Saya senang menghadiri PGDay UK minggu lalu – acara yang sangat bagus, semoga saya memiliki kesempatan untuk datang kembali tahun depan. Ada banyak pembicaraan menarik, tetapi yang menarik perhatian saya khususnya adalah Performace untuk kueri dengan pengelompokan oleh Alexey Bashtanov.
Saya telah memberikan cukup banyak pembicaraan berorientasi kinerja serupa di masa lalu, jadi saya tahu betapa sulitnya menyajikan hasil benchmark dengan cara yang dapat dipahami dan menarik, dan Alexey melakukan pekerjaan yang cukup bagus, saya pikir. Jadi, jika Anda berurusan dengan agregasi data (yaitu BI, analitik, atau beban kerja serupa) saya sarankan membaca slide dan jika Anda mendapat kesempatan untuk menghadiri pembicaraan di beberapa konferensi lain, saya sangat menyarankan melakukannya.
Tapi ada satu titik di mana saya tidak setuju dengan pembicaraan itu. Di sejumlah tempat pembicaraan menyarankan bahwa Anda biasanya lebih memilih HashAggregate, karena jenisnya lambat.
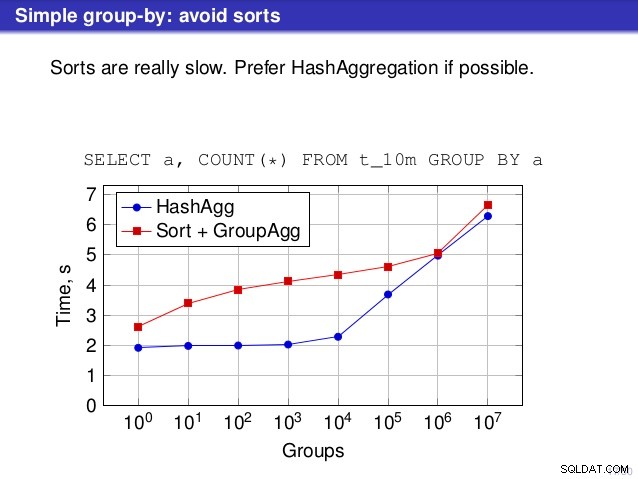
Saya menganggap ini agak menyesatkan, karena alternatif untuk HashAggregate adalah GroupAggregate, bukan Sort. Jadi rekomendasi mengasumsikan bahwa setiap GroupAggregate memiliki Sort bersarang, tapi itu tidak sepenuhnya benar. GroupAggregate memerlukan input yang diurutkan, dan Sortir eksplisit bukan satu-satunya cara untuk melakukannya – kami juga memiliki node IndexScan dan IndexOnlyScan, yang menghilangkan biaya pengurutan dan mempertahankan manfaat lain yang terkait dengan jalur yang diurutkan (terutama IndexOnlyScan).
Izinkan saya menunjukkan bagaimana (IndexOnlyScan+GroupAggregate) bekerja dibandingkan dengan HashAggregate dan (Sort+GroupAggregate) – skrip yang saya gunakan untuk pengukuran ada di sini. Itu membangun empat tabel sederhana, masing-masing dengan 100 juta baris dan jumlah grup yang berbeda di kolom "branch_id" (menentukan ukuran tabel hash). Yang terkecil memiliki 10k grup
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
dan tiga tabel tambahan memiliki grup 100rb, 1M, dan 5M. Mari kita jalankan kueri sederhana ini dengan menggabungkan data:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
lalu yakinkan database untuk menggunakan tiga paket berbeda:
1) HashAggregate
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (dengan Sortir)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (dengan IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Hasil
Setelah mengukur waktu untuk setiap rencana di semua tabel, hasilnya terlihat seperti ini:
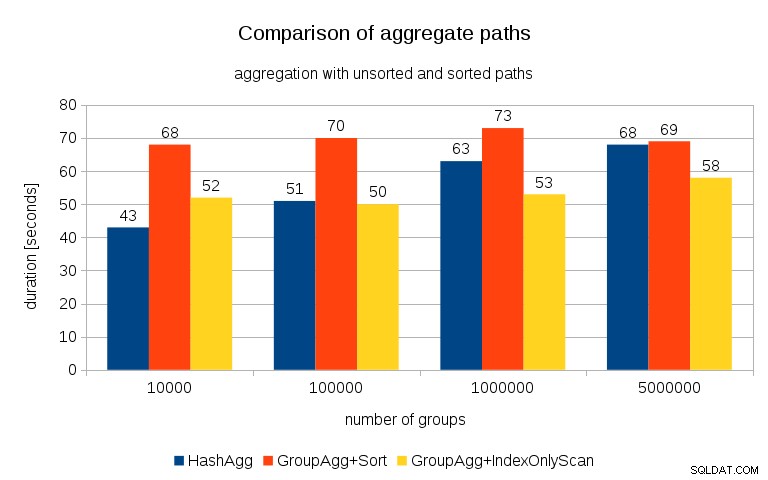
Untuk tabel hash kecil (sesuai dengan cache L3, yaitu 16MB dalam kasus ini), jalur HashAggregate jelas lebih cepat daripada kedua jalur yang diurutkan. Tapi segera GroupAgg+IndexOnlyScan menjadi sama cepat atau bahkan lebih cepat – ini karena efisiensi cache, keuntungan utama GroupAggregate. Sementara HashAggregate perlu menyimpan seluruh tabel hash dalam memori sekaligus, GroupAggregate hanya perlu menyimpan grup terakhir. Dan semakin sedikit memori yang Anda gunakan, semakin besar kemungkinan untuk memasukkannya ke dalam cache L3, yang kira-kira urutan besarnya lebih cepat dibandingkan dengan RAM biasa (untuk cache L1/L2 perbedaannya bahkan lebih besar).
