Amazon Relational Database Service (AWS RDS) adalah layanan database yang terkelola sepenuhnya yang dapat mendukung beberapa mesin database. Di antara yang didukung adalah PostgreSQL, MySQL, dan MariaDB. ClusterControl, di sisi lain, adalah manajemen database dan perangkat lunak otomatisasi yang juga mendukung penanganan cadangan untuk database open source PostgreSQL, MySQL, dan MariaDB.
Meskipun RDS telah digunakan secara luas oleh banyak perusahaan, beberapa mungkin tidak mengetahui cara kerja Point-in-time Recovery (PITR) dan cara menggunakannya.
Beberapa mesin database yang digunakan oleh Amazon RDS memiliki pertimbangan khusus saat memulihkan dari titik waktu tertentu, dan di blog ini kita akan membahas cara kerjanya untuk PostgreSQL, MySQL, dan MariaDB. Kami juga akan membandingkan perbedaannya dengan fungsi PITR di ClusterControl.
Apa itu Pemulihan Point-in-Time (PITR)
Jika Anda belum terbiasa dengan Disaster Recovery Planning (DRP) atau Business Continuity Planning (BCP), Anda harus mengetahui bahwa PITR adalah salah satu praktik standar penting untuk manajemen database. Seperti disebutkan di blog kami sebelumnya, Point In Time Recovery (PITR) melibatkan pemulihan basis data pada saat tertentu di masa lalu. Untuk dapat melakukan ini, kita perlu memulihkan cadangan penuh dan kemudian PITR terjadi dengan menerapkan semua perubahan yang terjadi pada titik waktu tertentu yang ingin Anda pulihkan.
Pemulihan Point-in-time (PITR) dengan AWS RDS
AWS RDS menangani PITR secara berbeda dari cara tradisional yang umum untuk database lokal. Hasil akhirnya berbagi konsep yang sama, tetapi dengan AWS RDS, cadangan lengkap adalah snapshot, kemudian menerapkan PITR (yang disimpan di S3), dan kemudian meluncurkan instans database baru (berbeda).
Cara umum mengharuskan Anda menggunakan logika (menggunakan pg_dump, mysqldump, mydumper) atau fisik (Percona Xtrabackup, Mariabackup, pg_basebackup, pg_backrest) untuk cadangan lengkap Anda sebelum menerapkan PITR.
AWS RDS akan meminta Anda untuk meluncurkan instans DB baru, sedangkan pendekatan tradisional memungkinkan Anda menyimpan PITR secara fleksibel pada node database yang sama tempat pencadangan dilakukan atau menargetkan instans DB (yang sudah ada) berbeda yang membutuhkan pemulihan atau ke instans DB baru.
Setelah pembuatan instans AWS RDS Anda, pencadangan otomatis akan diaktifkan. Amazon RDS secara otomatis melakukan snapshot harian penuh dari data Anda. Jadwal snapshot dapat diatur selama pembuatan di jendela cadangan pilihan Anda. Saat pencadangan otomatis diaktifkan, AWS juga merekam log transaksi ke Amazon S3 setiap 5 menit yang merekam semua pembaruan DB Anda. Setelah Anda memulai pemulihan point-in-time, log transaksi diterapkan ke pencadangan harian yang paling tepat untuk memulihkan instans DB Anda ke waktu yang diminta spesifik.
Cara Mendaftar PITR dengan AWS RDS
Menerapkan PITR dapat dilakukan dengan tiga cara berbeda. Anda dapat menggunakan AWS Management Console, AWS CLI, atau Amazon RDS API setelah instans DB tersedia. Anda juga harus mempertimbangkan bahwa log transaksi dicatat setiap lima menit yang kemudian disimpan di AWS S3.
Setelah Anda memulihkan instans DB, grup keamanan DB (SG) default diterapkan ke instans DB baru. Jika Anda memerlukan db SG khusus, Anda dapat secara eksplisit mendefinisikannya menggunakan AWS Management Console, perintah AWS CLI modifikasi-db-instance, atau operasi Amazon RDS API ModifyDBInstance setelah instans DB tersedia.
