Pelajari arsitektur penyerapan data hampir real-time untuk mengubah dan memperkaya aliran data menggunakan Apache Flume, Apache Kafka, dan RocksDB di Santander UK.
Cloudera Professional Services telah bekerja sama dengan Santander UK untuk membangun sistem analisis transaksi hampir real-time (NRT) di Apache Hadoop. Tujuannya adalah untuk menangkap, mengubah, memperkaya, menghitung, dan menyimpan transaksi dalam beberapa detik setelah pembelian kartu terjadi. Sistem menerima transaksi kartu pelanggan ritel bank dan menghitung informasi tren terkait yang dikumpulkan oleh pemegang rekening dan melalui sejumlah dimensi dan taksonomi. Informasi ini kemudian disajikan dengan aman ke aplikasi “Spendlytics” Santander (lihat di bawah) untuk memungkinkan pelanggan menganalisis pola pengeluaran terbaru mereka.
Apache HBase dipilih sebagai solusi penyimpanan dasar karena kemampuannya untuk mendukung penulisan acak throughput tinggi, dan pembacaan acak latensi rendah. Namun, persyaratan NRT mengesampingkan melakukan transformasi dan pengayaan transaksi dalam batch, jadi ini harus dilakukan saat transaksi dialirkan ke HBase. Ini termasuk mengubah pesan dari XML ke Avro dan memperkayanya dengan informasi trendi, seperti informasi merek dan pedagang.
Posting ini menjelaskan bagaimana Santander menggunakan Apache Flume, Apache Kafka, dan RocksDB untuk mengubah, memperkaya, dan mengalirkan transaksi ke HBase. Ini adalah implementasi dari NRT Event Processing with External Context pola streaming yang dijelaskan oleh Ted Malaska di postingan ini.
Flafka
Keputusan pertama yang harus dibuat Santander adalah cara terbaik untuk mengalirkan data ke HBase. Flume hampir selalu merupakan pilihan terbaik untuk penyerapan streaming ke Hadoop karena kesederhanaan, keandalan, beragam sumber dan sink, dan skalabilitas yang melekat.
Baru-baru ini, integrasi yang sangat baik ke Kafka telah ditambahkan yang mengarah ke Flafka yang tak terhindarkan. Flume secara native dapat memberikan jaminan pengiriman acara melalui saluran file-nya, tetapi kemampuan untuk memutar ulang acara dan fleksibilitas tambahan serta menghadirkan Kafka yang tahan di masa depan adalah pendorong utama untuk integrasi.
Dalam arsitektur ini, Santander menggunakan saluran Kafka untuk menyediakan buffer penyerapan yang andal, self-balancing, dan skalabel di mana semua transformasi dan pemrosesan diwakili dalam topik Kafka yang dirantai. Secara khusus, kami menggunakan sumber dan sink Flafka secara ekstensif, dan kemampuan Flume untuk melakukan pemrosesan dalam penerbangan menggunakan Interceptors. Hal ini mencegah kami untuk membuat kode produsen dan konsumen Kafka kami sendiri, dan memungkinkan Santander untuk memanfaatkan Cloudera Manager sepenuhnya untuk mengonfigurasi, menerapkan, dan memantau agen dan broker.
Transformasi
Transaksi yang ditangkap oleh sistem perbankan inti dikirimkan ke Flume sebagai pesan XML, yang telah dibaca dari database sumber melalui replikasi log. (Mengikuti log database ke topik Kafka dengan cara ini adalah pola yang semakin umum dan dikombinasikan dengan pemadatan log, dapat memberikan “tampilan terbaru” dari database untuk kasus penggunaan pengambilan data perubahan.)
Flume menyimpan pesan XML ini dalam topik Kafka "mentah". Dari sini, dan sebagai pendahulu untuk semua pemrosesan lainnya, diputuskan untuk mengubah XML semi-terstruktur menjadi catatan biner terstruktur untuk memfasilitasi pemrosesan hilir standar. Pemrosesan ini dilakukan oleh Flume Interceptor kustom yang mengubah pesan XML menjadi representasi Avro generik, menerapkan tipe tertentu jika sesuai dan kembali ke representasi string jika tidak. Semua pemrosesan NRT berikutnya kemudian menyimpan hasil turunan di Avro dalam topik Kafka khusus, sehingga memudahkan untuk memasuki aliran dan mendapatkan umpan peristiwa di titik mana pun dalam rantai pemrosesan.
Jika pemrosesan peristiwa yang lebih kompleks diperlukan-misalnya agregasi dengan Spark Streaming-akan menjadi masalah sepele untuk mengkonsumsi satu atau lebih dari topik ini dan mempublikasikan ke topik turunan baru. (Apache Avro adalah pilihan alami untuk format ini:ini adalah protokol biner kompak yang mendukung evolusi skema, memiliki definisi skema yang fleksibel, dan didukung di seluruh tumpukan Hadoop. Avro dengan cepat menjadi standar de facto untuk penyimpanan data sementara dan umum di hub data perusahaan dan ditempatkan dengan sempurna untuk transformasi menjadi Apache Parket untuk beban kerja analitik.)
