Saat pengguna meminta data dari suatu sistem, mereka biasanya suka melihatnya dalam urutan tertentu… bahkan ketika mereka mengembalikan ribuan baris. Seperti yang diketahui oleh banyak DBA dan pengembang, ORDER BY dapat memasukkan malapetaka ke dalam rencana kueri, karena memerlukan data untuk diurutkan. Ini terkadang memerlukan operator SORT sebagai bagian dari eksekusi kueri, yang dapat menjadi operasi yang mahal, terutama jika perkiraan tidak sesuai dan tumpah ke disk. Di dunia yang ideal, data sudah diurutkan berkat indeks (indeks dan pengurutan sangat saling melengkapi). Kami sering berbicara tentang membuat indeks penutup untuk memenuhi kueri – sehingga pengoptimal tidak harus kembali ke tabel dasar atau indeks berkerumun untuk mendapatkan kolom tambahan. Dan Anda mungkin pernah mendengar orang mengatakan bahwa urutan kolom dalam indeks itu penting. Pernahkah Anda mempertimbangkan bagaimana hal itu memengaruhi operasi SORT Anda?
Memeriksa ORDER BY dan Sorts
Kita akan mulai dengan salinan baru database AdventureWorks2014 pada contoh SQL Server 2014 (versi 12.0.2000). Jika kita menjalankan kueri SELECT sederhana terhadap Sales.SalesOrderHeader tanpa ORDER BY, kita akan melihat Pemindaian Indeks Clustered yang lama (menggunakan SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Kueri tanpa ORDER BY, pemindaian indeks berkerumun
Kueri tanpa ORDER BY, pemindaian indeks berkerumun
Sekarang mari tambahkan ORDER BY untuk melihat bagaimana rencana berubah:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
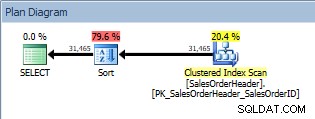 Kueri dengan ORDER BY, pemindaian indeks berkerumun, dan semacamnya
Kueri dengan ORDER BY, pemindaian indeks berkerumun, dan semacamnya
Selain Pemindaian Indeks Berkelompok, kami sekarang memiliki Sortir yang diperkenalkan oleh pengoptimal, dan perkiraan biayanya jauh lebih tinggi daripada biaya pemindaian. Sekarang, perkiraan biaya hanyalah perkiraan, dan kami tidak dapat mengatakan dengan pasti di sini bahwa Pengurutan mengambil 79,6% dari biaya kueri. Untuk benar-benar memahami betapa mahalnya Penyortiran, kita juga perlu melihat IO STATISTICS, yang melampaui target hari ini.
Sekarang jika ini adalah kueri yang sering dijalankan di lingkungan Anda, Anda mungkin akan mempertimbangkan untuk menambahkan indeks untuk mendukungnya. Dalam hal ini, tidak ada klausa WHERE, kami hanya mengambil empat kolom, dan mengurutkan salah satunya. Upaya logis pertama pada indeks adalah:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Kami akan menjalankan kembali kueri kami setelah menambahkan indeks yang memiliki semua kolom yang kami inginkan, dan ingat bahwa indeks telah melakukan pekerjaan untuk menyortir data. Kami sekarang melihat Pemindaian Indeks terhadap indeks nonclustered baru kami:
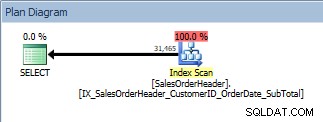 Kueri dengan ORDER BY, indeks nonclustered baru dipindai
Kueri dengan ORDER BY, indeks nonclustered baru dipindai
Ini adalah kabar baik. Tetapi apa yang terjadi jika seseorang mengubah kueri itu – baik karena pengguna dapat menentukan kolom apa yang ingin mereka pesan, atau karena perubahan diminta dari pengembang? Misalnya, mungkin pengguna ingin melihat CustomerID dan SalesOrderID dalam urutan menurun:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
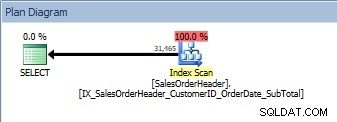 Kueri dengan dua kolom dalam ORDER BY, indeks baru yang tidak berkerumun dipindai