PITR mengharuskan Anda mengidentifikasi waktu pemulihan terbaru untuk instans DB. Untuk melakukannya, Anda dapat menggunakan perintah AWS CLI mendeskripsikan-db-instances dan melihat nilai yang dikembalikan di bidang LatestRestorableTime untuk instans DB. Misalnya,
[example@sqldat.com ~]# aws rds describe-db-instances --db-instance-identifier database-s9s-mysql|grep LatestRestorableTime
"LatestRestorableTime": "2020-05-08T07:25:00+00:00",Menerapkan PITR dengan AWS Console
Untuk menerapkan PITR di AWS Console, login ke AWS Console → buka Amazon RDS → Databases → Pilih (atau klik) instans DB yang Anda inginkan, lalu klik Tindakan. Lihat di bawah,
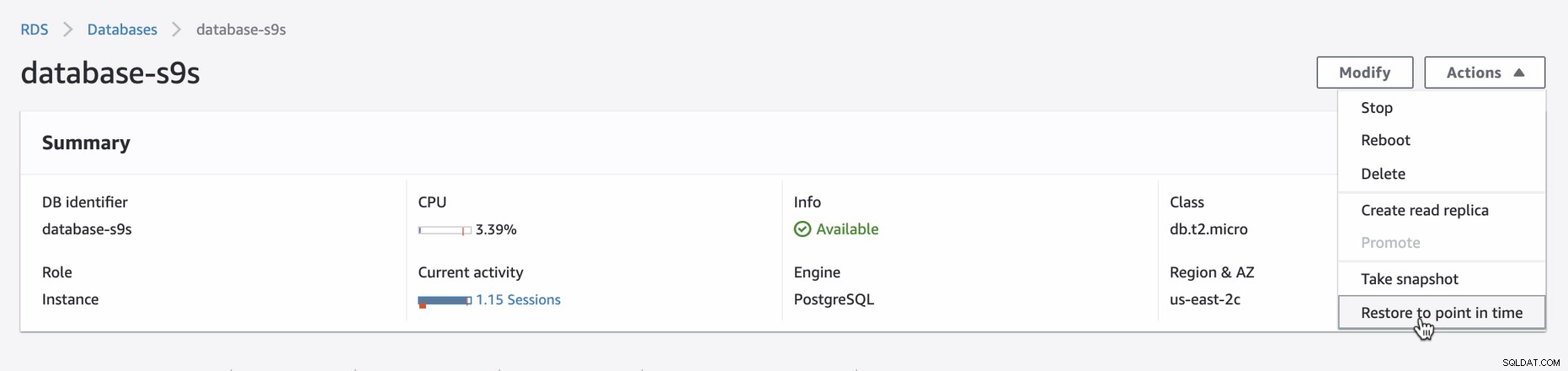
Setelah Anda mencoba memulihkan melalui PITR, UI konsol akan memberi tahu Anda apa yang waktu pemulihan terbaru yang dapat Anda atur. Anda dapat menggunakan waktu pemulihan terbaru atau menentukan tanggal dan waktu target yang Anda inginkan. Lihat di bawah:
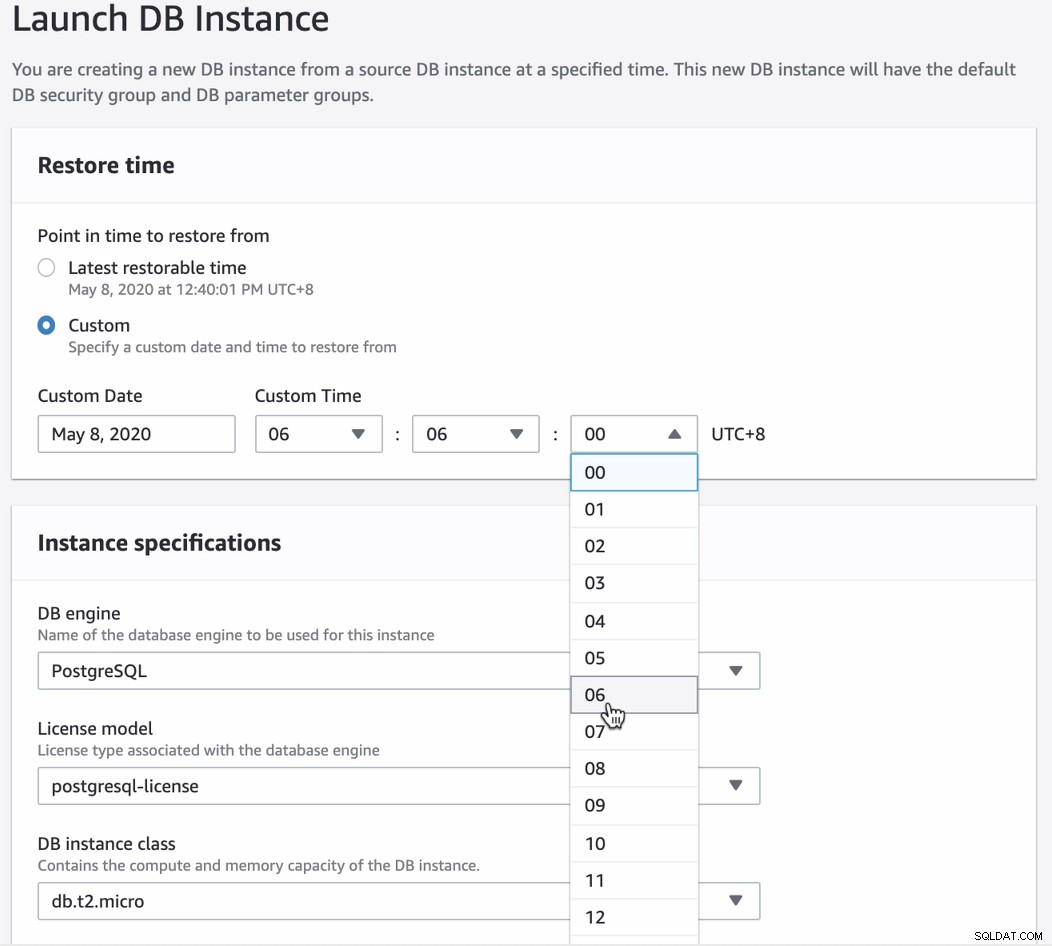
Cukup mudah diikuti tetapi Anda harus memperhatikan dan mengisi spesifikasi yang diinginkan yang Anda perlukan untuk meluncurkan instans baru.
Menerapkan PITR dengan AWS CLI
Menggunakan AWS CLI bisa sangat berguna terutama jika Anda perlu menggabungkan ini dengan alat otomatisasi untuk saluran CI/CD Anda. Untuk melakukannya, Anda dapat memulainya dengan,
[example@sqldat.com ~]# aws rds restore-db-instance-to-point-in-time \
> --source-db-instance-identifier database-s9s-mysql \
> --target-db-instance-identifier database-s9s-mysql-pitr \
> --restore-time 2020-05-08T07:30:00+00:00
{
"DBInstance": {
"DBInstanceIdentifier": "database-s9s-mysql-pitr",
"DBInstanceClass": "db.t2.micro",
"Engine": "mysql",
"DBInstanceStatus": "creating",
