SQL Server 2014 menghadirkan banyak fitur baru yang ditunggu-tunggu oleh DBA dan pengembang untuk diuji dan digunakan di lingkungan mereka, seperti indeks Columnstore berkerumun yang dapat diperbarui, Ketahanan Tertunda, dan Ekstensi Buffer Pool. Fitur yang tidak sering dibahas adalah statistik inkremental. Kecuali Anda menggunakan partisi, ini bukan fitur yang dapat Anda terapkan. Tetapi jika Anda memiliki tabel yang dipartisi dalam database Anda, statistik inkremental mungkin merupakan sesuatu yang sangat Anda nantikan.
Catatan:Benjamin Nevarez membahas beberapa dasar yang terkait dengan statistik inkremental dalam posting Februari 2014, SQL Server 2014 Incremental Statistics. Dan meskipun tidak banyak yang berubah dalam cara kerja fitur ini sejak postingnya dan rilis April 2014, sepertinya ini saat yang tepat untuk menggali bagaimana mengaktifkan statistik tambahan dapat membantu kinerja pemeliharaan.
Statistik tambahan kadang-kadang disebut statistik tingkat partisi, dan ini karena untuk pertama kalinya, SQL Server dapat secara otomatis membuat statistik khusus untuk sebuah partisi. Salah satu tantangan sebelumnya dengan partisi adalah, meskipun Anda dapat memiliki 1 hingga n partisi untuk tabel, hanya ada satu (1) statistik yang mewakili distribusi data di semua partisi tersebut. Anda dapat membuat statistik yang difilter untuk tabel yang dipartisi – satu statistik untuk setiap partisi – untuk menyediakan pengoptimal kueri dengan informasi yang lebih baik tentang distribusi data. Tetapi ini adalah proses manual, dan memerlukan skrip untuk membuatnya secara otomatis untuk setiap partisi baru.
Di SQL Server 2014, Anda menggunakan STATISTICS_INCREMENTAL opsi agar SQL Server membuat statistik tingkat partisi tersebut secara otomatis. Namun, statistik ini tidak digunakan seperti yang Anda kira.
Saya sebutkan sebelumnya bahwa, sebelum 2014, Anda dapat membuat statistik yang difilter untuk memberikan pengoptimal informasi yang lebih baik tentang partisi. Statistik tambahan itu? Mereka saat ini tidak digunakan oleh pengoptimal. Pengoptimal kueri masih hanya menggunakan histogram utama yang mewakili seluruh tabel. (Posting yang akan datang yang akan menunjukkan ini!)
Jadi apa gunanya statistik inkremental? Jika Anda berasumsi bahwa hanya data di partisi terbaru yang berubah, maka idealnya Anda hanya memperbarui statistik untuk partisi tersebut. Anda dapat melakukannya sekarang dengan statistik tambahan – dan yang terjadi adalah informasi tersebut kemudian digabungkan kembali ke dalam histogram utama. Histogram untuk seluruh tabel akan diperbarui tanpa harus membaca seluruh tabel untuk memperbarui statistik, dan ini dapat membantu kinerja tugas pemeliharaan Anda.
Penyiapan
