Sementara Jeff Atwood dan Joe Celko tampaknya berpikir bahwa biaya GUID bukanlah masalah besar (lihat posting blog Jeff, "Kunci Utama:ID versus GUID," dan utas newsgroup ini, berjudul "Identitas Vs. Uniqueidentifier"), pakar lainnya – lebih khusus pakar indeks dan arsitektur yang berfokus pada ruang SQL Server – cenderung tidak setuju. Misalnya, Kimberly Tripp membahas beberapa detail dalam postingnya, "Ruang Disk Murah – ITU BUKAN TITIKNYA!", Di mana dia menjelaskan bahwa dampaknya tidak hanya pada ruang disk dan fragmentasi, tetapi lebih penting lagi pada ukuran indeks dan memori. tapak.
Apa yang dikatakan Kimberly memang benar – saya selalu menemukan pembenaran "ruang disk murah" untuk GUID (contoh dari minggu lalu). Ada pembenaran lain untuk GUID, termasuk kebutuhan untuk menghasilkan pengidentifikasi unik di luar database (dan terkadang sebelum baris benar-benar dibuat), dan kebutuhan akan pengidentifikasi unik di seluruh sistem terdistribusi yang terpisah (dan di mana rentang identitas tidak praktis). Tapi saya benar-benar ingin menghilangkan mitos bahwa GUID tidak menghabiskan banyak biaya, karena memang demikian, dan Anda perlu mempertimbangkan biaya ini ke dalam keputusan Anda.
Saya memulai misi ini untuk menguji kinerja ukuran kunci yang berbeda, dengan data yang sama di jumlah baris yang sama, dengan indeks yang sama, dan beban kerja yang kira-kira sama (memutar ulang beban kerja yang *persis* yang sama bisa sangat menantang). Saya tidak hanya ingin mengukur hal-hal dasar seperti ukuran indeks dan fragmentasi indeks, tetapi juga efek yang ditimbulkannya, seperti:
- dampak pada penggunaan kumpulan buffer
- frekuensi pemisahan halaman "buruk"
- dampak keseluruhan pada durasi beban kerja yang realistis
- dampak pada rata-rata waktu proses kueri individual
- dampak pada durasi runtime setelah pemicu
- dampak pada penggunaan tempdb
Saya akan menggunakan berbagai teknik untuk menyelidiki data ini, termasuk Extended Events, default trace, tempdb-related DMVs, dan SQL Sentry Performance Advisor.
Penyiapan
Pertama, saya membuat satu juta pelanggan untuk dimasukkan ke dalam tabel benih menggunakan beberapa metadata SQL Server bawaan; ini akan memastikan bahwa pelanggan "acak" akan terdiri dari data alami yang sama di setiap pengujian.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (PARTITION BY em ORDER BY em) FROM ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. nama, LEN(o.name)%5+2) + '@' + KANAN(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;GO SELECT TOP (10) * FROM dbo.CustomerSeeds ORDER BY rn;GO
Jarak tempuh Anda mungkin berbeda, tetapi di sistem saya, populasi ini membutuhkan waktu 86 detik. Sepuluh baris perwakilan (klik untuk memperbesar):
 Pelanggan Sampel
Pelanggan Sampel
Selanjutnya, saya membutuhkan tabel untuk menampung data awal untuk setiap kasus penggunaan, dengan beberapa indeks tambahan untuk mensimulasikan semacam realitas, dan saya membuat sufiks pendek untuk membuat semua jenis diagnostik lebih mudah nanti:
| tipe data | bawaan | kompresi | gunakan akhiran kasus |
|---|---|---|---|
| INT | IDENTITAS | tidak ada | Saya |
| INT | IDENTITAS | halaman + baris | Ic |
| BESAR | IDENTITAS | tidak ada | B |
| BESAR | IDENTITAS | halaman + baris | Bc |
| UNIQUEIDENTIFIER | BARU() | tidak ada | G |
| UNIQUEIDENTIFIER | BARU() | halaman + baris | Gc |
| UNIQUEIDENTIFIER | NESEQUENTIALID() | tidak ada | S |
| UNIQUEIDENTIFIER | NESEQUENTIALID() | halaman + baris | Sc |
Tabel 1:Kasus penggunaan, tipe data, dan sufiks
Delapan tabel semuanya diceritakan, semuanya berasal dari templat yang sama (saya hanya akan mengubah komentar di sekitar agar sesuai dengan kasus penggunaan, dan mengganti $use_case$ dengan akhiran yang sesuai dari tabel di atas):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, EMail NVARCHAR(320) NOT NULL, Active BIT NOT NULL DEFAULT 1, Dibuat DATETIME NOT NULL DEFAULT SYSDATETIME(), Diperbarui DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --DATA (DATA_COMPRESSION =HALAMAN)GO;BUAT INDEKS UNIK C_$use_case_Customers. Pelanggan_$use_case$(EMail) --WITH (DATA_COMPRESSION =HALAMAN);GOCREATE INDEX C_Active_Customers_$use_case$ DI dbo.Customers_$use_case$(Nama Depan, Nama Belakang, EMail) WHERE Active =1 --WITH (DATA_COMPRESSION =HALAMAN); INDEX C_Name_Customers_$use_case$ PADA dbo.Customers_$use_case$(LastName, FirstName) TERMASUK (EMail) --DATA (DATA_COMPRESSION =PAGE);GOSetelah tabel dibuat, saya melanjutkan untuk mengisi tabel dan mengukur banyak metrik yang saya singgung di atas. Saya memulai ulang layanan SQL Server di antara setiap pengujian untuk memastikan semuanya dimulai dari garis dasar yang sama, bahwa DMV akan disetel ulang, dll.
