Jika infrastruktur TI Anda berjalan di AWS, Anda mungkin pernah mendengar tentang Amazon Relational Database Service (RDS), cara mudah untuk menyiapkan, mengoperasikan, dan menskalakan database relasional di cloud. Ini memberikan kapasitas yang hemat biaya dan dapat diubah ukurannya sambil mengotomatiskan tugas-tugas administrasi yang memakan waktu seperti penyediaan perangkat keras, pengaturan basis data, patching, dan pencadangan. Ada sejumlah penawaran mesin database untuk RDS seperti MySQL, MariaDB, PostgreSQL, Microsoft SQL Server dan Oracle Server.
ClusterControl 1.7.3 bertindak serupa dengan RDS karena mendukung penyebaran, pengelolaan, pemantauan, dan penskalaan cluster database pada platform AWS. Ini juga mendukung sejumlah platform cloud lain seperti Google Cloud Platform dan Microsoft Azure. ClusterControl memahami topologi database dan mampu melakukan pemulihan otomatis, manajemen topologi, dan banyak fitur lanjutan lainnya untuk mengontrol database Anda.
Dalam posting blog ini, kita akan membandingkan waktu failover otomatis untuk Amazon Aurora, Amazon RDS untuk MySQL, dan pengaturan Replikasi MySQL yang diterapkan dan dikelola oleh ClusterControl. Jenis failover yang akan kita lakukan adalah promosi budak jika master turun. Di sinilah slave paling mutakhir mengambil alih peran master dalam cluster untuk melanjutkan layanan database.
Uji Kegagalan Kami
Untuk mengukur waktu failover, kita akan menjalankan tes MySQL connect-update sederhana, dengan loop untuk menghitung status pernyataan SQL yang terhubung ke satu titik akhir database. Scriptnya seperti ini:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Skrip Bash di atas hanya terhubung ke host MySQL dan melakukan pembaruan pada satu baris dengan batas waktu 1 detik pada perintah klien Bash dan mysql. Parameter terkait waktu habis diperlukan agar kami dapat mengukur waktu henti dalam hitungan detik dengan benar karena klien mysql default untuk selalu menyambung kembali hingga mencapai waktu tunggu_waktu habis MySQL. Kami mengisi dataset uji dengan perintah berikut sebelumnya:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareScript melaporkan apakah kueri di atas berhasil (OK) atau gagal (Gagal). Contoh keluaran ditampilkan lebih jauh ke bawah.
Kegagalan dengan Amazon RDS untuk MySQL
Dalam pengujian kami, kami menggunakan penawaran RDS terendah dengan spesifikasi berikut:
- Versi MySQL:5.7.22
- vCPU:4
- RAM:16 GB
- Jenis penyimpanan:IOPS (SSD) yang Disediakan
- IOPS:1000
- Penyimpanan:100Gib
- Replikasi Multi-AZ:Ya
Setelah Amazon RDS menyediakan instans DB, Anda dapat menggunakan aplikasi atau utilitas klien MySQL standar apa pun untuk terhubung ke instans. Dalam string koneksi, Anda menentukan alamat DNS dari titik akhir instans DB sebagai parameter host, dan menentukan nomor port dari titik akhir instans DB sebagai parameter port.
Menurut halaman dokumentasi Amazon RDS, jika terjadi pemadaman terencana atau tidak terencana dari instans DB Anda, Amazon RDS secara otomatis beralih ke replika siaga di Availability Zone lain jika Anda telah mengaktifkan Multi-AZ. Waktu yang diperlukan untuk penyelesaian failover bergantung pada aktivitas database dan kondisi lain saat instans DB utama tidak tersedia. Waktu failover biasanya 60-120 detik.