"MasterUsername": "admin",
"DBName": "s9s",
"AllocatedStorage": 18,
"PreferredBackupWindow": "00:00-00:30",
"BackupRetentionPeriod": 7,
"DBSecurityGroups": [],
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-xxxxx",
"Status": "active"
}
],
"DBParameterGroups": [
{
"DBParameterGroupName": "default.mysql5.7",
"ParameterApplyStatus": "in-sync"
}
],
"DBSubnetGroup": {
"DBSubnetGroupName": "default",
"DBSubnetGroupDescription": "default",
"VpcId": "vpc-f91bdf90",
"SubnetGroupStatus": "Complete",
"Subnets": [
{
"SubnetIdentifier": "subnet-exxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2a"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2c"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2b"
},
"SubnetStatus": "Active"
}
]
},
"PreferredMaintenanceWindow": "fri:06:01-fri:06:31",
"PendingModifiedValues": {},
"MultiAZ": false,
"EngineVersion": "5.7.22",
"AutoMinorVersionUpgrade": true,
"ReadReplicaDBInstanceIdentifiers": [],
"LicenseModel": "general-public-license",
"OptionGroupMemberships": [
{
"OptionGroupName": "default:mysql-5-7",
"Status": "pending-apply"
}
],
"PubliclyAccessible": true,
"StorageType": "gp2",
"DbInstancePort": 0,
"StorageEncrypted": false,
"DbiResourceId": "db-XXXXXXXXXXXXXXXXX",
"CACertificateIdentifier": "rds-ca-2019",
"DomainMemberships": [],
"CopyTagsToSnapshot": false,
"MonitoringInterval": 0,
"DBInstanceArn": "arn:aws:rds:us-east-2:042171833148:db:database-s9s-mysql-pitr",
"IAMDatabaseAuthenticationEnabled": false,
"PerformanceInsightsEnabled": false,
"DeletionProtection": false,
"AssociatedRoles": []
}
}Kedua pendekatan ini membutuhkan waktu untuk membuat atau menyiapkan instans database hingga tersedia dan dapat dilihat dalam daftar instans database di konsol AWS RDS Anda.
