Pernahkah Anda menghubungi Microsoft atau mitra Microsoft dan mendiskusikan dengan mereka berapa biaya untuk pindah ke cloud? Jika demikian, Anda mungkin pernah mendengar tentang kalkulator DTU Azure SQL Database, dan Anda mungkin juga membaca tentang bagaimana kalkulator tersebut telah direkayasa balik oleh Andy Mallon. Kalkulator DTU adalah alat gratis yang dapat Anda gunakan untuk mengunggah metrik kinerja dari server Anda, dan menggunakan data untuk menentukan tingkat layanan yang sesuai jika Anda ingin memigrasikan server tersebut ke Azure SQL Database (atau ke kumpulan elastis Database SQL).
Untuk melakukannya, Anda harus menjadwalkan atau menjalankan skrip secara manual (baris perintah atau Powershell, tersedia untuk diunduh di situs web kalkulator DTU) selama periode beban kerja produksi biasa.
Jika Anda mencoba menganalisis lingkungan yang besar, atau ingin menganalisis data dari titik waktu tertentu, ini bisa menjadi tugas. Dalam banyak kasus, banyak DBA memiliki beberapa jenis alat pemantauan yang sudah menangkap data kinerja untuk mereka. Dalam banyak kasus, mungkin sudah menangkap metrik yang diperlukan, atau dapat dengan mudah dikonfigurasi untuk menangkap data yang Anda butuhkan. Hari ini, kita akan melihat bagaimana memanfaatkan SentryOne sehingga kita dapat memberikan data yang sesuai ke kalkulator DTU.
Untuk memulai, mari kita lihat informasi yang ditarik oleh utilitas baris perintah dan skrip PowerShell yang tersedia di situs web kalkulator DTU; ada 4 penghitung monitor kinerja yang ditangkapnya:
- Prosesor – % Waktu Prosesor
- Disk Logis – Disk Dibaca/dtk
- Disk Logis – Penulisan Disk/dtk
- Basis Data – Log Byte Flushed/dtk
Langkah pertama adalah menentukan apakah metrik ini sudah ditangkap sebagai bagian dari pengumpulan data di SQL Sentry. Untuk penemuan, saya sarankan membaca posting blog ini oleh Jason Hall, di mana dia berbicara tentang bagaimana data ditata dan bagaimana Anda dapat menanyakannya. Saya tidak akan membahas setiap langkah ini di sini, tetapi mendorong Anda untuk membaca dan menandai seluruh seri blog itu.
Ketika saya melihat melalui database SentryOne, saya menemukan bahwa 3 dari 4 penghitung sudah ditangkap secara default. Satu-satunya yang hilang adalah [Database – Log Bytes Flushed/sec] , jadi saya harus bisa mengaktifkannya. Ada postingan blog lain oleh Justin Randall yang menjelaskan cara melakukannya.
Singkatnya, Anda dapat menanyakan [PerformanceAnalysisCounter] tabel.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Anda akan melihat bahwa secara default [PerformanceAnalysisSampleIntervalID] diatur ke 0 - ini berarti dinonaktifkan. Anda harus menjalankan perintah berikut untuk mengaktifkan ini. Cukup tarik ID dari kueri SELECT yang baru saja Anda jalankan dan gunakan dalam PEMBARUAN ini:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Setelah menjalankan pembaruan, Anda harus memulai ulang layanan pemantauan SentryOne yang relevan dengan target ini, sehingga data penghitung baru dapat dikumpulkan.
Perhatikan bahwa saya menyetel [PerformanceAnalysisSampleIntervalID] ke 1 sehingga data diambil setiap 10 detik, namun, Anda dapat mengambil data ini lebih jarang untuk meminimalkan ukuran data yang dikumpulkan dengan biaya akurasi yang lebih rendah. Lihat [PerformanceAnalysisSampleInterval] tabel untuk daftar nilai yang dapat Anda gunakan.
Jangan berharap data mulai mengalir ke tabel dengan segera; ini akan membutuhkan waktu untuk melewati sistem. Anda dapat memeriksa populasi dengan kueri berikut:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Setelah Anda mengonfirmasi bahwa data muncul, Anda harus memiliki data untuk setiap metrik yang diperlukan oleh kalkulator DTU, meskipun Anda mungkin ingin menunggu untuk mengekstraknya sampai Anda memiliki sampel yang representatif dari beban kerja penuh atau siklus bisnis.
Jika Anda membaca posting blog Jason, Anda akan melihat bahwa data disimpan di berbagai tabel rollup, dan masing-masing tabel rollup ini memiliki tingkat retensi yang berbeda-beda. Banyak dari ini lebih rendah dari yang saya inginkan jika saya menganalisis beban kerja selama periode waktu tertentu. Meskipun dimungkinkan untuk mengubah ini, itu mungkin bukan yang paling bijaksana. Karena apa yang saya tunjukkan kepada Anda tidak didukung, Anda mungkin ingin menghindari mengutak-atik pengaturan SentryOne karena dapat berdampak negatif pada kinerja, pertumbuhan, atau keduanya.