Jadi meskipun ada overhead yang cukup besar yang terkait dengan IndexOnlyScan (untuk kasus 10k ini sekitar 20% lebih lambat dari jalur HashAggregate), karena tabel hash tumbuh, rasio hit cache L3 dengan cepat turun dan perbedaan akhirnya membuat GroupAggregate lebih cepat. Dan akhirnya bahkan GroupAggregate+Sort setara dengan jalur HashAggregate.
Anda mungkin berpendapat bahwa data Anda umumnya memiliki jumlah grup yang cukup rendah, dan dengan demikian tabel hash akan selalu masuk ke cache L3. Tetapi pertimbangkan bahwa cache L3 digunakan bersama oleh semua proses yang berjalan di CPU, dan juga oleh semua bagian dari rencana kueri. Jadi, meskipun saat ini kami memiliki ~20MB cache L3 per soket, kueri Anda hanya akan mendapatkan sebagian dari itu, dan bit itu akan dibagikan oleh semua node dalam kueri Anda (mungkin cukup rumit).
Pembaruan 2016/07/26 :Seperti yang ditunjukkan dalam komentar oleh Peter Geoghegan, cara data dihasilkan mungkin menghasilkan korelasi – bukan nilai (atau lebih tepatnya hash dari nilai), tetapi alokasi memori. Saya telah mengulangi kueri dengan data yang diacak dengan benar, yaitu melakukan
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
bukannya
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
dan hasilnya seperti ini:
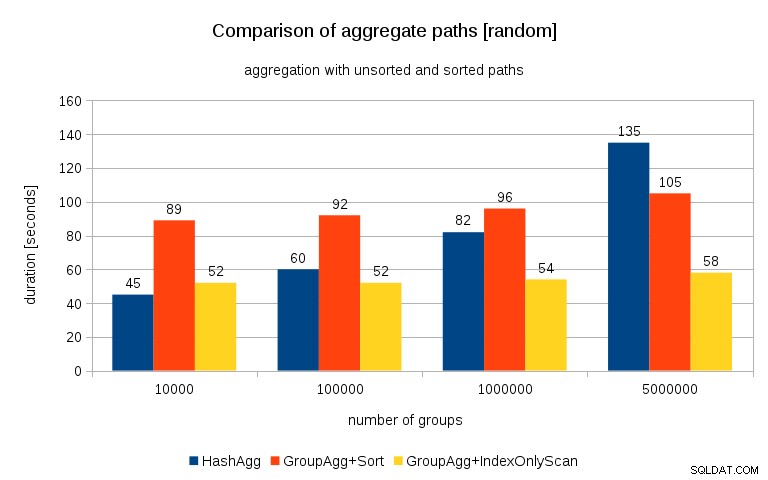
Membandingkan ini dengan bagan sebelumnya, saya pikir cukup jelas hasilnya bahkan lebih mendukung jalur yang diurutkan, terutama untuk kumpulan data dengan grup 5 juta. Kumpulan data 5 juta juga menunjukkan bahwa GroupAgg dengan Sort eksplisit mungkin lebih cepat daripada HashAgg.
Ringkasan
Meskipun HashAggregate mungkin lebih cepat daripada GroupAggregate dengan Sort eksplisit (walaupun saya ragu untuk mengatakan bahwa hal itu selalu terjadi), menggunakan GroupAggregate dengan IndexOnlyScan lebih cepat dapat dengan mudah membuatnya jauh lebih cepat daripada HashAggregate.
Tentu saja, Anda tidak dapat memilih paket yang tepat secara langsung – perencana harus melakukannya untuk Anda. Tetapi Anda memengaruhi proses pemilihan dengan (a) membuat indeks dan (b) menyetel work_mem . Itulah mengapa terkadang menurunkan work_mem (dan maintenance_work_mem ) nilai menghasilkan kinerja yang lebih baik.
Namun, indeks tambahan tidak gratis – keduanya menghabiskan waktu CPU (saat memasukkan data baru), dan ruang disk. Untuk IndexOnlyScans, persyaratan ruang disk mungkin cukup signifikan karena indeks perlu menyertakan semua kolom yang direferensikan oleh kueri, dan IndexScan biasa tidak akan memberi Anda kinerja yang sama karena menghasilkan banyak I/O acak terhadap tabel (menghilangkan semua potensi keuntungan).
Fitur bagus lainnya adalah stabilitas kinerja – perhatikan bagaimana peluang waktu HashAggregate bergantung pada jumlah grup, sedangkan jalur GroupAggregate sebagian besar berkinerja sama.