Dalam posting terakhir saya, kami melihat bagaimana kueri yang menampilkan agregat skalar dapat diubah oleh pengoptimal ke bentuk yang lebih efisien. Sebagai pengingat, ini skemanya lagi:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Pilihan Rencana
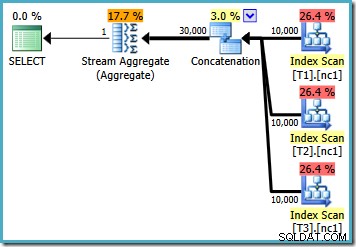
Dengan 10.000 baris di setiap tabel dasar, pengoptimal datang dengan rencana sederhana yang menghitung maksimum dengan membaca semua 30.000 baris menjadi agregat:
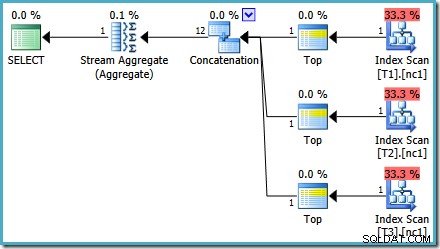
Dengan 50.000 baris di setiap tabel, pengoptimal menghabiskan sedikit lebih banyak waktu untuk masalah dan menemukan rencana yang lebih cerdas. Itu hanya membaca baris atas (dalam urutan menurun) dari setiap indeks dan kemudian menghitung maksimum hanya dari 3 baris tersebut:
Bug Pengoptimal
Anda mungkin melihat sesuatu yang agak aneh tentang perkiraan itu rencana. Operator Penggabungan membaca satu baris dari tiga tabel dan entah bagaimana menghasilkan dua belas baris! Ini adalah kesalahan yang disebabkan oleh bug dalam estimasi kardinalitas yang saya laporkan pada Mei 2011. Ini masih belum diperbaiki pada SQL Server 2014 CTP 1 (bahkan jika penaksir kardinalitas baru digunakan) tapi saya harap ini akan diatasi untuk rilis terakhir.
Untuk melihat bagaimana kesalahan muncul, ingatlah bahwa salah satu alternatif rencana yang dipertimbangkan oleh pengoptimal untuk kasus 50.000 baris memiliki agregat parsial di bawah operator Penggabungan:
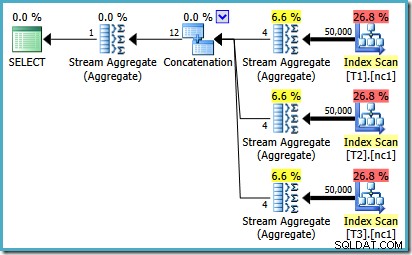
Ini adalah estimasi kardinalitas untuk MAX parsial ini agregat yang salah. Mereka memperkirakan empat baris yang hasilnya dijamin satu baris. Anda mungkin melihat angka selain empat – itu tergantung pada berapa banyak prosesor logis yang tersedia untuk pengoptimal pada saat paket dikompilasi (lihat tautan bug di atas untuk detail lebih lanjut).
Pengoptimal kemudian mengganti agregat parsial dengan operator Top (1), yang menghitung ulang perkiraan kardinalitas dengan benar. Sayangnya, operator Penggabungan masih mencerminkan perkiraan untuk agregat parsial yang diganti (3 * 4 =12). Akibatnya, kita berakhir dengan Penggabungan yang membaca 3 baris dan menghasilkan 12.
Menggunakan TOP bukan MAX
Melihat kembali rencana 50.000 baris, tampaknya peningkatan terbesar yang ditemukan oleh pengoptimal adalah menggunakan operator Top (1) daripada membaca semua baris dan menghitung nilai maksimum menggunakan brute force. Apa yang terjadi jika kita mencoba sesuatu yang serupa dan menulis ulang kueri menggunakan Top secara eksplisit?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Rencana eksekusi untuk kueri baru adalah:
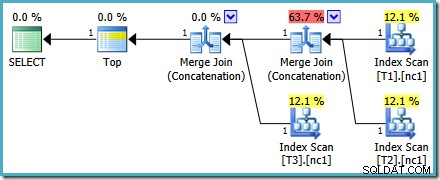
Paket ini sangat berbeda dari yang dipilih oleh pengoptimal untuk MAX pertanyaan. Ini menampilkan tiga Pemindaian Indeks yang dipesan, dua Penggabungan Gabung yang berjalan dalam mode Penggabungan, dan satu operator Top. Paket kueri baru ini memiliki beberapa fitur menarik yang perlu diperiksa dengan sedikit detail.