Batasan PITR AWS RDS
Saat menggunakan AWS RDS, Anda terikat dengan mereka sebagai vendor. Memindahkan operasi Anda keluar dari sistem mereka bisa merepotkan. Berikut adalah beberapa hal yang harus Anda pertimbangkan:
- Tingkat penguncian vendor saat menggunakan AWS RDS
- Satu-satunya pilihan Anda untuk memulihkan melalui PITR mengharuskan Anda meluncurkan instans baru yang berjalan di RDS
- Tidak mungkin Anda dapat memulihkan menggunakan proses PITR ke node eksternal yang tidak ada di RDS
- Mengharuskan Anda mempelajari dan memahami alat dan kerangka kerja keamanan mereka.
Cara Menerapkan PITR dengan ClusterControl
ClusterControl menjalankan PITR dengan cara yang sederhana, namun lugas, (tetapi Anda harus mengaktifkan atau mengatur prasyarat agar PITR dapat digunakan). Seperti yang dibahas sebelumnya, PITR untuk ClusterControl bekerja secara berbeda dari AWS RDS. Berikut daftar tempat PITR dapat diterapkan menggunakan ClusterControl (mulai versi 1.7.6):
- Berlaku setelah pencadangan penuh berdasarkan solusi metode pencadangan yang tersedia yang kami dukung untuk database PostgreSQL, MySQL, dan MariaDB.
- Untuk PostgreSQL, hanya metode pencadangan pg_basebackup yang didukung dan kompatibel untuk bekerja dengan PITR
- Untuk MySQL atau MariaDB, hanya metode pencadangan xtrabackup/mariabackup yang didukung dan kompatibel untuk bekerja dengan PITR
- Berlaku untuk database MySQL atau MariaDB, PITR hanya berlaku jika node sumber dari cadangan lengkap adalah node target yang akan dipulihkan.
- Database MySQL atau MariaDB mengharuskan Anda mengaktifkan logging biner
- Berlaku untuk database PostgreSQL, PITR hanya berlaku untuk master/utama yang aktif dan mengharuskan Anda untuk mengaktifkan pengarsipan WAL.
- PITR hanya dapat diterapkan saat memulihkan cadangan lengkap yang ada
Manajemen Pencadangan untuk ClusterControl berlaku untuk lingkungan di mana database tidak sepenuhnya dikelola dan memerlukan akses SSH yang sama sekali berbeda dari AWS RDS. Meskipun mereka berbagi hasil yang sama yaitu memulihkan data, solusi pencadangan yang ada di ClusterControl tidak dapat diterapkan di AWS RDS. ClusterControl juga tidak mendukung RDS untuk pengelolaan dan pemantauan.
