Dalam posting saya sebelumnya tentang statistik tambahan, fitur baru di SQL Server 2014, saya menunjukkan bagaimana mereka dapat membantu mengurangi durasi tugas pemeliharaan. Ini karena statistik dapat diperbarui di tingkat partisi, dan perubahannya digabungkan ke dalam histogram utama untuk tabel. Saya juga mencatat bahwa Pengoptimal Kueri tidak menggunakan statistik tingkat partisi tersebut saat membuat rencana kueri, yang mungkin merupakan sesuatu yang diharapkan orang. Tidak ada dokumentasi yang menyatakan bahwa statistik inkremental akan, atau tidak, akan digunakan oleh Pengoptimal Kueri. Jadi bagaimana Anda tahu? Anda harus mengujinya. :-)
Penyiapan
Pengaturan untuk tes ini akan mirip dengan yang ada di posting terakhir, tetapi dengan lebih sedikit data. Perhatikan bahwa ukuran default lebih kecil untuk file data, dan skrip hanya dimuat dalam beberapa juta baris data:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Saat kita membuat indeks berkerumun untuk dbo.Orders, kita akan membuatnya tanpa STATISTICS_INCREMENTAL opsi diaktifkan, jadi kita akan mulai dengan tabel terpartisi tradisional tanpa statistik tambahan:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Selanjutnya kita akan memuat sekitar 4 juta baris, yang hanya membutuhkan waktu kurang dari satu menit di komputer saya:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Setelah memuat data, kami akan memperbarui statistik dengan FULLSCAN (sehingga kami dapat membuat histogram yang konsisten untuk pengujian) dan kemudian memverifikasi data apa yang kami miliki di setiap partisi:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Data di setiap partisi setelah data dimuat
Data di setiap partisi setelah data dimuat
Sebagian besar data ada di partisi 2015, tetapi ada juga data untuk 2012, 2013, dan 2014. Dan jika kita memeriksa output dari DMV yang tidak berdokumen sys.dm_db_stats_properties_internal , kita dapat melihat bahwa tidak ada statistik tingkat partisi:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_output internal hanya menampilkan satu statistik untuk dbo.Orders
sys.dm_db_stats_properties_output internal hanya menampilkan satu statistik untuk dbo.Orders
Ujian
Pengujian memerlukan kueri sederhana yang dapat kita gunakan untuk memverifikasi bahwa penghapusan partisi terjadi, dan juga memeriksa perkiraan berdasarkan statistik. Kueri tidak mengembalikan data apa pun, tetapi itu tidak masalah, kami tertarik dengan apa yang pikirkan pengoptimal itu akan kembali, berdasarkan statistik:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
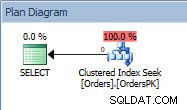 Rencana kueri untuk pernyataan SELECT
Rencana kueri untuk pernyataan SELECT
Paket tersebut memiliki Clustered Index Seek, dan jika kita memeriksa propertinya, kita melihat bahwa itu memperkirakan 4000 baris, dan mengakses partisi 5, yang berisi data 2014.