Pengayaan
Inspirasi untuk desain solusi pengayaan streaming berasal dari postingan O'Reilly Radar yang ditulis oleh Jay Kreps. Dalam postingannya, Jay menjelaskan manfaat menggunakan toko lokal untuk memungkinkan pemroses aliran melakukan kueri atau memodifikasi status lokal sebagai respons terhadap inputnya, dibandingkan dengan melakukan panggilan jarak jauh ke database terdistribusi.
Di Santander, kami mengadaptasi pola ini untuk menyediakan toko referensi lokal yang digunakan untuk kueri dan memperkaya transaksi saat mereka mengalir melalui Flume. Mengapa tidak menggunakan HBase sebagai toko referensi saja? Nah, pola tipikal untuk jenis masalah ini adalah dengan hanya menyimpan status di HBase dan meminta mekanisme pengayaan untuk menanyakannya secara langsung. Kami memutuskan untuk tidak menggunakan pendekatan ini karena beberapa alasan. Pertama, data referensi relatif kecil dan akan masuk ke dalam satu wilayah HBase, mungkin menyebabkan hotspot wilayah. Kedua, HBase melayani aplikasi Spendlytics yang dihadapi pelanggan dan Santander tidak ingin beban tambahan memengaruhi latensi aplikasi, atau sebaliknya. Ini juga alasan mengapa kami memutuskan untuk tidak menggunakan HBase bahkan untuk mem-bootstrap toko lokal saat startup.
Jadi, dengan menyediakan toko lokal yang cepat untuk setiap Agen Flume untuk memperkaya acara dalam penerbangan, Santander mampu memberikan jaminan kinerja yang lebih baik untuk pengayaan dalam penerbangan dan aplikasi Spendlytics. Kami memutuskan untuk menggunakan RocksDB untuk mengimplementasikan penyimpanan lokal karena mampu menyediakan akses cepat ke sejumlah besar data off-heap (menghilangkan beban GC), dan fakta bahwa ia memiliki Java API untuk membuatnya lebih mudah digunakan dari sebuah Flume Interceptor khusus. Pendekatan ini menyelamatkan kami dari keharusan membuat kode toko off-heap kami sendiri. RocksDB dapat dengan mudah ditukar dengan implementasi toko lokal lainnya, tetapi dalam kasus ini sangat cocok untuk kasus penggunaan Santander.
Implementasi Interceptor pengayaan Flume khusus memproses peristiwa dari topik "berubah" di hulu, menanyakan toko lokalnya untuk memperkayanya, dan menulis hasilnya ke topik Kafka hilir tergantung pada hasilnya. Proses ini diilustrasikan secara lebih rinci di bawah ini.
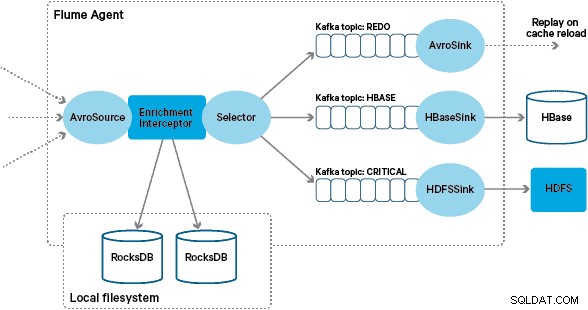
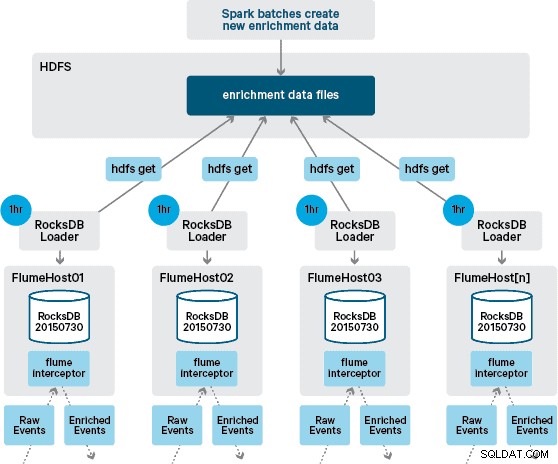
Pada titik ini Anda mungkin bertanya-tanya:Tanpa ketekunan yang disediakan HBase, bagaimana toko lokal dihasilkan? Data referensi terdiri dari sejumlah kumpulan data berbeda yang perlu digabungkan bersama. Kumpulan data ini diperbarui dalam HDFS setiap hari dan membentuk input ke aplikasi Apache Spark terjadwal, yang menghasilkan penyimpanan RocksDB. Penyimpanan RocksDB yang baru dibuat akan dipentaskan dalam HDFS hingga diunduh oleh Agen Flume untuk memastikan bahwa aliran peristiwa diperkaya dengan informasi terbaru.
