Pagination adalah kasus penggunaan umum di seluruh klien dan aplikasi web di mana saja. Google menampilkan 10 hasil sekaligus, bank online Anda mungkin menampilkan 20 tagihan per halaman, dan perangkat lunak pelacakan bug dan kontrol sumber mungkin menampilkan 50 item di layar.
Saya ingin melihat pendekatan pagination umum pada SQL Server 2012 – OFFSET / FETCH (standar yang setara dengan klausa LIMIT prioprietary MySQL) – dan menyarankan variasi yang akan menghasilkan kinerja paging yang lebih linier di seluruh rangkaian, alih-alih hanya optimal pada awalnya. Sayangnya, hanya itulah yang akan diuji oleh banyak toko.
Apa itu pagination di SQL Server?
Berdasarkan pengindeksan tabel, kolom yang dibutuhkan, dan metode pengurutan yang dipilih, pagination dapat relatif tidak menyakitkan. Jika Anda mencari 20 pelanggan "pertama" dan indeks berkerumun mendukung penyortiran itu (misalnya, indeks berkerumun pada kolom IDENTITAS atau kolom DateCreated), maka kueri akan relatif efisien. Jika Anda perlu mendukung pengurutan yang memerlukan indeks non-cluster, dan terutama jika Anda memiliki kolom yang diperlukan untuk output yang tidak tercakup oleh indeks (apalagi jika tidak ada indeks pendukung), kueri bisa menjadi lebih mahal. Dan bahkan kueri yang sama (dengan parameter @PageNumber yang berbeda) bisa menjadi jauh lebih mahal karena @PageNumber semakin tinggi – karena lebih banyak pembacaan mungkin diperlukan untuk mendapatkan "potongan" data tersebut.
Beberapa orang akan mengatakan bahwa maju menuju akhir set adalah sesuatu yang dapat Anda selesaikan dengan membuang lebih banyak memori pada masalah (sehingga Anda menghilangkan I/O fisik apa pun) dan/atau menggunakan caching tingkat aplikasi (sehingga Anda tidak akan database sama sekali). Mari kita asumsikan untuk tujuan posting ini bahwa lebih banyak memori tidak selalu memungkinkan, karena tidak setiap pelanggan dapat menambahkan RAM ke server yang kehabisan slot memori atau tidak dalam kendali mereka, atau hanya menjentikkan jari mereka dan menyiapkan server yang lebih baru dan lebih besar. untuk pergi. Terutama karena beberapa pelanggan menggunakan Edisi Standar, sehingga dibatasi pada 64GB (SQL Server 2012) atau 128GB (SQL Server 2014), atau menggunakan edisi yang lebih terbatas seperti Express (1GB) atau salah satu dari banyak penawaran cloud.
Jadi saya ingin melihat pendekatan paging umum pada SQL Server 2012 – OFFSET / FETCH – dan menyarankan variasi yang akan menghasilkan kinerja paging yang lebih linier di seluruh rangkaian, daripada hanya optimal di awal. Sayangnya, hanya itulah yang akan diuji oleh banyak toko.
Penyiapan / Contoh Data Pagination
Saya akan meminjam dari pos lain, Kebiasaan buruk :Berfokus hanya pada ruang disk saat memilih kunci, di mana saya mengisi tabel berikut dengan 1.000.000 baris data pelanggan acak (tetapi tidak sepenuhnya realistis):
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Karena saya tahu saya akan menguji I/O di sini, dan akan menguji dari cache hangat dan dingin, saya membuat pengujian setidaknya sedikit lebih adil dengan membangun kembali semua indeks untuk meminimalkan fragmentasi (seperti yang akan dilakukan lebih sedikit mengganggu, tetapi secara teratur, pada sebagian besar sistem sibuk yang melakukan semua jenis pemeliharaan indeks):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Setelah pembangunan kembali, fragmentasi masuk sekarang pada 0,05% – 0,17% untuk semua indeks (tingkat indeks =0), halaman terisi lebih dari 99%, dan jumlah baris / jumlah halaman untuk indeks adalah sebagai berikut:
| Indeks | Jumlah Halaman | Jumlah Baris |
|---|---|---|
| C_PK_Customers_I (indeks berkerumun) | 19.210 | 1.000.000 |
| C_Email_Customers_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (indeks terfilter) | 13.648 | 815.235 |
| C_Name_Customers_I | 16.824 | 1.000.000 |
Indeks, jumlah halaman, jumlah baris
Ini jelas bukan tabel yang sangat lebar, dan kali ini saya tidak menyertakan kompresi. Mungkin saya akan menjelajahi lebih banyak konfigurasi di pengujian mendatang.
Cara membuat halaman kueri SQL secara efektif
Konsep pagination – menampilkan baris hanya kepada pengguna pada satu waktu – lebih mudah untuk divisualisasikan daripada dijelaskan. Pikirkan indeks buku fisik, yang mungkin memiliki beberapa halaman referensi ke poin-poin di dalam buku, tetapi disusun menurut abjad. Untuk kesederhanaan, katakanlah sepuluh item muat di setiap halaman indeks. Ini mungkin terlihat seperti ini:
Sekarang, jika saya sudah membaca halaman 1 dan 2 dari indeks, saya tahu bahwa untuk sampai ke halaman 3, saya harus melewati 2 halaman. Tapi karena saya tahu ada 10 item di setiap halaman, saya juga bisa menganggap ini sebagai melewatkan 2 x 10 item, dan mulai dari item ke-21. Atau, dengan kata lain, saya harus melewatkan item pertama (10*(3-1)). Untuk membuatnya lebih umum, saya dapat mengatakan bahwa untuk memulai pada halaman n, saya harus melewati item pertama (10 * (n-1)). Untuk menuju halaman pertama, saya skip 10*(1-1) item, untuk mengakhiri item 1. Untuk menuju halaman kedua, saya melewatkan 10*(2-1) item, hingga berakhir pada item 11. Dan seterusnya aktif.