Menggunakan ClusterControl untuk PITR di PostgreSQL
Seperti yang disebutkan sebelumnya tentang prasyarat untuk memanfaatkan PITR, Anda harus mengaktifkan pengarsipan WAL. Ini dapat dicapai dengan mengklik ikon roda gigi seperti yang ditunjukkan di bawah ini:
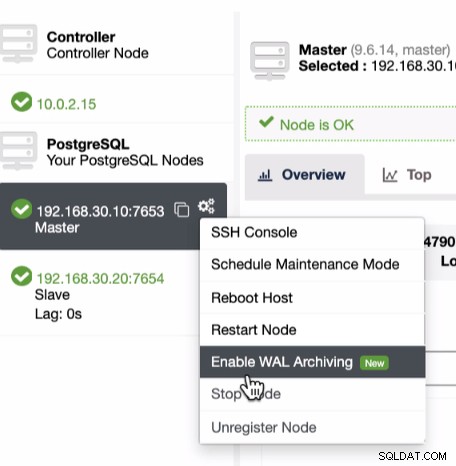
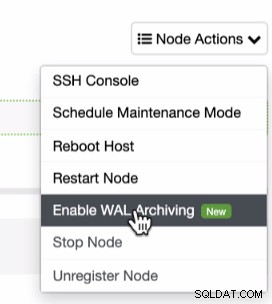
Karena PITR dapat diterapkan segera setelah pencadangan penuh, Anda hanya dapat menjalankan temukan fitur ini di bawah daftar Cadangan tempat Anda dapat mencoba memulihkan cadangan yang ada. Untuk melakukannya, urutan tangkapan layar akan menunjukkan cara melakukannya:
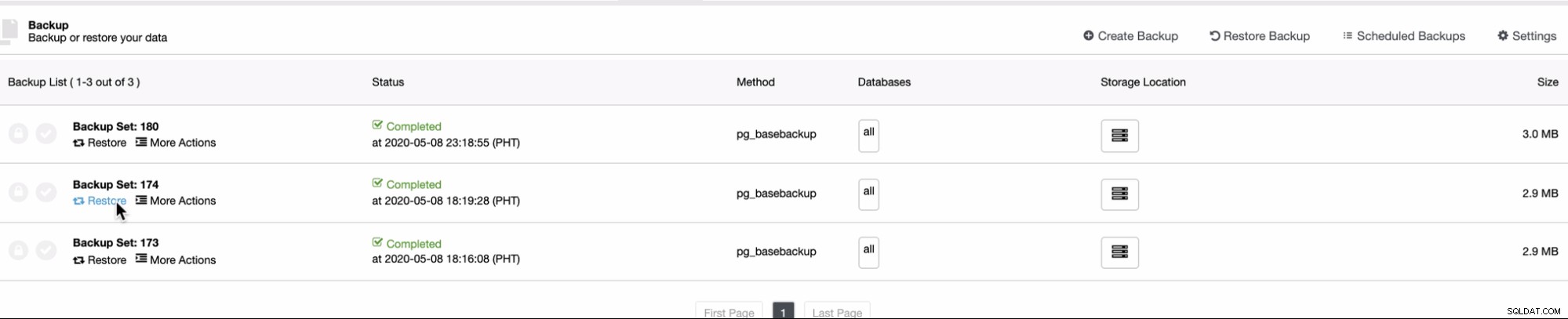
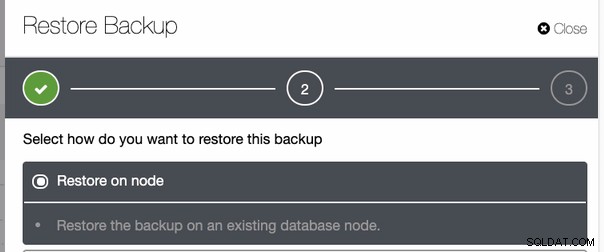
Kemudian pulihkan di host yang sama dengan sumber cadangan seperti yang diambil ,
Kemudian tinggal tentukan tanggal dan waktunya,
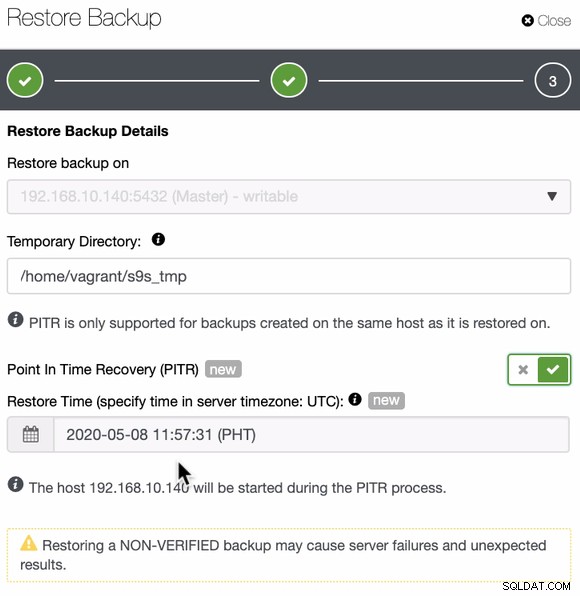
Setelah Anda menetapkan dan menentukan tanggal dan waktu, ClusterControl kemudian akan memulihkan cadangan kemudian menerapkan PITR setelah pencadangan selesai. Anda juga dapat memverifikasi ini dengan memeriksa log aktivitas pekerjaan seperti di bawah ini,

