Skenario terbaik adalah, jika terjadi kegagalan basis data, Anda memiliki Rencana Pemulihan Bencana (DRP) yang baik dan lingkungan yang sangat tersedia dengan proses failover otomatis, tetapi… apa yang terjadi jika gagal beberapa alasan yang tidak terduga? Bagaimana jika Anda perlu melakukan failover manual? Di blog ini, kami akan membagikan beberapa rekomendasi untuk diikuti jika Anda perlu melakukan failover database Anda.
Pemeriksaan Verifikasi
Sebelum melakukan perubahan apa pun, Anda perlu memverifikasi beberapa hal dasar untuk menghindari masalah baru setelah proses failover.
Status Replikasi
Mungkin saja, pada saat kegagalan, node slave tidak mutakhir, karena kegagalan jaringan, beban tinggi, atau masalah lain, jadi Anda perlu memastikan budak memiliki semua (atau hampir semua) informasi. Jika Anda memiliki lebih dari satu node slave, Anda juga harus memeriksa node mana yang paling canggih dan memilihnya untuk failover.
misalnya:Mari kita periksa status replikasi di Server MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Dalam kasus PostgreSQL, ini sedikit berbeda karena Anda perlu memeriksa status WAL dan membandingkan yang diterapkan dengan yang diambil.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Kredensial
Sebelum menjalankan failover, Anda harus memeriksa apakah aplikasi/pengguna Anda dapat mengakses master baru Anda dengan kredensial saat ini. Jika Anda tidak mereplikasi pengguna database Anda, mungkin kredensial telah diubah, jadi Anda perlu memperbaruinya di node slave sebelum ada perubahan.
misalnya:Anda dapat menanyakan tabel pengguna di database mysql untuk memeriksa kredensial pengguna di Server MariaDB/MySQL:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)Dalam kasus PostgreSQL, Anda dapat menggunakan perintah '\du' untuk mengetahui peran, dan Anda juga harus memeriksa file konfigurasi pg_hba.conf untuk mengelola akses pengguna (bukan kredensial). Jadi:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}Dan pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustAkses Jaringan/Firewall
Kredensial bukan satu-satunya masalah yang mungkin terjadi saat mengakses master baru Anda. Jika node berada di pusat data lain, atau Anda memiliki firewall lokal untuk memfilter lalu lintas, Anda harus memeriksa apakah Anda diizinkan untuk mengaksesnya atau bahkan jika Anda memiliki rute jaringan untuk mencapai node master baru.
misalnya:iptables. Mari izinkan lalu lintas dari jaringan 167.124.57.0/24 dan periksa aturan saat ini setelah menambahkannya:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationmisalnya:rute. Misalkan master node baru Anda berada di jaringan 10.0.0.0/24, server aplikasi Anda berada di 192.168.100.0/24, dan Anda dapat menjangkau jaringan jarak jauh menggunakan 192.168.100.100, jadi di server aplikasi Anda, tambahkan rute yang sesuai:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Poin Aksi
Setelah memeriksa semua poin yang disebutkan, Anda harus siap melakukan tindakan untuk melakukan failover database Anda.
Alamat IP Baru
Karena Anda akan mempromosikan node slave, alamat IP master akan berubah, jadi Anda perlu mengubahnya di aplikasi atau akses klien Anda.
Menggunakan Load Balancer adalah cara terbaik untuk menghindari masalah/perubahan ini. Setelah proses failover, Load Balancer akan mendeteksi master lama sebagai offline dan (tergantung pada konfigurasi) mengirim lalu lintas ke yang baru untuk menulis di dalamnya, jadi Anda tidak perlu mengubah apa pun di aplikasi Anda.
misalnya:Mari kita lihat contoh konfigurasi HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkDalam hal ini, jika satu node mati, HAProxy tidak akan mengirim lalu lintas ke sana dan hanya mengirim lalu lintas ke node yang tersedia.
Konfigurasi ulang Node Slave
Jika Anda memiliki lebih dari satu node slave, setelah mempromosikan salah satunya, Anda harus mengkonfigurasi ulang sisa slave untuk terhubung ke master baru. Ini bisa menjadi tugas yang memakan waktu, tergantung pada jumlah node.
Verifikasi &Konfigurasi Cadangan
Setelah Anda menyiapkan semuanya (master baru dipromosikan, slave dikonfigurasi ulang, penulisan aplikasi di master baru), penting untuk mengambil tindakan yang diperlukan untuk mencegah masalah baru, jadi pencadangan adalah suatu keharusan dalam langkah ini. Kemungkinan besar Anda memiliki kebijakan pencadangan yang berjalan sebelum kejadian (jika tidak, Anda pasti harus memilikinya), jadi Anda harus memeriksa apakah pencadangan masih berjalan atau akan dilakukan di topologi baru. Ada kemungkinan bahwa Anda menjalankan pencadangan pada master lama, atau menggunakan node budak yang sekarang menjadi master, jadi Anda perlu memeriksanya untuk memastikan kebijakan pencadangan Anda akan tetap berfungsi setelah perubahan.