Dengan informasi itu, pengguna akan merumuskan kueri paging seperti ini, mengingat klausa OFFSET / FETCH yang ditambahkan di SQL Server 2012 dirancang khusus untuk melewati banyak baris itu:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Seperti yang saya sebutkan di atas, ini berfungsi dengan baik jika ada indeks yang mendukung ORDER BY dan yang mencakup semua kolom dalam klausa SELECT (dan, untuk kueri yang lebih kompleks, klausa WHERE dan JOIN). Namun, biaya pengurutan mungkin berlebihan tanpa indeks pendukung, dan jika kolom keluaran tidak tercakup, Anda akan berakhir dengan sejumlah besar pencarian kunci, atau Anda bahkan mungkin mendapatkan pemindaian tabel dalam beberapa skenario.
Pengurutan praktik terbaik pagination SQL
Mengingat tabel dan indeks di atas, saya ingin menguji skenario ini, di mana kami ingin menampilkan 100 baris per halaman, dan menampilkan semua kolom dalam tabel:
- Bawaan –
ORDER BY CustomerID(indeks berkerumun). Ini adalah pemesanan yang paling nyaman untuk orang-orang database, karena tidak memerlukan penyortiran tambahan, dan semua data dari tabel ini yang mungkin diperlukan untuk tampilan disertakan. Di sisi lain, ini mungkin bukan indeks yang paling efisien untuk digunakan jika Anda menampilkan subset tabel. Pesanan juga mungkin tidak masuk akal bagi pengguna akhir, terutama jika CustomerID adalah pengidentifikasi pengganti tanpa makna eksternal. - Buku telepon –
ORDER BY LastName, FirstName(mendukung indeks non-clustered). Ini adalah urutan paling intuitif bagi pengguna, tetapi akan membutuhkan indeks non-cluster untuk mendukung penyortiran dan cakupan. Tanpa indeks pendukung, seluruh tabel harus dipindai. - Ditentukan pengguna –
ORDER BY FirstName DESC, EMail(tidak ada indeks pendukung). Ini menunjukkan kemampuan bagi pengguna untuk memilih urutan penyortiran yang mereka inginkan, sebuah pola yang diperingatkan Michael J. Swart dalam "Pola Desain UI yang Tidak Berskala".
Saya ingin menguji metode ini dan membandingkan rencana dan metrik ketika – di bawah skenario cache hangat dan cache dingin – melihat halaman 1, halaman 500, halaman 5.000, dan halaman 9.999. Saya membuat prosedur ini (hanya berbeda dengan klausa ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail Pada kenyataannya, Anda mungkin hanya akan memiliki satu prosedur yang menggunakan SQL dinamis (seperti dalam contoh “kitchen sink” saya) atau ekspresi CASE untuk mendikte urutannya.
Dalam kedua kasus tersebut, Anda mungkin melihat hasil terbaik dengan menggunakan OPTION (RECOMPILE) pada kueri untuk menghindari penggunaan ulang paket yang optimal untuk satu opsi pengurutan tetapi tidak semua. Saya membuat prosedur terpisah di sini untuk mengambil variabel-variabel itu; Saya menambahkan OPTION (RECOMPILE) untuk pengujian ini agar terhindar dari sniffing parameter dan masalah pengoptimalan lainnya tanpa menghapus seluruh cache paket berulang kali.
Pendekatan alternatif untuk pagination SQL Server untuk kinerja yang lebih baik
Pendekatan yang sedikit berbeda, yang menurut saya jarang diterapkan, adalah menemukan "halaman" yang kami gunakan hanya menggunakan kunci pengelompokan, lalu bergabung dengannya:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Ini kode yang lebih verbose, tentu saja, tapi mudah-mudahan jelas apa yang SQL Server dapat dipaksa untuk melakukan:menghindari scan, atau setidaknya menunda pencarian sampai hasil yang jauh lebih kecil dipangkas. Paul White (@SQL_Kiwi) menyelidiki pendekatan serupa pada tahun 2010, sebelum OFFSET/FETCH diperkenalkan pada awal SQL Server 2012 beta (saya pertama kali membuat blog tentangnya akhir tahun itu).
Mengingat skenario di atas, saya membuat tiga prosedur lagi, dengan satu-satunya perbedaan antara kolom yang ditentukan dalam klausa ORDER BY (sekarang kita membutuhkan dua, satu untuk halaman itu sendiri, dan satu untuk mengurutkan hasilnya):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Catatan:Ini mungkin tidak bekerja dengan baik jika kunci utama Anda tidak dikelompokkan – bagian dari trik yang membuat ini bekerja lebih baik, ketika indeks pendukung dapat digunakan, adalah bahwa kunci pengelompokan sudah ada dalam indeks, jadi pencarian sering dihindari.
