Mengevaluasi pola arsitektur streaming mana yang paling cocok dengan kasus penggunaan Anda merupakan prasyarat untuk penerapan produksi yang berhasil.
Ekosistem Apache Hadoop telah menjadi platform pilihan bagi perusahaan yang ingin memproses dan memahami data skala besar secara real time. Teknologi seperti Apache Kafka, Apache Flume, Apache Spark, Apache Storm, dan Apache Samza semakin mendorong amplop pada apa yang mungkin. Seringkali tergoda untuk menggabungkan kasus penggunaan streaming skala besar bersama-sama, tetapi pada kenyataannya mereka cenderung dipecah menjadi beberapa pola arsitektur yang berbeda, dengan komponen ekosistem yang berbeda lebih cocok untuk masalah yang berbeda.
Dalam postingan ini, saya akan menguraikan empat pola streaming utama yang kami temui dengan pelanggan yang menjalankan hub data perusahaan dalam produksi, dan menjelaskan cara menerapkan pola tersebut secara arsitektural di Hadoop.
Pola Streaming
Empat pola streaming dasar (sering digunakan bersama-sama) adalah:
- Penyerapan aliran: Melibatkan peristiwa yang bertahan dengan latensi rendah ke HDFS, Apache HBase, dan Apache Solr.
- Pemrosesan Peristiwa Near Real-Time (NRT) dengan Konteks Eksternal: Mengambil tindakan seperti memperingatkan, menandai, mengubah, dan memfilter peristiwa saat tiba. Tindakan mungkin diambil berdasarkan kriteria canggih, seperti model deteksi anomali. Kasus penggunaan umum, seperti deteksi dan rekomendasi penipuan NRT, sering kali menuntut latensi rendah di bawah 100 milidetik.
- Pemrosesan Partisi Acara NRT: Mirip dengan pemrosesan peristiwa NRT, tetapi memperoleh manfaat dari mempartisi data—seperti menyimpan informasi eksternal yang lebih relevan dalam memori. Pola ini juga memerlukan latensi pemrosesan di bawah 100 milidetik.
- Topologi Kompleks untuk Agregasi atau ML: Cawan suci pemrosesan aliran:mendapatkan jawaban real-time dari data dengan serangkaian operasi yang kompleks dan fleksibel. Di sini, karena hasil sering kali bergantung pada komputasi berjendela dan memerlukan lebih banyak data aktif, fokus beralih dari latensi sangat rendah ke fungsionalitas dan akurasi.
Di bagian berikut, kita akan membahas cara yang direkomendasikan untuk menerapkan pola tersebut dengan cara yang teruji, terbukti, dan dapat dipelihara.
Penerapan Streaming
Secara tradisional, Flume telah menjadi sistem yang direkomendasikan untuk penyerapan streaming. Pustaka sumber dan wastafelnya yang besar mencakup semua dasar tentang apa yang harus dikonsumsi dan di mana harus menulis. (Untuk detail tentang cara mengonfigurasi dan mengelola Flume, Menggunakan Flume , buku O'Reilly Media oleh Cloudera Software Engineer/Flume PMC member Hari Shreedharan, adalah sumber yang bagus.)
Dalam setahun terakhir, Kafka juga menjadi populer karena fitur-fitur canggih seperti pemutaran dan replikasi. Karena tumpang tindih antara tujuan Flume dan Kafka, hubungan mereka sering membingungkan. Bagaimana mereka cocok bersama? Jawabannya sederhana:Kafka adalah pipa yang mirip dengan abstraksi Saluran Flume, meskipun pipa lebih baik karena dukungannya untuk fitur yang disebutkan di atas. Salah satu pendekatan yang umum adalah menggunakan Flume untuk sumber dan wastafel, dan Kafka untuk pipa di antara keduanya.
Diagram di bawah mengilustrasikan bagaimana Kafka dapat berfungsi sebagai Sumber Data UpStream ke Flume, tujuan DownStream Flume, atau Saluran Flume.
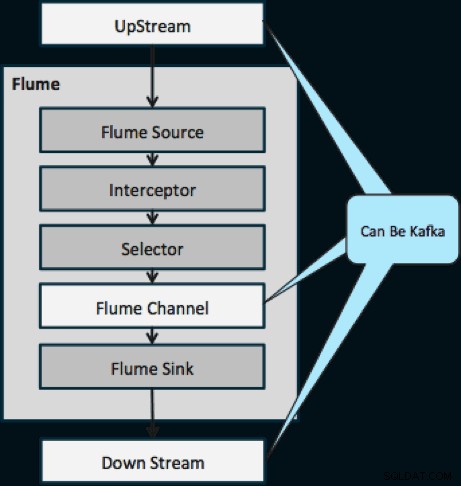
Desain yang diilustrasikan di bawah ini dapat diskalakan secara besar-besaran, pertempuran diperkeras, dipantau secara terpusat melalui Cloudera Manager, toleran terhadap kesalahan, dan mendukung pemutaran ulang.
