Replikasi Streaming PostgreSQL adalah cara yang bagus untuk menskalakan kluster PostgreSQL dan melakukannya menambah ketersediaan tinggi untuk mereka. Seperti halnya setiap replikasi, idenya adalah bahwa slave adalah salinan dari master dan bahwa slave terus diperbarui dengan perubahan yang terjadi pada master menggunakan semacam mekanisme replikasi.
Mungkin saja slave, karena alasan tertentu, tidak sinkron dengan master. Bagaimana cara mengembalikannya ke rantai replikasi? Bagaimana saya bisa memastikan bahwa slave kembali sinkron dengan master? Mari kita lihat postingan blog singkat ini.
Apa yang sangat membantu, tidak ada cara untuk menulis pada budak jika dalam mode pemulihan. Anda dapat mengujinya seperti itu:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionMasih mungkin terjadi bahwa slave tidak sinkron dengan master. Kerusakan data - baik perangkat keras maupun perangkat lunak tidak memiliki bug dan masalah. Beberapa masalah dengan drive disk dapat memicu kerusakan data pada slave. Beberapa masalah dengan proses "vakum" dapat mengakibatkan data diubah. Bagaimana memulihkan dari keadaan itu?
Membangun Kembali Budak Menggunakan pg_basebackup
Langkah utama adalah menyediakan budak menggunakan data dari master. Mengingat bahwa kami akan menggunakan replikasi streaming, kami tidak dapat menggunakan pencadangan logis. Untungnya ada alat siap pakai yang dapat digunakan untuk menyiapkan:pg_basebackup. Mari kita lihat langkah-langkah apa yang perlu kita ambil untuk menyediakan server budak. Untuk memperjelas, kami menggunakan PostgreSQL 12 untuk tujuan posting blog ini.
Status awalnya sederhana. Budak kita tidak meniru dari tuannya. Data yang dikandungnya rusak dan tidak dapat digunakan atau dipercaya. Oleh karena itu langkah pertama yang akan kita lakukan adalah menghentikan PostgreSQL pada slave kita dan menghapus data yang ada di dalamnya:
example@sqldat.com:~# systemctl stop postgresqlAtau bahkan:
example@sqldat.com:~# killall -9 postgresSekarang, mari kita periksa isi file postgresql.auto.conf, kita dapat menggunakan kredensial replikasi yang disimpan dalam file itu nanti, untuk pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Kami tertarik dengan pengguna dan sandi yang digunakan untuk menyiapkan replikasi.
Akhirnya kita bisa menghapus datanya:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Setelah data dihapus, kita perlu menggunakan pg_basebackup untuk mendapatkan data dari master:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointBendera yang kami gunakan memiliki arti sebagai berikut:
- -Xs: kami ingin melakukan streaming WAL saat cadangan dibuat. Ini membantu menghindari masalah saat menghapus file WAL saat Anda memiliki kumpulan data yang besar.
- -P: kami ingin melihat kemajuan pencadangan.
- -R: kami ingin pg_basebackup membuat file standby.signal dan menyiapkan file postgresql.auto.conf dengan pengaturan koneksi.
pg_basebackup akan menunggu pos pemeriksaan sebelum memulai pencadangan. Jika terlalu lama, Anda dapat menggunakan dua opsi. Pertama, dimungkinkan untuk mengatur mode pos pemeriksaan menjadi cepat di pg_basebackup menggunakan opsi '-c fast'. Atau, Anda dapat memaksa pos pemeriksaan dengan menjalankan:
postgres=# CHECKPOINT;
CHECKPOINTDengan satu atau lain cara, pg_basebackup akan dimulai. Dengan flag -P kita dapat melacak kemajuannya:
416906/1588478 kB (26%), 0/1 tablespaceceaceSetelah cadangan siap, yang harus kita lakukan adalah memastikan konten direktori data memiliki pengguna dan grup yang ditetapkan dengan benar - kita mengeksekusi pg_basebackup sebagai 'root' oleh karena itu kita ingin mengubahnya menjadi 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Itu saja, kita bisa memulai slave dan harus mulai mereplikasi dari master.
example@sqldat.com:~# systemctl start postgresqlAnda dapat memeriksa ulang kemajuan replikasi dengan menjalankan kueri berikut di master:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Seperti yang Anda lihat, kedua slave mereplikasi dengan benar.
Membangun Kembali Slave Menggunakan ClusterControl
Jika Anda adalah pengguna ClusterControl, Anda dapat dengan mudah mencapai hal yang sama persis hanya dengan memilih opsi dari UI.
