Untuk T-SQL Selasa bulan ini, Steve Jones (@way0utwest) meminta kami untuk berbicara tentang pengalaman pemicu terbaik atau terburuk kami. Meskipun benar bahwa pemicu sering kali tidak disukai, dan bahkan ditakuti, pemicu tersebut memiliki beberapa kasus penggunaan yang valid, termasuk:
- Audit (sebelum 2016 SP1, ketika fitur ini menjadi gratis di semua edisi)
- Penegakan aturan bisnis dan integritas data, ketika aturan tersebut tidak dapat dengan mudah diterapkan dalam batasan, dan Anda tidak ingin aturan tersebut bergantung pada kode aplikasi atau kueri DML itu sendiri
- Mempertahankan versi historis data (sebelum Ubah Pengambilan Data, Ubah Pelacakan, dan Tabel Temporal)
- Peringatan antrian atau pemrosesan asinkron sebagai respons terhadap perubahan tertentu
- Mengizinkan modifikasi tampilan (melalui BUKAN pemicu)
Itu bukan daftar yang lengkap, hanya rekap singkat dari beberapa skenario yang saya alami di mana pemicu adalah jawaban yang tepat saat itu.
Ketika pemicu diperlukan, saya selalu ingin mengeksplorasi penggunaan INSTEAD OF triggers daripada AFTER triggers. Ya, mereka sedikit lebih banyak pekerjaan di muka*, tetapi mereka memiliki beberapa manfaat yang cukup penting. Secara teori, setidaknya, prospek mencegah suatu tindakan (dan konsekuensi lognya) terjadi tampaknya jauh lebih efisien daripada membiarkan semuanya terjadi dan kemudian membatalkannya.
*Saya mengatakan ini karena Anda harus mengkodekan pernyataan DML lagi di dalam pemicu; inilah mengapa mereka tidak disebut pemicu SEBELUM. Perbedaannya penting di sini, karena beberapa sistem menerapkan pemicu SEBELUM yang sebenarnya, yang hanya dijalankan terlebih dahulu. Di SQL Server, pemicu INSTEAD OF secara efektif membatalkan pernyataan yang menyebabkannya terpicu.
Anggap saja kita memiliki tabel sederhana untuk menyimpan nama akun. Dalam contoh ini kami akan membuat dua tabel, sehingga kami dapat membandingkan dua pemicu yang berbeda dan dampaknya terhadap durasi kueri dan penggunaan log. Konsepnya adalah kami memiliki aturan bisnis:nama akun tidak ada di tabel lain, yang mewakili nama "buruk", dan pemicu digunakan untuk menegakkan aturan ini. Berikut databasenya:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Dan tabelnya:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Dan yang terakhir adalah pemicunya. Untuk mempermudah, kita hanya berurusan dengan sisipan, dan dalam kasus setelah dan sebagai ganti, kita hanya akan membatalkan seluruh kumpulan jika ada satu nama yang melanggar aturan kita:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Sekarang, untuk menguji kinerja, kami hanya akan mencoba memasukkan 100.000 nama ke dalam setiap tabel, dengan tingkat kegagalan yang dapat diprediksi sebesar 10%. Dengan kata lain, 90.000 adalah nama yang baik-baik saja, 10.000 lainnya gagal dalam pengujian dan menyebabkan pemicu melakukan rollback atau tidak menyisipkan tergantung pada kumpulan.
