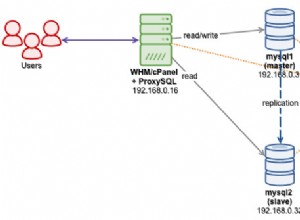
Aduh.. bukan itu cara kerja MySQL Cluster.
Secara default MySQL Cluster mempartisi data pada PRIMARY KEY. Namun dimungkinkan untuk menggunakan partisi dan partisi yang ditentukan pengguna pada bagian KUNCI UTAMA. Ini sangat berguna untuk mengelompokkan data terkait bersama-sama dan untuk memastikan lokalitas data dalam satu partisi. Karena data terkait kemudian disimpan dalam satu partisi, maka dimungkinkan untuk menskalakan dari 2 hingga 48 node data tanpa mengorbankan kinerja - itu akan konstan. Lihat detail selengkapnya di https://dev.mysql.com/doc/refman/5.5/en/partitioning-key.html
Secara default, API akan menghitung hash (menggunakan algoritme LH3*, yang menggunakan md5) pada PRIMARY KEY (atau bagian kunci utama yang ditentukan yang digunakan) untuk menentukan partisi mana yang akan mengirim kueri. Hash yang dihitung adalah 128 bit, dan 64 bit menentukan partisi dan 64 bit menentukan lokasi dalam indeks hash pada partisi. Sebagai pengguna, Anda tidak memiliki wawasan persis node mana yang memiliki data (atau siapa yang akan menyimpan data), tetapi secara praktis hal itu tidak terlalu penting.
Mengenai pertanyaan awal tentang mendistribusikan satu MySQL Cluster di 2 cloud dan mempartisi data. Node Data memerlukan akses latensi rendah yang andal satu sama lain, jadi Anda tidak ingin menyebarkan node kecuali jika jaraknya kurang dari 50-100 mil.