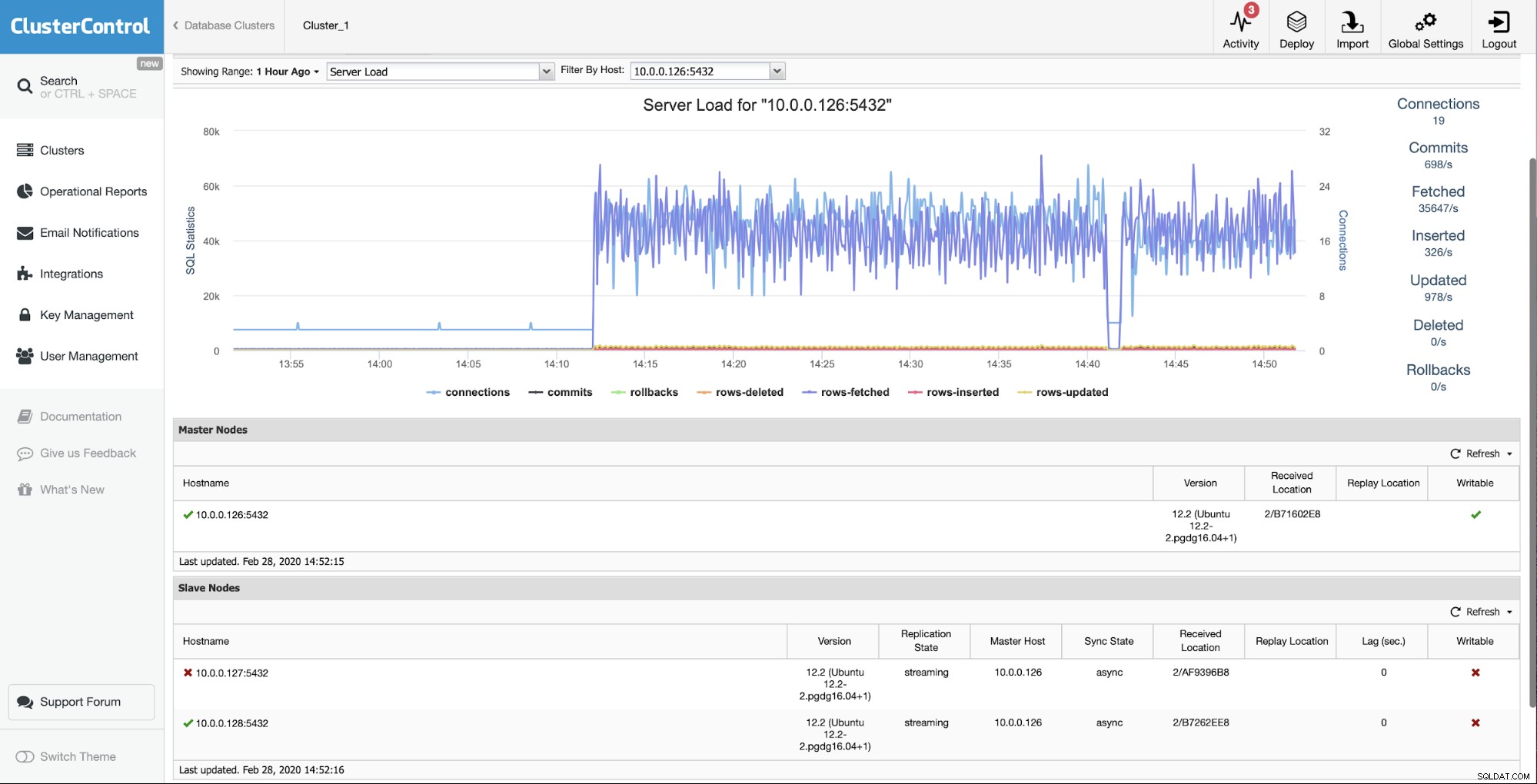
Situasi awalnya adalah salah satu budak (10.0.0.127) adalah tidak berfungsi dan tidak mereplikasi. Kami menganggap bahwa membangun kembali adalah pilihan terbaik bagi kami.