Menggunakan ClusterControl untuk PITR di MySQL/MariaDB
PITR untuk MySQL atau MariaDB tidak berbeda dari pendekatan yang kami miliki di atas untuk PostgreSQL. Namun, tidak ada kesetaraan pengarsipan WAL atau tombol atau opsi yang dapat Anda atur yang diperlukan untuk mengaktifkan fungsionalitas PITR. Karena MySQL dan MariaDB mengharuskan PITR dapat diterapkan menggunakan log biner, di ClusterControl, ini dapat ditangani di bawah tab Kelola. Lihat di bawah:
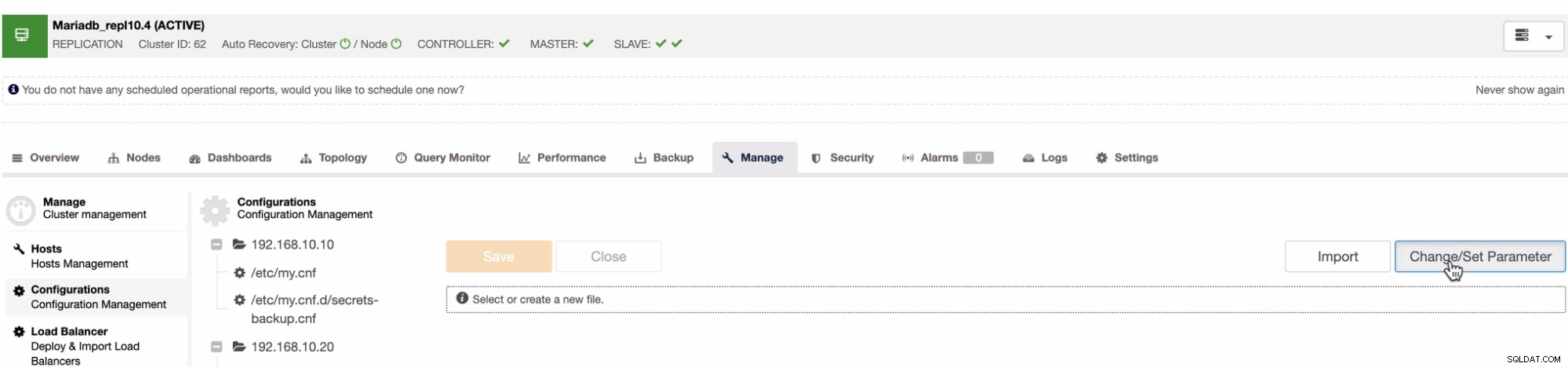
Kemudian tentukan variabel log_bin dengan nilai boolean yang sesuai. Misalnya,
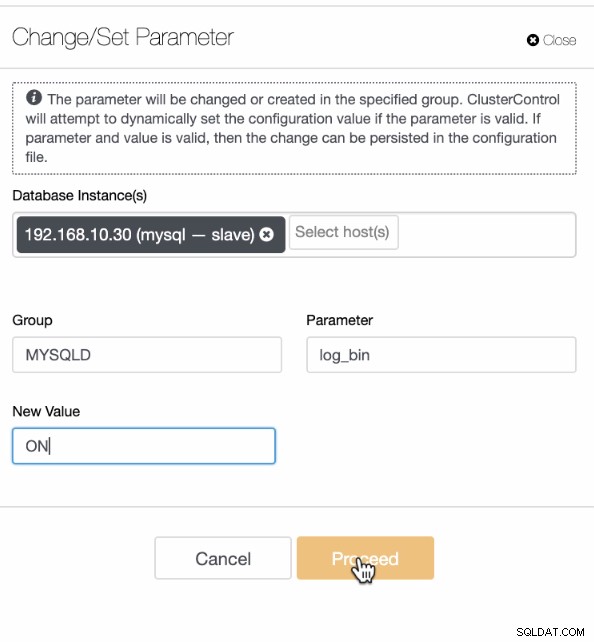
Setelah log_bin diatur pada node, pastikan Anda memiliki backup diambil pada node yang sama di mana Anda juga akan menerapkan proses PITR. Hal ini dinyatakan sebelumnya dalam prasyarat. Atau, Anda juga dapat mengedit file konfigurasi (/etc/my.cnf atau /etc/mysql/my.cnf) dan menambahkan log_bin=ON di bawah bagian [mysqld], misalnya.