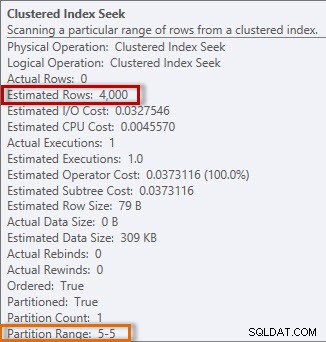 Perkiraan dan informasi aktual dari Pencarian Indeks Terkelompok
Perkiraan dan informasi aktual dari Pencarian Indeks Terkelompok
Jika kita melihat histogram untuk tabel dbo.Orders, khususnya di area data April 2014, kita melihat bahwa tidak ada langkah untuk 04-01-2014, sehingga pengoptimal memperkirakan jumlah baris untuk tanggal tersebut menggunakan langkah untuk 24-04-2014, di mana AVG_RANGE_ROWS adalah 4000 (untuk satu nilai antara 14-02-2014 dan 23-04-2014 inklusif, pengoptimal akan memperkirakan bahwa 4000 baris akan dikembalikan).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
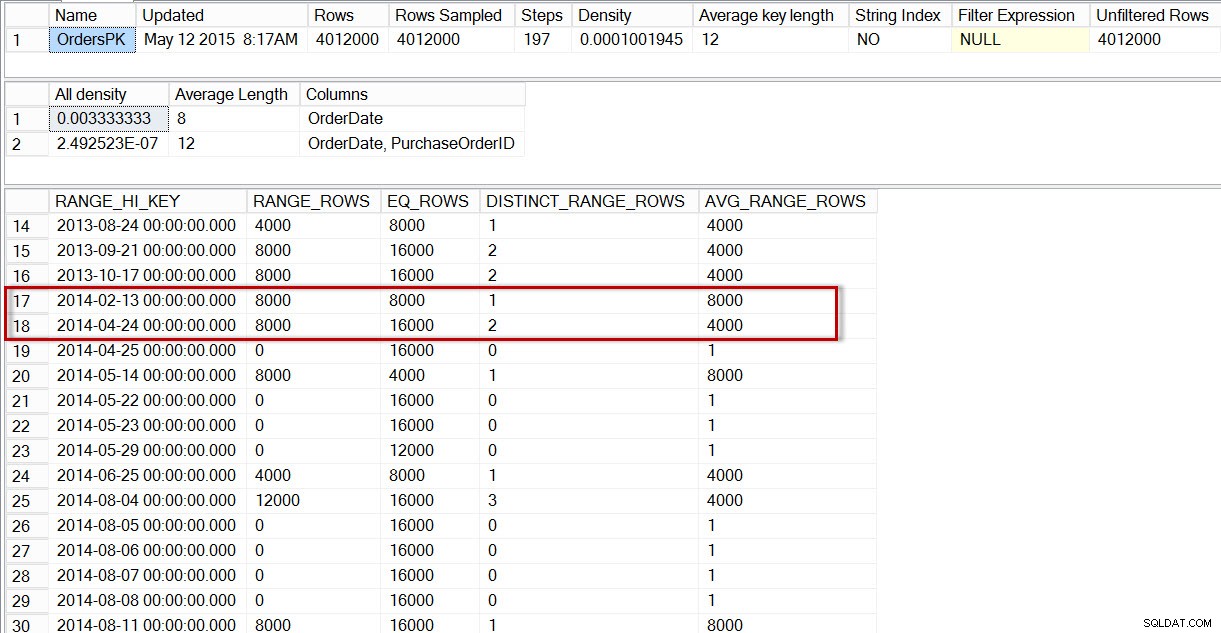 Distribusi dalam histogram dbo.Orders
Distribusi dalam histogram dbo.Orders
Perkiraan dan rencana sepenuhnya diharapkan. Mari aktifkan statistik tambahan dan lihat apa yang kita dapatkan.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Jika kami menjalankan kembali kueri kami terhadap sys.dm_db_stats_properties_internal , kita dapat melihat statistik inkremental:
 sys.dm_db_stats_properties_internal menampilkan informasi statistik tambahan
sys.dm_db_stats_properties_internal menampilkan informasi statistik tambahan
Sekarang mari kita jalankan kembali query kita lagi dbo.Orders, dan kita akan menjalankan DBCC FREEPROCCACHE pertama untuk sepenuhnya memastikan paket tidak digunakan kembali:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Kami mendapatkan paket yang sama, dan perkiraan yang sama:
Rencana kueri untuk pernyataan SELECT
Perkiraan dan informasi aktual dari Pencarian Indeks Terkelompok
Jika kita memeriksa histogram utama untuk dbo.Orders, kita melihat histogram yang hampir sama seperti sebelumnya:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histogram untuk dbo.Orders, setelah mengaktifkan statistik tambahan
