Posting blog ini akan menyajikan contoh sederhana "hello world" tentang cara mendapatkan data yang disimpan dalam indeks S3 dan dilayani oleh layanan Apache Solr yang dihosting di klaster Penemuan dan Eksplorasi Data di CDP. Bagi yang penasaran:DDE adalah opsi penerapan klaster yang dioptimalkan Solr yang telah ditempa sebelumnya di CDP, dan baru-baru ini dirilis dalam pratinjau teknologi . Kami hanya akan membahas lingkungan AWS dan S3 di blog ini. Opsi penerapan Azure dan ADLS juga tersedia dalam pratinjau teknologi, tetapi akan dibahas dalam entri blog mendatang.
Kami akan menggambarkan skenario paling sederhana untuk membuatnya mudah untuk memulai. Tentu saja ada lebih banyak pengaturan jalur pipa data dan skema yang lebih kaya, tetapi ini adalah titik awal yang baik untuk pemula.
Asumsi:
- Anda sudah memiliki akun CDP dan memiliki hak pengguna atau admin yang kuat untuk lingkungan tempat Anda berencana menjalankan layanan ini.
Jika Anda tidak memiliki akun AWS CDP, silakan hubungi perwakilan Cloudera favorit Anda, atau daftar untuk uji coba CDP di sini. - Anda memiliki lingkungan dan identitas yang dipetakan dan dikonfigurasi. Secara lebih eksplisit, Anda hanya perlu memiliki pemetaan Pengguna CDP ke Peran AWS yang memberikan akses ke bucket s3 tertentu yang ingin Anda baca (dan tulis).
- Anda telah menetapkan kata sandi beban kerja (FreeIPA).
- Anda menjalankan cluster DDE. Anda juga dapat menemukan informasi lebih lanjut tentang menggunakan template di CDP Data Hub di sini.
- Anda memiliki akses CLI ke cluster itu.
- Port SSH terbuka di AWS untuk alamat IP Anda. Anda bisa mendapatkan alamat IP publik untuk salah satu node Solr dalam detail cluster Datahub. Pelajari di sini cara SSH ke cluster AWS.
- Anda memiliki file log di bucket S3 yang dapat diakses oleh pengguna Anda (
/sample.log dalam contoh ini). Jika Anda tidak memilikinya, berikut adalah tautan ke yang kami gunakan.
Alur kerja
Bagian berikut akan memandu Anda melalui langkah-langkah untuk mendapatkan data yang diindeks menggunakan Alat Pengindeks Crunch yang keluar dari kotak dengan DDE.

Buat koleksi untuk menyimpan indeks Anda
Di HUE ada perancang indeks; namun, selama DDE dalam Pratinjau Teknologi, itu akan sedikit dalam konstruksi ulang dan tidak direkomendasikan pada saat ini. Tapi silakan coba setelah DDE masuk GA, dan beri tahu kami pendapat Anda.
Untuk saat ini, Anda dapat membuat skema dan konfigurasi Solr menggunakan alat CLI 'solrctl'. Buat konfigurasi yang disebut 'my-own-logs-config' dan koleksi yang disebut 'my-own-logs'. Ini mengharuskan Anda memiliki akses CLI.
1. SSH ke salah satu node pekerja di cluster Anda.
2. kinit sebagai pengguna dengan izin untuk membuat konfigurasi koleksi:
kinit
3. Pastikan bahwa variabel lingkungan SOLR_ZK_ENSEMBLE diatur di /etc/solr/conf/solr-env.sh. Simpan nilainya karena ini akan diperlukan pada langkah selanjutnya.
Tekan Enter dan ketikkan kata sandi beban kerja Anda (FreeIPA).
Misalnya:
cat /etc/solr/conf/solr-env.sh
Hasil yang diharapkan:
ekspor SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Ini secara otomatis disetel pada host dengan peran Solr Server atau Gateway di Cloudera Manager.
4. Untuk menghasilkan file konfigurasi untuk koleksi, jalankan perintah berikut:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate adalah salah satu templat default yang dikirimkan bersama Solr di CDP tetapi, sebagai templat, itu tidak dapat diubah. Untuk keperluan alur kerja ini, Anda perlu menyalinnya dan dengan demikian membuat yang baru yang dapat diubah (inilah yang dilakukan oleh opsi immutable=false). Ini memberi Anda konfigurasi yang fleksibel dan tanpa skema. Membuat skema yang dirancang dengan baik adalah sesuatu yang berharga untuk menginvestasikan waktu desain, tetapi tidak diperlukan untuk penggunaan eksplorasi. Untuk alasan ini, ini di luar cakupan posting blog ini. Namun, dalam lingkungan produksi yang sebenarnya, kami sangat menyarankan penggunaan skema yang dirancang dengan baik – dan kami dengan senang hati akan memberikan bantuan ahli jika diperlukan!
5. Buat koleksi baru menggunakan perintah berikut:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Tindakan ini membuat koleksi “log-saya-sendiri” berdasarkan konfigurasi koleksi “log-saya-sendiri-konfigurasi” pada satu pecahan.
6. Untuk memvalidasi koleksi yang telah dibuat, Anda dapat menavigasi ke UI Admin Solr. Koleksi untuk “log-saya sendiri” akan tersedia melalui drop-down di navigasi kiri.