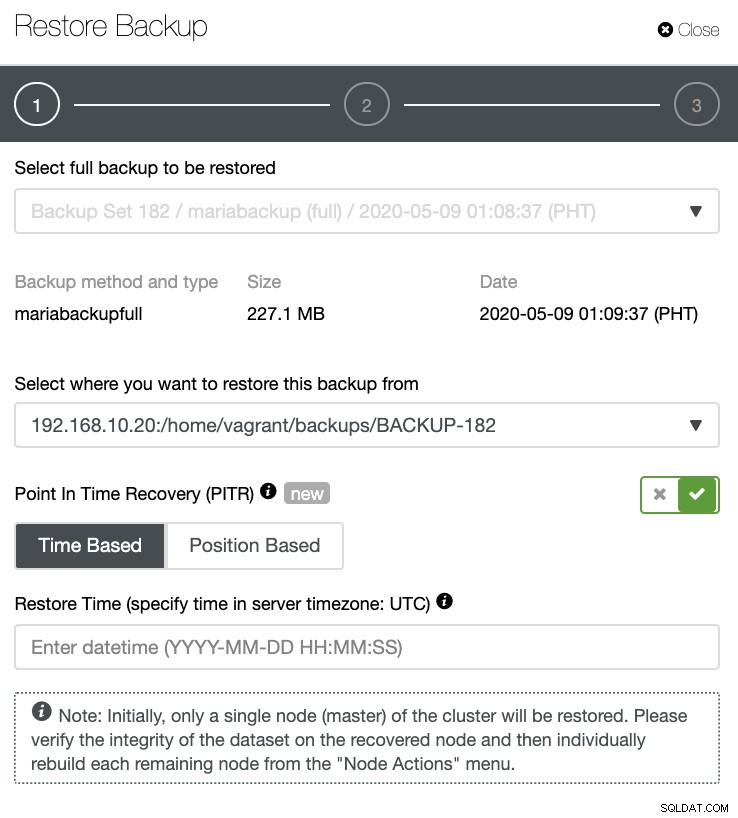
Bila log biner diaktifkan dan full backup tersedia, Anda kemudian dapat melakukan proses PITR sama seperti cara PostgreSQL UI tetapi dengan bidang berbeda yang dapat Anda isi. Anda dapat menentukan tanggal dan waktu atau tentukan berdasarkan file dan posisi binlog (atau posisi x &y). Lihat di bawah:
Keterbatasan PITR Kontrol Cluster
Jika Anda bertanya-tanya apa yang bisa dan tidak bisa Anda lakukan untuk PITR di ClusterControl, berikut daftarnya di bawah ini:
- Tidak ada alat CLI s9s saat ini yang mendukung proses PITR, jadi tidak mungkin untuk mengotomatisasi atau mengintegrasikan ke saluran CI/CD Anda.
- Tidak ada dukungan PITR untuk node eksternal
- Tidak ada dukungan PITR ketika sumber cadangan berbeda dari node target
- Tidak ada pemberitahuan berkala tentang periode waktu paling akhir yang dapat Anda ajukan untuk PITR
Kesimpulan
Kedua alat memiliki pendekatan dan solusi berbeda untuk lingkungan target. Kesimpulan utamanya adalah AWS RDS memiliki PITR sendiri yang lebih cepat, tetapi hanya berlaku jika database Anda dihosting di bawah RDS dan Anda terikat dengan vendor lock in.
ClusterControl memungkinkan Anda untuk secara bebas menerapkan proses PITR ke pusat data apa pun atau di lokasi selama prasyarat dipertimbangkan. Tujuannya adalah untuk memulihkan data. Terlepas dari keterbatasannya, ini didasarkan pada bagaimana Anda akan menggunakan solusi sesuai dengan lingkungan arsitektur yang Anda gunakan.