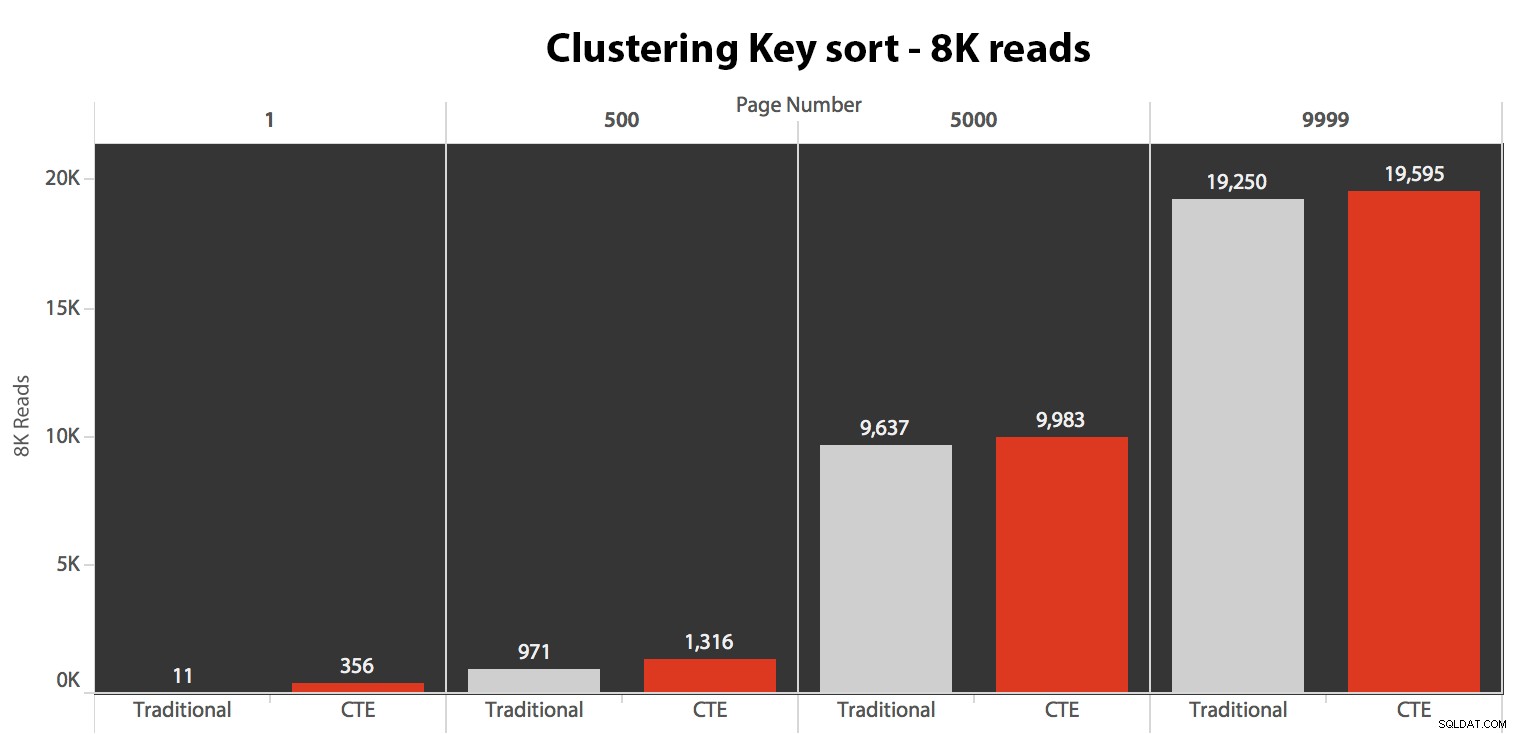
Menguji pengurutan kunci pengelompokan
Pertama saya menguji kasus di mana saya tidak mengharapkan banyak perbedaan antara kedua metode – mengurutkan berdasarkan kunci pengelompokan. Saya menjalankan pernyataan ini dalam batch di SQL Sentry Plan Explorer dan mengamati durasi, pembacaan, dan rencana grafis, memastikan bahwa setiap kueri dimulai dari cache yang benar-benar dingin:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
Hasil di sini tidak mencengangkan. Lebih dari 5 eksekusi, jumlah rata-rata pembacaan ditampilkan di sini, menunjukkan perbedaan yang dapat diabaikan antara dua kueri, di semua nomor halaman, saat mengurutkan berdasarkan kunci pengelompokan:
Rencana untuk metode default (seperti yang ditunjukkan di Plan Explorer) dalam semua kasus adalah sebagai berikut:
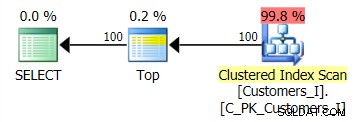
Sedangkan rencana metode berbasis CTE terlihat seperti ini:
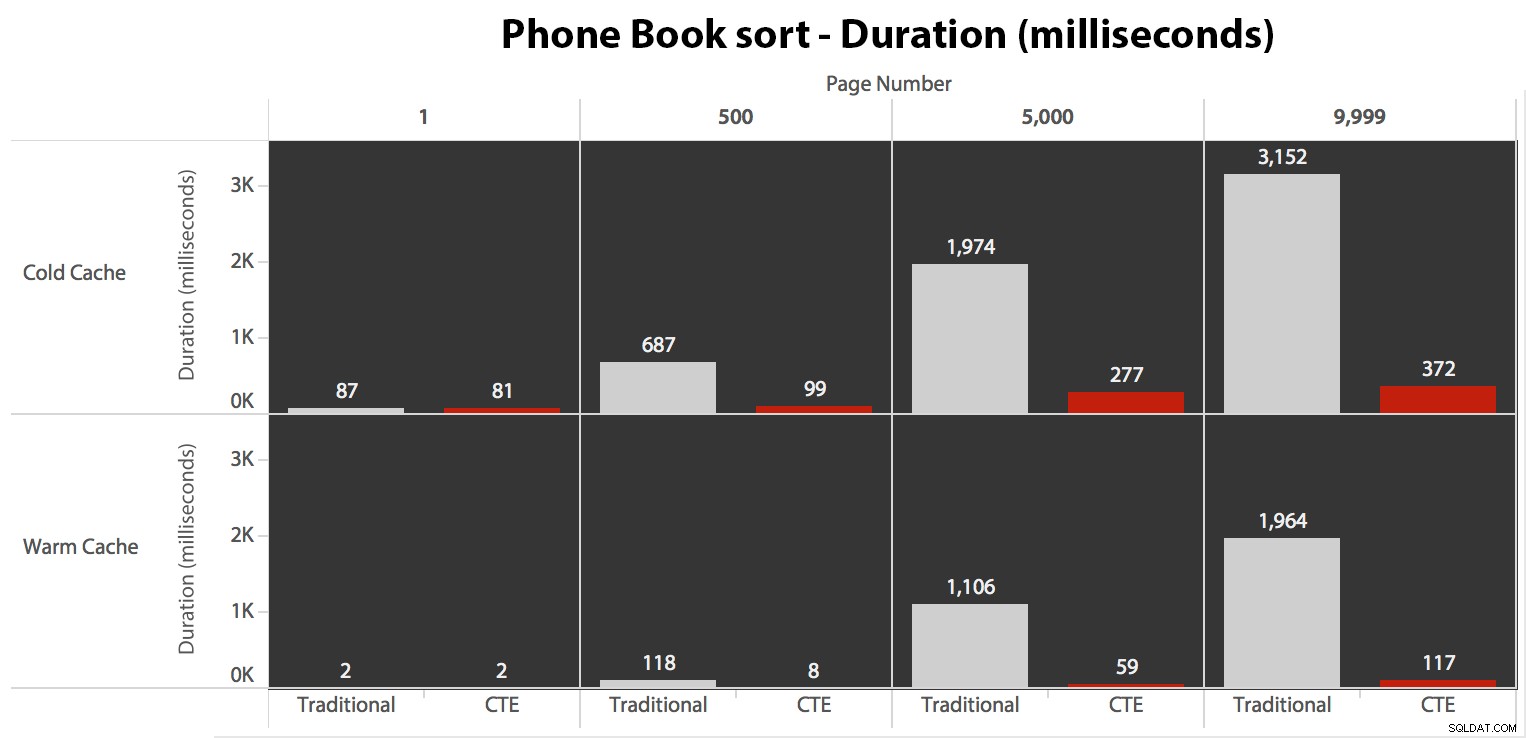
Sekarang, sementara I/O adalah sama terlepas dari caching (hanya lebih banyak membaca di depan dalam skenario cold cache), saya mengukur durasi dengan cache dingin dan juga dengan cache hangat (di mana saya mengomentari perintah DROPCLEANBUFFERS dan menjalankan kueri beberapa kali sebelum mengukur). Durasi ini terlihat seperti ini:
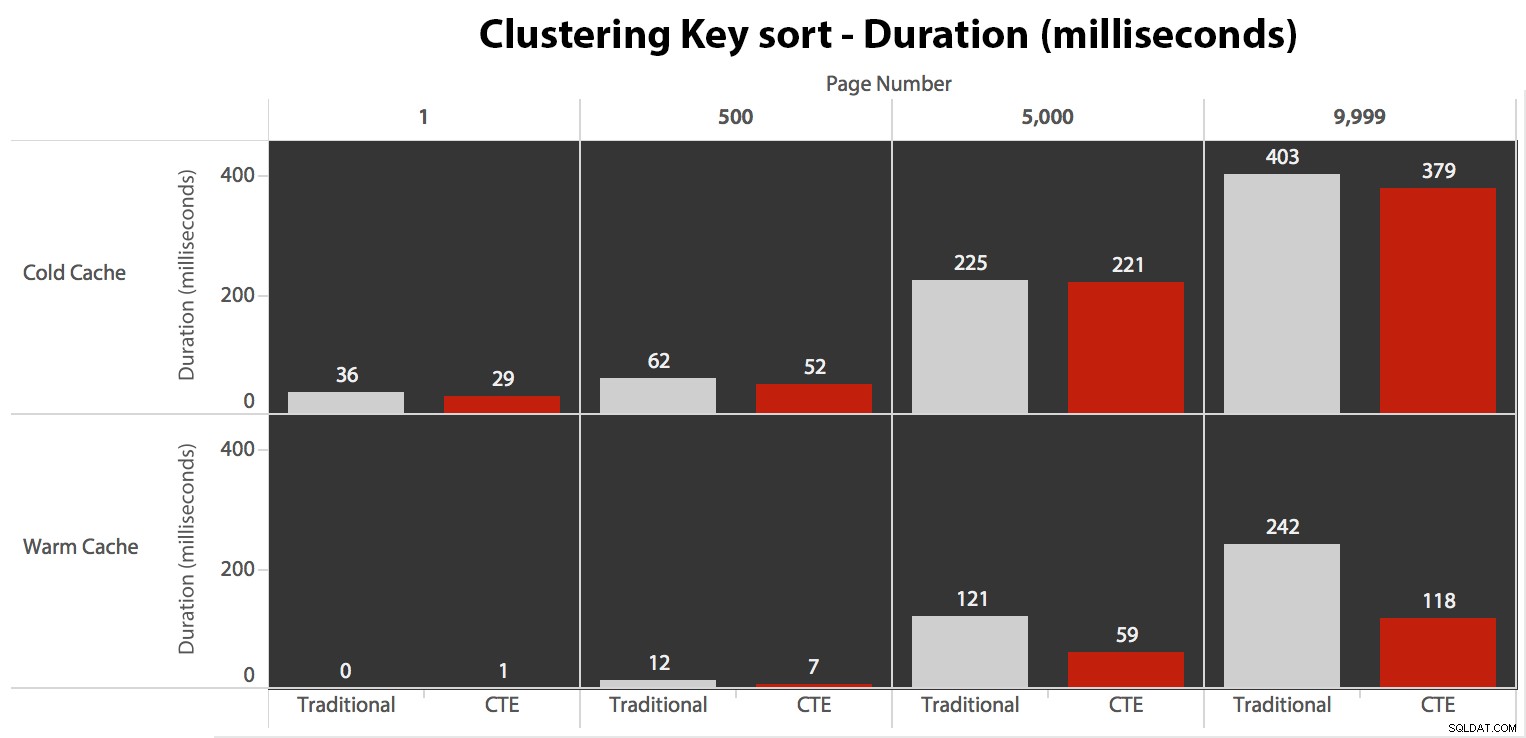
Meskipun Anda dapat melihat pola yang menunjukkan peningkatan durasi saat nomor halaman bertambah, ingat skalanya:untuk mencapai baris 999.801 -> 999.900, kita berbicara setengah detik dalam kasus terburuk dan 118 milidetik dalam kasus terbaik. Pendekatan CTE menang, tetapi tidak banyak.