Untuk mengimbanginya, saya membuat skrip yang memungkinkan saya mengekstrak data yang saya perlukan untuk berbagai tabel rollup dan menyimpan data tersebut di lokasinya sendiri, sehingga saya dapat mengontrol retensi saya sendiri dan tidak mengganggu fungsionalitas SentryOne.
TABEL:dbo.AzureDatabaseDTUData
Saya membuat tabel bernama [AzureDatabaseDTUData] dan menyimpannya di database SentryOne. Prosedur yang saya buat akan secara otomatis menghasilkan tabel ini jika tidak ada, jadi tidak perlu melakukan ini secara manual kecuali jika Anda ingin menyesuaikan tempat penyimpanannya. Anda dapat menyimpan ini di database terpisah jika mau, Anda hanya perlu mengedit skrip untuk melakukannya. Tabelnya terlihat seperti ini:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Prosedur:dbo.Custom_CollectDTUDataForDevice
Ini adalah prosedur tersimpan yang dapat Anda gunakan untuk menarik semua data khusus DTU pada satu waktu (asalkan Anda telah mengumpulkan penghitung byte log untuk waktu yang cukup), atau menjadwalkannya untuk secara berkala menambahkan ke data yang dikumpulkan sampai Anda siap mengirimkan output ke kalkulator DTU. Seperti tabel di atas, prosedur dibuat di database SentryOne, tetapi Anda dapat dengan mudah membuatnya di tempat lain, cukup tambahkan nama tiga atau empat bagian ke referensi objek. Antarmuka prosedur adalah sebagai berikut:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Catatan :Seluruh prosedurnya agak panjang, jadi dilampirkan ke posting ini (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Ada beberapa parameter yang dapat Anda gunakan. Masing-masing memiliki nilai default, jadi Anda tidak perlu menentukannya jika Anda setuju dengan nilai default.
- @DeviceID – Ini memungkinkan Anda untuk menentukan apakah Anda ingin mengumpulkan data untuk SQL Server tertentu atau semuanya. Standarnya adalah -1, yang berarti salin semua SQL Server yang ditonton. Jika Anda hanya ingin mengekspor informasi untuk instance tertentu, cari
DeviceIDsesuai dengan host di[dbo].[Device]tabel, dan berikan nilai itu. Anda hanya dapat melewati satu@DeviceIDsekaligus, jadi jika Anda ingin melewati sekumpulan server, Anda dapat memanggil prosedur beberapa kali, atau Anda dapat mengubah prosedur untuk mendukung sekumpulan perangkat. - @DaysToPurge – Ini mewakili usia di mana Anda ingin menghapus data. Defaultnya adalah 14 hari, artinya Anda hanya akan menarik data hingga 14 hari, dan data apa pun yang lebih lama dari 14 hari di tabel khusus Anda akan dihapus.
Empat parameter lainnya tersedia untuk pemeriksaan di masa mendatang, jika Enum SentryOne untuk ID penghitung berubah.
Beberapa catatan pada skrip:
- Saat data ditarik, dibutuhkan nilai maksimal dari menit yang terpotong dan mengekspornya. Ini berarti ada satu nilai per metrik per menit, tetapi itu adalah nilai maksimal yang ditangkap. Hal ini penting karena cara data perlu disajikan ke kalkulator DTU.
- Saat pertama kali Anda menjalankan ekspor, mungkin perlu waktu lebih lama. Ini karena ia menarik semua data yang dapat didasarkan pada nilai parameter Anda. Setiap proses tambahan, satu-satunya data yang diekstraksi adalah apa pun yang baru sejak proses terakhir, jadi seharusnya lebih cepat.
- Anda perlu menjadwalkan prosedur ini agar berjalan pada jadwal waktu yang mendahului proses pembersihan SentryOne. Apa yang saya lakukan hanyalah membuat Pekerjaan Agen SQL untuk dijalankan setiap malam yang mengumpulkan semua data baru sejak malam sebelumnya.
- Karena proses pembersihan di SentryOne dapat bervariasi berdasarkan metrik, Anda bisa berakhir dengan baris di salinan Anda yang tidak berisi semua 4 penghitung untuk jangka waktu tertentu. Anda mungkin hanya ingin mulai menganalisis data sejak Anda memulai proses ekstraksi.
- Saya menggunakan blok kode dari prosedur SentryOne yang ada untuk menentukan tabel rollup untuk setiap penghitung. Saya bisa saja mengkodekan nama tabel saat ini, namun, dengan menggunakan metode SentryOne, itu harus kompatibel dengan perubahan apa pun pada proses rollup bawaan.
Setelah data Anda dipindahkan ke tabel mandiri, Anda dapat menggunakan kueri PIVOT untuk mengubahnya menjadi bentuk yang diharapkan oleh kalkulator DTU.
Prosedur:dbo.Custom_ExportDataForDTUCalculator
Saya membuat prosedur lain untuk mengekstrak data ke dalam format CSV. Kode untuk prosedur ini juga dilampirkan (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Ada tiga parameter:
- @DeviceID – Smallint sesuai dengan salah satu perangkat yang Anda kumpulkan dan yang ingin Anda kirimkan ke kalkulator.
