PostgreSQL adalah proyek yang luar biasa dan berkembang dengan kecepatan yang luar biasa. Kami akan fokus pada evolusi kemampuan toleransi kesalahan di PostgreSQL di seluruh versinya dengan serangkaian posting blog. Ini adalah postingan ketiga dari seri ini dan kita akan membicarakan masalah timeline dan pengaruhnya terhadap toleransi kesalahan dan ketergantungan PostgreSQL.
Jika Anda ingin menyaksikan kemajuan evolusi dari awal, silakan periksa dua posting blog pertama dari seri ini:
- Evolusi Toleransi Kesalahan di PostgreSQL
- Evolusi Fault Tolerance di PostgreSQL:Fase Replikasi

Garis Waktu
Kemampuan untuk memulihkan database ke titik waktu sebelumnya menciptakan beberapa kerumitan yang akan kita bahas beberapa kasus dengan menjelaskan failover (Gbr. 1), peralihan (Gbr. 2) dan pg_rewind (Gbr. 3) kasus selanjutnya dalam topik ini.
Misalnya, dalam riwayat asli database, misalkan Anda menjatuhkan tabel kritis pada pukul 17:15 pada Selasa malam, tetapi tidak menyadari kesalahan Anda hingga Rabu siang. Tidak terpengaruh, Anda mengeluarkan cadangan Anda, memulihkan ke titik waktu 17:14 Selasa malam, dan aktif dan berjalan. Dalam sejarah semesta database ini, Anda tidak pernah menjatuhkan meja. Tapi seandainya Anda kemudian menyadari ini bukan ide yang bagus, dan ingin kembali ke suatu hari Rabu pagi dalam sejarah aslinya. Anda tidak akan dapat melakukannya jika, saat database Anda aktif dan berjalan, database menimpa beberapa file segmen WAL yang mengarah ke waktu yang Anda inginkan sekarang.
Oleh karena itu, untuk menghindari hal ini, Anda perlu membedakan rangkaian catatan WAL yang dihasilkan setelah Anda melakukan pemulihan tepat waktu dari catatan yang dibuat dalam riwayat database asli.
Untuk mengatasi masalah ini, PostgreSQL memiliki gagasan tentang garis waktu. Setiap kali pemulihan arsip selesai, garis waktu baru dibuat untuk mengidentifikasi rangkaian catatan WAL yang dihasilkan setelah pemulihan itu. Nomor ID garis waktu adalah bagian dari nama file segmen WAL sehingga garis waktu baru tidak menimpa data WAL yang dihasilkan oleh garis waktu sebelumnya. Sebenarnya dimungkinkan untuk mengarsipkan banyak linimasa yang berbeda.
Pertimbangkan situasi di mana Anda tidak yakin titik waktu mana yang harus dipulihkan, dan karenanya harus melakukan beberapa pemulihan titik waktu dengan coba-coba sampai Anda menemukan tempat terbaik untuk bercabang dari sejarah lama. Tanpa garis waktu, proses ini akan segera menghasilkan kekacauan yang tidak terkendali. Dengan garis waktu, Anda dapat memulihkan ke keadaan sebelumnya, termasuk keadaan di cabang garis waktu yang Anda tinggalkan sebelumnya.
Setiap kali garis waktu baru dibuat, PostgreSQL membuat file "riwayat garis waktu" yang menunjukkan dari mana garis waktu itu bercabang dan kapan. File riwayat ini diperlukan untuk memungkinkan sistem memilih file segmen WAL yang tepat saat memulihkan dari arsip yang berisi beberapa garis waktu. Oleh karena itu, mereka diarsipkan ke dalam area arsip WAL seperti file segmen WAL. File riwayat hanyalah file teks kecil, jadi murah dan tepat untuk menyimpannya tanpa batas waktu (tidak seperti file segmen yang besar). Anda dapat, jika mau, menambahkan komentar ke file riwayat untuk merekam catatan Anda sendiri tentang bagaimana dan mengapa garis waktu khusus ini dibuat. Komentar seperti itu akan sangat berharga ketika Anda memiliki kumpulan garis waktu yang berbeda sebagai hasil dari eksperimen.