Analisis Rencana
Baris pertama (dalam urutan indeks menurun) dibaca dari indeks nonclustered setiap tabel, dan Gabung Gabung yang beroperasi dalam mode Penggabungan digunakan. Meskipun operator Gabung Gabung tidak melakukan penggabungan dalam arti normal, algoritme pemrosesan operator ini mudah disesuaikan untuk menggabungkan inputnya alih-alih menerapkan kriteria gabung.
Manfaat menggunakan operator ini dalam paket baru adalah Merge Concatenation mempertahankan urutan pengurutan di seluruh inputnya. Sebaliknya, operator Penggabungan reguler membaca dari inputnya secara berurutan. Diagram di bawah menggambarkan perbedaannya (klik untuk meluaskan):
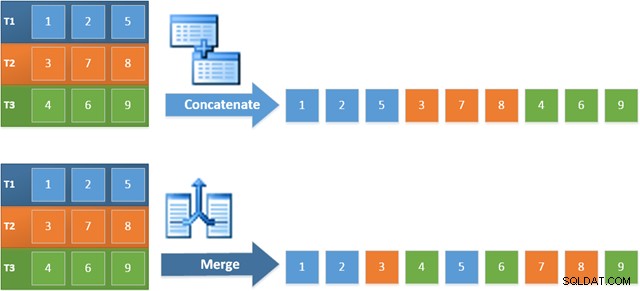
Perilaku mempertahankan urutan Penggabungan Penggabungan berarti bahwa baris pertama yang dihasilkan oleh operator Penggabungan paling kiri dalam rencana baru dijamin menjadi baris dengan nilai tertinggi di kolom c1 di ketiga tabel. Lebih khusus lagi, rencana tersebut beroperasi sebagai berikut:
- Satu baris dibaca dari setiap tabel (dalam urutan indeks menurun); dan
- Setiap penggabungan melakukan satu pengujian untuk melihat baris input mana yang memiliki nilai lebih tinggi
Ini tampaknya merupakan strategi yang sangat efisien, jadi mungkin tampak aneh bahwa MAX pengoptimal rencana memiliki perkiraan biaya kurang dari setengah dari rencana baru. Untuk sebagian besar, alasannya adalah bahwa Penggabungan Penggabungan yang mempertahankan pesanan diasumsikan lebih mahal daripada Penggabungan sederhana. Pengoptimal tidak menyadari bahwa setiap Penggabungan hanya dapat melihat maksimum satu baris, dan akibatnya menaksir biayanya secara berlebihan.
Masalah Biaya Lainnya
Sebenarnya kami tidak membandingkan apel dengan apel di sini, karena kedua paket tersebut untuk kueri yang berbeda. Membandingkan biaya seperti itu umumnya bukan hal yang valid untuk dilakukan, meskipun SSMS melakukan hal itu dengan menampilkan persentase biaya untuk pernyataan yang berbeda dalam satu batch. Tapi, saya ngelantur.
Jika Anda melihat paket baru di SSMS alih-alih SQL Sentry Plan Explorer, Anda akan melihat sesuatu seperti ini:
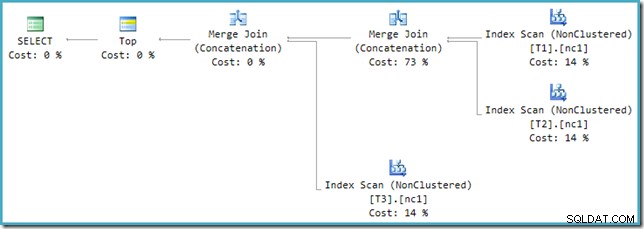
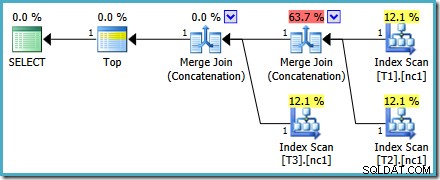
Salah satu operator Merge Join Concatenation memiliki perkiraan biaya 73% sedangkan yang kedua (beroperasi pada jumlah baris yang sama persis) ditampilkan tanpa biaya sama sekali. Tanda lain bahwa ada sesuatu yang salah di sini adalah persentase biaya operator dalam paket ini tidak berjumlah 100%.
