Pengantar
Baru-baru ini kami menemukan masalah kinerja yang menarik di salah satu database SQL Server kami yang memproses transaksi dengan kecepatan tinggi. Tabel transaksi yang digunakan untuk menangkap transaksi ini menjadi hot table. Akibatnya, masalah muncul di lapisan aplikasi. Itu adalah waktu tunggu yang terputus-putus dari sesi yang berusaha memposting transaksi.
Ini terjadi karena sebuah sesi biasanya akan "bertahan" pada tabel dan menyebabkan serangkaian kunci palsu dalam database.
Reaksi pertama dari administrator basis data tipikal adalah mengidentifikasi sesi pemblokiran utama dan menghentikannya dengan aman. Ini aman karena biasanya merupakan pernyataan SELECT atau sesi idle.
Ada juga upaya lain untuk memecahkan masalah:
- Membersihkan meja. Ini diharapkan memberikan kinerja yang baik bahkan jika kueri harus memindai tabel penuh.
- Mengaktifkan tingkat isolasi READ COMMITTED SNAPSHOT untuk mengurangi dampak sesi pemblokiran.
Dalam artikel ini, kami akan mencoba membuat ulang versi skenario yang disederhanakan dan menggunakannya untuk menunjukkan bagaimana pengindeksan sederhana dapat mengatasi situasi seperti ini jika dilakukan dengan benar.
Dua Tabel Terkait
Lihat Daftar 1 dan Daftar 2. Mereka menunjukkan versi tabel yang disederhanakan yang terlibat dalam skenario yang sedang dipertimbangkan.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Daftar 3 menunjukkan pemicu yang menyisipkan empat baris ke dalam TranDetails tabel untuk setiap baris yang disisipkan di TranLog tabel.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Gabung dengan Kueri
Biasanya menemukan tabel transaksi yang didukung oleh tabel besar. Tujuannya adalah untuk menyimpan transaksi yang jauh lebih lama atau untuk menyimpan rincian catatan yang dirangkum dalam tabel pertama. Anggap ini sebagai perintah dan detail pesanan tabel yang khas dalam database sampel SQL Server. Dalam kasus kami, kami sedang mempertimbangkan TranLog dan Detail Transaksi tabel.
Dalam keadaan normal, transaksi mengisi dua tabel ini dari waktu ke waktu. Dalam hal pelaporan atau kueri sederhana, kueri akan melakukan gabungan pada dua tabel ini. Gabung ini akan memanfaatkan kolom umum di antara tabel.
Pertama, kami mengisi tabel menggunakan kueri di Listing 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
Dalam contoh kami, kolom umum yang digunakan oleh gabungan adalah TranID kolom:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Anda dapat melihat dua contoh kueri sederhana yang menggunakan gabungan untuk mengambil catatan dari TranLog dan Detail Transaksi .
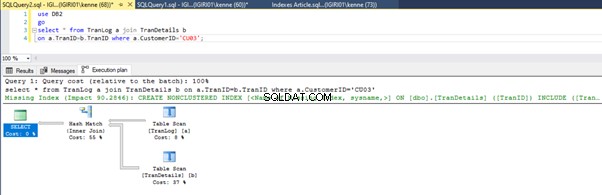
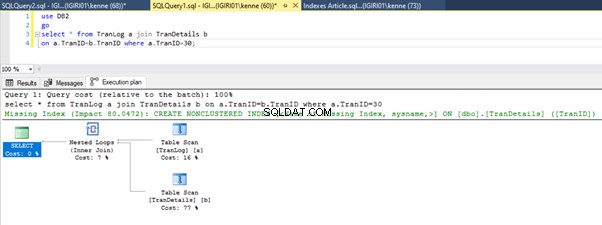
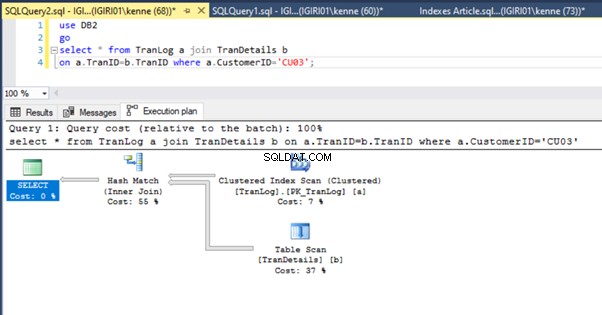
Ketika kita menjalankan query di Listing 5, dalam kedua kasus, kita harus melakukan scan tabel penuh pada kedua tabel (lihat Gambar 1 dan 2). Bagian dominan dari setiap query adalah operasi fisik. Keduanya bergabung dalam. Namun, Listing 5a menggunakan Hash Match bergabung, sementara Listing 5b menggunakan Loop Bersarang Ikuti. Catatan:Listing 5a mengembalikan 4000 baris sedangkan Listing 4b mengembalikan 4 baris.