Sisipan yang Tidak Terbantahkan
Tujuan akhir saya adalah mengisi tabel dengan 1.000.000 baris, tetapi pertama-tama saya ingin melihat dampak tipe data dan kompresi pada sisipan mentah tanpa perselisihan. Saya membuat kueri berikut – yang akan mengisi tabel dengan 200.000 kontak pertama, 2000 baris sekaligus – dan menjalankannya pada setiap tabel:
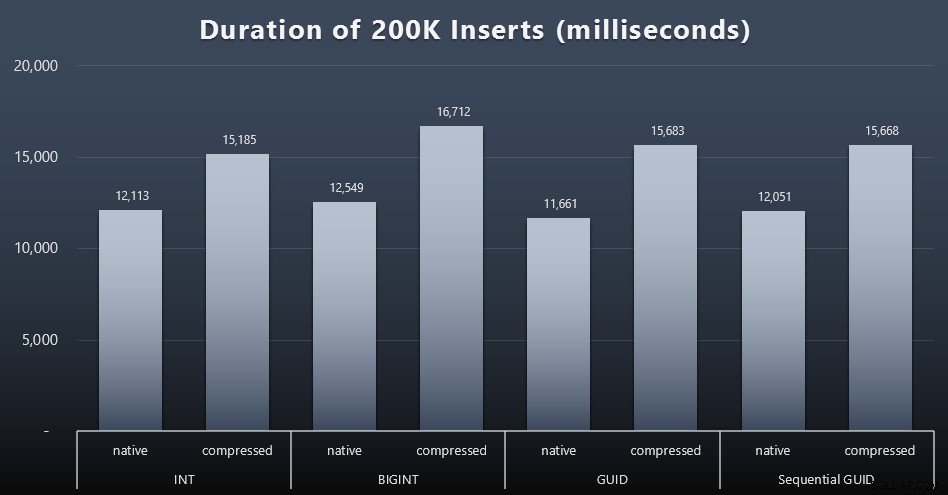
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) SELECT FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) HANYA MENGAMBIL BARIS BERIKUTNYA 2000 BARIS; SET @i +=1;ENDHasil (klik untuk memperbesar):
Setiap kasing membutuhkan waktu sekitar 12 detik (tanpa kompresi) dan 16 detik (dengan kompresi), tanpa pemenang yang jelas di kedua mode penyimpanan. Efek kompresi (terutama pada overhead CPU) cukup konsisten, tetapi karena ini berjalan pada SSD yang cepat, dampak I/O dari tipe data yang berbeda dapat diabaikan. Faktanya, kompresi terhadap BIGINT tampaknya memiliki dampak terbesar (dan ini masuk akal, karena setiap nilai kurang dari 2 miliar akan dikompresi).
Beban Kerja Lebih Banyak Perdebatan
Selanjutnya saya ingin melihat bagaimana beban kerja campuran akan bersaing untuk mendapatkan sumber daya dan secara umum bekerja terhadap setiap tipe data. Jadi saya membuat prosedur ini (mengganti
$use_case$dan$data_type$tepat untuk setiap tes):-- pembaruan tunggal acak untuk data di lebih dari satu indeksCREATE PROCEDURE [dbo].[Pelanggan_$use_case$_RandomUpdate] @Pelanggan_$use_case$ $data_type$ASBEGIN AKTIFKAN NOCOUNT; UPDATE dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- reads ("pagination") - mendukung banyak macam-- gunakan SQL dinamis untuk melacak statistik kueri secara terpisahCREATE PROCEDURE [dbo].[Pelanggan_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT CustomerID, FirstName, LastName, Email, Active, Created, Updated FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) ROWS FETCH NEXT @ps ROWS ONLY;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOKemudian saya membuat pekerjaan yang akan memanggil prosedur tersebut berulang kali, dengan sedikit penundaan, dan juga – secara bersamaan – menyelesaikan pengisian 800.000 kontak yang tersisa. Skrip ini membuat semua 32 tugas, dan juga mencetak keluaran yang dapat digunakan nanti untuk memanggil semua tugas untuk pengujian tertentu secara asinkron:
GUNAKAN msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(nama SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Populate customers', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Pelanggan_$use_case$ (Nama Depan, Nama Belakang, Email, Aktif) PILIH Nama Depan, Nama Belakang, Email, Aktif DARI dbo.CustomerSeeds SEBAGAI c ORDER OLEH rn OFFSET 2000 * (@i-1) ROWS FETCH NEXT 2000 ROWS ONLY; WAITFOR DELAY ''00:00:01''; SET @i +=1; END'),( N'Paging beban kerja 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- urutkan berdasarkan ID Pelanggan SET @sql =N ''EXEC dbo.Pelanggan_$use_case$_Halaman @PageNumber =@i, @sort =N''''IDPelanggan'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'),( N'Paging beban kerja 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- urutkan berdasarkan LastName, FirstName SET @sql =N''EXEC dbo.Pelanggan_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; MENUNGGU PENUNDA ''00:00:01''; SET @i +=2; SELESAI'); MENYATAKAN @n SYSNAME, @c NVARCHAR(MAX); MENYATAKAN c KURSOR LOKAL FAST_FORWARD FORSELECT name =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) DARI @typ SEBAGAI t CROSS GABUNG @jobs SEBAGAI j; BUKA c; TAMBAHKAN c KE @n, @c; SEMENTARA @@FETCH_STATUS <> -1BEGIN JIKA ADA (PILIH 1 FROM msdb.dbo.sysjobs WHERE name =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'ID'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(lokal)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDMengukur waktu pekerjaan dalam setiap kasus itu sepele – saya dapat memeriksa tanggal mulai/berakhir di
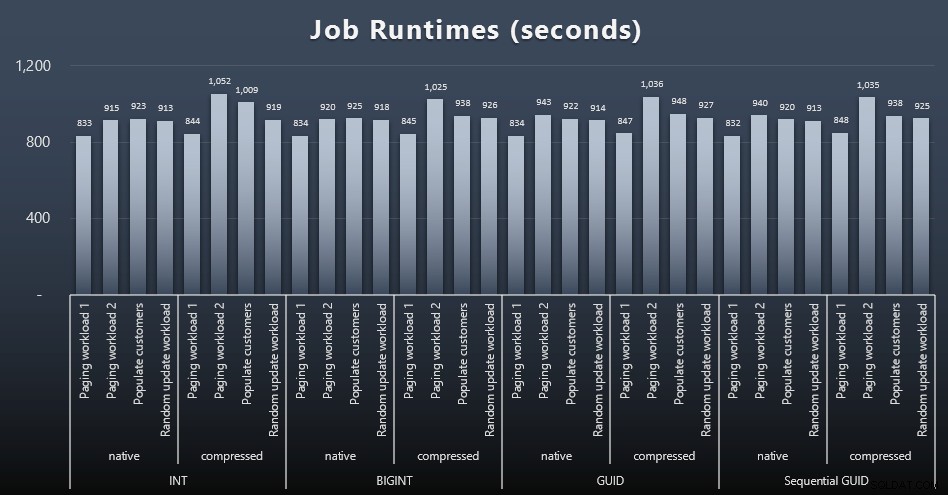
msdb.dbo.sysjobhistoryatau tarik dari SQL Sentry Event Manager. Berikut adalah hasilnya (klik untuk memperbesar):
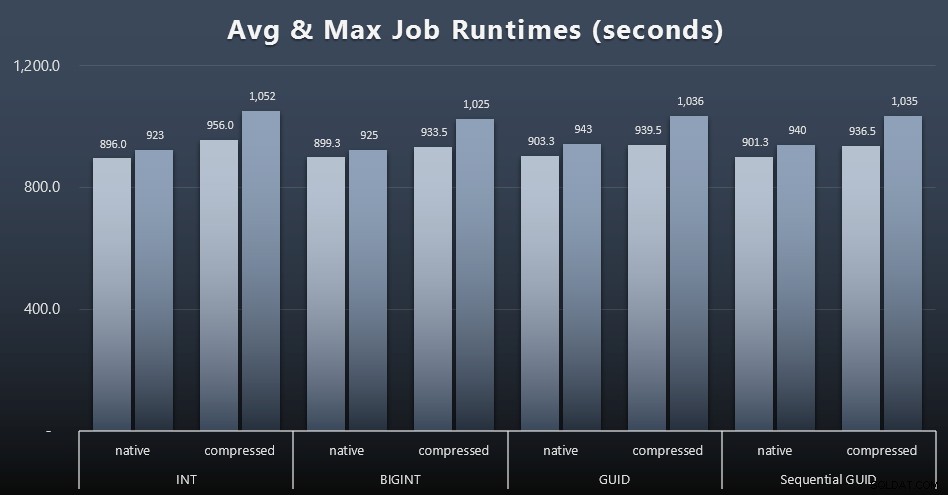
Dan jika Anda ingin memiliki sedikit lebih sedikit untuk dicerna, lihat saja runtime rata-rata dan maksimum di keempat pekerjaan (klik untuk memperbesar):
Tetapi bahkan dalam grafik kedua ini tidak ada cukup varians untuk membuat kasus yang meyakinkan untuk mendukung atau menentang salah satu pendekatan.
Waktu Proses Kueri
Saya mengambil beberapa metrik dari
sys.dm_exec_query_statsdansys.dm_exec_trigger_statsuntuk menentukan berapa lama rata-rata kueri individual.
Populasi
200.000 pelanggan pertama dimuat dengan cukup cepat – kurang dari 20 detik – karena tidak ada beban kerja yang bersaing. Namun, begitu keempat tugas dijalankan secara bersamaan, ada dampak signifikan pada durasi penulisan karena konkurensi. 800.000 baris yang tersisa membutuhkan setidaknya urutan besarnya lebih banyak waktu untuk diselesaikan, rata-rata. Berikut adalah hasil rata-rata dari setiap 2.000 pelanggan yang dimasukkan (klik untuk memperbesar):
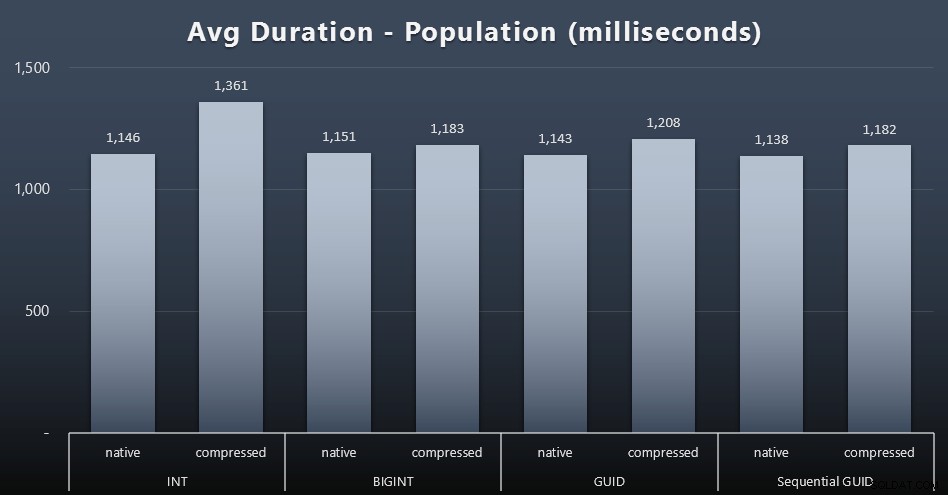
Kami melihat di sini bahwa mengompresi INT adalah satu-satunya outlier yang nyata – saya memiliki beberapa teori tentang itu, tetapi belum ada yang konklusif.
