Apache Hadoop adalah kerangka kerja perangkat lunak yang memproses dan menyimpan data besar di seluruh kelompok perangkat keras komoditas. Hadoop didasarkan pada model MapReduce untuk memproses sejumlah besar data secara terdistribusi.
Tutorial MapReduce ini meminta beberapa fitur MapReduce. Setelah membaca ini, Anda akan memahami dengan jelas mengapa MapReduce paling cocok untuk memproses data dalam jumlah besar.
Pertama, kita akan melihat sedikit pengantar untuk kerangka MapReduce. Kemudian kita akan menjelajahi berbagai fitur MapReduce.
Mari kita mulai dengan pengenalan kerangka kerja MapReduce.
Pengantar MapReduce
MapReduce adalah kerangka kerja perangkat lunak untuk menulis aplikasi yang dapat memproses data dalam jumlah besar di seluruh cluster node yang mahal. Hadoop MapReduce adalah bagian pemrosesan dari Apache Hadoop.
Ia juga dikenal sebagai jantung Hadoop. Ini adalah aplikasi pemrosesan data yang paling disukai. Beberapa pemain di sektor e-commerce seperti Amazon, Yahoo, dan Zuventus, dll. menggunakan kerangka kerja MapReduce untuk pemrosesan data volume tinggi.
Sekarang mari kita pelajari berbagai fitur Hadoop MapReduce.
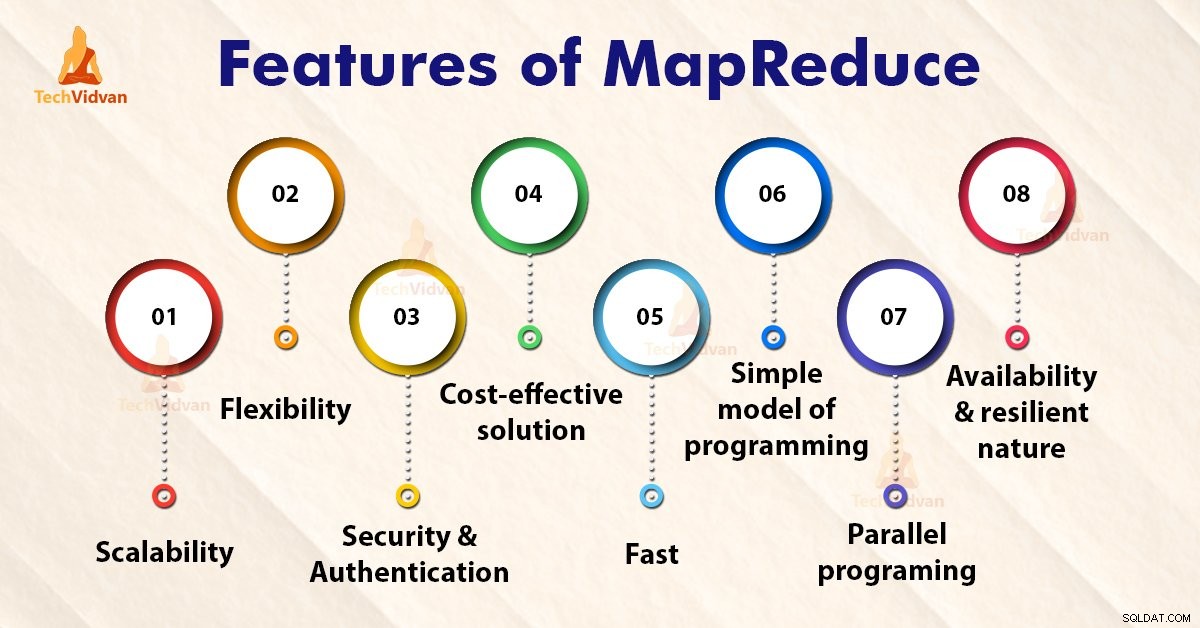
Fitur MapReduce
1. Skalabilitas
Apache Hadoop adalah kerangka kerja yang sangat skalabel. Ini karena kemampuannya untuk menyimpan dan mendistribusikan data besar di banyak server. Semua server ini tidak mahal dan dapat beroperasi secara paralel. Kami dapat dengan mudah menskalakan penyimpanan dan daya komputasi dengan menambahkan server ke cluster.
Pemrograman Hadoop MapReduce memungkinkan organisasi untuk menjalankan aplikasi dari kumpulan node besar yang dapat melibatkan penggunaan ribuan terabyte data.