Pengoptimal versus Mesin Eksekusi
Masalahnya terletak pada ketidakcocokan antara pengoptimal dan mesin eksekusi. Di pengoptimal, Union dan Union All dapat memiliki 2 input atau lebih. Di mesin eksekusi, hanya operator Penggabungan yang dapat menerima 2 atau lebih masukan; Gabung Bergabung membutuhkan tepat dua input, bahkan ketika dikonfigurasi untuk melakukan penggabungan daripada bergabung.
Untuk mengatasi ketidakcocokan ini, penulisan ulang pasca-optimasi diterapkan untuk menerjemahkan pohon keluaran pengoptimal ke dalam bentuk yang dapat ditangani oleh mesin eksekusi. Di mana Union atau Union All dengan lebih dari dua input diimplementasikan menggunakan Merge, rantai operator diperlukan. Dengan tiga input ke Union All dalam kasus ini, dua Gabung Serikat diperlukan:
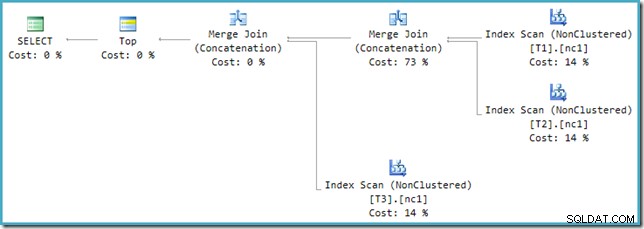
Kita dapat melihat pohon keluaran pengoptimal (dengan tiga masukan ke gabungan gabungan fisik) menggunakan tanda jejak 8607:
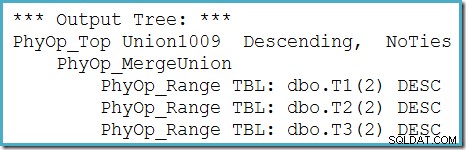
Perbaikan yang tidak lengkap
Sayangnya, penulisan ulang pasca-pengoptimalan tidak diterapkan dengan sempurna. Itu membuat sedikit berantakan dari nomor biaya. Mengesampingkan masalah, biaya paket bertambah hingga 114% dengan tambahan 14% berasal dari input ke Penggabungan Gabung Gabung tambahan yang dihasilkan oleh penulisan ulang:
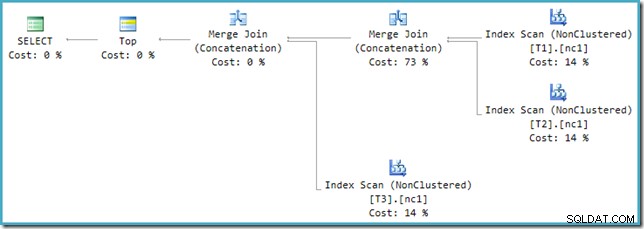
Penggabungan paling kanan dalam rencana ini adalah operator asli di pohon keluaran pengoptimal. Ini dibebankan biaya penuh dari operasi Union All. Penggabungan lainnya ditambahkan dengan penulisan ulang dan menerima biaya nol.
Apa pun cara yang kami pilih untuk melihatnya (dan ada masalah berbeda yang memengaruhi Penggabungan reguler), angka-angkanya terlihat aneh. Plan Explorer melakukan yang terbaik untuk mengatasi informasi yang rusak dalam paket XML dengan setidaknya memastikan jumlahnya bertambah hingga 100%:
Masalah penetapan biaya khusus ini telah diperbaiki di SQL Server 2014 CTP 1:
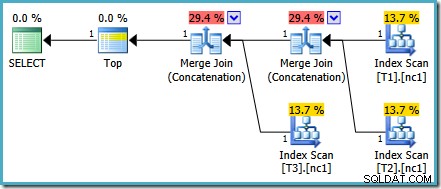
Biaya Penggabungan Penggabungan sekarang dibagi rata antara dua operator, dan persentasenya bertambah hingga 100%. Karena XML yang mendasarinya telah diperbaiki, SSMS juga berhasil menampilkan nomor yang sama.