- @BeginTime – Datetime mewakili waktu mulai, dalam waktu lokal; misalnya,
'2018-12-04 05:47:00.000'. Prosedur akan diterjemahkan ke UTC. Jika dihilangkan, itu akan mengumpulkan dari nilai paling awal dalam tabel. - @EndTime – Datetime mewakili waktu akhir, sekali lagi dalam waktu lokal; misalnya,
'2018-12-06 12:54:00.000'. Jika dihilangkan, itu akan mengumpulkan hingga nilai terbaru dalam tabel.
Contoh eksekusi, untuk mendapatkan semua data yang dikumpulkan untuk SQLInstanceA antara tanggal 4 Desember pukul 05:47 dan 6 Desember pukul 12:54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Data perlu diekspor ke file CSV. Jangan khawatir tentang data itu sendiri; Saya memastikan untuk menampilkan hasil sehingga tidak ada informasi pengenal tentang server Anda di file csv, hanya tanggal dan metrik.
Jika Anda menjalankan kueri di SSMS, Anda dapat mengklik kanan dan mengekspor hasil; namun, Anda memiliki pilihan terbatas di sini dan Anda harus memanipulasi output untuk mendapatkan format yang diharapkan oleh kalkulator DTU. (Jangan ragu untuk mencoba dan beri tahu saya jika Anda menemukan cara untuk melakukannya.)
Saya sarankan hanya menggunakan wizard ekspor yang dimasukkan ke dalam SSMS. Klik kanan pada database dan pergi ke Tasks -> Export Data. Untuk Sumber Data Anda, gunakan "SQL Server Native Client" dan arahkan ke database SentryOne Anda (atau di mana pun Anda memiliki salinan data yang disimpan). Untuk tujuan Anda, Anda akan ingin memilih "Tujuan File Datar." Telusuri ke suatu lokasi, beri nama file, dan simpan file sebagai CSV.
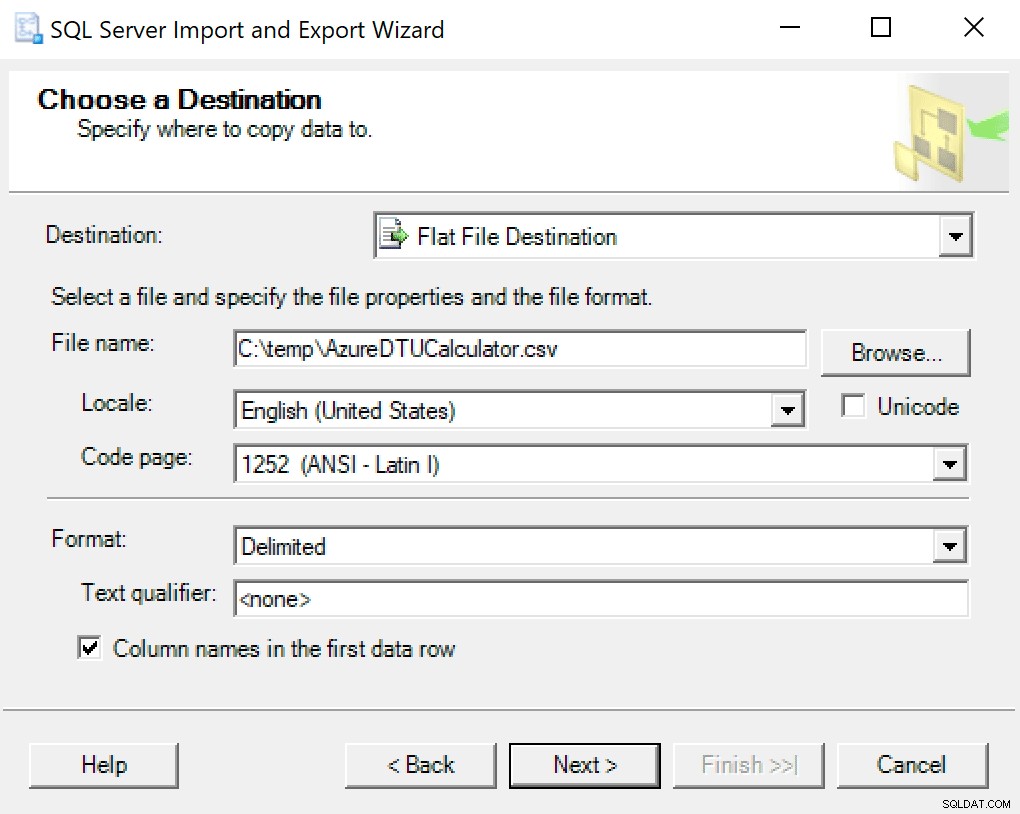
Berhati-hatilah untuk meninggalkan halaman kode; beberapa mungkin mengembalikan kesalahan. Saya tahu bahwa 1252 bekerja dengan baik. Nilai lainnya dibiarkan sebagai default.
Pada layar berikutnya, pilih opsi Tulis kueri untuk menentukan data yang akan ditransfer .