Pertama, kita perlu melakukan pembersihan sebelum setiap batch:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Sebelum kita memulai daging setiap batch, kita akan menghitung baris di log transaksi, dan mengukur ukuran dan ruang kosong. Kemudian kita akan melewati kursor untuk memproses 100.000 baris dalam urutan acak, mencoba memasukkan setiap nama ke dalam tabel yang sesuai. Setelah selesai, kami akan mengukur jumlah baris dan ukuran log lagi, dan memeriksa durasinya.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Hasil (rata-rata lebih dari 5 putaran setiap batch):
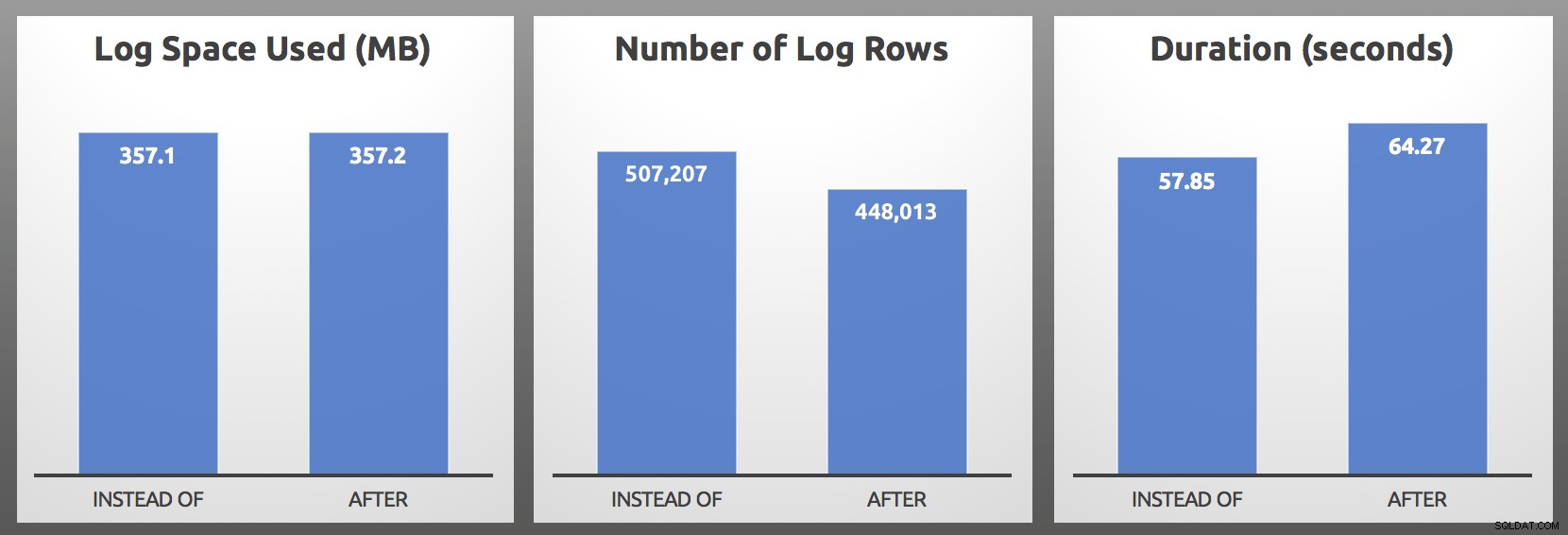 SETELAH vs. BUKAN :Hasil
SETELAH vs. BUKAN :Hasil
Dalam pengujian saya, penggunaan log hampir sama ukurannya, dengan lebih dari 10% lebih banyak baris log yang dihasilkan oleh pemicu BUKAN. Saya melakukan penggalian di akhir setiap batch:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Dan inilah hasil yang umum (saya menyoroti delta utama):
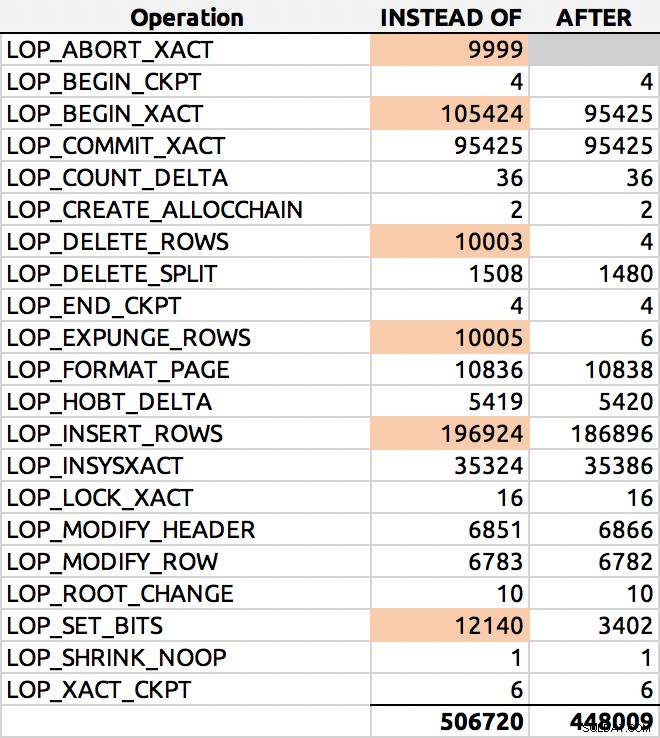 Distribusi baris log
Distribusi baris log
Saya akan menggalinya lebih dalam di lain waktu.
Tetapi ketika Anda langsung melakukannya…
…metrik terpenting hampir selalu adalah durasi , dan dalam kasus saya pemicu BUKAN dilakukan setidaknya 5 detik lebih cepat di setiap tes head-to-head. Jika ini semua terdengar akrab, ya, saya sudah membicarakannya sebelumnya, tetapi saat itu saya tidak mengamati gejala yang sama dengan baris log.
Perhatikan bahwa ini mungkin bukan skema atau beban kerja Anda yang sebenarnya, Anda mungkin memiliki perangkat keras yang sangat berbeda, konkurensi Anda mungkin lebih tinggi, dan tingkat kegagalan Anda mungkin jauh lebih tinggi (atau lebih rendah). Pengujian saya dilakukan pada mesin yang terisolasi dengan banyak memori dan SSD PCIe yang sangat cepat. Jika log Anda berada di drive yang lebih lambat, perbedaan dalam penggunaan log mungkin lebih besar daripada metrik lainnya dan mengubah durasi secara signifikan. Semua faktor ini (dan banyak lagi!) dapat memengaruhi hasil Anda, jadi Anda harus menguji di lingkungan Anda.
Intinya, BUKAN pemicu mungkin lebih cocok. Sekarang kalau saja kita bisa mendapatkan BUKAN pemicu DDL…