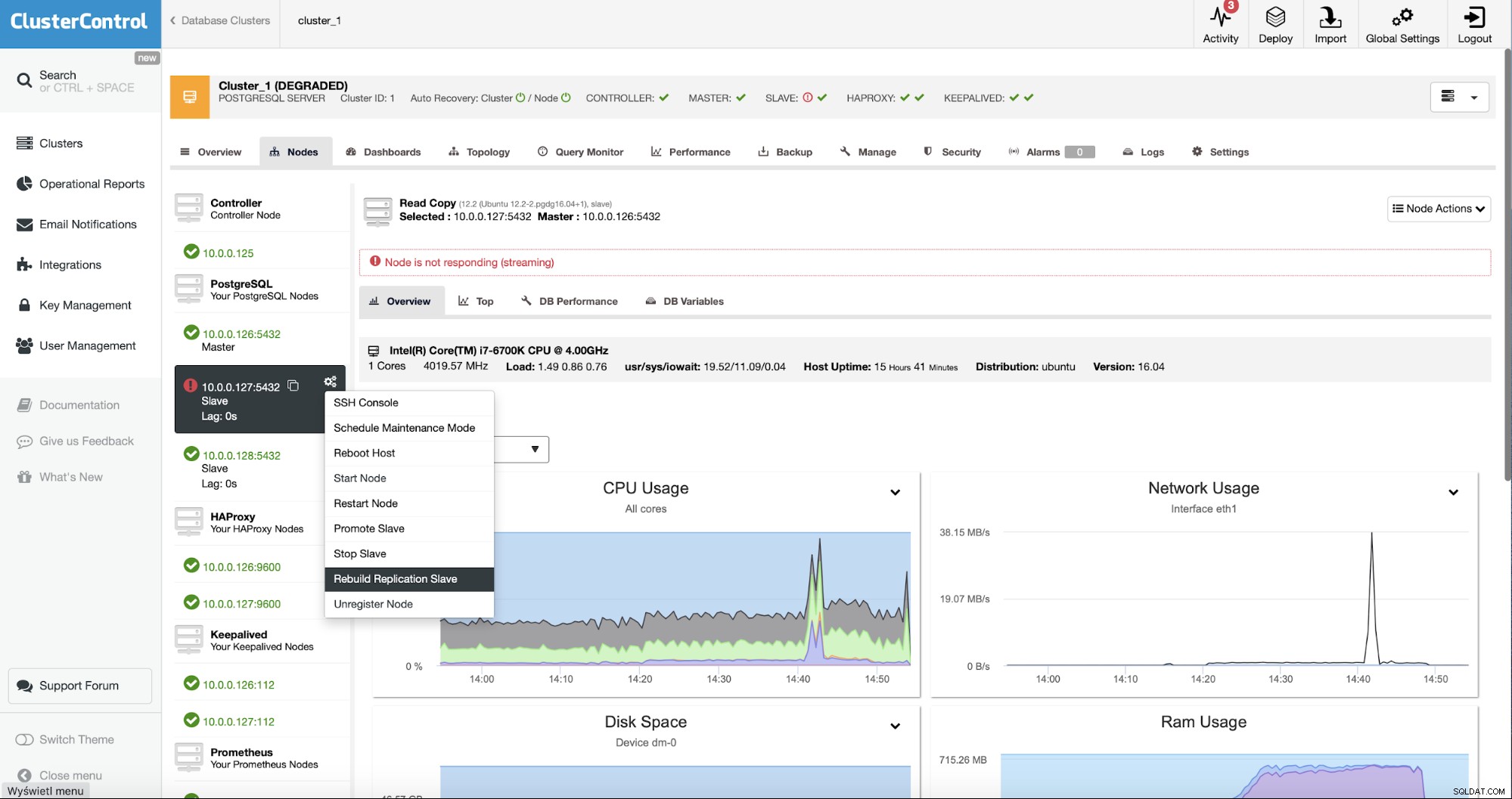
Sebagai pengguna ClusterControl yang harus kita lakukan adalah membuka “Node ” dan jalankan tugas “Rebuild Replication Slave”.