Kueri dengan dua kolom dalam ORDER BY, indeks baru yang tidak berkerumun dipindai
Kami memiliki rencana yang sama; tidak ada operator Sortir yang ditambahkan. Jika kita melihat indeks menggunakan sp_helpindex Kimberly Tripp (beberapa kolom diciutkan untuk menghemat ruang), kita dapat melihat mengapa paket tidak berubah:
 Keluaran dari sp_helpindex
Keluaran dari sp_helpindex
Kolom kunci untuk indeks adalah CustomerID, tetapi karena SalesOrderID adalah kolom kunci untuk indeks berkerumun, itu adalah bagian dari kunci indeks juga, sehingga data diurutkan berdasarkan CustomerID, lalu SalesOrderID. Kueri meminta data yang diurutkan berdasarkan dua kolom tersebut, dalam urutan menurun. Indeks dibuat dengan kedua kolom naik, tetapi karena ini adalah daftar yang ditautkan ganda, indeks dapat dibaca mundur. Anda dapat melihat ini di panel Properties di Management Studio untuk operator pemindaian indeks nonclustered:
 Panel properti dari pemindaian indeks nonclustered, menunjukkan bahwa itu terbalik
Panel properti dari pemindaian indeks nonclustered, menunjukkan bahwa itu terbalik
Bagus, tidak ada masalah dengan kueri itu…tapi bagaimana dengan yang ini:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
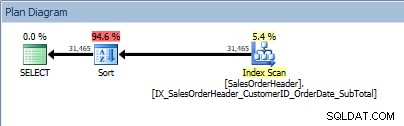 Kueri dengan dua kolom di ORDER BY, dan semacam ditambahkan
Kueri dengan dua kolom di ORDER BY, dan semacam ditambahkan
Operator SORT kami muncul kembali, karena data yang berasal dari indeks tidak diurutkan sesuai urutan yang diminta. Kita akan melihat perilaku yang sama jika kita mengurutkan pada salah satu kolom yang disertakan:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
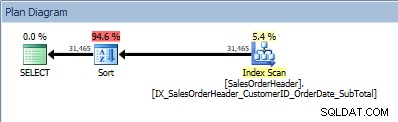 Kueri dengan dua kolom di ORDER BY, dan semacam ditambahkan
Kueri dengan dua kolom di ORDER BY, dan semacam ditambahkan
Apa yang terjadi jika kita (akhirnya) menambahkan predikat, dan sedikit mengubah ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
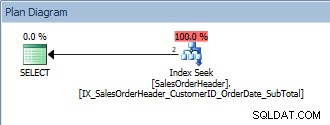 Kueri dengan predikat tunggal dan ORDER BY
Kueri dengan predikat tunggal dan ORDER BY
Kueri ini tidak masalah karena sekali lagi, SalesOrderID adalah bagian dari kunci indeks. Untuk CustomerID yang satu ini, datanya sudah dipesan oleh SalesOrderID. Bagaimana jika kita menanyakan rentang ID Pelanggan, yang diurutkan berdasarkan SalesOrderIDs?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
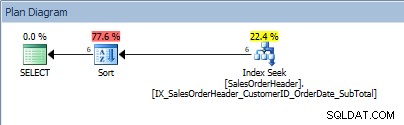 Kueri dengan rentang nilai dalam predikat dan ORDER BY
Kueri dengan rentang nilai dalam predikat dan ORDER BY
Tikus, SORT kami kembali. Fakta bahwa data diurutkan oleh CustomerID hanya membantu dalam mencari indeks untuk menemukan rentang nilai tersebut; untuk ORDER BY SalesOrderID, pengoptimal harus menyisipkan Sortir untuk menempatkan data dalam urutan yang diminta.
Sekarang pada titik ini, Anda mungkin bertanya-tanya mengapa saya terpaku pada operator Sortir yang muncul dalam rencana kueri. Itu karena mahal. Ini bisa mahal dalam hal sumber daya (memori, IO) dan/atau durasi.
Durasi kueri dapat dipengaruhi oleh Sortir karena merupakan operasi stop-and-go. Seluruh rangkaian data harus disortir sebelum operasi berikutnya dalam rencana dapat terjadi. Jika hanya beberapa baris data yang harus dipesan, itu bukan masalah besar. Jika ribuan atau jutaan baris? Sekarang kami menunggu.