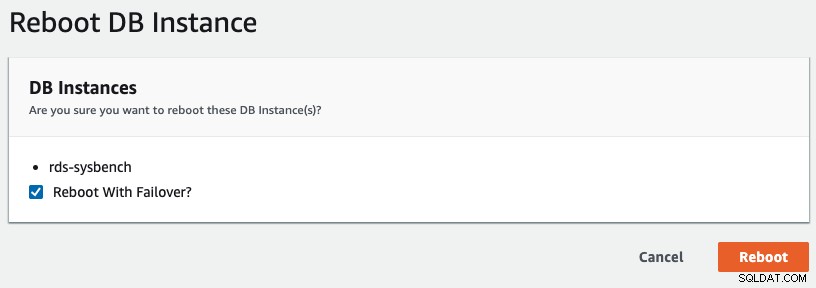
Untuk memulai failover multi-AZ di RDS, kami melakukan operasi reboot dengan "Reboot with Failover" dicentang, seperti yang ditunjukkan pada tangkapan layar berikut:
Berikut yang diamati oleh aplikasi kita:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Waktu henti MySQL dilihat dari sisi aplikasi dimulai dari 03:41:09 sampai 03:41:36 yang totalnya sekitar 27 detik. Dari kejadian RDS, kita dapat melihat failover multi-AZ hanya terjadi 15 detik setelah waktu henti yang sebenarnya:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Setelah instance database baru dimulai ulang sekitar 03:41:33, layanan MySQL kemudian dapat diakses sekitar 3 detik kemudian.
Kegagalan dengan Amazon Aurora untuk MySQL
Amazon Aurora dapat dianggap sebagai versi RDS yang unggul, dengan banyak fitur penting seperti replikasi yang lebih cepat dengan penyimpanan bersama, tidak ada kehilangan data selama failover, dan batas penyimpanan hingga 64TB. Amazon Aurora untuk MySQL didasarkan pada MySQL Edition open source, tetapi bukan open source dengan sendirinya; itu adalah milik, database sumber tertutup. Ini bekerja sama dengan replikasi MySQL (satu dan hanya satu master, dengan banyak budak) dan failover secara otomatis ditangani oleh Amazon Aurora.
Menurut FAQ Amazon Aurora, jika Anda memiliki Replika Amazon Aurora, di Availability Zone yang sama atau berbeda, saat gagal, Aurora membalik canonical name record (CNAME) untuk Instans DB Anda untuk menunjuk ke replika yang sehat, yang ada di gilirannya dipromosikan menjadi primer baru. Start-to-finish, failover biasanya selesai dalam waktu 30 detik.
Jika Anda tidak memiliki Replika Amazon Aurora (yaitu instans tunggal), Aurora pertama-tama akan mencoba membuat Instans DB baru di Availability Zone yang sama dengan instans asli. Jika tidak dapat melakukannya, Aurora akan mencoba membuat Instans DB baru di Availability Zone yang berbeda. Dari awal hingga akhir, failover biasanya selesai dalam waktu kurang dari 15 menit.
Aplikasi Anda harus mencoba kembali koneksi database jika koneksi terputus.
Setelah Amazon Aurora menyediakan instans DB Anda, Anda akan mendapatkan dua titik akhir satu untuk penulis dan satu untuk pembaca. Titik akhir pembaca menyediakan dukungan penyeimbangan beban untuk koneksi baca-saja ke klaster DB. Titik akhir berikut diambil dari penyiapan pengujian kami:
- penulis - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- pembaca - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
Dalam pengujian kami, kami menggunakan spesifikasi Aurora berikut:
- Jenis instans:db.r5.large
- Versi MySQL:5.7.12
- vCPU:2
- RAM:16 GB
- Replikasi Multi-AZ:Ya
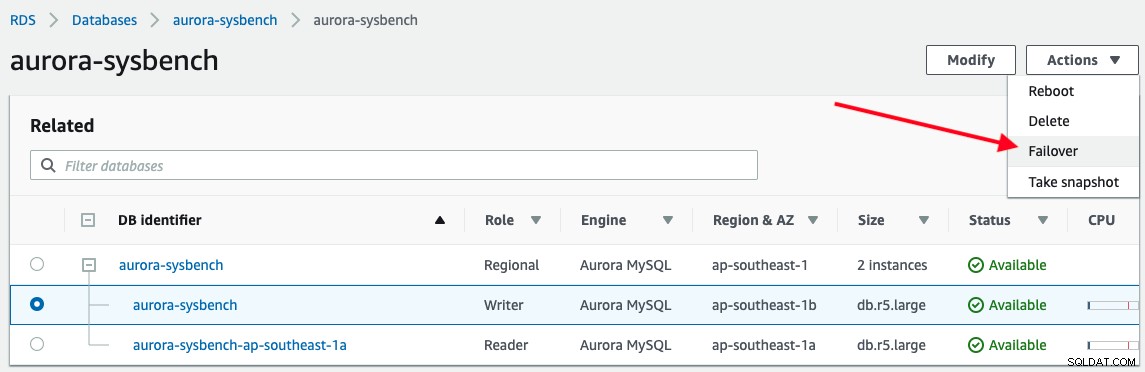
Untuk memicu failover, cukup pilih instance penulis -> Tindakan -> Failover, seperti yang ditunjukkan pada tangkapan layar berikut:
Output berikut dilaporkan oleh aplikasi kami saat menghubungkan ke titik akhir penulis Aurora :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Downtime database dimulai pada pukul 12:35:49 sampai 12:35:56 dengan total waktu 7 detik. Itu cukup mengesankan.