Paket Mana yang Lebih Baik?
Jika kita menulis query menggunakan MAX , kita harus mengandalkan pengoptimal yang memilih untuk melakukan pekerjaan ekstra yang diperlukan untuk menemukan rencana yang efisien. Jika pengoptimal menemukan rencana yang tampaknya cukup baik sejak awal, ia dapat menghasilkan rencana yang relatif tidak efisien yang membaca setiap baris dari setiap tabel dasar:
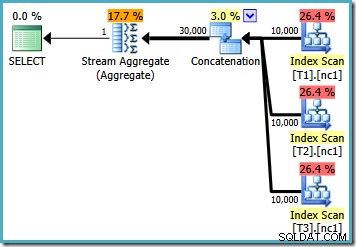
Jika Anda menjalankan SQL Server 2008 atau SQL Server 2008 R2, pengoptimal akan tetap memilih paket yang tidak efisien terlepas dari jumlah baris di tabel dasar. Paket berikut diproduksi di SQL Server 2008 R2 dengan 50.000 baris:
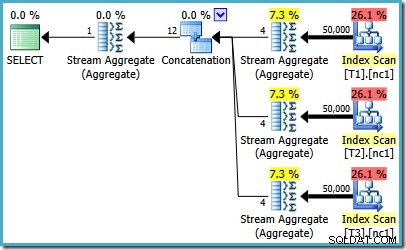
Bahkan dengan 50 juta baris di setiap tabel, pengoptimal R2 2008 dan 2008 hanya menambahkan paralelisme, tidak memperkenalkan operator Top:
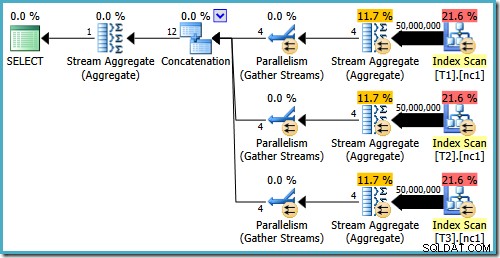
Seperti yang disebutkan dalam posting saya sebelumnya, trace flag 4199 diperlukan untuk mendapatkan SQL Server 2008 dan 2008 R2 untuk menghasilkan paket dengan operator Top. SQL Server 2005 dan 2012 dan seterusnya tidak memerlukan tanda jejak:
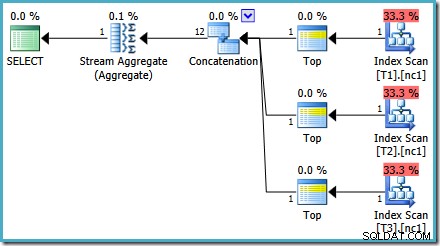
ATAS dengan ORDER BY
Setelah kami memahami apa yang terjadi dalam rencana eksekusi sebelumnya, kami dapat membuat pilihan sadar (dan terinformasi) untuk menulis ulang kueri menggunakan TOP eksplisit dengan ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Rencana eksekusi yang dihasilkan mungkin memiliki persentase biaya yang terlihat aneh di beberapa versi SQL Server, tetapi rencana dasarnya masuk akal. Penulisan ulang pasca-pengoptimalan yang menyebabkan angka terlihat ganjil diterapkan setelah pengoptimalan kueri selesai, sehingga kami dapat memastikan bahwa pilihan paket pengoptimal tidak terpengaruh oleh masalah ini.
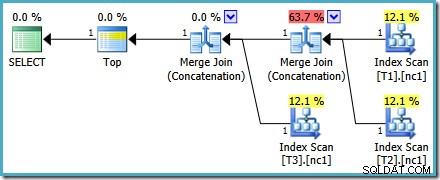
Paket ini tidak berubah tergantung pada jumlah baris di tabel dasar, dan tidak memerlukan tanda jejak apa pun untuk dibuat. Keuntungan tambahan kecil adalah bahwa rencana ini ditemukan oleh pengoptimal selama fase pertama pengoptimalan berbasis biaya (pencarian 0):
Paket terbaik yang dipilih oleh pengoptimal untuk MAX kueri diperlukan untuk menjalankan dua tahap pengoptimalan berbasis biaya (telusuri 0 dan cari 1).