Beban Kerja Paging
Rata-rata runtime dari kueri paging juga tampaknya telah dipengaruhi secara signifikan oleh konkurensi dibandingkan dengan pengujian saya yang berjalan secara terpisah. Berikut adalah hasilnya (klik untuk memperbesar):
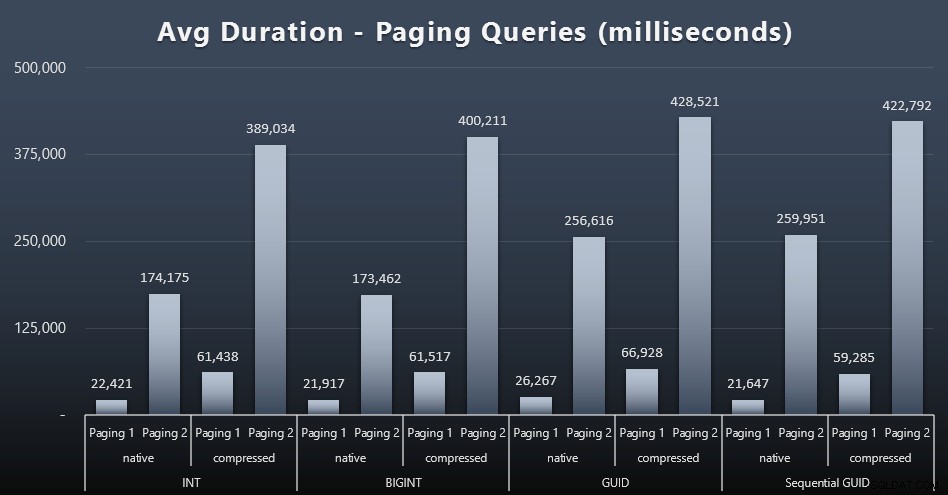
(Halaman 1 =pesanan berdasarkan ID Pelanggan, Halaman 2 =pesanan berdasarkan Nama Belakang, Nama Depan.)
Kami melihat bahwa untuk Paging 1 (pesan berdasarkan ID Pelanggan) dan Paging 2 (urutkan berdasarkan nama), ada dampak signifikan pada waktu proses karena kompresi (hingga ~700%). Kedua GUID tampaknya menjadi kuda paling lambat dalam lomba ini, dengan NEWID() tampil paling buruk.
Perbarui Beban Kerja
Pembaruan tunggal cukup cepat bahkan di bawah konkurensi yang berat, tetapi masih ada beberapa perbedaan mencolok karena kompresi, dan bahkan beberapa perbedaan mengejutkan di seluruh tipe data (klik untuk memperbesar):
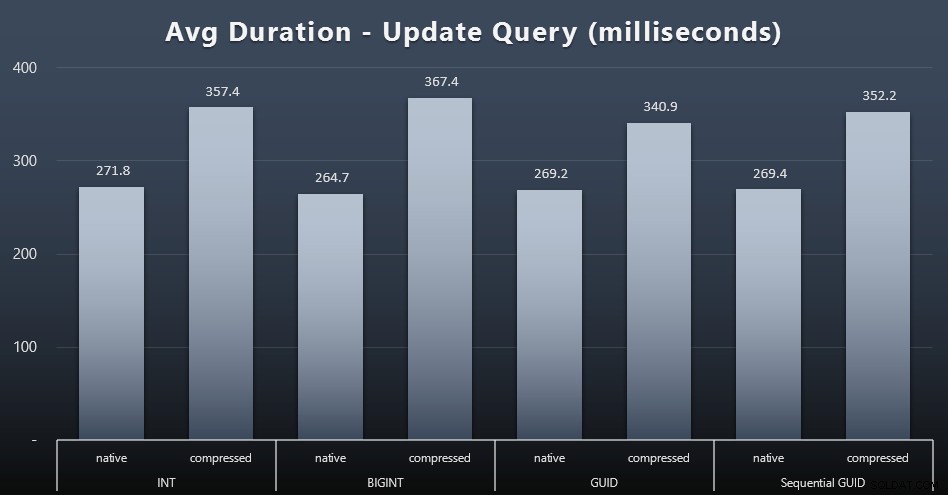
Terutama, pembaruan pada baris yang berisi nilai GUID sebenarnya lebih cepat daripada pembaruan yang mengandung INT/BIGINT, saat kompresi sedang digunakan. Dengan penyimpanan asli, perbedaannya tidak terlalu mencolok (tetapi INT masih kalah di sana).