Perilaku default pemulihan adalah memulihkan di sepanjang garis waktu yang sama dengan saat ini saat pencadangan dasar diambil. Jika Anda ingin memulihkan ke beberapa lini masa anak (yaitu, Anda ingin kembali ke beberapa status yang dibuat sendiri setelah upaya pemulihan), Anda perlu menentukan ID linimasa target di recovery.conf. Anda tidak dapat memulihkan ke garis waktu yang bercabang lebih awal dari pencadangan dasar.
Untuk menyederhanakan konsep garis waktu di PostgreSQL, masalah terkait garis waktu jika terjadi failover , beralih dan pg_rewind diringkas dan dijelaskan dengan Gbr.1, Gbr.2 dan Gbr.3.
Skenario kegagalan:
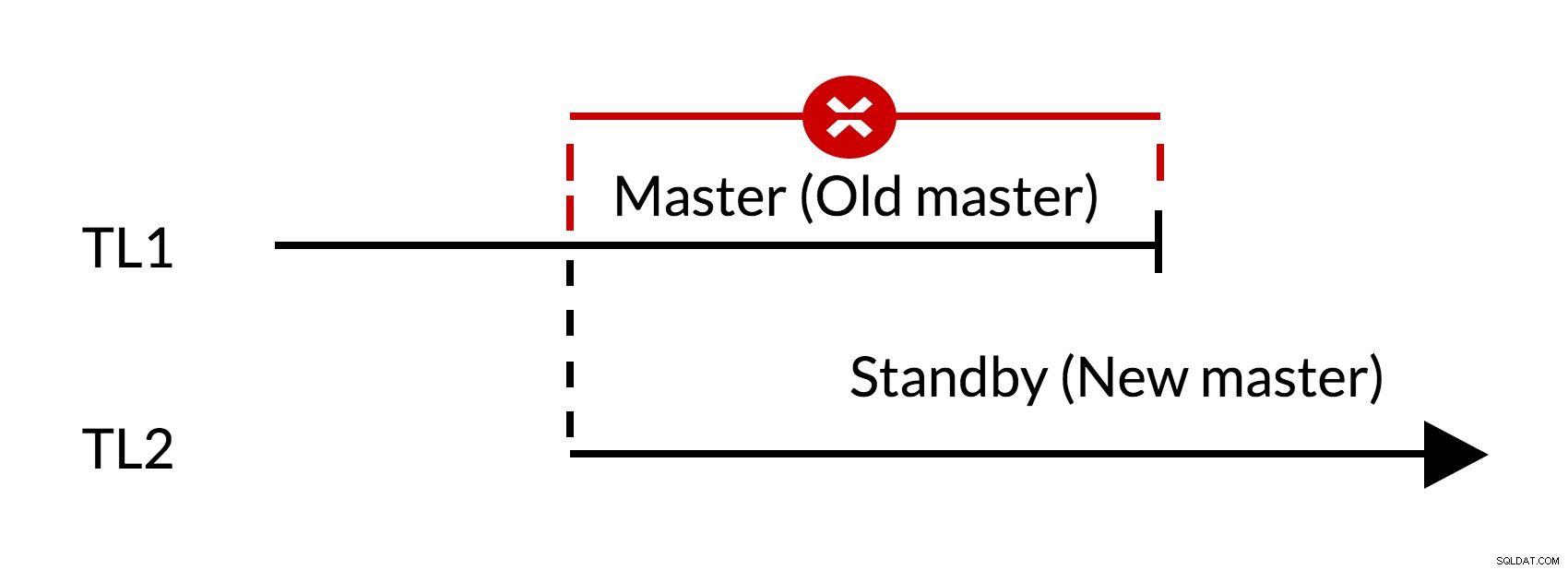
Gbr.1 Kegagalan
- Ada perubahan luar biasa pada master lama (TL1)
- Peningkatan garis waktu menunjukkan riwayat perubahan baru (TL2)
- Perubahan dari timeline lama tidak dapat diputar ulang di server yang beralih ke timeline baru
- Tuan lama tidak bisa mengikuti tuan baru
Skenario peralihan:
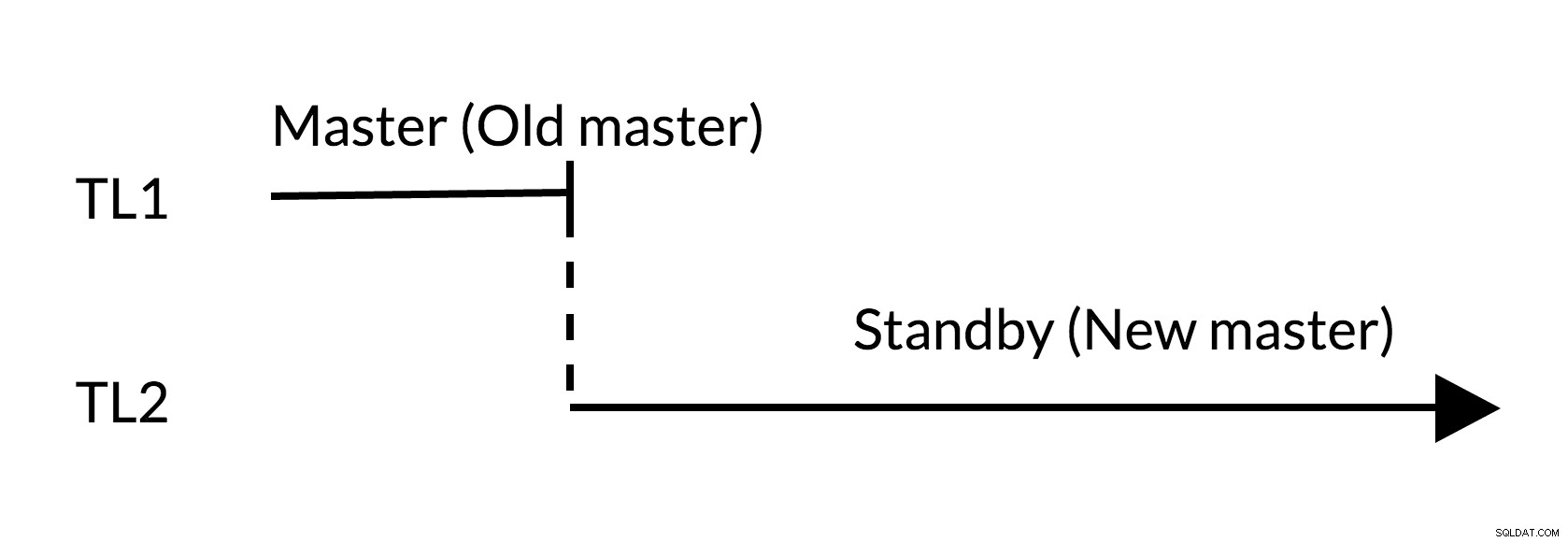 Gbr.2 Peralihan
Gbr.2 Peralihan
- Tidak ada perubahan yang menonjol pada master lama (TL1)
- Peningkatan garis waktu menunjukkan riwayat perubahan baru (TL2)
- Master lama dapat menjadi standby untuk master baru
skenario pg_rewind:
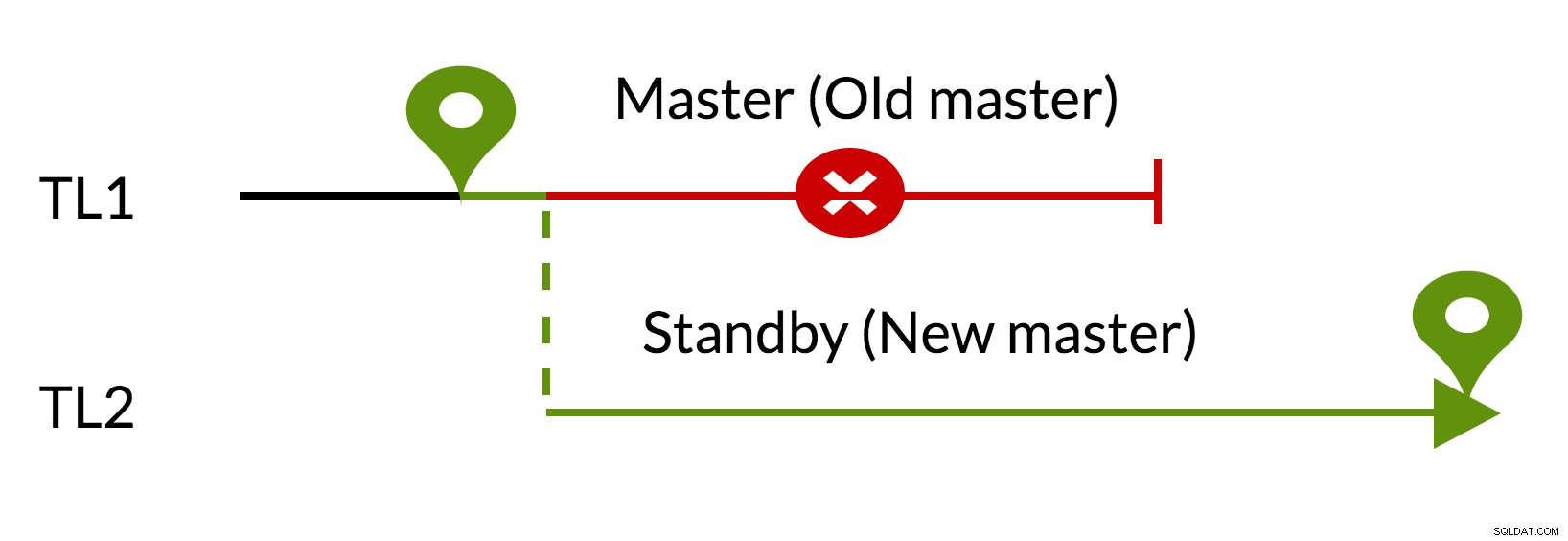 Gbr.3 pg_rewind
Gbr.3 pg_rewind
- Perubahan yang belum terselesaikan akan dihapus menggunakan data dari master baru (TL1)
- Master lama dapat mengikuti master baru (TL2)
pg_rewind
pg_rewind adalah alat untuk menyinkronkan cluster PostgreSQL dengan salinan lain dari cluster yang sama, setelah garis waktu cluster berbeda. Skenario yang umum adalah membawa server master lama kembali online setelah failover, sebagai standby yang mengikuti master baru.
Hasilnya setara dengan mengganti direktori data target dengan direktori sumber. Semua file disalin, termasuk file konfigurasi. Keuntungan pg_rewind dibandingkan mengambil cadangan basis baru, atau alat seperti rsync, adalah pg_rewind tidak memerlukan membaca semua file yang tidak berubah di cluster. Itu membuatnya jauh lebih cepat ketika database besar dan hanya sebagian kecil yang berbeda antar cluster.
Bagaimana cara kerjanya?
Ide dasarnya adalah menyalin semuanya dari cluster baru ke cluster lama, kecuali blok yang kita ketahui sama.
- Pindai log WAL klaster lama, mulai dari pos pemeriksaan terakhir sebelum titik di mana riwayat garis waktu klaster baru bercabang dari klaster lama. Untuk setiap catatan WAL, buat catatan blok data yang disentuh. Ini menghasilkan daftar semua blok data yang diubah di cluster lama, setelah cluster baru bercabang.