Ada perbedaan semantik kecil antara TOP kueri dan MAX asli bentuk yang harus saya sebutkan. Jika tidak ada tabel yang berisi baris, kueri asli akan menghasilkan satu NULL hasil. Pengganti TOP (1) query tidak menghasilkan output sama sekali dalam keadaan yang sama. Perbedaan ini seringkali tidak penting dalam kueri dunia nyata, tetapi ini adalah sesuatu yang harus diperhatikan. Kita dapat meniru perilaku TOP menggunakan MAX di SQL Server 2008 dan seterusnya dengan menambahkan set kosong GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Perubahan ini tidak mempengaruhi rencana eksekusi yang dihasilkan untuk MAX kueri dengan cara yang terlihat oleh pengguna akhir.
MAX dengan Merge Concatenation
Mengingat keberhasilan Merge Join Concatenation di TOP (1) rencana eksekusi, wajar untuk bertanya-tanya apakah rencana optimal yang sama dapat dihasilkan untuk MAX asli kueri jika kami memaksa pengoptimal untuk menggunakan Merge Concatenation alih-alih Concatenation biasa untuk UNION ALL operasi.
Ada petunjuk kueri untuk tujuan ini – MERGE UNION – tapi sayangnya itu hanya berfungsi dengan benar di SQL Server 2012 dan seterusnya. Di versi sebelumnya, UNION petunjuk hanya memengaruhi UNION kueri, bukan UNION ALL . Di SQL Server 2012 dan seterusnya, kita dapat mencoba ini:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Kami dihadiahi dengan paket yang menampilkan Merge Concatenation. Sayangnya, itu bukan segalanya yang kami harapkan:
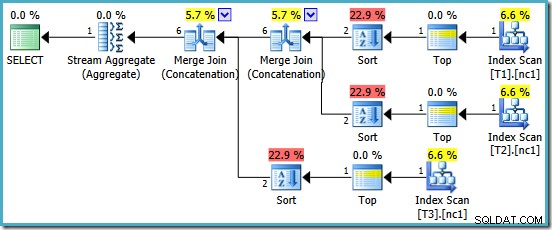
Operator yang menarik dalam rencana ini adalah macamnya. Perhatikan estimasi kardinalitas input 1 baris, dan estimasi 4 baris pada output. Penyebabnya seharusnya sudah Anda kenal sekarang:ini adalah kesalahan estimasi kardinalitas agregat parsial yang sama yang telah kita bahas sebelumnya.
Kehadiran jenis mengungkapkan satu masalah lagi dengan agregat parsial. Mereka tidak hanya menghasilkan perkiraan kardinalitas yang salah, mereka juga gagal mempertahankan urutan indeks yang akan membuat penyortiran tidak perlu (Merge Concatenation memerlukan input yang diurutkan). Agregat parsial adalah skalar MAX agregat, dijamin untuk menghasilkan satu baris sehingga masalah pemesanan harus diperdebatkan (hanya ada satu cara untuk mengurutkan satu baris!)
Ini memalukan, karena tanpa semacam ini akan menjadi rencana eksekusi yang layak. Jika agregat parsial diterapkan dengan benar, dan MAX ditulis dengan GROUP BY () klausa, kami bahkan mungkin berharap pengoptimal dapat melihat bahwa tiga Tops dan Stream Agregat terakhir dapat digantikan oleh satu operator Top terakhir, memberikan rencana yang sama persis dengan TOP (1) eksplisit pertanyaan. Pengoptimal tidak memuat transformasi itu hari ini, dan saya rasa itu tidak akan cukup sering berguna untuk membuat penyertaannya bermanfaat di masa mendatang.
Kata Akhir
Menggunakan TOP tidak akan selalu lebih baik daripada MIN atau MAX . Dalam beberapa kasus akan menghasilkan rencana yang kurang optimal secara signifikan. Inti dari postingan ini adalah memahami transformasi yang diterapkan oleh pengoptimal dapat menyarankan cara untuk menulis ulang kueri asli yang mungkin berguna.



