Model data penggajian memungkinkan Anda menghitung gaji karyawan dengan mudah. Bagaimana cara kerja model ini?
Tidak peduli apakah Anda menjalankan perusahaan kecil atau besar, Anda memerlukan semacam solusi penggajian. Di situlah aplikasi penggajian berguna. Plus, semakin besar perusahaan, semakin sulit menangani perhitungan gaji karyawan; di sini, aplikasi penggajian menjadi sebuah kebutuhan. Untuk membantu Anda memahami semua data yang diperlukan untuk aplikasi semacam itu, kami akan memandu Anda melalui model data terkait.
Mari kita lihat bagaimana model data penggajian kita bekerja!
Model Data
Dengan membuat model data ini, saya mencoba membuat model yang berlaku umum untuk setiap bisnis. Tentu saja, akan selalu ada perbedaan dalam peraturan, kebijakan perusahaan, dll. yang mengharuskan model tersebut disesuaikan untuk memenuhi kebutuhan penggajian tertentu. Namun, prinsip-prinsip yang ditetapkan dalam model ini harus relevan untuk sebagian besar organisasi.
Perlu dicatat bahwa model ini dibuat dengan beberapa asumsi:
- Gaji yang disepakati dalam kontrak kerja adalah per tahun.
- Gaji bersih (yaitu dengan jumlah tertentu yang dipotong untuk pajak, dll.) dibayarkan kepada karyawan.
- Gaji dibayarkan setiap bulan.
Model data terdiri dari empat belas tabel dan dibagi menjadi dua bidang subjek:
EmployeesSalaries
Untuk memahami model dengan lebih baik, Anda perlu mempelajari setiap area subjek secara menyeluruh.
Karyawan
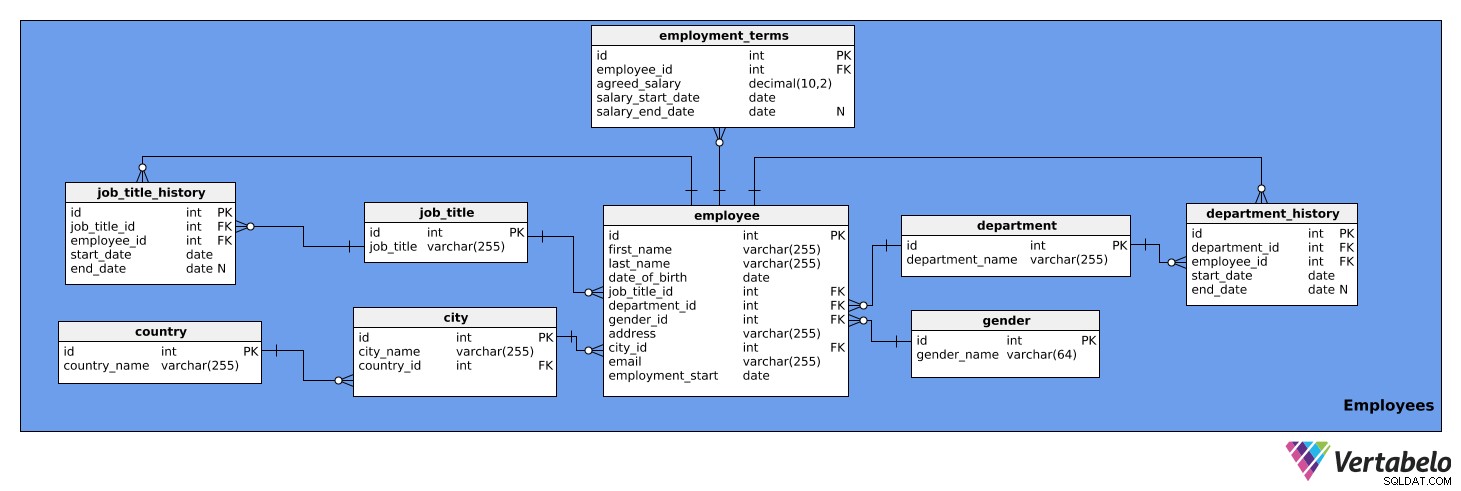
Area subjek ini berisi informasi rinci tentang karyawan. Ini terdiri dari sembilan tabel:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
Tabel pertama yang akan kita lihat adalah employee meja. Ini berisi daftar semua karyawan dan detail mereka yang relevan. Atribut tabel adalah:
id– ID unik untuk setiap karyawan.first_name– Nama depan karyawan.last_name– Nama belakang karyawan.job_title_id– Merujuk padajob_titlemeja.department_id– Referensidepartmentmeja.gender_id– Merujuk padagendermeja.address– Alamat karyawan.city_id– Merujukcitymeja.email– Email karyawan.employment_start– Tanggal saat pekerjaan orang ini dimulai.
