasar, tetapi tampilan yang diindeks masih rusak dengan jumlah NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Outputnya menunjukkan korupsi indeks yang sekarang dikenal:
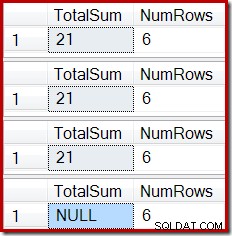
Efek serupa dapat dihasilkan menggunakan tampilan yang berisi satu atau lebih gabungan bagian dalam. Selama baris yang ditambahkan ke tabel dasar ditolak (misalnya dengan gagal bergabung), Agregat Aliran tidak akan menerima baris, Skalar Hitung akan menghasilkan jumlah NULL, dan tampilan yang diindeks kemungkinan akan rusak.
Pemikiran Terakhir
Masalah ini tidak terjadi untuk kueri pembaruan (setidaknya sejauh yang saya tahu) tetapi ini tampaknya lebih kebetulan daripada desain - Agregat Aliran yang bermasalah masih ada dalam rencana pembaruan yang berpotensi rentan, tetapi Skalar Hitung yang menghasilkan jumlah NULL tidak ditambahkan (atau mungkin dioptimalkan). Beri tahu saya jika Anda berhasil mereproduksi bug menggunakan kueri pembaruan.
Sampai bug ini diperbaiki (atau, mungkin, agregat skalar menjadi tidak diizinkan dalam tampilan yang diindeks) berhati-hatilah dalam menggunakan agregat dalam tampilan yang diindeks tanpa klausa GROUP BY.
Artikel ini didorong oleh item Connect yang dikirimkan oleh Vladimir Moldovanenko, yang cukup baik untuk meninggalkan komentar di posting blog lama saya (yang menyangkut korupsi tampilan terindeks yang berbeda yang disebabkan oleh pernyataan MERGE). Vladimir menggunakan agregat skalar dalam tampilan yang diindeks untuk alasan yang masuk akal, jadi jangan terlalu cepat menilai bug ini sebagai kasus tepi yang tidak akan pernah Anda temui di lingkungan produksi! Terima kasih saya kepada Vladimir karena telah mengingatkan saya tentang item Connect-nya.