Melihat peristiwa database dari konsol manajemen Aurora, hanya dua peristiwa berikut yang terjadi:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedTidak butuh banyak waktu bagi Aurora untuk mempromosikan budak menjadi master, dan menurunkan master menjadi budak. Perhatikan bahwa semua replika Aurora berbagi volume dasar yang sama dengan instans utama dan ini berarti bahwa replikasi dapat dilakukan dalam milidetik karena pembaruan yang dibuat oleh instans utama langsung tersedia untuk semua replika Aurora. Oleh karena itu, ia memiliki jeda replikasi minimal (Amazon diklaim 100 milidetik dan kurang). Ini akan sangat mengurangi waktu pemeriksaan kesehatan dan meningkatkan waktu pemulihan secara signifikan.
Kegagalan dengan ClusterControl
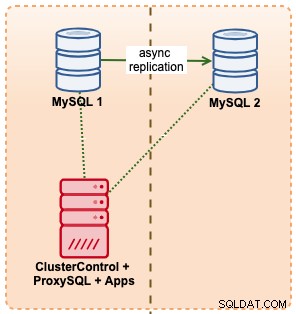
Dalam contoh ini, kami meniru pengaturan serupa dengan Amazon RDS menggunakan instans m5.xlarge, dengan ProxySQL di antaranya untuk mengotomatiskan failover dari aplikasi menggunakan akses titik akhir tunggal seperti RDS. Diagram berikut mengilustrasikan arsitektur kita:
Karena kita memiliki akses langsung ke instance database, kita akan memicu failover otomatis hanya dengan mematikan proses MySQL pada master aktif:
$ kill -9 $(pidof mysqld)Perintah di atas memicu pemulihan otomatis di dalam ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Sementara dari sudut pandang aplikasi pengujian kami, waktu henti terjadi pada waktu berikut saat menghubungkan ke port host ProxySQL 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Dengan melihat kedua peristiwa tugas pemulihan dan output dari aplikasi kita, node database MySQL turun 4 detik sebelum tugas pemulihan cluster dimulai, dari 11:08:28 hingga 11:08:39, dengan total waktu henti MySQL 11 detik . Salah satu hal yang paling mengesankan tentang ClusterControl adalah, Anda dapat melacak kemajuan pemulihan pada tindakan apa yang diambil dan dilakukan oleh ClusterControl selama failover. Ini memberikan tingkat transparansi yang tidak akan bisa Anda dapatkan dengan penawaran basis data apa pun oleh penyedia cloud.
Untuk replikasi MySQL/MariaDB/PostgreSQL, ClusterControl memungkinkan Anda memiliki database yang lebih halus dengan dukungan konfigurasi dan parameter lanjutan berikut:
- Manajemen topologi replikasi master-master
- Manajemen topologi replikasi rantai
- Penampil topologi
- Budak Whitelist/Blacklist untuk dipromosikan sebagai master
- Pemeriksa transaksi yang salah
- Acara pra/posting, sukses/gagal failover/switchover terkait dengan skrip eksternal
- Otomatis membangun kembali budak saat kesalahan
- Skalakan budak dari cadangan yang ada
Ringkasan Waktu Kegagalan
Dalam hal waktu failover, Amazon RDS Aurora untuk MySQL adalah pemenangnya dengan 7 detik , diikuti oleh ClusterControl 11 detik dan Amazon RDS untuk MySQL dengan 27 detik .
Perhatikan bahwa ini hanyalah tes sederhana, dengan satu klien dan satu transaksi per detik untuk mengukur waktu pemulihan tercepat. Transaksi besar atau proses pemulihan yang lama dapat meningkatkan waktu failover, mis., transaksi yang berjalan lama mungkin memerlukan waktu lama untuk dikembalikan saat mematikan MySQL.