Histogram untuk dbo.Orders, setelah mengaktifkan statistik tambahan
Sekarang, mari kita periksa histogram untuk partisi dengan data 2014 (kita dapat melakukannya menggunakan tanda jejak tidak berdokumen 2309, yang memungkinkan nomor partisi ditentukan sebagai argumen tambahan untuk DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
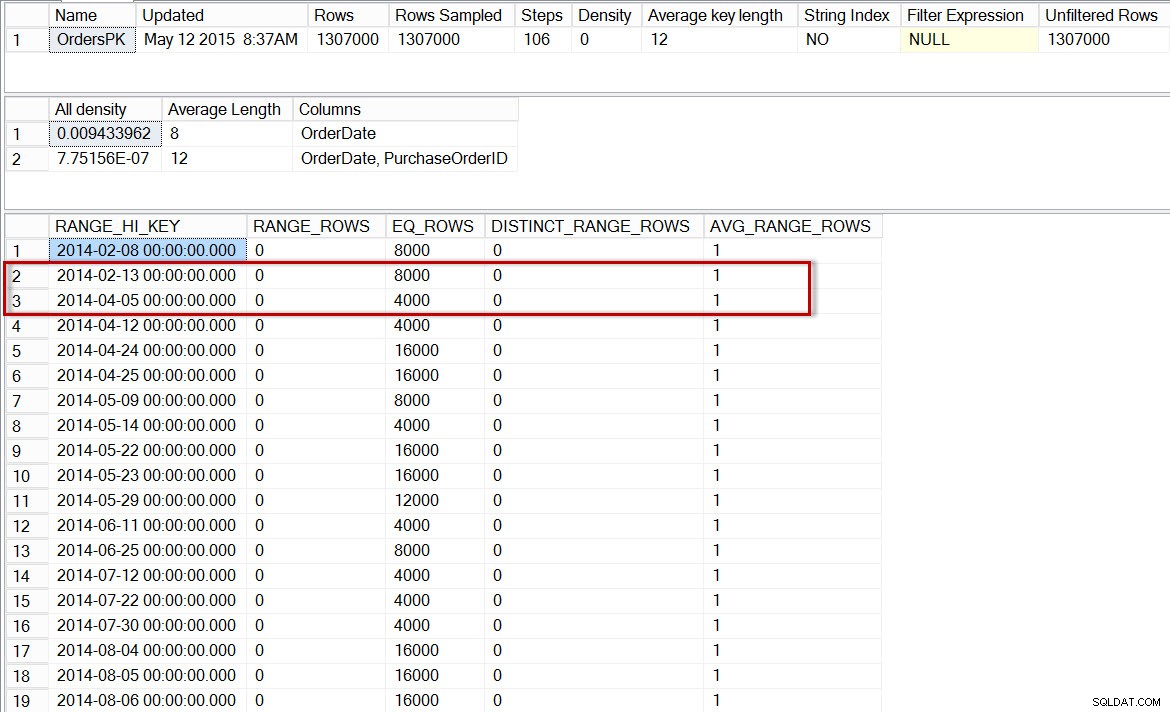
Histogram untuk partisi dbo.Orders tahun 2014, setelah mengaktifkan statistik tambahan
Di sini kita melihat bahwa, sekali lagi, tidak ada langkah untuk 04-01-2014, tetapi ada 0 RANGE_ROWS antara 13-02-2014 dan 04-05-2014, dengan AVG_RANGE_ROWS dari 1. Jika pengoptimal menggunakan histogram untuk statistik tingkat partisi, maka perkiraan jumlah baris untuk 04-01 2014 adalah 1.
Catatan:Partisi yang diidentifikasi seperti yang digunakan dalam rencana kueri adalah 5, tetapi Anda akan melihat bahwa DBCC SHOW_STATISTICS partisi referensi pernyataan 6. Asumsinya adalah inkonsistensi dalam metadata statistik (kesalahan umum satu per satu, kemungkinan karena penghitungan berbasis 0 vs. berbasis 1), yang mungkin atau mungkin tidak diperbaiki di masa mendatang. Pahami bahwa tanda pelacakan tidak didokumentasikan saat ini, dan tidak direkomendasikan untuk digunakan di lingkungan produksi.
Ringkasan
Penambahan statistik inkremental dalam rilis SQL Server 2014 adalah langkah ke arah yang benar untuk meningkatkan perkiraan kardinalitas untuk tabel yang dipartisi. Namun, seperti yang telah kami tunjukkan, nilai statistik inkremental saat ini terbatas pada penurunan durasi pemeliharaan, karena statistik inkremental tersebut belum digunakan oleh Pengoptimal Kueri.