Menguji pengurutan buku telepon
Selanjutnya, saya menguji kasus kedua, di mana penyortiran didukung oleh indeks non-covering pada LastName, FirstName. Kueri di atas baru saja mengubah semua contoh Test_1 untuk Test_2 . Berikut adalah pembacaan menggunakan cache dingin:
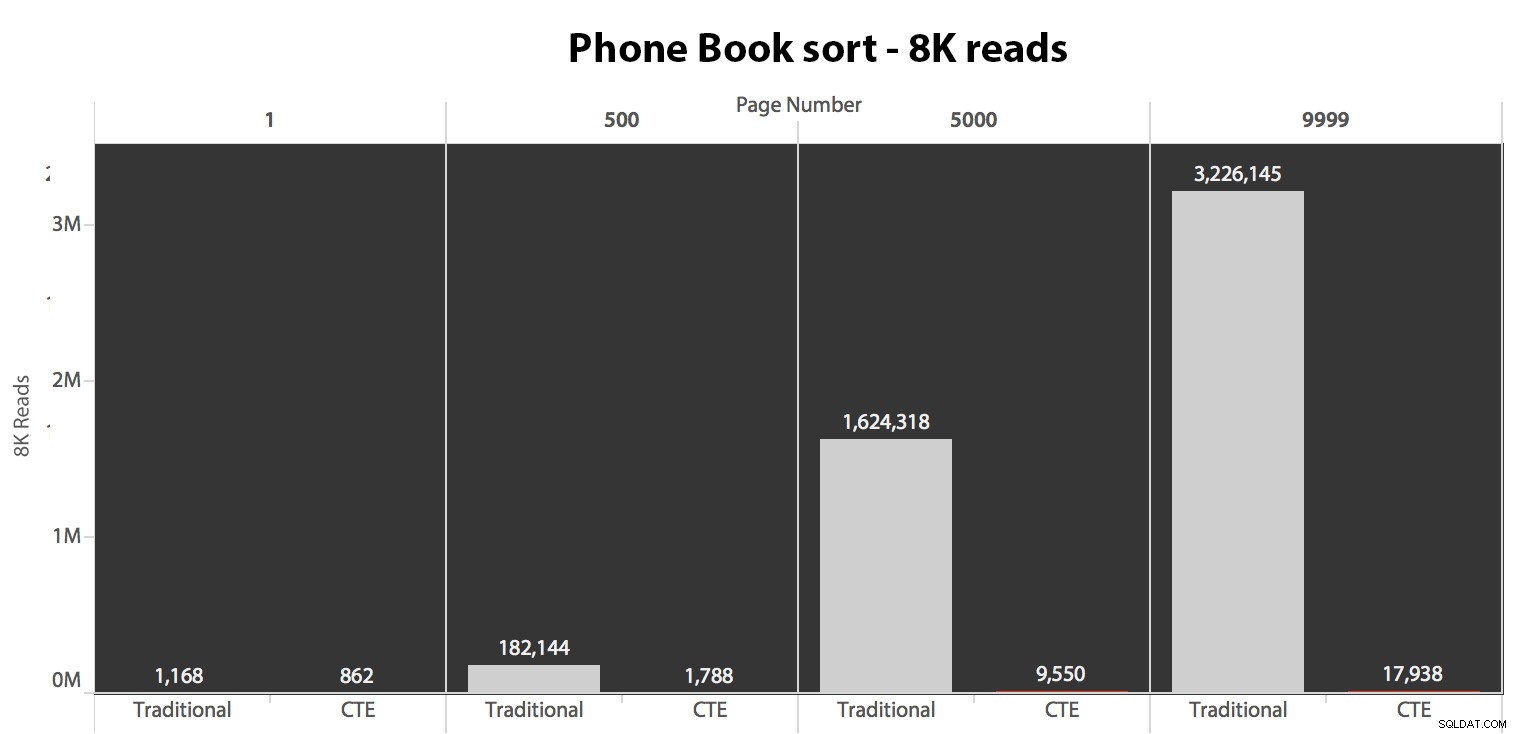
(Pembacaan di bawah cache hangat mengikuti pola yang sama – angka sebenarnya sedikit berbeda, tetapi tidak cukup untuk membenarkan bagan terpisah.)
Saat kita tidak menggunakan indeks berkerumun untuk menyortir, jelas bahwa biaya I/O yang terlibat dengan metode tradisional OFFSET/FETCH jauh lebih buruk daripada saat mengidentifikasi kunci terlebih dahulu dalam CTE, dan menarik kolom lainnya hanya untuk subset itu.
Berikut adalah rencana untuk pendekatan kueri tradisional:
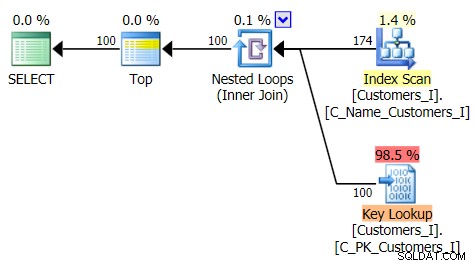
Dan rencana alternatif saya, pendekatan CTE:
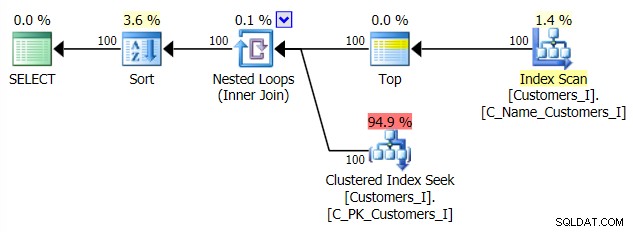
Akhirnya, durasinya:
Pendekatan tradisional menunjukkan peningkatan yang sangat jelas dalam durasi saat Anda berbaris menuju akhir pagination. Pendekatan CTE juga menunjukkan pola non-linier, tetapi jauh lebih jelas dan menghasilkan waktu yang lebih baik di setiap nomor halaman. Kami melihat 117 milidetik untuk halaman kedua hingga terakhir, dibandingkan dengan pendekatan tradisional yang datang hampir dua detik.