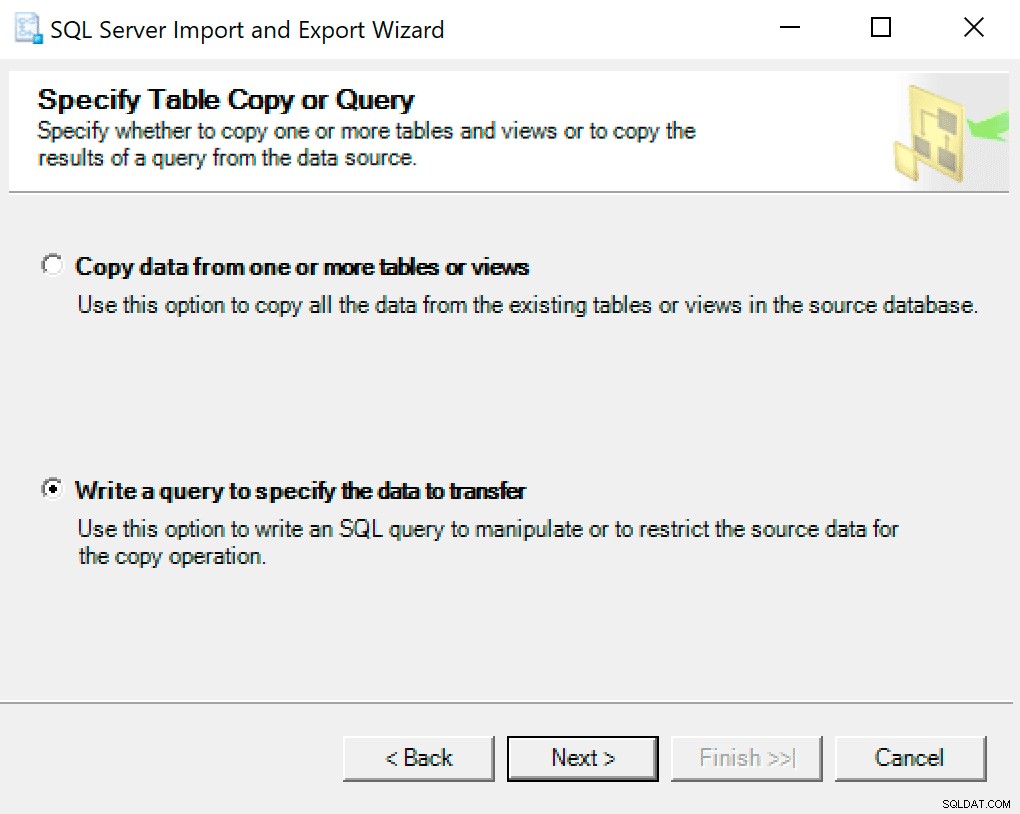
Di jendela berikutnya, salin panggilan prosedur dengan parameter Anda diatur ke dalamnya. Tekan selanjutnya.
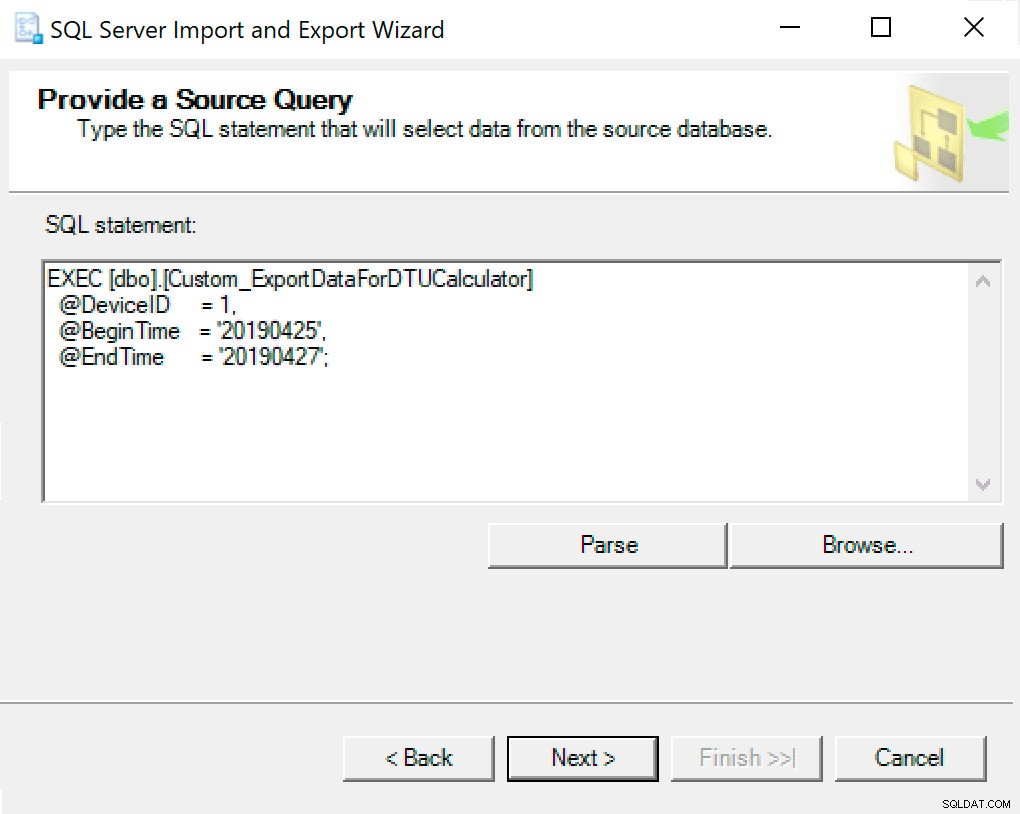
Saat Anda masuk ke Configure Flat File Destination, saya membiarkan opsi sebagai default. Berikut adalah tangkapan layar jika Anda berbeda:
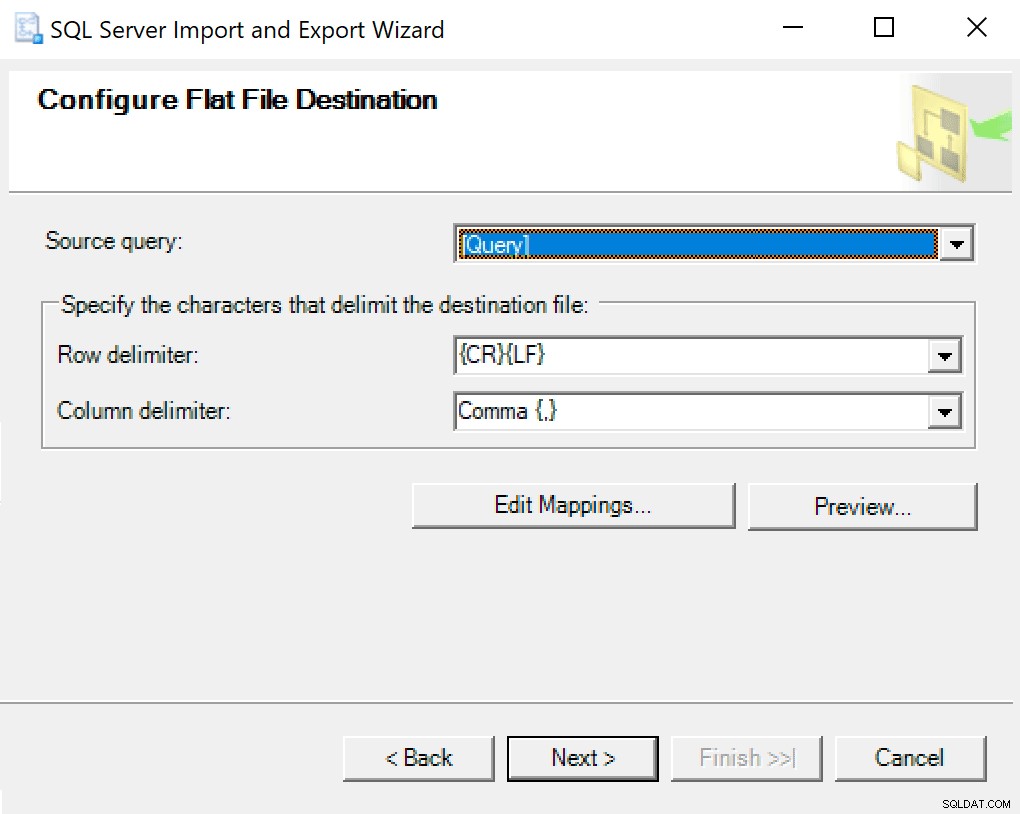
Tekan berikutnya dan lari segera. Sebuah file akan dibuat yang akan Anda gunakan pada langkah terakhir.
CATATAN :Anda dapat membuat paket SSIS untuk digunakan untuk ini dan kemudian meneruskan nilai parameter Anda ke paket SSIS jika Anda akan sering melakukan ini. Ini akan mencegah Anda dari keharusan melalui wizard setiap saat.