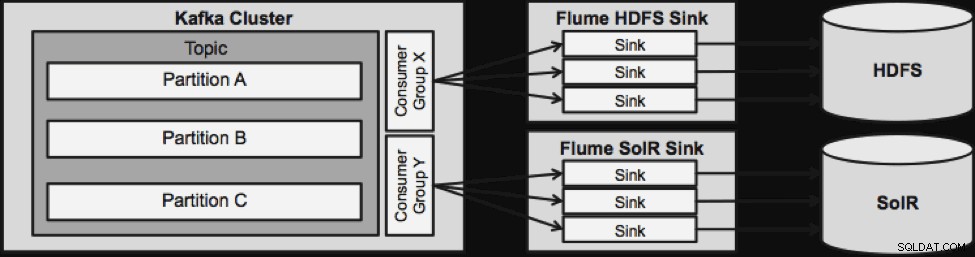
Satu hal yang perlu diperhatikan sebelum kita beralih ke arsitektur streaming berikutnya adalah bagaimana desain ini menangani kegagalan dengan anggun. Flume Sinks menarik dari Kafka Consumer Group. Grup Konsumen melacak offset Topik dengan bantuan dari Apache ZooKeeper. Jika Flume Sink hilang, Konsumen Kafka akan mendistribusikan kembali beban ke sink yang tersisa. Saat Flume Sink muncul kembali, grup Konsumen akan mendistribusikan kembali.
Pemrosesan Peristiwa NRT dengan Konteks Eksternal
Untuk mengulangi, kasus penggunaan umum untuk pola ini adalah untuk melihat peristiwa yang mengalir dan membuat keputusan segera, baik untuk mengubah data atau untuk mengambil semacam tindakan eksternal. Logika keputusan seringkali bergantung pada profil eksternal atau metadata. Cara mudah dan skalabel untuk menerapkan pendekatan ini adalah dengan menambahkan pencegat Source atau Sink Flume ke arsitektur Kafka/Flume Anda. Dengan penyetelan sederhana, tidak sulit untuk mencapai latensi dalam milidetik rendah.
Flume Interceptors mengambil peristiwa atau kumpulan peristiwa dan mengizinkan kode pengguna untuk memodifikasi atau mengambil tindakan berdasarkan peristiwa tersebut. Kode pengguna dapat berinteraksi dengan memori lokal atau sistem penyimpanan eksternal seperti HBase untuk mendapatkan informasi profil yang diperlukan untuk pengambilan keputusan. HBase biasanya dapat memberikan informasi kami dalam waktu sekitar 4-25 milidetik tergantung pada jaringan, desain skema, dan konfigurasi. Anda juga dapat mengatur HBase dengan cara yang tidak pernah down atau terputus, bahkan jika terjadi kegagalan.
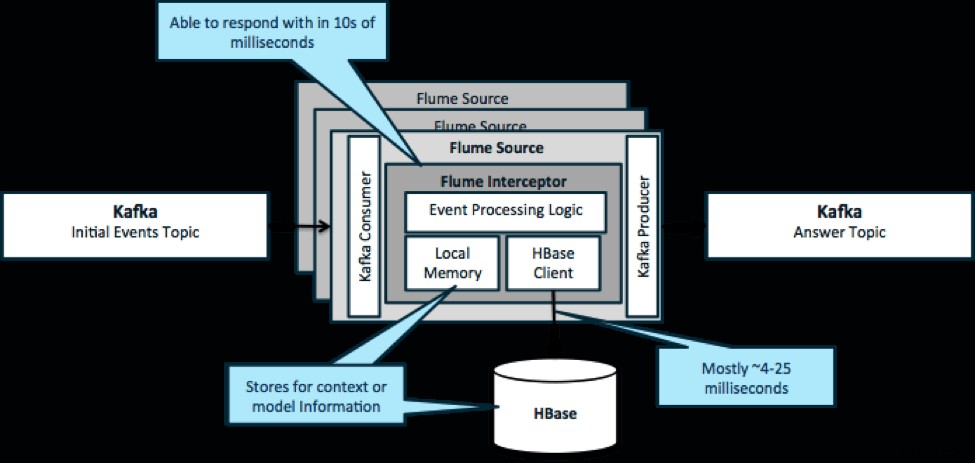
Implementasi hampir tidak memerlukan pengkodean di luar logika khusus aplikasi di pencegat. Cloudera Manager menawarkan UI intuitif untuk menerapkan logika ini melalui paket serta menghubungkan, mengonfigurasi, dan memantau layanan.
Pemrosesan Peristiwa Terpartisi NRT dengan Konteks Eksternal
Dalam arsitektur yang diilustrasikan di bawah (solusi yang tidak dipartisi), Anda perlu sering memanggil HBase karena konteks eksternal yang relevan dengan peristiwa tertentu tidak sesuai dengan memori lokal pada pencegat Flume.
