Di Bagian 1 seri ini tentang snapshot Apache HBase, Anda mempelajari cara menggunakan fitur Snapshot baru dan sedikit teori di balik penerapannya. Sekarang, saatnya menyelami detail teknis lebih dalam.
Apa itu Tabel?
Tabel HBase terdiri dari satu set informasi metadata dan satu set pasangan kunci/nilai:
- Info Tabel :File manifes yang menjelaskan "pengaturan" tabel, seperti kelompok kolom, codec kompresi dan encoding, jenis filter bloom, dan sebagainya.
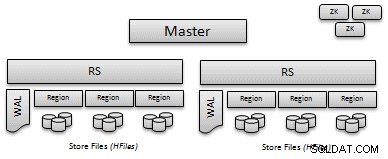
- Wilayah :Tabel "partisi" disebut daerah. Setiap region bertanggung jawab untuk menangani kumpulan kunci/nilai yang berdekatan, dan mereka ditentukan oleh kunci awal dan kunci akhir.
- WAL/MemStore :Sebelum menulis data pada disk, put ditulis ke Write Ahead Log (WAL) dan kemudian disimpan dalam memori sampai tekanan memori memicu flush ke disk. WAL menyediakan cara mudah untuk memulihkan put yang tidak di-flush ke disk saat gagal.
- HFiles :Pada titik tertentu semua data di-flush ke disk; sebuah HFile adalah format HBase yang berisi kunci/nilai yang disimpan. HFile tidak dapat diubah tetapi dapat dihapus saat pemadatan atau penghapusan wilayah.
(Catatan:Untuk mempelajari lebih lanjut tentang HBase Write Path, lihat posting blog HBase Write Path.)
Apa itu Snapshot?
Snapshot adalah kumpulan informasi metadata yang memungkinkan admin untuk kembali ke status tabel sebelumnya. Sebuah snapshot bukanlah salinan dari tabel; cara termudah untuk memikirkannya adalah sebagai serangkaian operasi untuk melacak metadata (info tabel dan wilayah) dan data (HFiles, memstore, WAL). Tidak ada salinan data yang terlibat selama operasi snapshot.
- Cuplikan Luring :Kasus paling sederhana untuk mengambil snapshot adalah saat tabel dinonaktifkan. Menonaktifkan tabel berarti semua data dihapus pada disk, dan tidak ada penulisan atau pembacaan yang diterima. Dalam hal ini, mengambil snapshot hanyalah masalah menelusuri metadata tabel dan HFiles pada disk dan menyimpan referensinya. Master melakukan operasi ini, dan waktu yang dibutuhkan ditentukan terutama oleh waktu yang dibutuhkan oleh namenode HDFS untuk menyediakan daftar file.
- Cuplikan Daring :Namun, dalam kebanyakan situasi, tabel diaktifkan dan setiap server wilayah menangani permintaan put dan get. Dalam hal ini master menerima permintaan snapshot dan meminta setiap server wilayah untuk mengambil snapshot dari wilayah yang menjadi tanggung jawabnya.
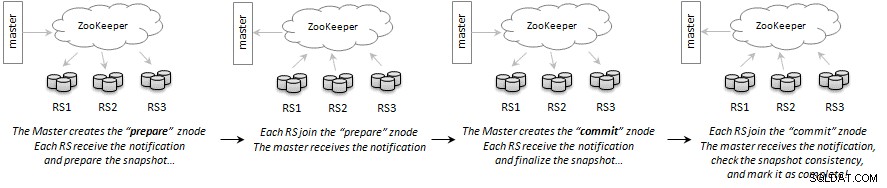
Komunikasi antara master dan server wilayah dilakukan melalui Apache ZooKeeper menggunakan transaksi seperti komit dua fase. Master membuat znode yang berarti "mempersiapkan snapshot". Setiap server wilayah akan memproses permintaan dan menyiapkan snapshot untuk wilayah dari tabel yang menjadi tanggung jawabnya. Setelah selesai, mereka menambahkan sub-simpul ke znode persiapan-permintaan dengan arti, “Saya sudah selesai”.
Setelah semua server wilayah melaporkan kembali statusnya, master membuat znode lain yang berarti "Komit snapshot"; setiap server wilayah akan menyelesaikan snapshot dan melaporkan status seperti sebelum bergabung dengan node. Setelah semua server wilayah melaporkan kembali, master akan menyelesaikan snapshot dan menandai operasi sebagai selesai. Jika server wilayah melaporkan kegagalan, master akan membuat znode baru yang digunakan untuk menyiarkan pesan pembatalan.
Karena server wilayah terus memproses permintaan baru, kasus penggunaan yang berbeda mungkin memerlukan model konsistensi yang berbeda. Misalnya, seseorang mungkin tertarik dengan snapshot yang ceroboh tanpa data baru di MemStore, orang lain mungkin menginginkan snapshot yang sepenuhnya konsisten yang memerlukan penguncian penulisan untuk sementara waktu, dan seterusnya.
Untuk alasan ini, prosedur untuk mengambil snapshot di server wilayah dapat dipasang. Saat ini, satu-satunya implementasi yang ada adalah "Flush Snapshot," yang melakukan flush sebelum mengambil snapshot dan hanya menjamin konsistensi baris. Prosedur lain dengan kebijakan konsistensi yang berbeda dapat diterapkan di masa mendatang.