Perhatikan bahwa kolom job_title_id dan department_id berlebihan, karena informasi tentang jabatan dan departemen saat ini dapat diakses dari job_title_history dan department_history tabel. Namun, kami akan menyimpan dua kolom ini di tabel ini untuk akses lebih cepat ke info.
Berikut adalah employment_terms meja. Ini menyimpan data tentang gaji setiap karyawan, sebagaimana disepakati dalam kontrak kerja, dan bagaimana itu berubah dari waktu ke waktu. Atribut tabel adalah:
id– ID unik untuk setiap rangkaian persyaratan kerja.employee_id– Merujuk kepadaemployeemeja.agreed_salary– Gaji yang tercantum dalam kontrak kerja.salary_start_date– Tanggal mulai gaji yang disepakati.salary_end_date– Tanggal berakhirnya gaji yang disepakati. Ini bisa menjadi NULL karena gaji mungkin tidak memiliki perubahan yang direncanakan.
job_title tabel adalah daftar judul pekerjaan yang dapat ditugaskan ke berbagai karyawan perusahaan, mis. analis, pengemudi, sekretaris, direktur, dll. Tabel memiliki atribut berikut:
id– ID unik untuk setiap jabatan.job_title- Nama jabatan pekerjaan. Ini adalah kunci alternatif.
Kami juga membutuhkan tabel untuk menyimpan riwayat jabatan setiap karyawan. Kami membutuhkan ini karena karyawan dapat dipromosikan, diturunkan, atau dipindahkan dalam perusahaan. job_title_history table akan mengelola info ini dan akan terdiri dari atribut berikut:
id– ID unik untuk entri riwayat jabatan.job_title_id– Merujuk padajob_titlemeja.employee_id– Merujuk kepadaemployeemeja.start_date– Tanggal karyawan pertama kali memegang jabatan tersebut.end_date– Ketika karyawan berhenti memiliki jabatan itu. Ini bisa menjadi NULL karena karyawan tersebut saat ini mungkin memegang jabatan tersebut.
Kombinasi job_title_id , employee_id , dan start_date adalah kunci alternatif untuk tabel di atas. Seorang karyawan hanya dapat memiliki satu jabatan yang ditetapkan pada tanggal tertentu.
Tabel berikutnya adalah department meja. Ini hanya akan mencantumkan semua departemen perusahaan, seperti TI, Akuntansi, Hukum, dll. Ini berisi dua atribut:
id– ID unik untuk setiap departemen.department_name- Nama masing-masing departemen. Ini adalah kunci alternatif.
Karyawan juga dapat berpindah departemen dalam perusahaan. Oleh karena itu, kita perlu memiliki department_history meja. Tabel ini akan menyimpan yang berikut:
id– ID unik untuk entri historis departemen tersebut.department_id– Referensidepartmentmeja.employee_id– Merujuk kepadaemployeemeja.start_date– Tanggal seorang karyawan mulai bekerja di sebuah departemen.end_date- Tanggal seorang karyawan berhenti bekerja di departemen itu. Ini bisa menjadi NULL karena karyawan tersebut mungkin masih bekerja di sana.
Kombinasi department_id , employee_id , dan start_date adalah kunci alternatif. Seorang karyawan hanya dapat bekerja di satu departemen dalam satu waktu.
Tabel selanjutnya yang akan kita bahas adalah city meja. Ini adalah daftar semua kota yang relevan. Ini memiliki atribut berikut:
id– ID unik untuk setiap kota.city_name– Nama kota.country_id– Merujukcountrymeja.
country tabel berikutnya dalam model kami. Ini hanyalah daftar negara dan berisi informasi berikut:
id– ID unik untuk setiap negara.country_name- Nama negara. Ini adalah kunci alternatif.
Tabel terakhir di area subjek ini adalah gender meja. Tabel ini mencantumkan semua jenis kelamin. Ini berisi atribut berikut:
id– ID unik untuk setiap jenis kelamin.gender_name– Nama jenis kelamin.
Sekarang mari kita menganalisis area subjek kedua.