Menguji pengurutan yang ditentukan pengguna
Akhirnya, saya mengubah kueri untuk menggunakan Test_3 prosedur tersimpan, menguji kasus di mana pengurutan ditentukan oleh pengguna dan tidak memiliki indeks pendukung. I/O konsisten di setiap rangkaian pengujian; grafiknya sangat tidak menarik, saya hanya akan menautkannya. Singkat cerita:ada sedikit lebih dari 19.000 pembacaan di semua tes. Alasannya karena setiap variasi tunggal harus melakukan pemindaian penuh karena tidak adanya indeks untuk mendukung pemesanan. Berikut adalah rencana untuk pendekatan tradisional:
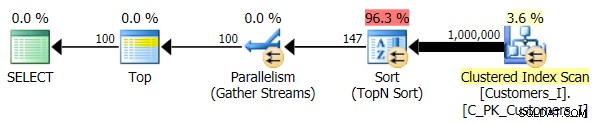
Dan sementara rencana kueri versi CTE terlihat lebih kompleks…
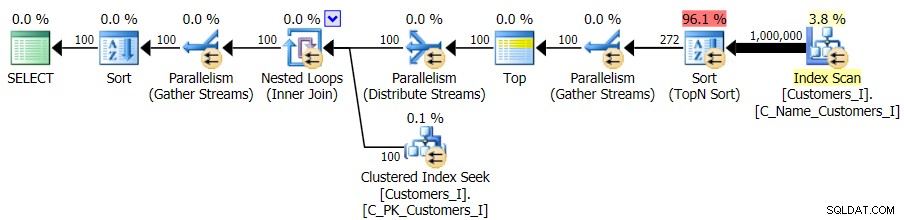
…itu mengarah ke durasi yang lebih rendah di semua kecuali satu kasus. Berikut adalah durasinya:
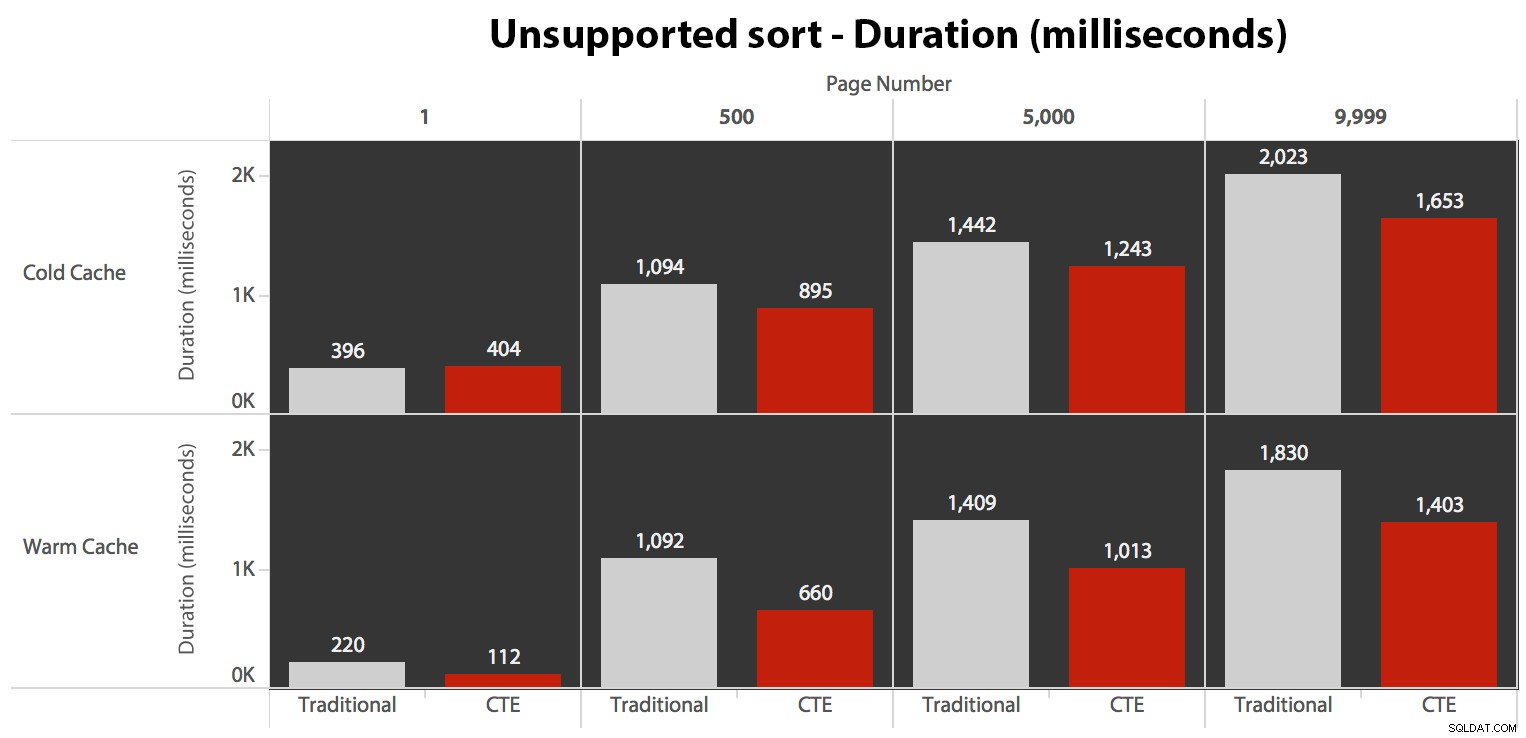
Anda dapat melihat bahwa kami tidak bisa mendapatkan kinerja linier di sini menggunakan salah satu metode, tetapi CTE keluar di atas dengan margin yang baik (di mana saja dari 16% hingga 65% lebih baik) dalam setiap kasus kecuali kueri cache dingin terhadap yang pertama halaman (di mana ia hilang dengan kekalahan 8 milidetik). Juga menarik untuk dicatat bahwa metode tradisional tidak banyak membantu sama sekali oleh cache hangat di "tengah" (halaman 500 dan 5000); hanya menjelang akhir set efisiensi yang layak disebut.