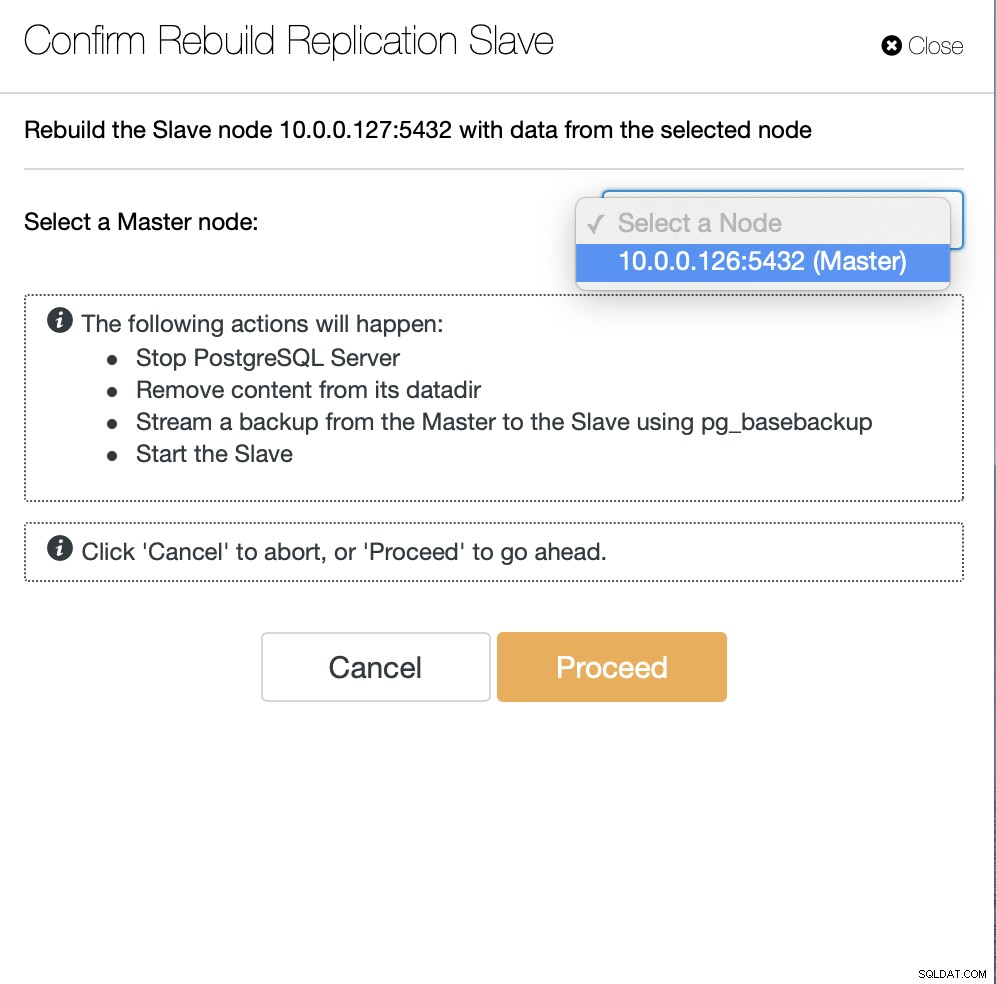
Selanjutnya, kita harus memilih node untuk membangun kembali slave dan itu adalah semua. ClusterControl akan menggunakan pg_basebackup untuk menyiapkan slave replikasi dan mengonfigurasi replikasi segera setelah data ditransfer.
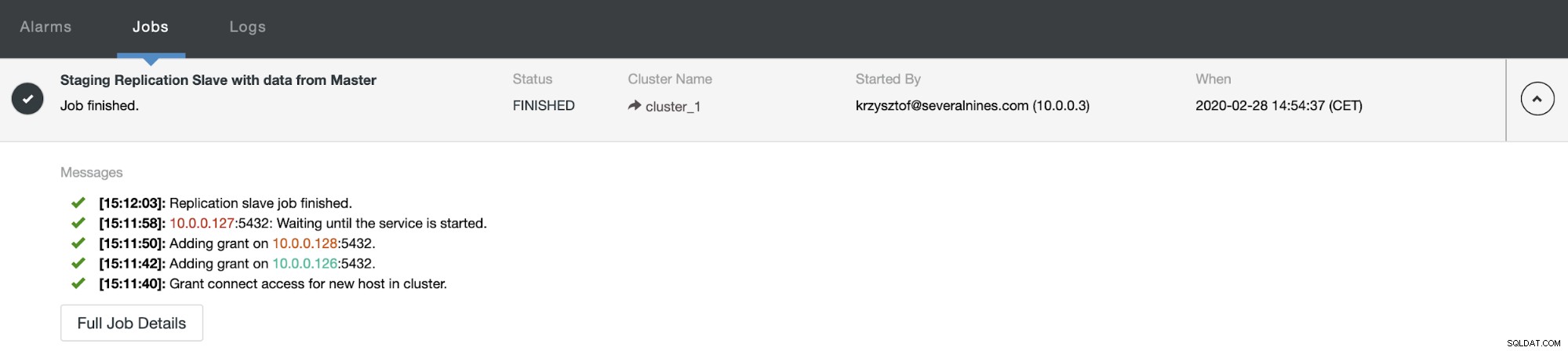