Indeks Data Anda
Di sini kami menjelaskan menggunakan contoh sederhana cara mengonfigurasi dan menjalankan Alat Pengindeks Crunch bawaan untuk mengindeks data dengan cepat di S3 dan melayani melalui Solr di DDE. Karena mengamankan cluster dapat menggunakan CM Auto TLS, Knox, Kerberos, dan Ranger, 'Spark submit' mungkin bergantung pada aspek yang tidak tercakup dalam postingan ini.
Mengindeks data dari S3 sama saja dengan mengindeks dari HDFS.
Lakukan langkah-langkah ini pada node pekerja Benang (disebut sebagai "Pekerja Benang" di UI web Management Console).
1. SSH ke node pekerja Yarn khusus dari cluster DDE sebagai pengguna admin Solr.
Untuk mengetahui alamat IP node pekerja Yarn, klik Perangkat Keras tab pada halaman detail cluster, lalu gulir ke node “Pekerja Benang”.

2. Buka direktori sumber daya Anda (atau buat direktori jika Anda belum memilikinya:
cd
Gunakan folder beranda pengguna admin sebagai direktori sumber daya (
3. Kini pengguna Anda :
kinit
Tekan Enter dan ketikkan kata sandi beban kerja Anda (FreeIPA).
4. Jalankan perintah curl berikut, menggantikan
curl --negosiasi -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --tidak aman> tokenFile.txt
5. Buat file konfigurasi Morphline untuk Alat Pengindeks Crunch, read-log-morphline.conf dalam contoh ini. Ganti
SOLR_LOCATOR :{ # Nama koleksi koleksi solr :my-own-logs #zk ensemble zkHost :
Morphline ini membaca jejak tumpukan dari file log yang diberikan, kemudian menulis log entri debug dan memuatnya ke Solr yang ditentukan.
6. Buat file log4j.properties untuk konfigurasi log:
log4j.rootLogger=INFO, A1# A1 diatur menjadi ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 menggunakan PatternLayout.log4j.appender.A1.layout=org.apache.log4j .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Periksa apakah file yang ingin Anda baca ada di S3 (jika Anda tidak memilikinya, berikut adalah tautan ke file yang kami gunakan untuk contoh sederhana ini:
aws s3 ls s3://
8. Jalankan perintah spark-submit:
Ganti placeholder di dan dengan nilai yang telah Anda tetapkan.
ekspor myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunchexport myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunchexport myDriverJar=$(temukan $myDriverJarDir - maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar')export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1)export myDependencyJarPaths=$(cari $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) ekspor myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "ekspor myResourcesDir="
Jika Anda menemukan pesan serupa, Anda dapat mengabaikannya:
PERINGATAN metadata.Hive:Gagal mendaftarkan semua functions.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportException
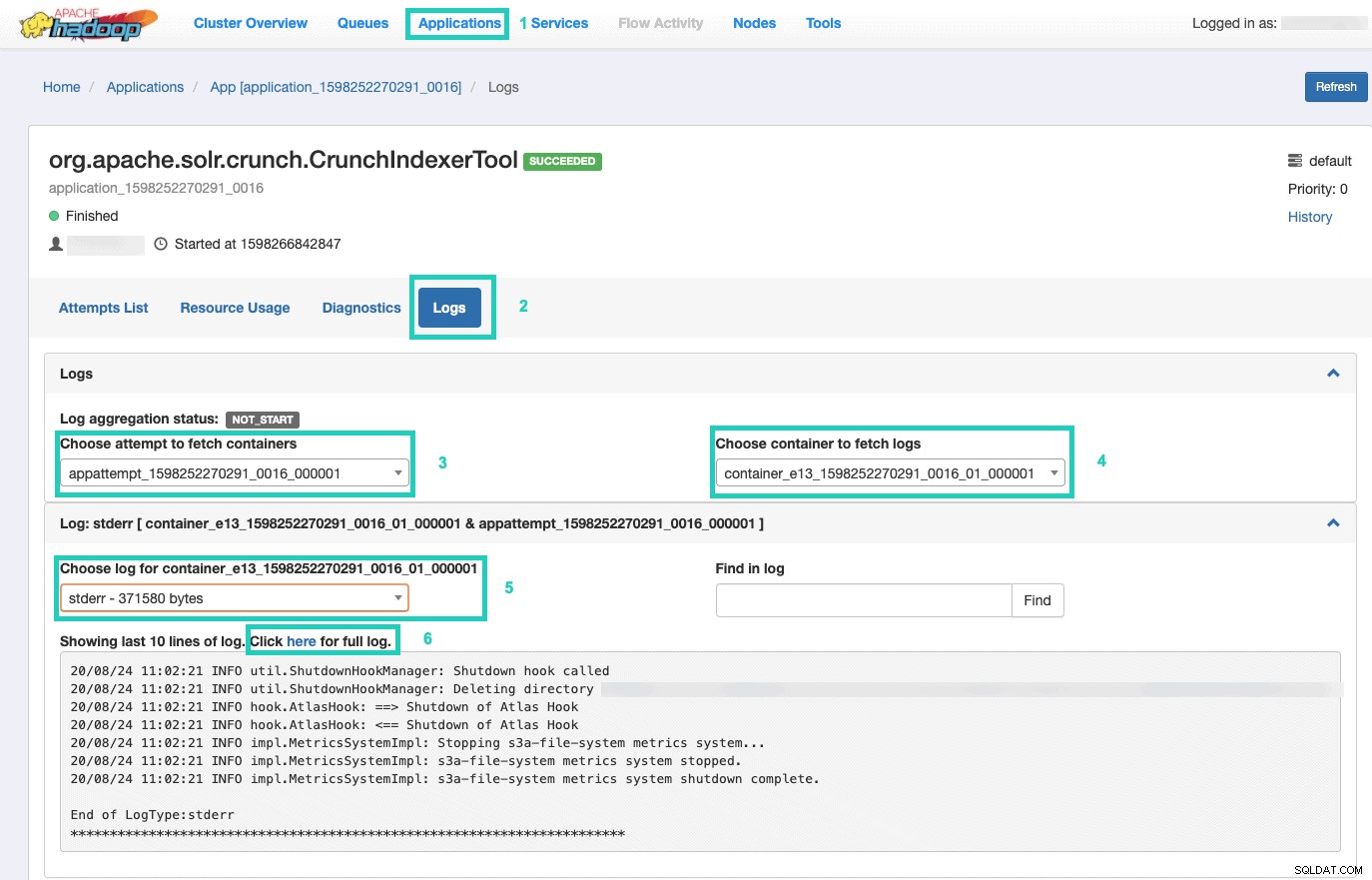
9. Untuk memantau eksekusi perintah, buka Resource Manager.