Volume lebih tinggi
Setelah pengujian individu dari beberapa eksekusi dan mengambil rata-rata, saya pikir masuk akal juga untuk menguji volume transaksi yang tinggi yang akan mensimulasikan lalu lintas nyata pada sistem yang sibuk. Jadi saya membuat pekerjaan dengan 6 langkah, satu untuk setiap kombinasi metode kueri (paging tradisional vs. CTE) dan jenis pengurutan (kunci pengelompokan, buku telepon, dan tidak didukung), dengan urutan 100 langkah untuk menekan empat nomor halaman di atas , masing-masing 10 kali, dan 60 nomor halaman lainnya dipilih secara acak (tetapi sama untuk setiap langkah). Inilah cara saya membuat skrip pembuatan pekerjaan:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Berikut adalah daftar langkah pekerjaan yang dihasilkan dan salah satu properti langkah:
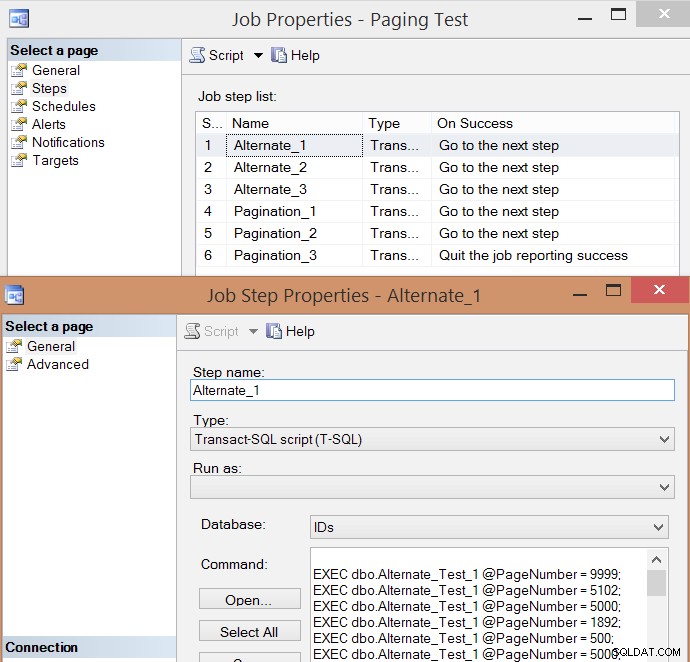
Saya menjalankan tugas lima kali, lalu meninjau riwayat tugas, dan berikut adalah rata-rata runtime dari setiap langkah:
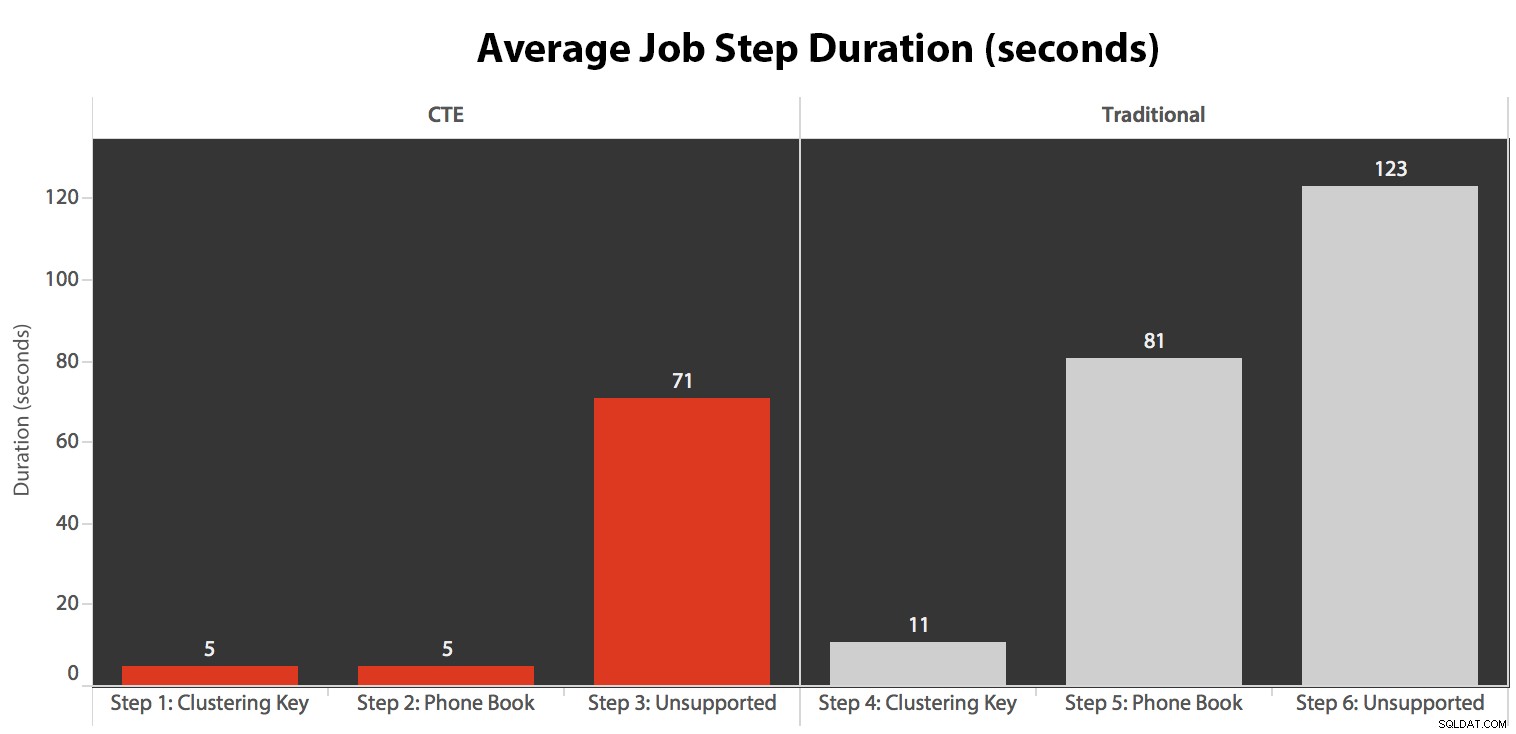
Saya juga menghubungkan salah satu eksekusi di kalender SQL Sentry Event Manager…
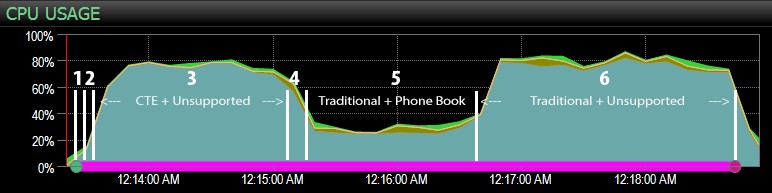
…dengan dasbor SQL Sentry, dan secara manual menandai secara kasar di mana masing-masing dari enam langkah dijalankan. Berikut adalah bagan penggunaan CPU dari dasbor sisi Windows:
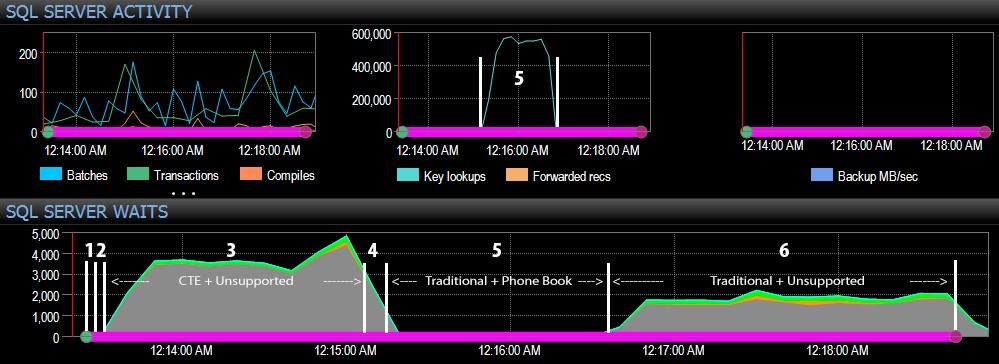
Dan dari sisi SQL Server di dasbor, metrik yang menarik ada di grafik Pencarian Kunci dan Waktu Tunggu:
Pengamatan paling menarik hanya dari perspektif visual murni:
- CPU cukup panas, sekitar 80%, selama langkah 3 (CTE + tidak ada indeks pendukung) dan langkah 6 (tradisional + tidak ada indeks pendukung);
- Waktu tunggu CXPACKET relatif tinggi selama langkah 3 dan pada tingkat yang lebih rendah selama langkah 6;
- Anda dapat melihat lompatan besar dalam pencarian kunci, hingga hampir 600.000, dalam rentang waktu sekitar satu menit (berkaitan dengan langkah 5 – pendekatan tradisional dengan indeks gaya buku telepon).