Pemantauan Basis Data
Saat Anda melakukan proses failover, pemantauan adalah suatu keharusan sebelum, selama, dan setelah proses. Dengan ini, Anda dapat mencegah masalah sebelum menjadi lebih buruk, mendeteksi masalah yang tidak terduga selama failover, atau bahkan mengetahui jika terjadi kesalahan setelahnya. Misalnya, Anda harus memantau apakah aplikasi Anda dapat mengakses master baru Anda dengan memeriksa jumlah koneksi yang aktif.
Metrik Utama untuk Dipantau
Mari kita lihat beberapa metrik yang paling penting untuk dipertimbangkan:
- Keterlambatan Replikasi
- Status Replikasi
- Jumlah koneksi
- Penggunaan/kesalahan jaringan
- Pemuatan server (CPU, Memori, Disk)
- Database dan log sistem
Kembalikan
Tentu saja, jika terjadi kesalahan, Anda harus dapat memutar kembali. Memblokir lalu lintas ke node lama dan membuatnya seisolasi mungkin bisa menjadi strategi yang baik untuk ini, jadi jika Anda perlu melakukan rollback, Anda akan memiliki node lama yang tersedia. Jika rollback setelah beberapa menit, tergantung pada lalu lintas, Anda mungkin perlu memasukkan data menit ini di master lama, jadi pastikan Anda juga memiliki node master sementara yang tersedia dan diisolasi untuk mengambil informasi ini dan menerapkannya kembali .