Idealnya, kita tidak perlu menunggu semua kumpulan data ini tersedia dalam HDFS sebelum dapat diproses. Jika ini masalahnya, maka pembaruan data referensi dapat dialirkan melalui pipa Flafka untuk terus mempertahankan status data referensi lokal.
Dalam desain awal kami, kami telah merencanakan untuk menulis dan menjadwalkan melalui cron skrip untuk polling HDFS untuk memeriksa versi baru dari toko RocksDB, mengunduhnya dari HDFS jika tersedia. Meskipun karena kontrol internal dan tata kelola lingkungan produksi Santander, mekanisme ini harus dimasukkan ke dalam Flume Interceptor yang sama yang digunakan untuk melakukan pengayaan (memeriksa pembaruan sekali per jam, jadi ini bukan operasi yang mahal). Ketika versi baru toko tersedia, tugas dikirim ke utas pekerja untuk mengunduh toko baru dari HDFS dan memuatnya ke RocksDB. Proses ini terjadi di latar belakang sementara Interceptor pengayaan terus memproses aliran. Setelah versi baru toko dimuat ke RocksDB, Interceptor beralih ke versi terbaru, dan toko kedaluwarsa dihapus. Mekanisme yang sama digunakan untuk mem-bootstrap penyimpanan RocksDB dari startup dingin sebelum Interceptor mulai mencoba memperkaya acara.
Pesan yang berhasil diperkaya ditulis ke topik Kafka untuk ditulis secara idempoten ke HBase menggunakan HBaseEventSerializer.
Sementara aliran peristiwa diproses secara berkelanjutan, versi baru toko lokal hanya dapat dibuat setiap hari. Segera setelah versi baru toko lokal dimuat oleh Flume, itu dianggap baru,” meskipun menjadi semakin usang sebelum ketersediaan versi baru. Akibatnya, jumlah "cache misses" meningkat hingga versi yang lebih baru dari toko lokal tersedia. Misalnya, informasi merek dan pedagang baru dan yang diperbarui dapat ditambahkan ke data referensi, tetapi sampai tersedia untuk pengayaan Flume, transaksi Interceptor dapat gagal untuk diperkaya, atau diperkaya dengan informasi usang yang nantinya harus didamaikan setelah dipertahankan di HBase.
Untuk menangani kasus ini, cache miss (peristiwa yang gagal diperkaya) ditulis ke topik Kafka “ulangi” menggunakan Flume Selector. Topik redo kemudian diputar kembali ke topik sumber pengayaan Interceptor saat toko lokal baru tersedia.
Untuk mencegah "pesan racun" (peristiwa yang terus-menerus gagal pengayaan), kami memutuskan untuk menambahkan penghitung ke header acara sebelum menambahkannya ke topik redo. Peristiwa yang berulang kali muncul pada topik itu akhirnya dialihkan ke topik "kritis", yang ditulis ke HDFS untuk pemeriksaan dan perbaikan nanti. Pendekatan ini diilustrasikan dalam diagram pertama.
Kesimpulan
Untuk meringkas poin-poin utama yang dapat diambil dari postingan ini:
- Menggunakan rangkaian topik Kafka untuk menyimpan data antara yang dibagikan sebagai bagian dari alur penyerapan Anda adalah pola yang efektif.
- Anda memiliki beberapa opsi untuk mempertahankan dan menanyakan status atau data referensi di saluran penyerapan NRT Anda. Pilih HBase untuk tujuan ini sebagai pola umum ketika data tambahan berukuran besar, tetapi pertimbangkan penggunaan penyimpanan lokal yang disematkan (seperti RocksDB) atau memori JVM karena saat menggunakan HBase tidak praktis.
- Penanganan kegagalan itu penting. (Lihat #1 untuk bantuan tentang itu.)
Dalam posting tindak lanjut, kami akan menjelaskan bagaimana kami menggunakan koprosesor HBase untuk menyediakan agregasi tren pembelian historis per pelanggan, dan bagaimana transaksi offline diproses dalam batch menggunakan (proyek Cloudera Labs) SparkOnHBase (yang baru-baru ini berkomitmen ke batang HBase). Kami juga akan menjelaskan bagaimana solusi tersebut dirancang untuk memenuhi persyaratan ketersediaan tinggi lintas pusat data pelanggan.
James Kinley, Ian Buss, dan Rob Siwicki adalah Arsitek Solusi di Cloudera.