Sesampai di sana, pilih Aplikasi tab > Klik ID Aplikasi dari upaya aplikasi yang ingin Anda pantau > Pilih Log> Pilih upaya untuk mengambil penampung> Pilih penampung untuk mengambil log> Pilih log untuk penampung> Pilih stderr log> Klik Klik di sini untuk log lengkap .
Layani Indeks Anda
Anda memiliki banyak pilihan bagaimana menyajikan data terindeks yang dapat dicari kepada pengguna akhir. Anda dapat membangun aplikasi kaya Anda sendiri berdasarkan API kaya Solr (sangat umum). Anda dapat menghubungkan alat pihak ke-3 favorit Anda, seperti Qlik, Tableau dll melalui koneksi Solr bersertifikat mereka. Anda dapat menggunakan dasbor solr sederhana Hue untuk membuat aplikasi prototipe.
Untuk melakukan yang terakhir:
1. Buka Hue.

2. Pada tampilan dasbor, navigasikan ke file indeks pilihan (mis. yang baru saja Anda buat).
3. Mulai seret dan lepas berbagai elemen dasbor dan pilih bidang dari indeks untuk mengisi data untuk visual yang ada.
Video tutorial dasbor cepat dari masa lalu dapat ditemukan di sini, sebagai inspirasi.
Kami akan membahas lebih dalam untuk entri blog mendatang.
Ringkasan
Kami harap Anda telah belajar banyak dari posting blog ini tentang cara mendapatkan data dalam S3 yang diindeks oleh Solr di DDE menggunakan Crunch Indexer Tool. Tentu saja ada banyak cara lain (Spark dalam pengalaman Data Engineering, Nifi dalam pengalaman Data Flow, Kafka dalam pengalaman Stream Management, dan sebagainya), tetapi itu akan dibahas dalam posting blog mendatang. Kami berharap Anda sangat sukses dalam perjalanan lanjutan Anda dalam membangun aplikasi wawasan yang kuat yang melibatkan teks dan data tidak terstruktur lainnya. Jika Anda memutuskan untuk mencoba DDE di CDP, beri tahu kami bagaimana hasilnya!