- Salin semua blok yang diubah dari cluster baru ke cluster lama.
- Salin semua file lain seperti clog dan file konfigurasi dari cluster baru ke cluster lama, semuanya kecuali file relasi.
- Terapkan WAL dari cluster baru, mulai dari pos pemeriksaan yang dibuat saat failover. (Sebenarnya, pg_rewind tidak menerapkan WAL, itu hanya membuat file label cadangan yang menunjukkan bahwa ketika PostgreSQL dimulai, itu akan mulai memutar ulang dari pos pemeriksaan itu dan menerapkan semua WAL yang diperlukan.)
Catatan: wal_log_hints harus disetel di postgresql.conf agar pg_rewind dapat bekerja. Parameter ini hanya dapat disetel saat server mulai. Nilai defaultnya adalah nonaktif .
Kesimpulan
Dalam posting blog ini, kami membahas garis waktu di Postgres dan bagaimana kami menangani kasus failover dan switchover. Kami juga berbicara tentang cara kerja pg_rewind dan manfaatnya bagi toleransi kesalahan dan ketergantungan Postgres. Kami akan melanjutkan dengan komit sinkron di entri blog berikutnya.
Referensi
Dokumentasi PostgreSQL
Buku Masak Administrasi PostgreSQL 9 – Edisi Kedua
pg_rewind Presentasi PGDay Nordik oleh Heikki Linnakangas