Statistik Pemicu
Berikut adalah runtime rata-rata dan maksimum untuk pemicu sederhana dalam setiap kasus (klik untuk memperbesar):
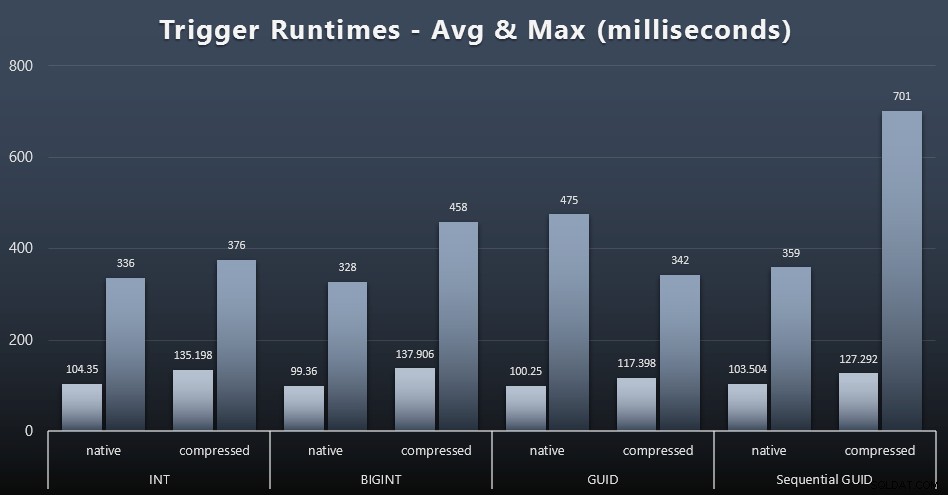
Kompresi tampaknya memiliki dampak yang jauh lebih besar di sini daripada pilihan tipe data (meskipun ini kemungkinan akan lebih terasa jika beberapa beban kerja pembaruan saya telah memperbarui banyak baris alih-alih hanya terdiri dari pencarian satu baris). Maksimum untuk GUID sekuensial jelas merupakan outlier dari beberapa jenis yang tidak saya selidiki (Anda dapat mengatakan itu tidak signifikan berdasarkan rata-rata yang masih sejalan di seluruh papan).
Apa yang menunggu pertanyaan ini?
Setelah setiap beban kerja, saya juga melihat waktu tunggu teratas pada sistem, membuang antrian/timer menunggu yang jelas (seperti yang dijelaskan oleh Paul Randal), dan aktivitas yang tidak relevan dari perangkat lunak pemantauan (seperti TRACEWRITE ). Berikut adalah 3 penantian teratas dalam setiap kasus (klik untuk memperbesar):
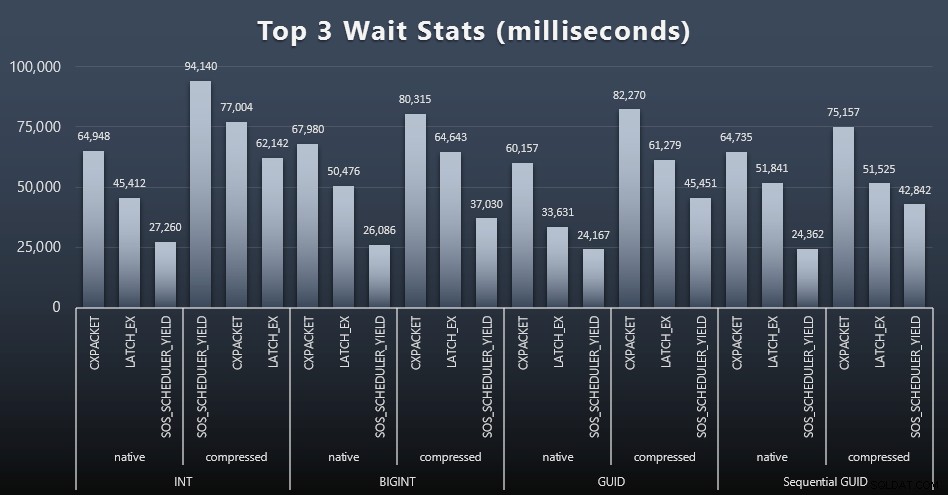
Dalam kebanyakan kasus, menunggu adalah CXPACKET, lalu LATCH_EX, lalu SOS_SCHEDULER_YIELD. Namun, dalam kasus penggunaan yang melibatkan bilangan bulat dan kompresi, SOS_SCHEDULER_YIELD mengambil alih, yang menyiratkan kepada saya beberapa inefisiensi dalam algoritme untuk mengompresi bilangan bulat (yang mungkin sama sekali tidak terkait dengan algoritme yang digunakan untuk memeras BIGINT menjadi INT). Saya tidak menyelidiki ini lebih lanjut, saya juga tidak menemukan pembenaran untuk melacak waktu tunggu per kueri individual.