Setelah beberapa waktu pekerjaan selesai dan slave kembali dalam rantai replikasi:
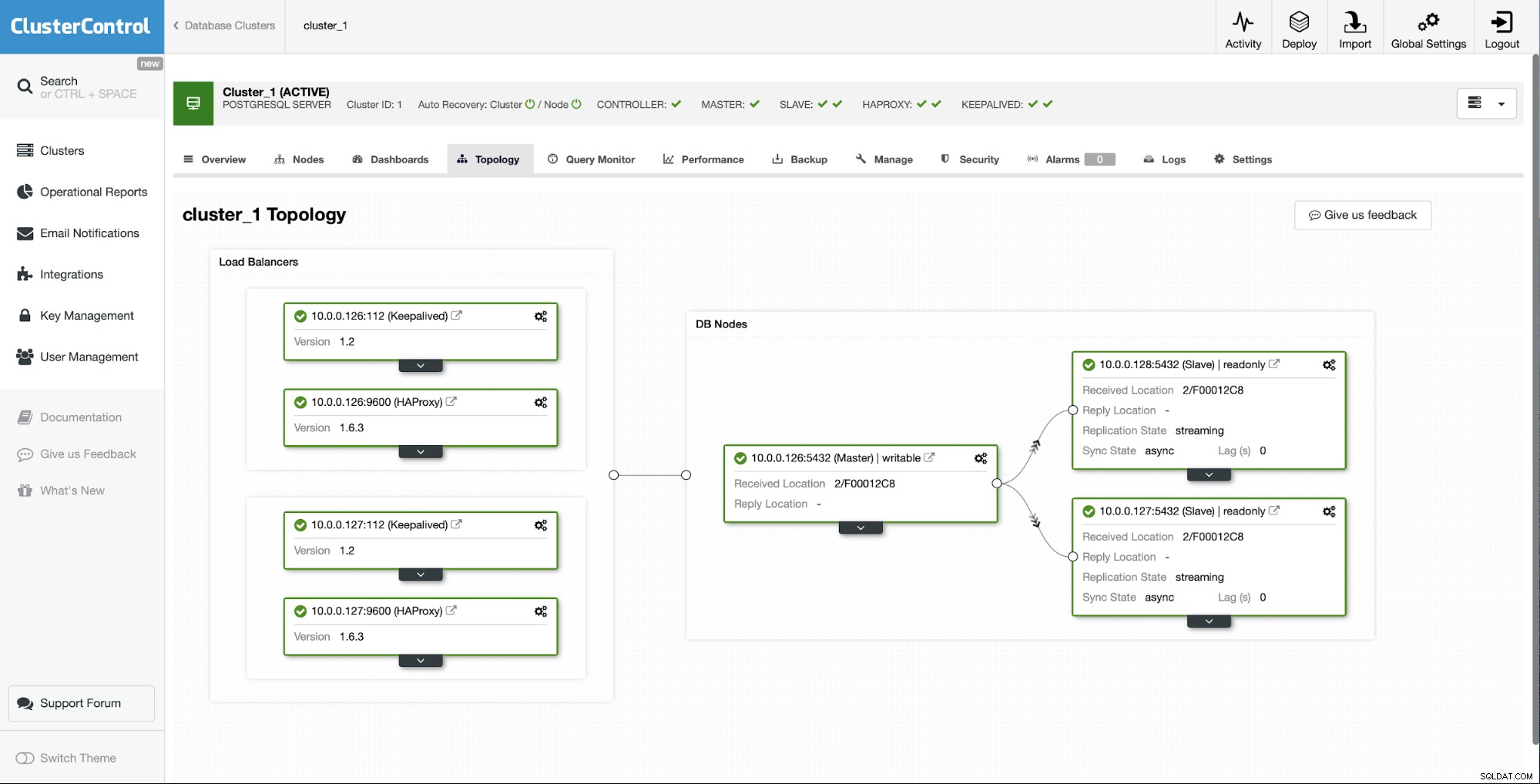
Seperti yang Anda lihat, hanya dengan beberapa klik, berkat ClusterControl, kami berhasil membangun kembali slave kami yang gagal dan mengembalikannya ke cluster.