Dalam posting terakhir saya, saya menunjukkan beberapa pendekatan yang efisien untuk penggabungan yang dikelompokkan. Kali ini, saya ingin berbicara tentang beberapa aspek tambahan dari masalah ini yang dapat kita selesaikan dengan mudah dengan FOR XML PATH pendekatan:memesan daftar, dan menghapus duplikat.
Ada beberapa cara yang saya lihat orang-orang menginginkan daftar yang dipisahkan koma untuk diurutkan. Terkadang mereka ingin item dalam daftar diurutkan menurut abjad; Saya sudah menunjukkannya di posting saya sebelumnya. Tapi terkadang mereka ingin itu diurutkan berdasarkan beberapa atribut lain yang sebenarnya tidak diperkenalkan di output; misalnya, mungkin saya ingin mengurutkan daftar berdasarkan item terbaru terlebih dahulu. Mari kita ambil contoh sederhana, di mana kita memiliki tabel Karyawan dan tabel CoffeeOrders. Mari kita isi pesanan satu orang selama beberapa hari:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Jika kita menggunakan pendekatan yang ada tanpa menentukan ORDER BY , kami mendapatkan urutan arbitrer (dalam hal ini, kemungkinan besar Anda akan melihat baris dalam urutan yang dimasukkan, tetapi jangan bergantung padanya dengan kumpulan data yang lebih besar, lebih banyak indeks, dll.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Hasil (ingat, Anda mungkin mendapatkan hasil *berbeda* kecuali Anda menentukan ORDER BY ):
Jack | Double besar, Double sedang, Latte Vanilla Besar, Double sedang
Jika kita ingin mengurutkan daftar berdasarkan abjad, caranya sederhana; kita tinggal menambahkan ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Hasil:
Nama | PesananJack | Double double besar, Latte Vanilla Besar, Double sedang, Double sedang, Double sedang
Kami juga dapat memesan berdasarkan kolom yang tidak muncul di kumpulan hasil; misalnya kita bisa memesan kopi berdasarkan pesanan kopi terbaru dulu:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Hasil:
Nama | PesananJack | Double sedang, Latte Vanilla Besar, Double sedang, Double besar, Double besar
Hal lain yang sering ingin kita lakukan adalah menghapus duplikat; lagi pula, ada sedikit alasan untuk melihat "Medium double double" dua kali. Kita bisa menghilangkannya dengan menggunakan GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Sekarang, *kebetulan* ini mengurutkan output berdasarkan abjad, tetapi sekali lagi Anda tidak dapat mengandalkan ini:
Nama | PesananJack | Double double besar, Large Vanilla Latte, Double double sedang
Jika Anda ingin menjamin bahwa memesan dengan cara ini, Anda cukup menambahkan ORDER BY lagi:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Hasilnya sama (tapi saya ulangi, ini hanya kebetulan dalam kasus ini; jika Anda menginginkan pesanan ini, selalu katakan demikian):
Nama | PesananJack | Double double besar, Large Vanilla Latte, Double double sedang
Tetapi bagaimana jika kita ingin menghilangkan duplikat *dan* mengurutkan daftar berdasarkan pesanan kopi terbaru terlebih dahulu? Kecenderungan pertama Anda mungkin untuk mempertahankan GROUP BY dan cukup ubah ORDER BY , seperti ini:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Itu tidak akan berhasil, karena OrderDate tidak dikelompokkan atau dikumpulkan sebagai bagian dari kueri:
Kolom "dbo.CoffeeOrders.OrderDate" tidak valid dalam klausa ORDER BY karena tidak terkandung dalam fungsi agregat atau klausa GROUP BY.
Solusinya, yang memang membuat kueri sedikit lebih buruk, adalah mengelompokkan pesanan secara terpisah terlebih dahulu, lalu hanya mengambil baris dengan tanggal maksimum untuk pesanan kopi tersebut per karyawan:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Hasil:
Nama | PesananJack | Double double sedang, Latte Vanilla Besar, Double double besar
Ini menyelesaikan kedua tujuan kami:kami telah menghilangkan duplikat, dan kami telah mengurutkan daftar dengan sesuatu yang sebenarnya tidak ada dalam daftar.