Ruang Disk / Fragmentasi
Meskipun saya cenderung setuju bahwa ini bukan tentang ruang disk, ini masih merupakan metrik yang layak untuk disajikan. Bahkan dalam kasus yang sangat sederhana ini di mana hanya ada satu tabel dan kuncinya tidak ada di semua tabel terkait lainnya (yang pasti akan ada dalam aplikasi nyata), perbedaannya signifikan. Pertama kita lihat saja reserved kolom dari sp_spaceused (klik untuk memperbesar):
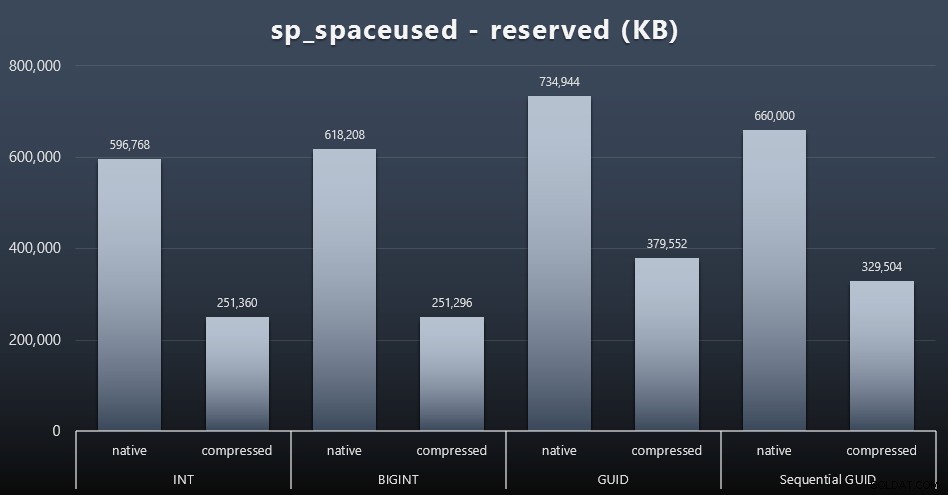
Di sini, BIGINT hanya mengambil sedikit lebih banyak ruang daripada INT, dan GUID (seperti yang diharapkan) memiliki lompatan yang lebih besar. GUID berurutan memiliki peningkatan yang kurang signifikan dalam ruang yang digunakan, dan dikompresi jauh lebih baik daripada GUID tradisional juga. Sekali lagi, tidak ada kejutan di sini – GUID lebih besar dari angka, titik. Sekarang, pendukung GUID mungkin berpendapat bahwa harga yang Anda bayar dalam hal ruang disk tidak banyak (18% lebih BIGINT tanpa kompresi, sekitar 50% dengan kompresi). Tetapi ingat bahwa ini adalah satu tabel dengan 1 juta baris. Bayangkan bagaimana hal itu akan mengekstrapolasi ketika Anda memiliki 10 juta pelanggan dan banyak dari mereka memiliki 10, 30, atau 500 pesanan – kunci tersebut dapat diulang di selusin tabel lain, dan menggunakan ruang ekstra yang sama di setiap baris.
Ketika saya melihat fragmentasi setelah setiap beban kerja (ingat, tidak ada pemeliharaan indeks yang dilakukan) menggunakan kueri ini:
PILIH index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Hasilnya dibuat untuk visual yang jauh lebih menarik; semua indeks non-clustered terfragmentasi lebih dari 99%. Namun, indeks berkerumun sangat terfragmentasi, atau tidak terfragmentasi sama sekali (klik untuk memperbesar):
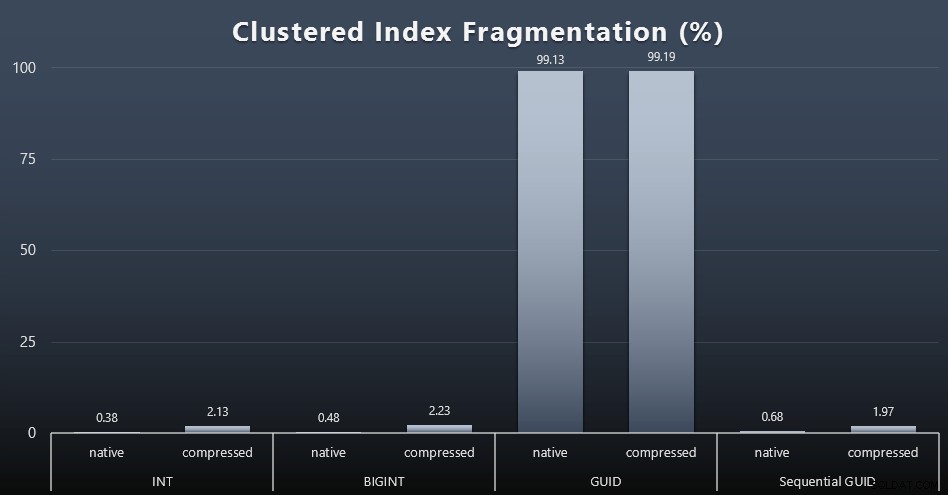
Fragmentasi adalah metrik lain yang sering kali kurang berarti ketika kita berbicara tentang SSD, tetapi penting untuk dicatat semua sama, karena tidak semua sistem mampu untuk tidak menyadari dampak fragmentasi pada pola I/O. Saya percaya bahwa menggunakan GUID non-sekuensial, pada sistem yang lebih terikat I/O, dampak dari fragmentasi ini saja akan diperkuat secara drastis pada sebagian besar metrik lain dalam pengujian ini.
Penggunaan Buffer Pool
Di sinilah menjadi bijaksana tentang jumlah ruang disk yang digunakan oleh tabel Anda benar-benar terbayar – semakin besar tabel Anda, semakin banyak ruang yang mereka ambil di kumpulan buffer. Memindahkan data masuk dan keluar dari kumpulan buffer itu mahal, dan sekali lagi, ini adalah kasus yang sangat sederhana di mana pengujian dijalankan secara terpisah dan tidak ada aplikasi dan database lain pada instans yang bersaing untuk mendapatkan memori berharga.