Otomatiskan Proses Failover dengan ClusterControl
Melihat semua tugas yang diperlukan ini untuk melakukan failover, kemungkinan besar Anda ingin mengotomatiskannya dan menghindari semua pekerjaan manual ini. Untuk ini, Anda dapat memanfaatkan beberapa fitur yang dapat ditawarkan ClusterControl kepada Anda untuk berbagai teknologi basis data, seperti pemulihan otomatis, pencadangan, pengelolaan pengguna, pemantauan, dan fitur lainnya, semuanya dari sistem yang sama.
Dengan ClusterControl Anda dapat memverifikasi status replikasi dan kelambatannya, membuat atau mengubah kredensial, mengetahui jaringan dan status host, dan bahkan lebih banyak verifikasi.
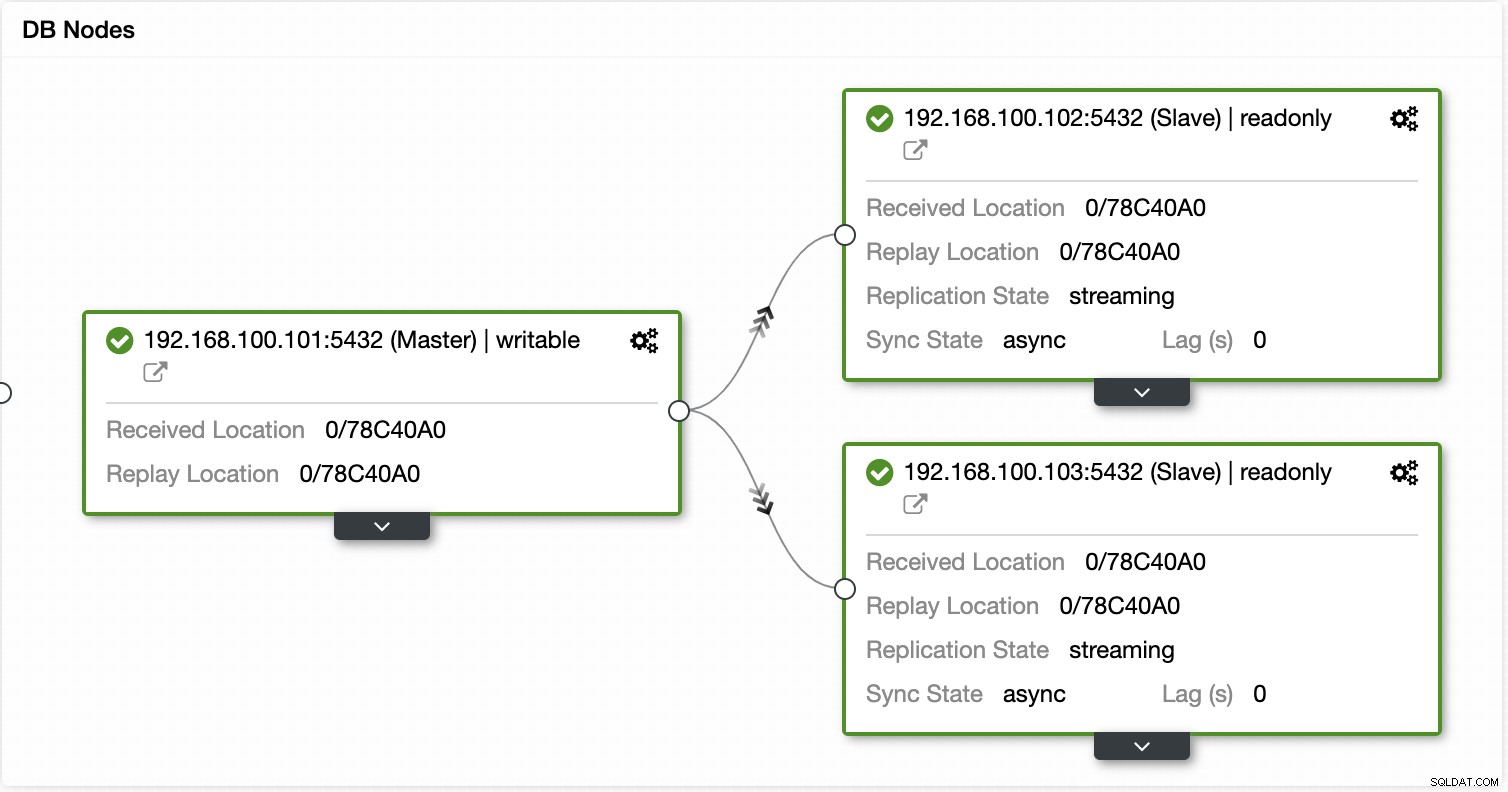
Menggunakan ClusterControl Anda juga dapat melakukan tindakan cluster dan node yang berbeda, seperti mempromosikan budak , memulai ulang database dan server, menambah atau menghapus node database, menambah atau menghapus node load balancer, membangun kembali slave replikasi, dan banyak lagi.
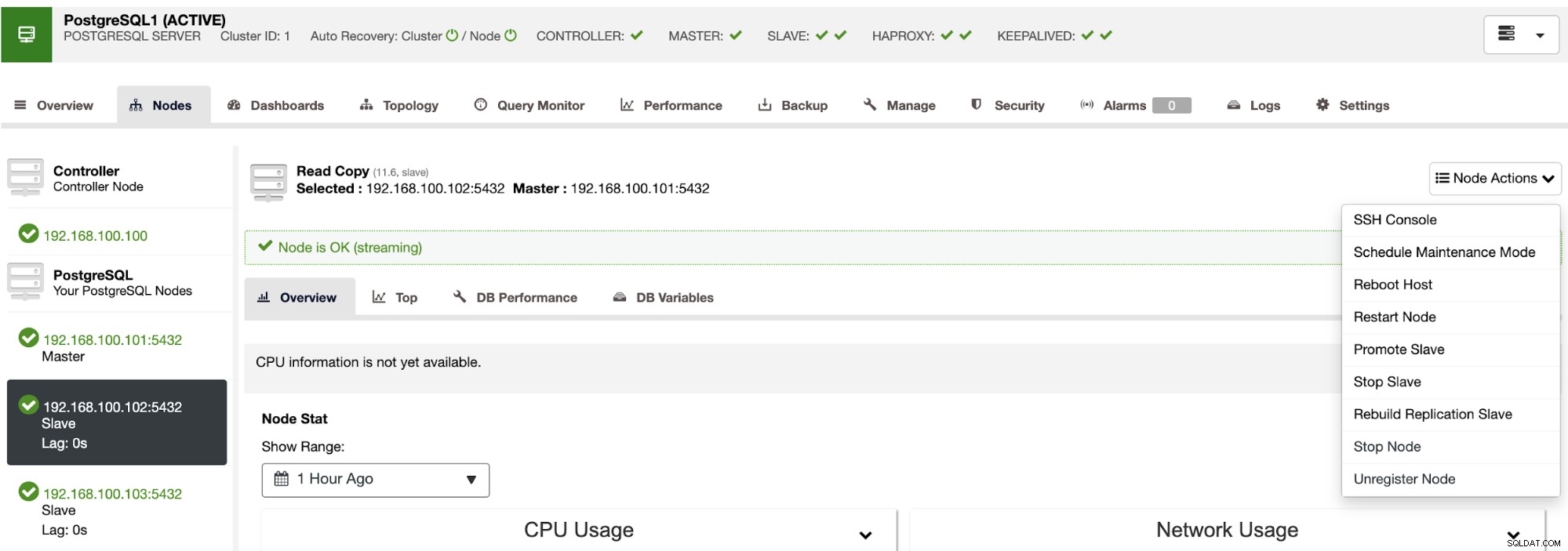
Dengan menggunakan tindakan ini, Anda juga dapat mengembalikan failover jika diperlukan dengan membangun kembali dan mempromosikan master sebelumnya.