Dalam pengujian di masa mendatang - seperti posting saya sebelumnya tentang GUID - saya ingin menguji ini pada sistem di mana data tidak masuk ke dalam memori (mudah disimulasikan) dan di mana disk lambat (tidak begitu mudah untuk disimulasikan) , karena beberapa dari hasil ini mungkin mendapat manfaat dari hal-hal yang tidak dimiliki setiap sistem produksi – disk cepat dan RAM yang memadai. Saya juga harus memperluas tes untuk memasukkan lebih banyak variasi (menggunakan kolom kurus dan lebar, indeks kurus dan lebar, indeks buku telepon yang benar-benar mencakup semua kolom keluaran, dan menyortir di kedua arah). Scope creep jelas membatasi tingkat pengujian saya untuk rangkaian pengujian pertama ini.
Cara meningkatkan pagination SQL Server
Pagination tidak selalu harus menyakitkan; SQL Server 2012 tentu saja membuat sintaks lebih mudah, tetapi jika Anda hanya memasukkan sintaks asli, Anda mungkin tidak selalu melihat manfaat yang besar. Di sini saya telah menunjukkan bahwa sintaks yang sedikit lebih bertele-tele menggunakan CTE dapat menghasilkan kinerja yang jauh lebih baik dalam kasus terbaik, dan perbedaan kinerja yang bisa diabaikan dalam kasus terburuk. Dengan memisahkan lokasi data dari pengambilan data menjadi dua langkah yang berbeda, kita dapat melihat manfaat yang luar biasa dalam beberapa skenario, di luar CXPACKET yang lebih tinggi menunggu dalam satu kasus (dan bahkan kemudian, kueri paralel selesai lebih cepat daripada kueri lain yang menampilkan sedikit atau tanpa menunggu, jadi mereka tidak mungkin menjadi CXPACKET "buruk" yang diperingatkan semua orang kepada Anda).
Namun, bahkan metode yang lebih cepat lambat ketika tidak ada indeks pendukung. Meskipun Anda mungkin tergoda untuk menerapkan indeks untuk setiap kemungkinan algoritme pengurutan yang mungkin dipilih pengguna, Anda mungkin ingin mempertimbangkan untuk memberikan lebih sedikit opsi (karena kita semua tahu bahwa indeks tidak gratis). Misalnya, apakah aplikasi Anda benar-benar perlu mendukung pengurutan berdasarkan Nama Belakang naik *dan* Nama Belakang turun? Jika mereka ingin pergi langsung ke pelanggan yang nama belakangnya dimulai dengan Z, tidak bisakah mereka pergi ke halaman *terakhir* dan bekerja mundur? Itu adalah keputusan bisnis dan kegunaan yang lebih dari sekadar keputusan teknis, simpan saja sebagai opsi sebelum menerapkan indeks pada setiap kolom pengurutan, di kedua arah, untuk mendapatkan kinerja terbaik bahkan untuk opsi penyortiran yang paling tidak jelas.