Pemrograman Hadoop MapReduce memungkinkan organisasi bisnis untuk menjalankan aplikasi dari kumpulan node yang besar. Ini dapat menggunakan ribuan terabyte data.
2. Fleksibilitas
Pemrograman MapReduce memungkinkan perusahaan untuk mengakses sumber data baru. Ini memungkinkan perusahaan untuk beroperasi pada berbagai jenis data. Ini memungkinkan perusahaan untuk mengakses data terstruktur maupun tidak terstruktur, dan memperoleh nilai signifikan dengan memperoleh wawasan dari berbagai sumber data.
Selain itu, framework MapReduce juga menyediakan dukungan untuk berbagai bahasa dan data dari berbagai sumber mulai dari email, media sosial, hingga clickstream.
MapReduce memproses data dalam pasangan nilai kunci sederhana sehingga mendukung tipe data termasuk meta-data, gambar, dan file besar. Oleh karena itu, MapReduce fleksibel untuk menangani data daripada DBMS tradisional.
3. Keamanan dan Otentikasi
Model pemrograman MapReduce menggunakan platform keamanan HBase dan HDFS yang memungkinkan akses hanya ke pengguna yang diautentikasi untuk beroperasi pada data. Dengan demikian, ini melindungi akses tidak sah ke data sistem dan meningkatkan keamanan sistem.
4. Solusi hemat biaya
Arsitektur Hadoop yang dapat diskalakan dengan kerangka kerja pemrograman MapReduce memungkinkan penyimpanan dan pemrosesan kumpulan data besar dengan cara yang sangat terjangkau.
5. Cepat
Hadoop menggunakan metode penyimpanan terdistribusi yang disebut sebagai Hadoop Distributed File System yang pada dasarnya mengimplementasikan sistem pemetaan untuk menemukan data dalam sebuah cluster.
Alat yang digunakan untuk pemrosesan data, seperti pemrograman MapReduce, umumnya terletak di server yang sama yang memungkinkan pemrosesan data lebih cepat.
Jadi, Bahkan jika kita berurusan dengan volume besar data tidak terstruktur, Hadoop MapReduce hanya membutuhkan waktu beberapa menit untuk memproses terabyte data. Itu dapat memproses data berukuran petabyte hanya dalam satu jam.
6. Model pemrograman sederhana
Di antara berbagai fitur Hadoop MapReduce, salah satu fitur terpenting adalah ia didasarkan pada model pemrograman sederhana. Pada dasarnya, ini memungkinkan pemrogram untuk mengembangkan program MapReduce yang dapat menangani tugas dengan mudah dan efisien.
Program MapReduce dapat ditulis dalam Java, yang tidak terlalu sulit untuk diambil dan juga digunakan secara luas. Jadi, siapa pun dapat dengan mudah mempelajari dan menulis program MapReduce dan memenuhi kebutuhan pemrosesan data mereka.
7. Pemrograman Paralel
Salah satu aspek utama dari kerja pemrograman MapReduce adalah pemrosesan paralelnya. Ini membagi tugas dengan cara yang memungkinkan eksekusi mereka secara paralel.
Pemrosesan paralel memungkinkan beberapa prosesor untuk menjalankan tugas yang dibagi ini. Jadi seluruh program dijalankan dalam waktu yang lebih singkat.
8. Ketersediaan dan sifatnya yang tangguh
Setiap kali data dikirim ke node individu, kumpulan data yang sama diteruskan ke beberapa node lain dalam sebuah cluster. Jadi, jika ada simpul tertentu yang mengalami kegagalan, maka selalu ada salinan lain yang ada di simpul lain yang masih dapat diakses kapan pun dibutuhkan. Ini memastikan ketersediaan data yang tinggi.
Salah satu fitur utama yang ditawarkan oleh Apache Hadoop adalah toleransi kesalahannya. Kerangka kerja Hadoop MapReduce memiliki kemampuan untuk mengenali kesalahan yang terjadi dengan cepat.
Ini kemudian menerapkan solusi pemulihan cepat dan otomatis. Fitur ini menjadikannya pengubah permainan di dunia pemrosesan data besar.
Ringkasan
Saya harap setelah membaca artikel ini Anda memahami dengan jelas berbagai fitur Hadoop MapReduce. Artikel tersebut mencantumkan berbagai fitur MapReduce. Kerangka kerja MapReduce dapat diskalakan, fleksibel, hemat biaya, dan sistem pemrosesan cepat.
Menawarkan keamanan, toleransi kesalahan, dan otentikasi. MapReduce adalah model pemrograman sederhana dan menawarkan pemrograman paralel.