Dalam kasus online, waktu yang diperlukan untuk mengambil snapshot dibatasi oleh waktu yang dibutuhkan oleh server wilayah paling lambat untuk melakukan operasi snapshot dan melaporkan keberhasilan kembali ke master. Operasi ini biasanya berlangsung beberapa detik.
Pengarsipan
Seperti yang telah kita lihat sebelumnya, HFiles tidak dapat diubah. Hal ini memungkinkan kita untuk menghindari penyalinan data selama operasi snapshot atau kloning, tetapi selama pemadatan data tersebut dihapus dan diganti dengan versi yang dipadatkan. Dalam hal ini, jika Anda memiliki snapshot atau tabel kloning yang merujuk salah satu file tersebut, alih-alih menghapusnya, file tersebut dipindahkan ke lokasi "arsip". Jika Anda menghapus snapshot dan tidak ada orang lain yang mereferensikan file yang dirujuk oleh snapshot, file tersebut akan dihapus.
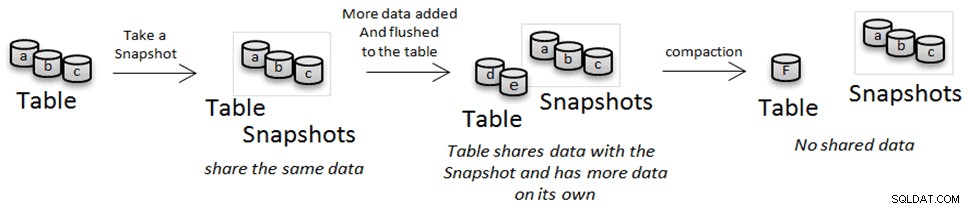
Mengkloning dan Memulihkan Tabel
Snapshots dapat dilihat sebagai solusi pencadangan di mana mereka dapat digunakan untuk memulihkan/memulihkan tabel setelah kesalahan pengguna atau aplikasi, tetapi fitur snapshot dapat memungkinkan lebih dari sekadar pencadangan dan pemulihan sederhana. Setelah mengkloning tabel dari snapshot, Anda dapat menulis pekerjaan MapReduce atau aplikasi sederhana untuk secara selektif menggabungkan perbedaan, atau apa yang menurut Anda penting, ke dalam produksi. Kasus penggunaan lainnya adalah Anda dapat menguji perubahan skema atau pembaruan data tanpa harus menunggu berjam-jam untuk salinan tabel dan tanpa berakhir dengan banyak duplikasi data pada disk.
Klon Tabel dari Snapshot
Saat administrator melakukan operasi kloning, tabel baru dengan tabel-skema yang ada di snapshot dibuat pra-split dengan tombol mulai/akhir di info wilayah snapshot. Setelah metadata tabel dibuat, alih-alih menyalin data, trik yang sama seperti snapshot digunakan. Karena HFile tidak dapat diubah, hanya referensi ke file sumber yang dibuat; ini memungkinkan operasi untuk menghindari salinan data dan memungkinkan klon untuk diedit tanpa memengaruhi tabel sumber atau snapshot. Operasi kloning dilakukan oleh master.
Memulihkan Tabel dari Snapshot
Operasi pemulihan mirip dengan operasi kloning; Anda dapat menganggapnya sebagai menghapus tabel dan mengkloningnya dari snapshot. Operasi pemulihan mengembalikan data lama yang ada di snapshot menghapus data apa pun dari tabel yang tidak juga ada di snapshot, dan juga skema tabel dikembalikan ke snapshot. Di bawah tenda, pemulihan diimplementasikan dengan melakukan perbedaan antara status tabel dan snapshot, menghapus file yang tidak ada di snapshot dan menambahkan referensi ke yang ada di snapshot tetapi tidak ada di status saat ini. Juga deskriptor tabel dimodifikasi untuk mencerminkan "skema" tabel pada saat snapshot. Operasi pemulihan dilakukan oleh master dan tabel harus dinonaktifkan.
Masa Depan
Saat ini, implementasi snapshot mencakup semua fungsionalitas dasar yang diperlukan. Seperti yang telah kita lihat, kebijakan konsistensi snapshot baru untuk snapshot online dapat memberikan lebih banyak fleksibilitas, konsistensi, atau peningkatan kinerja. Manajemen file yang lebih baik dapat mengurangi beban pada Node Nama HDFS dan meningkatkan manajemen ruang disk. Selain itu, metrik, UI Web (Hue), dan lainnya ada dalam daftar tugas.
Kesimpulan
Snapshot HBase menambahkan fungsionalitas baru seperti "koordinasi prosedur" yang digunakan oleh snapshot online, atau snapshot copy-on-write, restore, dan clone.
Snapshots memberikan alternatif yang lebih cepat dan lebih baik untuk solusi "cadangan" dan "kloning" buatan tangan berdasarkan distcp atau CopyTable. Semua operasi snapshot (snapshot, restore, clone) tidak melibatkan salinan data, sehingga snapshot tabel lebih cepat dan penghematan ruang disk.
Untuk informasi lebih lanjut tentang cara mengaktifkan dan menggunakan snapshot, silakan merujuk ke dokumen manajemen operasional HBase.
Matteo Bertozzi adalah Software Engineer di tim Platform dan HBase Committer.