Ini adalah ukuran sederhana dari kueri berikut di akhir setiap beban kerja:
PILIH total_kb FROM sys.dm_os_memory_broker_clerks WHERE officer_name =N'Buffer Pool';
Hasil (klik untuk memperbesar):
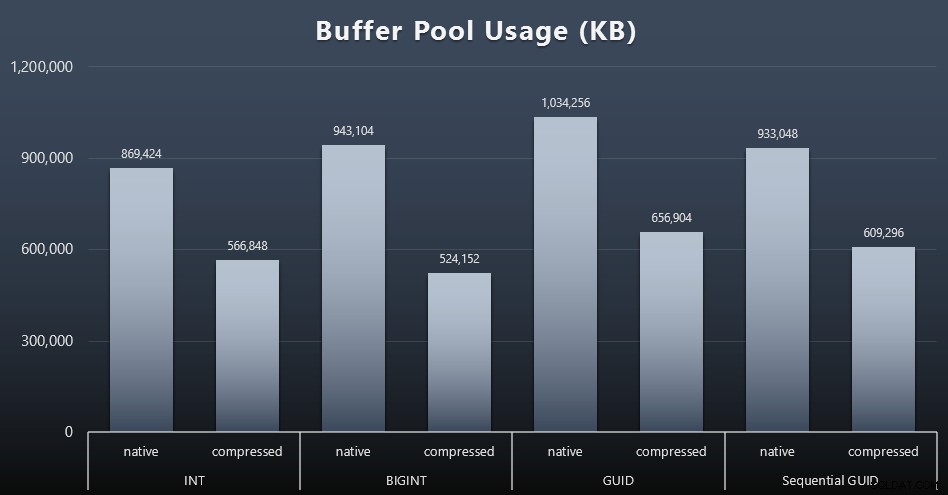
Sementara sebagian besar grafik ini sama sekali tidak mengejutkan – GUID membutuhkan lebih banyak ruang daripada BIGINT, BIGINT lebih dari INT – saya merasa menarik bahwa GUID Sequential membutuhkan lebih sedikit ruang daripada BIGINT, bahkan tanpa kompresi. Saya telah membuat catatan untuk melakukan beberapa forensik tingkat halaman untuk menentukan jenis efisiensi yang terjadi di sini.
Penggunaan tempdb
Saya tidak yakin apa yang saya harapkan di sini, tetapi setelah setiap beban kerja, saya mengumpulkan konten dari tiga DMV penggunaan ruang terkait tempdb, sys.dm_db_file|session|task_space_usage . Satu-satunya yang tampaknya menunjukkan volatilitas berdasarkan tipe data adalah sys.dm_db_file_space_usage extent_allocation_page_count . Ini menunjukkan bahwa – setidaknya dalam konfigurasi saya dan beban kerja khusus ini – GUID akan membuat tempdb melalui latihan yang sedikit lebih menyeluruh (klik untuk memperbesar):
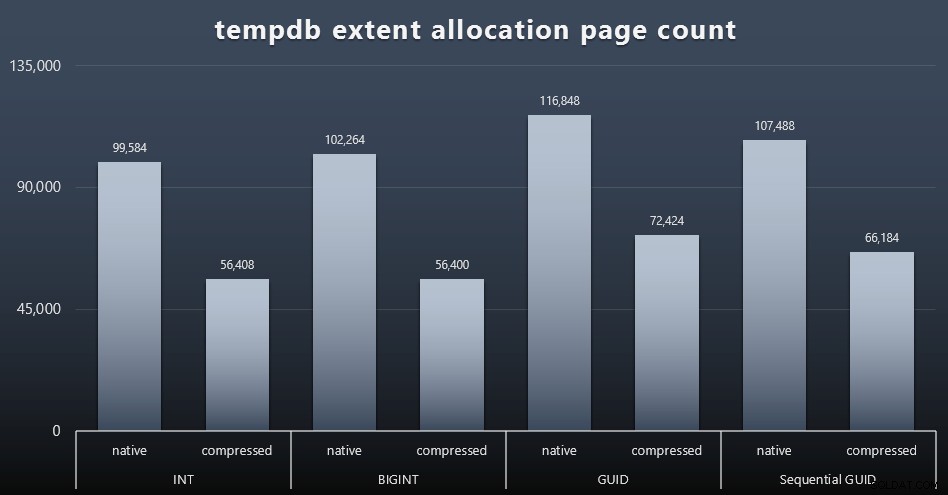
Pemisahan Halaman "Buruk"
Salah satu hal yang ingin saya ukur adalah dampak pada pemisahan halaman – bukan pemisahan halaman normal (saat Anda menambahkan halaman baru) tetapi ketika Anda benar-benar harus memindahkan data antar halaman untuk memberi ruang bagi lebih banyak baris. Jonathan Kehayias membicarakan hal ini secara lebih mendalam dalam posting blognya, "Melacak Pemisahan Halaman Bermasalah di SQL Server 2012 Extended Events – Tidak Benar-Benar Saat Ini!," yang juga menyediakan dasar untuk sesi Extended Events yang saya gunakan untuk menangkap data:
BUAT SESI ACARA [BadPageSplits] PADA SERVER ADD EVENT sqlserver.transaction_log (WHERE operation =11 DAN database_id =10) ADD TARGET package0.histogram ( SET filtering_event_name ='sqlserver.transaction_log', source_type =0, source_id'alloc' ); SESI ACARA GOALTER [BadPageSplits] PADA NEGARA SERVER =MULAI;PERGI
Dan kueri yang saya gunakan untuk merencanakannya:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'besar') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER GABUNG sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE 'target_Bas. ='histogram' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) SEBAGAI tabINNER GABUNG sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER GABUNG sys.partitions AS p container_id =p.partition_idINNER GABUNG sys.tables AS t PADA p.object_id =t.[object_id]GROUP BY t.name; Dan inilah hasilnya (klik untuk memperbesar):
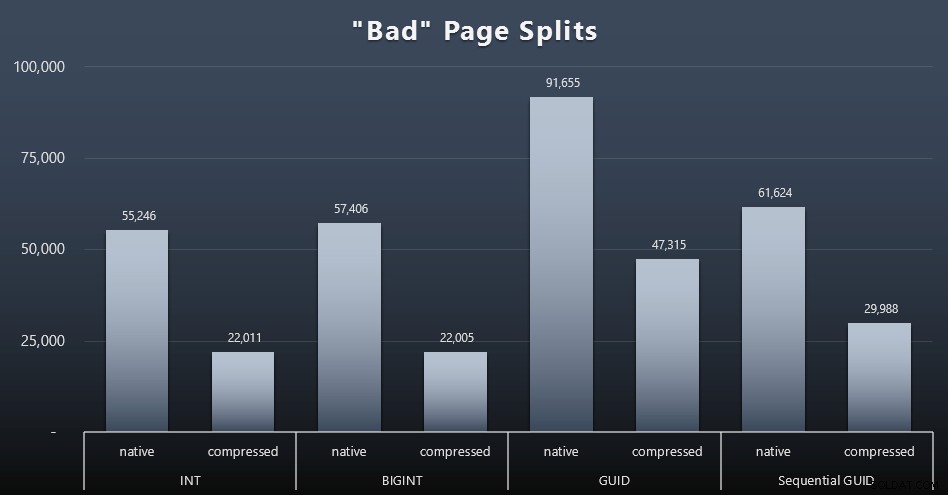
Meskipun saya telah mencatat bahwa dalam skenario saya (di mana saya menjalankan SSD cepat) perbedaan yang tak terbantahkan dalam aktivitas I/O tidak secara langsung memengaruhi waktu berjalan secara keseluruhan, ini masih merupakan metrik yang ingin Anda pertimbangkan – terutama jika Anda tidak memiliki SSD atau jika beban kerja Anda sudah terikat I/O.