ClusterControl memiliki layanan pemantauan dan peringatan yang membantu Anda mengetahui apa yang terjadi atau bahkan jika sesuatu terjadi sebelumnya.
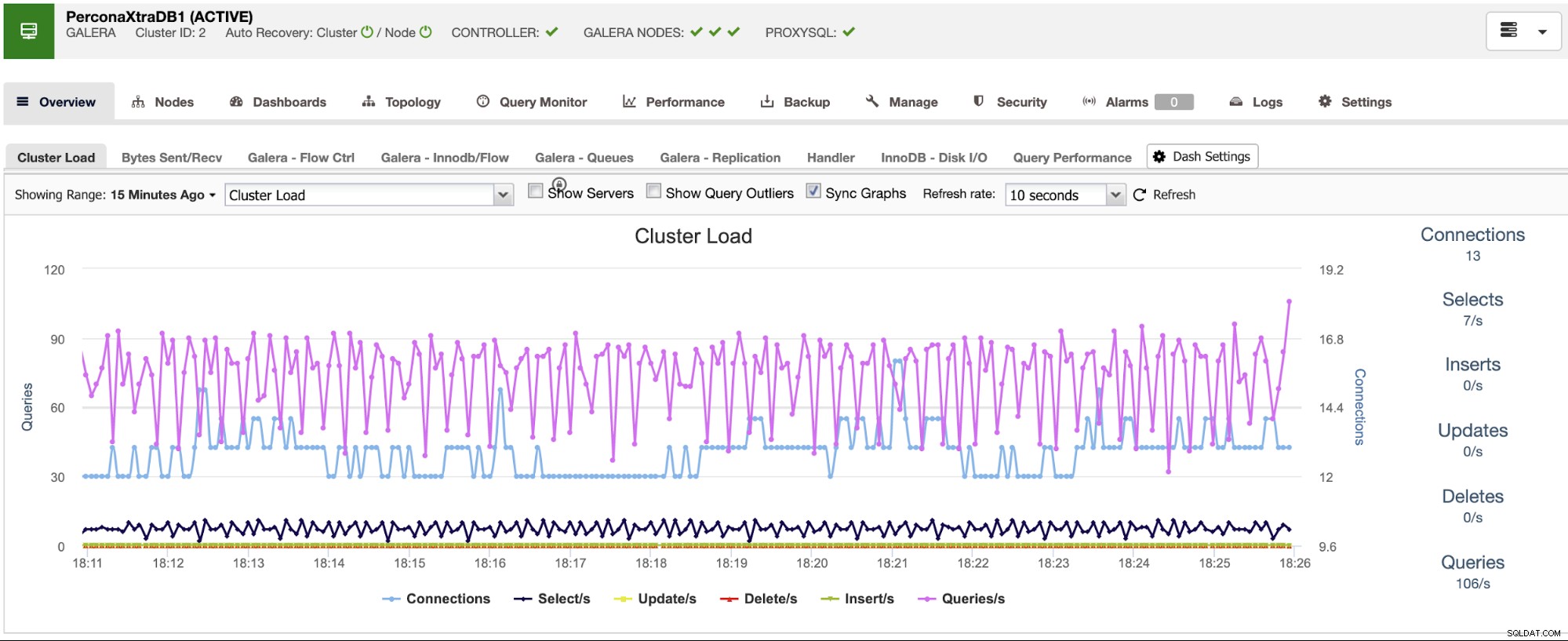
Anda juga dapat menggunakan bagian dasbor untuk mendapatkan tampilan yang lebih ramah pengguna tentang status sistem Anda.
Kesimpulan
Jika terjadi kegagalan database master, Anda harus memiliki semua informasi untuk mengambil tindakan yang diperlukan secepatnya. Memiliki DRP yang baik adalah kunci untuk menjaga sistem Anda berjalan sepanjang (atau hampir semua) waktu. DRP ini harus menyertakan proses failover yang terdokumentasi dengan baik untuk memiliki RTO (Tujuan Waktu Pemulihan) yang dapat diterima untuk perusahaan.