Tiga Langkah Penyetelan Performa
Pengoptimalan pertama yang kami lakukan adalah memperkenalkan indeks (kunci utama, tepatnya) pada TranID kolom TranLog tabel:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
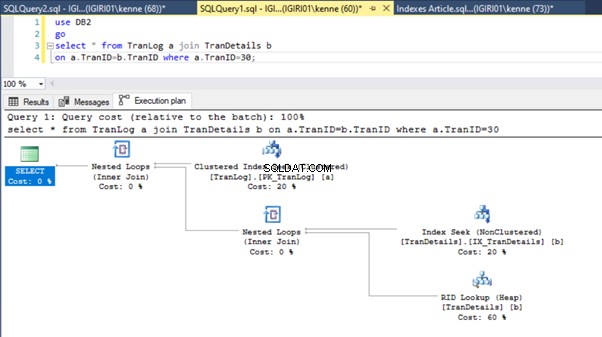
Gambar 3 dan 4 menunjukkan bahwa SQL Server menggunakan indeks ini di kedua kueri, melakukan pemindaian di Listing 5a dan pencarian di Listing 5b.
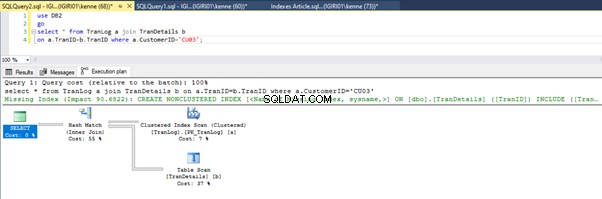
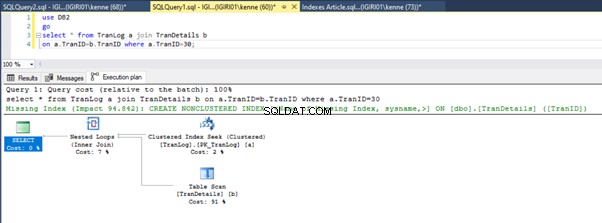
Kami memiliki pencarian indeks di Listing 5b. Itu terjadi karena kolom yang terlibat dalam predikat klausa WHERE – TranID. Ini adalah kolom yang telah kami terapkan indeksnya.
Selanjutnya, kami memperkenalkan kunci asing pada TranID kolom TranDetails tabel (Daftar 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Ini tidak banyak berubah dalam rencana eksekusi. Situasinya hampir sama seperti yang ditunjukkan sebelumnya pada Gambar 3 dan 4.
Kemudian kami memperkenalkan indeks pada kolom kunci asing:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
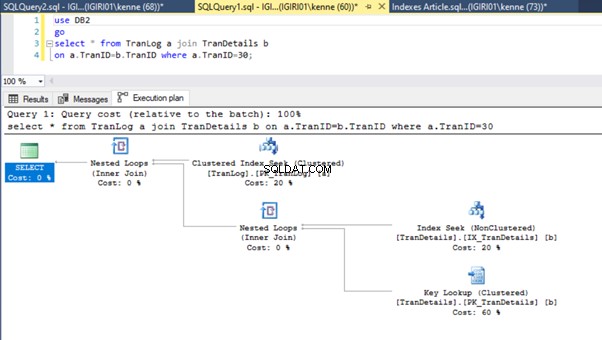
Tindakan ini mengubah rencana eksekusi Listing 5b secara dramatis (Lihat Gambar 6). Kami melihat lebih banyak upaya indeks terjadi. Perhatikan juga pencarian RID pada Gambar 6.
Pencarian RID di tumpukan biasanya terjadi tanpa adanya kunci utama. Heap adalah tabel tanpa kunci utama.
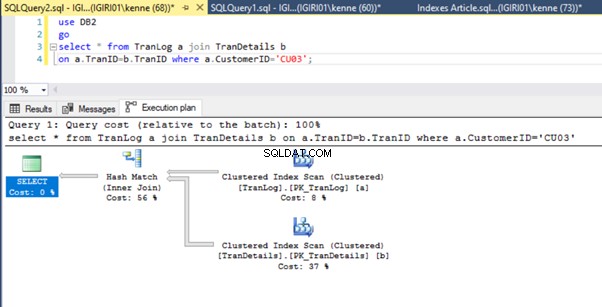
Terakhir, kami menambahkan kunci utama ke TranDetails meja. Ini menghilangkan pemindaian tabel dan pencarian tumpukan RID di Daftar 5a dan 5b masing-masing (Lihat Gambar 7 dan 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Kesimpulan
Peningkatan kinerja yang diperkenalkan oleh indeks terkenal bahkan oleh DBA pemula. Namun, kami ingin menunjukkan bahwa Anda perlu melihat lebih dekat bagaimana kueri menggunakan indeks.
Selanjutnya, idenya adalah untuk menetapkan solusi dalam kasus tertentu di mana kita memiliki kueri gabungan antara Log Transaksi tabel dan Detail Transaksi tabel.
Secara umum masuk akal untuk menegakkan hubungan antara tabel tersebut menggunakan kunci dan memperkenalkan indeks ke kolom kunci utama dan asing.
Dalam mengembangkan aplikasi yang menggunakan desain seperti itu, pengembang harus mengingat indeks dan hubungan yang diperlukan pada tahap desain. Alat modern untuk spesialis SQL Server membuat persyaratan ini lebih mudah untuk dipenuhi. Anda dapat membuat profil kueri Anda menggunakan alat Profiler Kueri khusus. Ini adalah bagian dari solusi profesional multi-fitur dbForge Studio untuk SQL Server yang dikembangkan oleh Devart untuk membuat kehidupan DBA lebih sederhana.