Kinerja
Anda mungkin bertanya-tanya seberapa buruk kinerja metode ini terhadap kumpulan data yang lebih kuat. Saya akan mengisi tabel kami dengan 100.000 baris, melihat bagaimana mereka melakukannya tanpa indeks tambahan, dan kemudian menjalankan kueri yang sama lagi dengan sedikit penyetelan indeks untuk mendukung kueri kami. Jadi pertama, dapatkan 100.000 baris yang tersebar di 1.000 karyawan:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Sekarang mari kita jalankan setiap kueri kita dua kali, dan lihat seperti apa waktunya pada percobaan kedua (kita akan mengambil lompatan keyakinan di sini, dan berasumsi bahwa – di dunia yang ideal – kita akan bekerja dengan cache prima ). Saya menjalankan ini di SQL Sentry Plan Explorer, karena ini adalah cara termudah yang saya ketahui dari waktu ke waktu dan membandingkan sekelompok kueri individual:
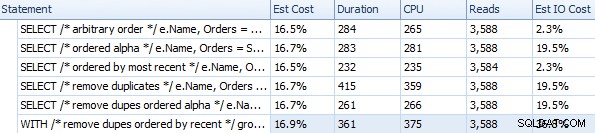 Durasi dan metrik waktu proses lainnya untuk pendekatan FOR XML PATH yang berbeda
Durasi dan metrik waktu proses lainnya untuk pendekatan FOR XML PATH yang berbeda
Pengaturan waktu ini (durasi dalam milidetik) sebenarnya tidak terlalu buruk sama sekali IMHO, ketika Anda memikirkan apa yang sebenarnya dilakukan di sini. Rencana yang paling rumit, setidaknya secara visual, tampaknya adalah rencana tempat kami menghapus duplikat dan mengurutkan berdasarkan urutan terbaru:
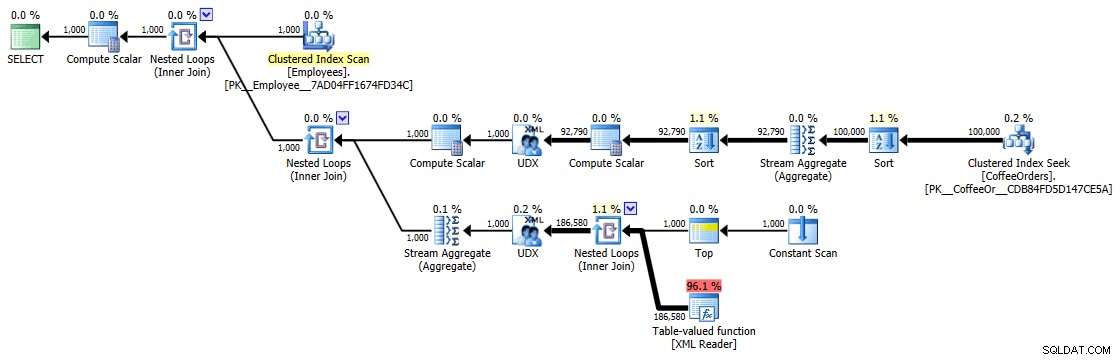 Rencana eksekusi untuk kueri yang dikelompokkan dan diurutkan
Rencana eksekusi untuk kueri yang dikelompokkan dan diurutkan
Tetapi bahkan operator yang paling mahal di sini – fungsi bernilai tabel XML – tampaknya semuanya adalah CPU (walaupun saya akan dengan bebas mengakui bahwa saya tidak yakin berapa banyak pekerjaan sebenarnya yang diekspos dalam detail rencana kueri):
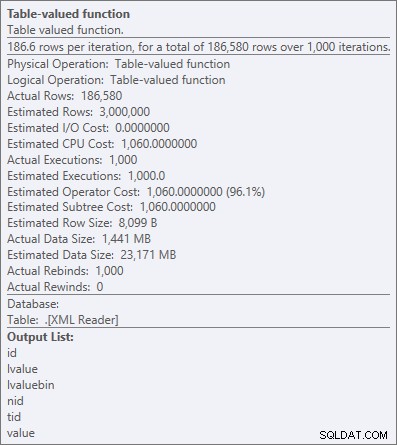 Properti operator untuk fungsi bernilai tabel XML
Properti operator untuk fungsi bernilai tabel XML
"Semua CPU" biasanya baik-baik saja, karena sebagian besar sistem terikat I/O dan/atau terikat memori, bukan terikat CPU. Seperti yang sering saya katakan, di sebagian besar sistem saya akan menukar beberapa ruang kepala CPU saya dengan memori atau disk setiap hari dalam seminggu (salah satu alasan saya menyukai OPTION (RECOMPILE) sebagai solusi untuk masalah sniffing parameter yang meluas).
Karena itu, saya sangat menganjurkan Anda untuk menguji pendekatan ini terhadap hasil serupa yang bisa Anda dapatkan dari pendekatan CLR GROUP_CONCAT di CodePlex, serta melakukan agregasi dan pengurutan pada tingkat presentasi (terutama jika Anda menyimpan data yang dinormalisasi dalam beberapa jenis lapisan cache).