Gaji
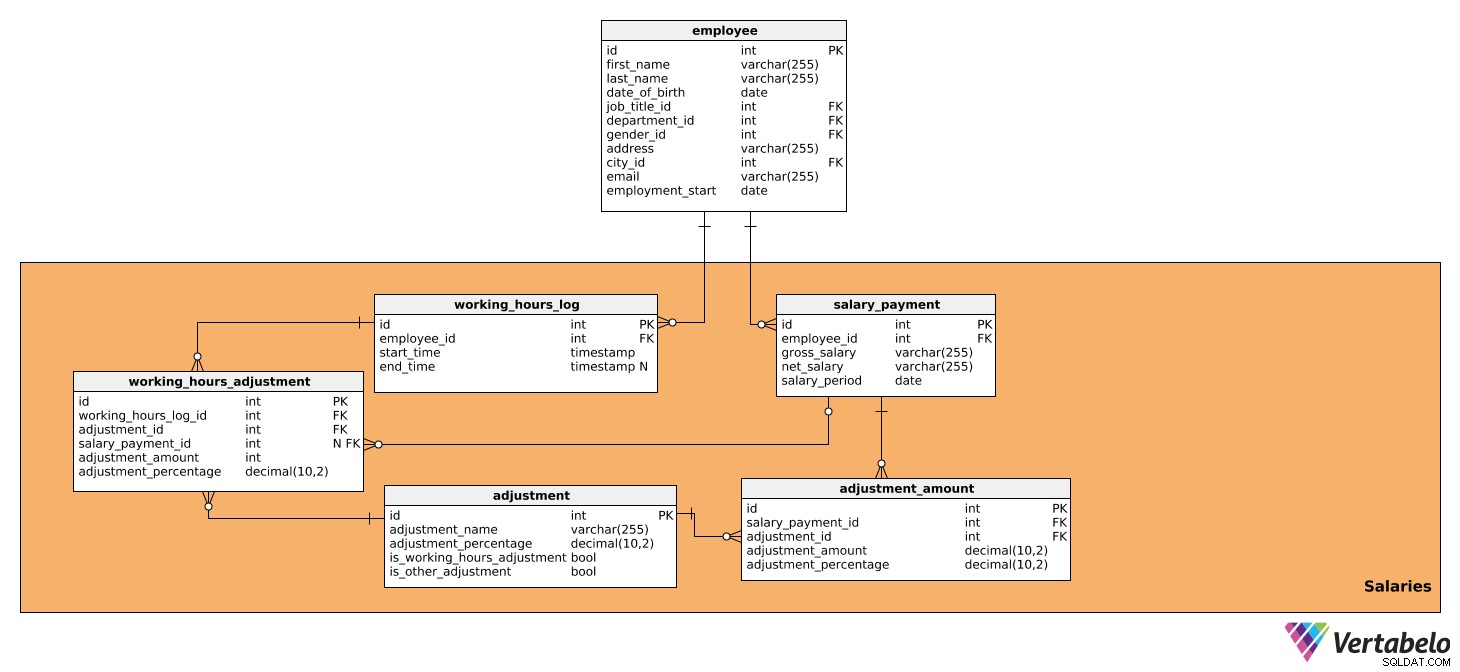
Area subjek ini terdiri dari tabel yang berisi semua data yang secara langsung mempengaruhi perhitungan gaji untuk setiap periode serta jumlah yang harus dibayarkan. Ini terdiri dari lima tabel:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Sekarang mari kita lihat setiap tabel.
Tabel pertama adalah salary_payment . Ini berisi semua detail yang relevan tentang gaji yang dibayarkan kepada setiap karyawan dan memiliki atribut berikut:
id– ID unik untuk setiap gaji.employee_id– Merujuk kepadaemployeemeja.gross_salary– Gaji kotor, yang akan menjadi dasar untuk penyesuaian lebih lanjut.net_salary– Gaji bersih (yaitu jumlah yang diterima oleh karyawan setelah berbagai pemotongan dilakukan).salary_period– Periode penghitungan dan pembayaran gaji.
Kedua adalah working_hours_log meja. Ini berisi data tentang jumlah jam kerja oleh setiap karyawan, yang dapat mempengaruhi penyesuaian gaji tertentu. Tabel ini memiliki atribut berikut:
id– ID unik untuk setiap entri log.employee_id– Merujuk kepadaemployeemeja.start_time– Waktu ketika karyawan masuk, yaitu mulai bekerja untuk hari itu.end_time– Saat karyawan logout. Bisa jadi NULL karena kita tidak akan tahu waktu pastinya sampai karyawan logout.
Tabel selanjutnya yang akan kita analisa adalah working_hours_adjustment . Tabel ini hanya akan digunakan dalam perhitungan penyesuaian berdasarkan jam kerja, yaitu yang memiliki nilai BENAR di is_working_hours_adjustment di adjustment meja. Atributnya adalah sebagai berikut:
id– ID unik untuk setiap penyesuaian.working_hours_log_id– Merujukworking_hours_logmeja.adjustment_id- Referensiadjustmentmeja.salary_payment_id– Merujuk padasalary_paymentmeja. Nilai ini bisa NULL karenasalary_payment_idhanya akan digunakan sebulan sekali, saat kami memulai penghitungan gaji.adjustment_amount– Jumlah penyesuaian.adjustment_percentage– Jumlah persentase penyesuaian. Ini akan digunakan untuk tujuan historis, karena persentasenya dapat berubah seiring waktu.