Selain durasi kueri secara keseluruhan, kita juga harus memikirkan penggunaan sumber daya. Mari kita ambil 31.465 baris yang telah kita kerjakan dan masukkan ke dalam variabel tabel, lalu jalankan kueri awal itu dengan ORDER BY di CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
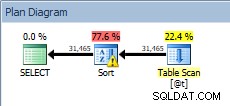 Kueri terhadap variabel tabel, dengan pengurutan
Kueri terhadap variabel tabel, dengan pengurutan
SORT kami kembali, dan kali ini ada peringatan (perhatikan segitiga kuning dengan tanda seru). Peringatan tidak baik. Jika kita melihat Properties semacam itu, kita dapat melihat peringatan, "Operator menggunakan tempdb untuk menumpahkan data selama eksekusi dengan level tumpahan 1":
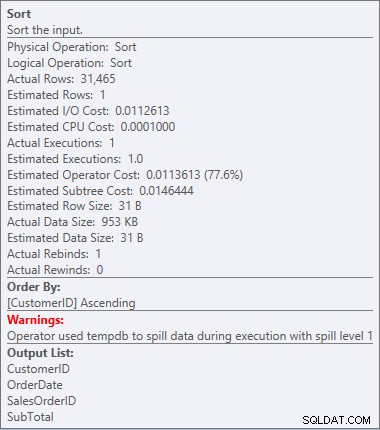 Urutkan peringatan
Urutkan peringatan
Ini bukan sesuatu yang ingin saya lihat dalam rencana. Pengoptimal membuat perkiraan berapa banyak ruang yang dibutuhkan dalam memori untuk menyortir data, dan itu meminta memori itu. Tapi ketika itu benar-benar memiliki semua data dan pergi untuk menyortirnya, mesin menyadari tidak ada cukup memori (pengoptimal meminta terlalu sedikit!), sehingga operasi Sortir tumpah. Dalam beberapa kasus, ini dapat tumpah ke disk, yang berarti membaca dan menulis – yang lambat. Kami tidak hanya menunggu untuk mendapatkan data secara berurutan, bahkan lebih lambat karena kami tidak dapat melakukan semuanya di memori. Mengapa pengoptimal tidak meminta cukup memori? Itu memiliki perkiraan yang buruk tentang data yang diperlukan untuk menyortir:
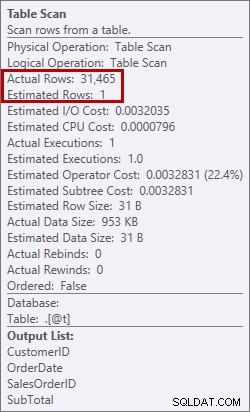 Perkiraan 1 baris versus aktual 31.465 baris
Perkiraan 1 baris versus aktual 31.465 baris
Dalam hal ini saya memaksakan perkiraan buruk dengan menggunakan variabel tabel. Ada masalah yang diketahui dengan perkiraan statistik dan variabel tabel (Aaron Bertrand memiliki posting bagus tentang opsi untuk mencoba mengatasi ini), dan di sini, pengoptimal percaya hanya 1 baris yang akan dikembalikan dari pemindaian tabel, bukan 31.465.
Opsi
Jadi apa yang dapat Anda, sebagai DBA atau pengembang, lakukan untuk menghindari SORT dalam rencana kueri Anda? Jawaban cepatnya adalah, "Jangan memesan data Anda." Tapi itu tidak selalu realistis. Dalam beberapa kasus, Anda dapat memindahkan pengurutan tersebut ke klien, atau ke lapisan aplikasi – tetapi pengguna masih harus menunggu untuk mengurutkan data di itu lapisan. Dalam situasi di mana Anda tidak dapat mengubah cara kerja aplikasi, Anda dapat memulai dengan melihat indeks Anda.
Jika Anda mendukung aplikasi yang memungkinkan pengguna menjalankan kueri ad-hoc, atau mengubah urutan pengurutan sehingga mereka dapat melihat data yang diurutkan sesuai keinginan… jangan berhenti membaca ya!). Anda tidak dapat mengindeks untuk setiap opsi. Ini tidak efisien dan Anda akan menciptakan lebih banyak masalah daripada yang Anda pecahkan. Taruhan terbaik Anda di sini adalah berbicara dengan pengguna (saya tahu, terkadang menakutkan untuk meninggalkan sudut hutan Anda, tetapi cobalah). Untuk kueri yang paling sering dijalankan pengguna, cari tahu bagaimana biasanya mereka ingin melihat data. Ya, Anda juga bisa mendapatkan ini dari cache paket – Anda dapat mengambil kueri dan paket hingga Anda puas melihat apa yang mereka lakukan. Tapi lebih cepat untuk berbicara dengan pengguna. Manfaat tambahannya adalah Anda dapat menjelaskan mengapa Anda bertanya, dan mengapa ide untuk "mengurutkan semua kolom karena saya bisa" bukanlah ide yang bagus. Mengetahui adalah setengah dari pertempuran. Jika Anda dapat meluangkan waktu untuk mendidik pengguna yang kuat, dan pengguna yang melatih orang baru, Anda mungkin dapat melakukan beberapa hal yang baik.
Jika Anda mendukung aplikasi dengan opsi ORDER BY terbatas, Anda dapat melakukan analisis nyata. Tinjau variasi ORDER BY yang ada, tentukan kombinasi mana yang paling sering dieksekusi, dan indeks untuk mendukung kueri tersebut. Anda mungkin tidak akan memukul setiap orang, tetapi Anda masih bisa membuat dampak. Anda dapat mengambil satu langkah lebih jauh dengan berbicara dengan pengembang Anda dan mendidik mereka tentang masalah tersebut, dan bagaimana mengatasinya.
Terakhir, saat Anda melihat rencana kueri dengan operasi SORT, jangan hanya fokus pada penghapusan Sort. Lihat di mana Sortir terjadi dalam rencana. Jika itu terjadi di sebelah kiri rencana, dan biasanya beberapa baris, mungkin ada area lain dengan faktor peningkatan yang lebih besar untuk difokuskan. Pengurutan di sebelah kiri adalah pola yang kami fokuskan hari ini, tetapi Pengurutan tidak selalu terjadi karena ORDER BY. Jika Anda melihat Sortir di paling kanan rencana, dan ada banyak baris yang bergerak melalui bagian rencana itu, Anda tahu bahwa Anda telah menemukan tempat yang baik untuk mulai menyetel.