Kami akan mulai dengan membuat fungsi dan skema partisi, dan kemudian tabel baru yang akan kami partisi. Perhatikan bahwa saya membuat grup file untuk setiap fungsi partisi seperti yang mungkin Anda lakukan di lingkungan produksi. Anda dapat membuat skema partisi pada filegroup yang sama (mis. PRIMARY ) jika Anda tidak dapat dengan mudah menjatuhkan basis data pengujian Anda. Setiap grup file juga berukuran beberapa GB, karena kami akan menambahkan hampir 400 juta baris.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Sebelum menambahkan data, kita akan membuat indeks berkerumun, dan perhatikan bahwa sintaksnya menyertakan WITH (STATISTICS_INCREMENTAL = ON) pilihan:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Yang menarik untuk diperhatikan di sini adalah jika Anda melihat ALTER TABLE entri di MSDN, itu tidak termasuk opsi ini. Anda hanya akan menemukannya di ALTER INDEX masuk ... tapi ini berhasil. Jika Anda ingin mengikuti dokumentasi ke surat, Anda akan menjalankan:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Setelah indeks berkerumun dibuat untuk skema partisi, kami akan memuat data kami dan kemudian memeriksa untuk melihat berapa banyak baris yang ada per partisi (perhatikan ini membutuhkan waktu lebih dari 7 menit di laptop saya, Anda mungkin ingin menambahkan lebih sedikit baris tergantung pada seberapa banyak penyimpanan (dan waktu) yang Anda miliki):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
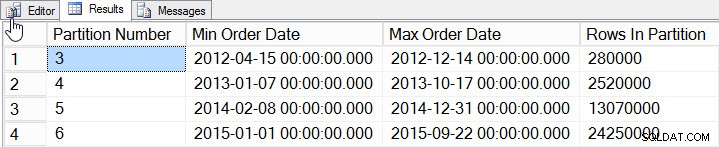 Data per partisi
Data per partisi
Kami telah menambahkan data untuk tahun 2012 hingga 2015, dengan lebih banyak data secara signifikan pada tahun 2014 dan 2015. Mari kita lihat seperti apa statistik kami:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
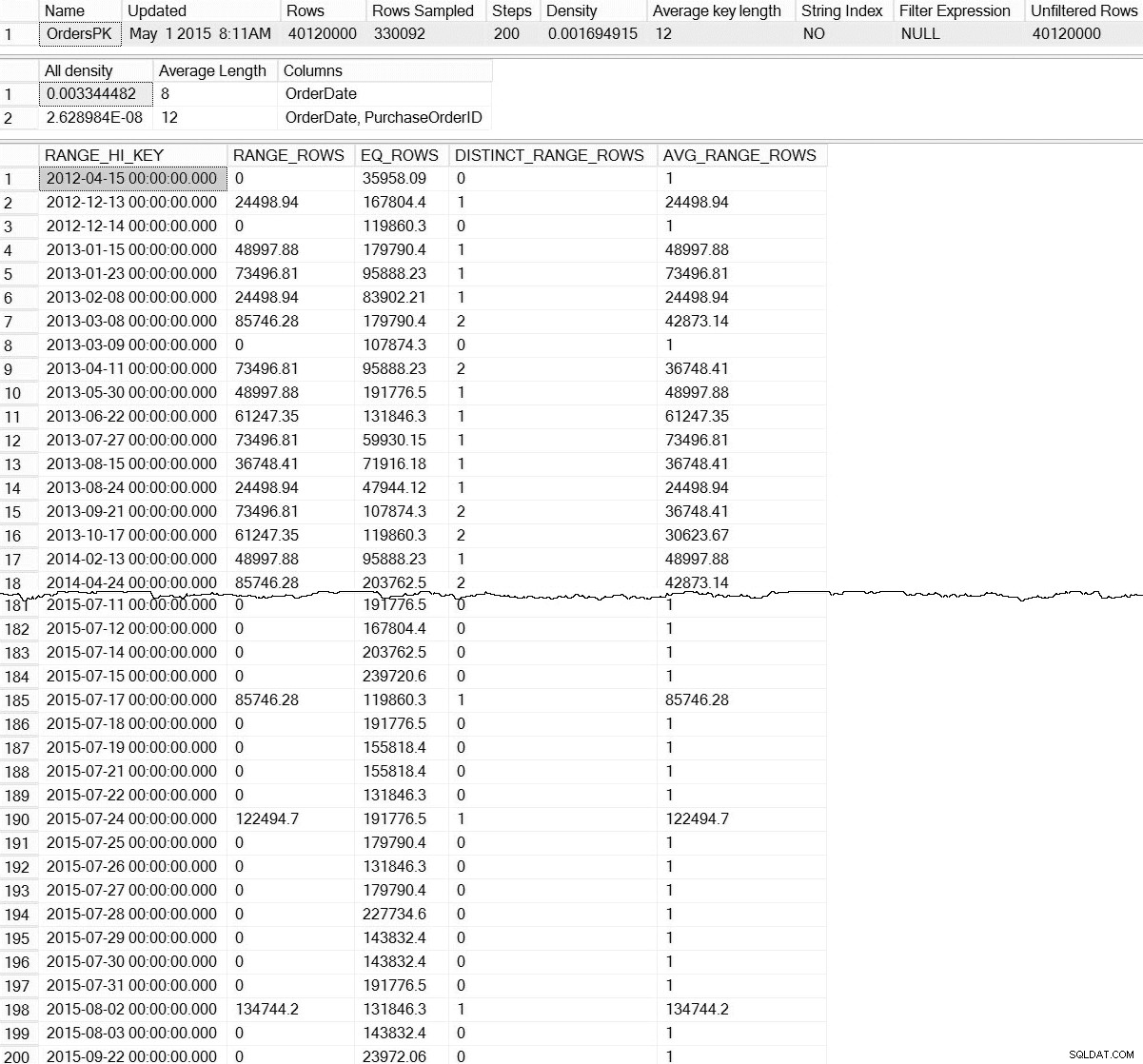 DBCC SHOW_STATISTICS keluaran untuk dbo.Orders (klik untuk memperbesar)
DBCC SHOW_STATISTICS keluaran untuk dbo.Orders (klik untuk memperbesar)
Dengan DBCC SHOW_STATISTICS default perintah, kami tidak memiliki informasi tentang statistik di tingkat partisi. Jangan takut; kami tidak sepenuhnya hancur – ada fungsi manajemen dinamis yang tidak terdokumentasi, sys.dm_db_stats_properties_internal . Ingat bahwa tidak berdokumen berarti tidak didukung (tidak ada entri MSDN untuk DMF), dan dapat berubah kapan saja tanpa peringatan dari Microsoft. Karena itu, ini adalah awal yang baik untuk mendapatkan gambaran tentang apa yang ada untuk statistik inkremental kami:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Informasi histogram dari dm_db_stats_properties_internal (klik untuk memperbesar)
Informasi histogram dari dm_db_stats_properties_internal (klik untuk memperbesar)
Ini jauh lebih menarik. Di sini kita dapat melihat bukti bahwa statistik tingkat partisi (dan banyak lagi) ada. Karena DMF ini tidak didokumentasikan, kami harus melakukan beberapa interpretasi. Untuk hari ini, kita akan fokus pada tujuh baris pertama dalam output, di mana baris pertama mewakili histogram untuk seluruh tabel (perhatikan rows nilai 40 juta), dan baris berikutnya mewakili histogram untuk setiap partisi. Sayangnya, partition_number nilai dalam histogram ini tidak sejalan dengan nomor partisi dari sys.dm_db_index_physical_stats untuk partisi berbasis kanan (itu berkorelasi dengan benar untuk partisi berbasis kiri). Perhatikan juga bahwa keluaran ini juga menyertakan last_updated dan modification_counter kolom, yang berguna saat memecahkan masalah, dan dapat digunakan untuk mengembangkan skrip pemeliharaan yang secara cerdas memperbarui statistik berdasarkan usia atau modifikasi baris.