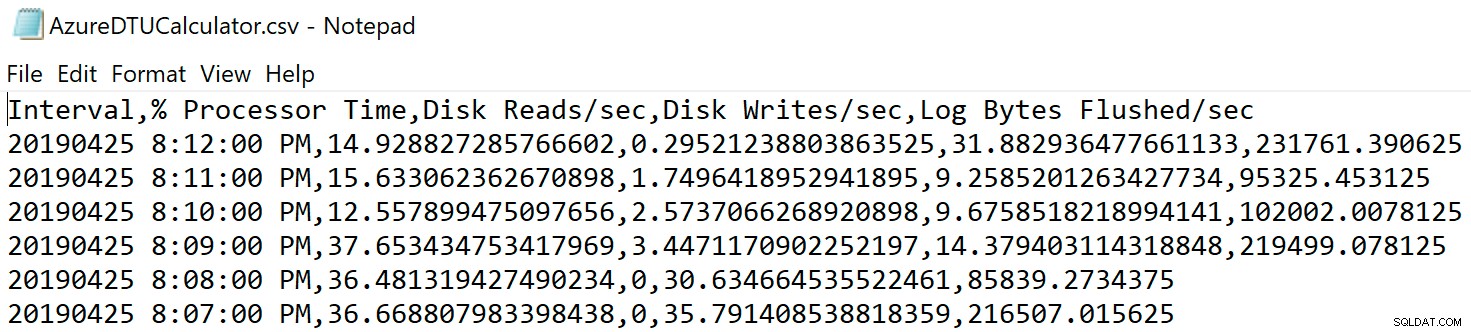
Arahkan ke lokasi tempat Anda menyimpan file dan verifikasi ada di sana. Ketika Anda membukanya, itu akan terlihat seperti ini:
Buka situs web kalkulator DTU, dan gulir ke bawah ke bagian yang bertuliskan, “Unggah file CSV dan Hitung.” Masukkan jumlah Core yang dimiliki server, unggah file CSV, dan klik Hitung. Anda akan mendapatkan serangkaian hasil seperti ini (klik gambar apa saja untuk memperbesar):
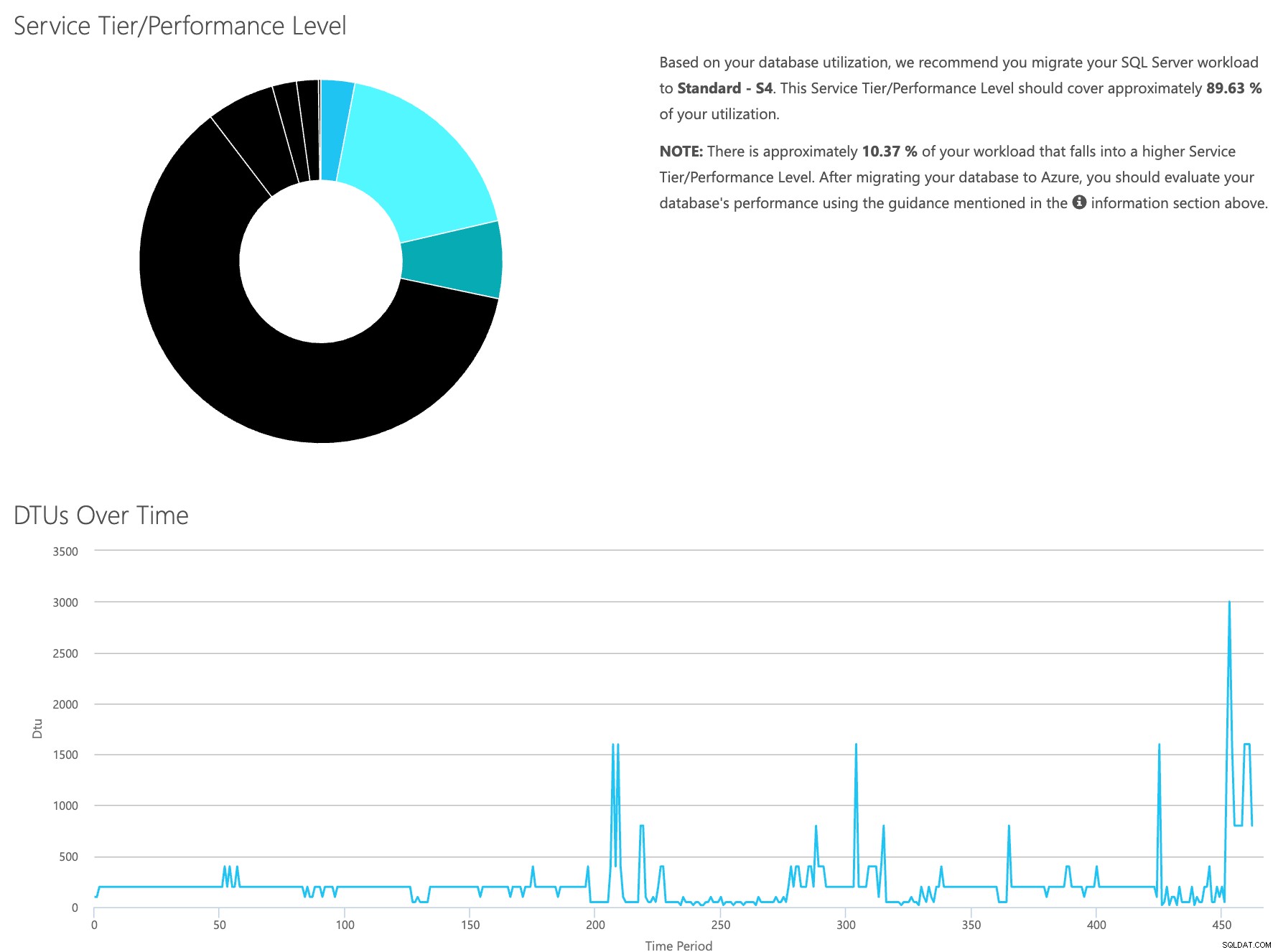
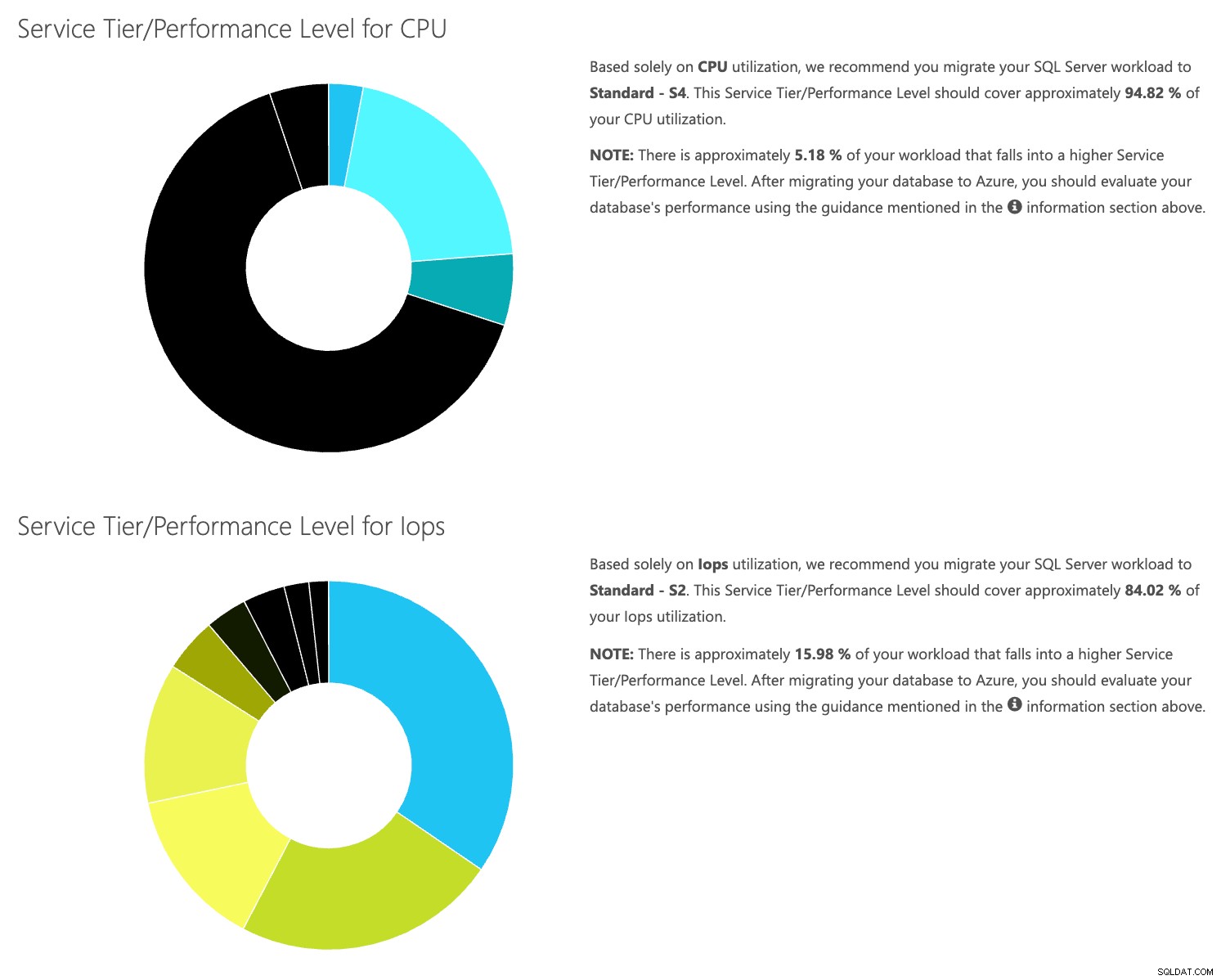
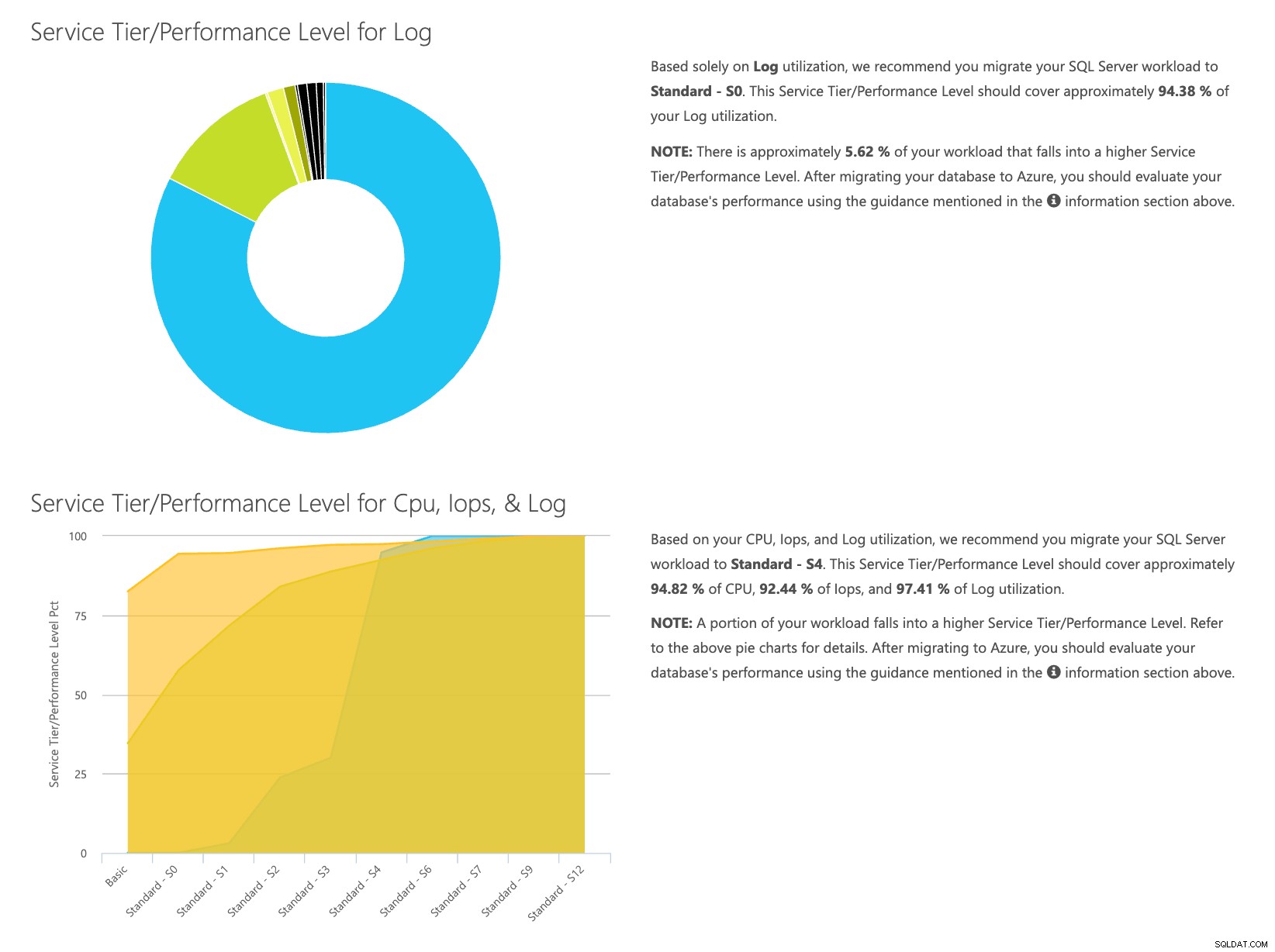
Karena Anda memiliki data yang disimpan secara terpisah, Anda dapat menganalisis beban kerja dari waktu yang berbeda-beda, dan Anda dapat melakukannya tanpa harus menjalankan\menjadwalkan utilitas perintah\skrip powershell secara manual untuk server mana pun yang telah Anda pantau oleh SentryOne.
Untuk meringkas langkah-langkah secara singkat, inilah yang perlu dilakukan:
- Aktifkan penghitung [Database – Log Bytes Flushed/sec], dan verifikasi data sedang dikumpulkan
- Salin data dari tabel SentryOne ke tabel Anda sendiri (dan jadwalkan jika perlu).
- Ekspor data dari tabel baru dalam format yang tepat untuk kalkulator DTU
- Unggah CSV ke Kalkulator DTU
Untuk server/instance apa pun yang Anda pertimbangkan untuk bermigrasi ke cloud, dan yang saat ini Anda pantau dengan SQL Sentry, ini adalah cara yang relatif mudah untuk memperkirakan jenis tingkat layanan yang Anda perlukan dan berapa biayanya. Anda masih perlu memantaunya setelah berada di atas sana; untuk itu, periksa SentryOne DB Sentry.
Tentang Penulis
 Dustin Dorsey saat ini adalah Managing Database Engineer untuk LifePoint Health di mana dia memimpin tim yang bertanggung jawab untuk mengelola dan merekayasa solusi dalam teknologi database untuk 90 rumah sakit. Dia telah bekerja dengan dan mendukung SQL Server terutama dalam perawatan kesehatan sejak 2008 dalam administrasi, arsitektur, pengembangan, dan kapasitas BI. Dia bersemangat menemukan cara untuk memecahkan masalah yang mengganggu DBA sehari-hari dan suka berbagi ini dengan orang lain. Dia dapat ditemukan berbicara di acara komunitas SQL, serta blogging di DustinDorsey.com.
Dustin Dorsey saat ini adalah Managing Database Engineer untuk LifePoint Health di mana dia memimpin tim yang bertanggung jawab untuk mengelola dan merekayasa solusi dalam teknologi database untuk 90 rumah sakit. Dia telah bekerja dengan dan mendukung SQL Server terutama dalam perawatan kesehatan sejak 2008 dalam administrasi, arsitektur, pengembangan, dan kapasitas BI. Dia bersemangat menemukan cara untuk memecahkan masalah yang mengganggu DBA sehari-hari dan suka berbagi ini dengan orang lain. Dia dapat ditemukan berbicara di acara komunitas SQL, serta blogging di DustinDorsey.com.