Tabel selanjutnya yang akan kita bahas adalah adjustment meja. Ini berisi informasi tentang semua penyesuaian yang digunakan untuk perhitungan gaji, artinya semua pajak dan kontribusi yang berdampak pada jumlah gaji. Juga, itu akan berisi semua penyesuaian yang bergantung pada jam kerja dan tidak bekerja, seperti bonus, lembur, cuti sakit, dan cuti hamil/bersalin. Untuk itu diperlukan data sebagai berikut:
id– ID unik untuk setiap penyesuaian.adjustment_name– Nama yang menjelaskan penyesuaian itu.adjustment_percentage– Jumlah persentase penyesuaian tertentu.is_working_hours_adjustment– Ini adalah penandaan bendera jika penyesuaian secara langsung bergantung pada jam kerja, mis. lembur, cuti sakit, dll.is_other_adjustment– Ini adalah penyesuaian penandaan bendera yang tidak secara langsung bergantung pada jam kerja, seperti pemotongan pajak, kontribusi jaminan sosial, kontribusi pemberi kerja, dll.
Setelah itu, kita membutuhkan adjustment_amount meja. Ini akan digunakan untuk menghitung semua penyesuaian gaji kecuali yang sudah ada di working_hours_adjustment , yaitu yang memiliki nilai TRUE di is_other_adjustment di adjustment meja. Tabel berisi atribut berikut:
id– ID unik untuk setiap entri jumlah penyesuaian.salary_payment_id– Merujuk padasalary_paymentmeja.adjustment_id– Merujuk padaadjustmentmeja.adjustment_amount– Jumlah setiap penyesuaian yang dihitung.adjustment_percentage- Jumlah persentase penyesuaian. Ini akan digunakan untuk tujuan historis, karena persentasenya dapat berubah seiring waktu.
Biarkan saya memberi Anda contoh bagaimana tabel working_hours_log , working_hours_adjustment , adjustment , dan adjustment_amount bekerja sama untuk menghitung gaji. Setiap hari, karyawan mencatat kapan dia tiba di tempat kerja dan kapan dia pergi. Data ini dapat dilihat di working_hours_log meja. Katakanlah karyawan kita telah bekerja lembur 10 jam selama satu bulan dan, menurut kebijakan perusahaan, dia akan dibayar 20% lebih banyak per jam untuk setiap jam lembur. Dengan merujuk pada adjustment tabel, kita akan dapat menemukan penyesuaian yang diperlukan, yaitu lembur, yang akan memiliki jumlah persentase tertentu (20%). Kami juga akan memiliki is_working_hours_adjustment disetel ke BENAR. Dengan menggunakan data dari kedua tabel tersebut, kita akan dapat menghitung penyesuaian dan menyimpannya di working_hours_adjustment meja.
Sekarang kita dapat menghitung semua penyesuaian lain yang tidak tergantung jam kerja. Ini akan dilakukan di adjustment_amount meja. Seperti yang kami lakukan di atas, kami akan mereferensikan adjustment tabel dan temukan penyesuaian yang kita butuhkan – mis. pengurangan pajak, kontribusi jaminan sosial, atau kontribusi pemberi kerja – dan persentasenya yang relevan. is_other_adjustment tandai di adjustment tabel akan disetel ke TRUE untuk penyesuaian ini.
Berdasarkan perhitungan tersebut, kita dapat menyimpan data gaji kotor dan gaji bersih di salary_payment meja.
Dengan melihat contoh ini, kami telah membahas semuanya dalam model data kami!
Apakah Anda Menyukai Model Data Penggajian?
Saya mencoba membuat model yang dapat digunakan di hampir semua situasi. Namun, tidak mungkin memasukkan semua parameter spesifik yang memengaruhi penghitungan gaji dalam artikel sepanjang ini. Dengan membahas prinsip-prinsip umum, saya telah mencoba membuat model ini berguna sebagai dasar yang kuat untuk model data penggajian Anda.
Apa pendapat Anda tentang model data penggajian? Apakah dapat diterapkan sebagai solusi untuk kebutuhan payroll Anda? Apakah Anda datang dengan sesuatu yang berbeda? Apakah ada masalah khusus yang Anda temukan yang secara signifikan akan mengubah model data? Sampaikan pendapat Anda di bagian komentar.