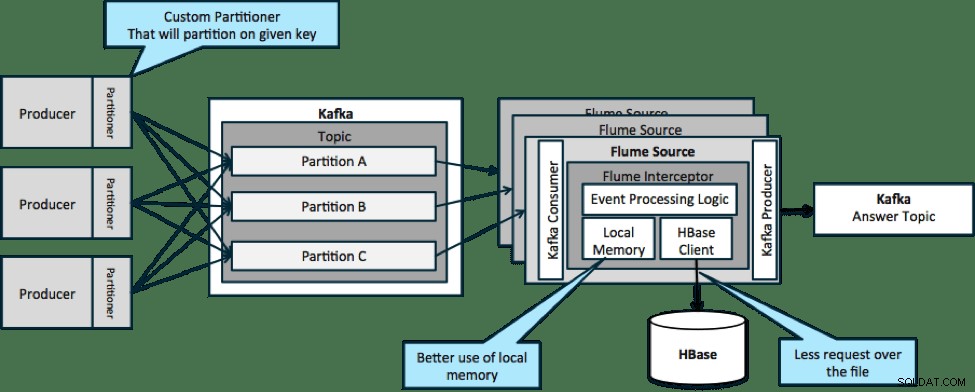
Namun, jika Anda menentukan kunci untuk mempartisi data Anda, Anda bisa mencocokkan data yang masuk ke subset data konteks yang relevan dengannya. Jika Anda mempartisi data 10 kali, maka Anda hanya perlu menyimpan 1/10 profil di memori. HBase cepat, tetapi memori lokal lebih cepat. Kafka memungkinkan Anda untuk menentukan partisi khusus yang digunakannya untuk memisahkan data Anda.
Perhatikan bahwa Flume tidak sepenuhnya diperlukan di sini; solusi root di sini hanya konsumen Kafka. Jadi, Anda hanya dapat menggunakan konsumen di YARN atau aplikasi MapReduce khusus-Peta.
Topologi Kompleks untuk Agregasi atau ML
Hingga saat ini, kami telah menjelajahi operasi tingkat peristiwa. Namun, terkadang Anda memerlukan operasi yang lebih kompleks seperti penghitungan, rata-rata, sesi, atau pembuatan model pembelajaran mesin yang beroperasi pada kumpulan data. Dalam hal ini, Spark Streaming adalah alat yang ideal karena beberapa alasan:
- Mudah dikembangkan dibandingkan dengan alat lain. API Spark yang kaya dan ringkas membuat pembuatan topologi kompleks menjadi mudah.
- Kode serupa untuk streaming dan pemrosesan batch. Dengan beberapa perubahan, kode untuk batch kecil secara real time dapat digunakan untuk batch besar secara offline. Selain mengurangi ukuran kode, pendekatan ini mengurangi waktu yang dibutuhkan untuk pengujian dan integrasi.
- Ada satu mesin yang perlu diketahui. Ada biaya yang harus dikeluarkan untuk melatih staf tentang kebiasaan dan internal mesin pemrosesan terdistribusi. Standarisasi di Spark menggabungkan biaya ini untuk streaming dan batch.
- Micro-batching membantu Anda menskalakan dengan andal. Mengakui pada tingkat batch memungkinkan lebih banyak throughput dan memungkinkan solusi tanpa takut pengiriman ganda. Micro-batching juga membantu mengirimkan perubahan ke HDFS atau HBase dalam hal kinerja dalam skala besar.
- Integrasi ekosistem Hadoop dijalankan. Spark memiliki integrasi mendalam dengan HDFS, HBase, dan Kafka.
- Tidak ada risiko kehilangan data. Berkat WAL dan Kafka, Spark Streaming menghindari kehilangan data jika terjadi kegagalan.
- Mudah untuk di-debug dan dijalankan. Anda dapat men-debug dan menelusuri kode Anda Spark Streaming di IDE lokal tanpa cluster. Selain itu, kode tersebut terlihat seperti kode pemrograman fungsional normal sehingga tidak membutuhkan banyak waktu bagi pengembang Java atau Scala untuk melakukan lompatan. (Python juga didukung.)
- Streaming secara native stateful. Di Spark Streaming, negara bagian adalah warga negara kelas satu, artinya mudah untuk menulis aplikasi streaming stateful yang tahan terhadap kegagalan node.
- Sebagai standar de facto, Spark mendapatkan investasi jangka panjang dari seluruh ekosistem.
Pada saat penulisan ini, ada sekitar 700 commit ke Spark secara keseluruhan dalam 30 hari terakhir—dibandingkan dengan framework streaming lainnya seperti Storm, dengan 15 commit pada waktu yang sama. - Anda memiliki akses ke pustaka ML.
MLlib Spark menjadi sangat populer dan fungsinya hanya akan meningkat. - Anda dapat menggunakan SQL jika diperlukan.
Dengan Spark SQL, Anda dapat menambahkan logika SQL ke aplikasi streaming Anda untuk mengurangi kerumitan kode.
Kesimpulan
Ada banyak kekuatan dalam streaming dan beberapa kemungkinan pola, tetapi seperti yang telah Anda pelajari di posting ini, Anda dapat melakukan hal-hal yang sangat hebat dengan pengkodean minimal jika Anda tahu pola mana yang paling cocok dengan kasus penggunaan Anda.
Ted Malaska adalah Arsitek Solusi di Cloudera, kontributor untuk Spark, Flume, dan HBase, dan rekan penulis buku O'Reilly, Arsitektur Aplikasi Hadoop.