Kesimpulan
Sementara tes ini telah membuka mata saya sedikit lebih lebar tentang seberapa lama persepsi saya telah diubah oleh perangkat keras yang lebih modern, saya masih cukup kukuh terhadap pemborosan ruang pada disk atau memori. Sementara saya mencoba untuk menunjukkan beberapa keseimbangan dan membiarkan GUID bersinar, ada sangat sedikit di sini dari perspektif kinerja untuk mendukung peralihan dari INT/BIGINT ke salah satu bentuk UNIQUEIDENTIFIER – kecuali jika Anda memerlukannya untuk alasan lain yang kurang nyata (seperti membuat kunci di aplikasi atau mempertahankan nilai kunci unik di seluruh sistem yang berbeda). Ringkasan singkat, menunjukkan bahwa NEWID() adalah pilihan terburuk di banyak metrik yang memiliki perbedaan substansial (dan dalam sebagian besar kasus tersebut, NEWSEQUENTIALID() berada di urutan kedua)):
Tabel 2:Pecundang Terbesar
Jangan ragu untuk menguji hal-hal ini sendiri; Saya dapat merakit skrip lengkap saya jika Anda ingin menjalankannya di lingkungan Anda sendiri. Tujuan singkat dari keseluruhan postingan ini cukup sederhana:ada banyak metrik penting yang perlu dipertimbangkan selain dari dampak yang dapat diprediksi pada ruang disk, sehingga tidak boleh digunakan sendiri sebagai argumen di kedua arah.
Sekarang, saya tidak ingin pemikiran ini dibatasi pada kunci saja. Ini benar-benar harus dipikirkan kapan pun pilihan tipe data dibuat. Saya melihat datetime sering dipilih, misalnya, ketika hanya date atau smalldatetime dibutuhkan. Pada tabel transaksional, ini juga dapat menghasilkan banyak ruang disk yang terbuang, dan ini juga mengalir ke beberapa sumber daya lainnya.
Dalam pengujian di masa mendatang, saya ingin membandingkan hasil untuk tabel yang jauh lebih besar (> 2 miliar baris). Saya dapat mensimulasikan ini dengan INT dengan menyetel benih identitas ke -2 miliar, memungkinkan ~4 miliar baris. Dan saya ingin perbandingan beban kerja dan ruang disk/jejak memori melibatkan lebih dari satu tabel, karena salah satu keuntungan dari kunci kurus adalah ketika kunci itu diwakili dalam lusinan tabel terkait. Saya memantau peristiwa autogrow, tetapi tidak ada, karena basis data berukuran cukup besar untuk mengakomodasi pertumbuhan, dan saya tidak berpikir untuk mengukur penggunaan log aktual di dalam file log yang ada, jadi saya ingin menguji lagi dengan default untuk ukuran log dan pertumbuhan otomatis, dan kali ini mengukur DBCC SQLPERF(LOGSPACE); . Juga akan menarik untuk membangun kembali waktu dan mengukur penggunaan log sebagai hasil dari operasi tersebut juga. Terakhir, saya ingin menjadikan I/O faktor yang lebih relevan dengan mencari server dengan hard disk mekanis – saya tahu ada banyak di luar sana, tetapi di beberapa toko mereka cukup langka.