Meminimalkan perawatan yang diperlukan
Nilai utama statistik inkremental saat ini adalah kemampuan untuk memperbarui statistik untuk sebuah partisi dan menggabungkannya ke dalam histogram tingkat tabel, tanpa harus memperbarui statistik untuk seluruh tabel (dan karenanya membaca seluruh tabel). Untuk melihat ini beraksi, pertama-tama mari kita perbarui statistik untuk partisi yang menyimpan data 2015, partisi 5, dan kita akan mencatat waktu yang dibutuhkan dan memotret sys.dm_io_virtual_file_stats DMF sebelum dan sesudah untuk melihat seberapa banyak I/O terjadi:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Keluaran:
Waktu Eksekusi SQL Server:Waktu CPU =203 md, waktu yang berlalu =240 md.
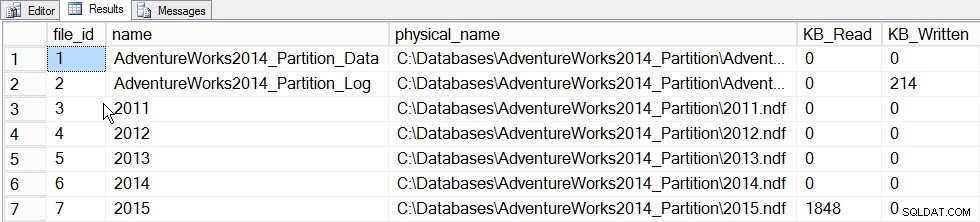 Data file_stats setelah memperbarui satu partisi
Data file_stats setelah memperbarui satu partisi
Jika kita perhatikan sys.dm_db_stats_properties_internal output, kita melihat bahwa last_updated diubah untuk histogram 2015 dan histogram tingkat tabel (serta beberapa node lainnya, yang akan diselidiki nanti):
 Informasi histogram yang diperbarui dari dm_db_stats_properties_internal
Informasi histogram yang diperbarui dari dm_db_stats_properties_internal
Sekarang kami akan memperbarui statistik dengan FULLSCAN untuk tabel, dan kami akan memotret file_stats sebelum dan sesudah lagi:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Keluaran:
Waktu Eksekusi SQL Server:Waktu CPU =12720 md, waktu yang berlalu =13646 md
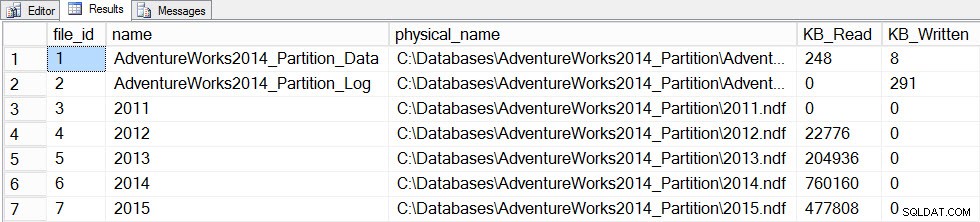 Data statistik file setelah diperbarui dengan pemindaian penuh
Data statistik file setelah diperbarui dengan pemindaian penuh
Pembaruan memakan waktu jauh lebih lama (13 detik versus beberapa ratus milidetik) dan menghasilkan lebih banyak I/O. Jika kita memeriksa sys.dm_db_stats_properties_internal lagi, kami menemukan bahwa last_updated diubah untuk semua histogram:
 Informasi histogram dari dm_db_stats_properties_internal setelah pemindaian penuh
Informasi histogram dari dm_db_stats_properties_internal setelah pemindaian penuh
Ringkasan
Sementara statistik inkremental belum digunakan oleh pengoptimal kueri untuk memberikan informasi tentang setiap partisi, statistik tersebut memberikan manfaat kinerja saat mengelola statistik untuk tabel yang dipartisi. Jika statistik hanya perlu diperbarui untuk partisi tertentu, hanya itu yang dapat diperbarui. Informasi baru kemudian digabungkan ke dalam histogram tingkat tabel, memberikan pengoptimal lebih banyak informasi terkini, tanpa biaya membaca seluruh tabel. Ke depannya, kami berharap statistik tingkat partisi tersebut akan digunakan oleh pengoptimal. Pantau terus…



