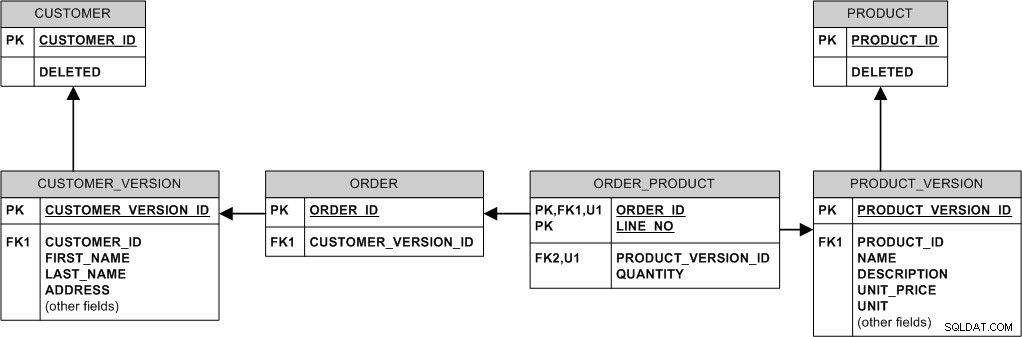
Berikut adalah salah satu cara untuk melakukannya:
Intinya, kami tidak pernah mengubah atau menghapus data yang ada. Kami "memodifikasi" dengan membuat versi baru. Kami "menghapusnya" dengan menyetel tanda DELETED.
Misalnya:
- Jika produk mengubah harga, kami memasukkan baris baru ke PRODUCT_VERSION sementara pesanan lama tetap terhubung ke PRODUCT_VERSION lama dan harga lama.
- Saat pembeli mengubah alamat, kami cukup menyisipkan baris baru di CUSTOMER_VERSION dan menautkan pesanan baru ke sana, sementara pesanan lama tetap tertaut ke versi lama.
- Jika produk dihapus, kami tidak benar-benar menghapusnya - kami hanya menyetel tanda PRODUCT.DELETED, sehingga semua pesanan yang dibuat secara historis untuk produk tersebut tetap berada di database.
- Jika pelanggan dihapus (misalnya karena dia meminta untuk tidak terdaftar), setel tanda CUSTOMER.DELETED.
Peringatan:
- Jika nama produk harus unik, itu tidak dapat diterapkan secara deklaratif dalam model di atas. Anda harus "mempromosikan" NAMA dari PRODUCT_VERSION ke PRODUCT, menjadikannya kunci di sana dan melepaskan kemampuan untuk "mengembangkan" nama produk, atau menerapkan keunikan hanya pada PRODUCT_VER terbaru (mungkin melalui pemicu).
- Ada potensi masalah dengan privasi pelanggan. Jika pelanggan dihapus dari sistem, mungkin diinginkan untuk menghapus datanya secara fisik dari database dan hanya menyetel CUSTOMER.DELETED tidak akan melakukannya. Jika itu menjadi masalah, kosongkan data sensitif privasi di semua versi pelanggan, atau putuskan sambungan pesanan yang ada dari pelanggan sebenarnya dan sambungkan kembali ke pelanggan "anonim" khusus, lalu hapus semua versi pelanggan secara fisik.
Model ini menggunakan banyak hubungan pengidentifikasian. Ini mengarah ke kunci asing "gemuk" dan bisa menjadi sedikit masalah penyimpanan karena MySQL tidak mendukung kompresi indeks terdepan (tidak seperti, katakanlah, Oracle), tetapi di sisi lain InnoDB selalu mengelompokkan data pada PK dan pengelompokan ini dapat bermanfaat untuk kinerja. Selain itu, JOIN tidak terlalu diperlukan.
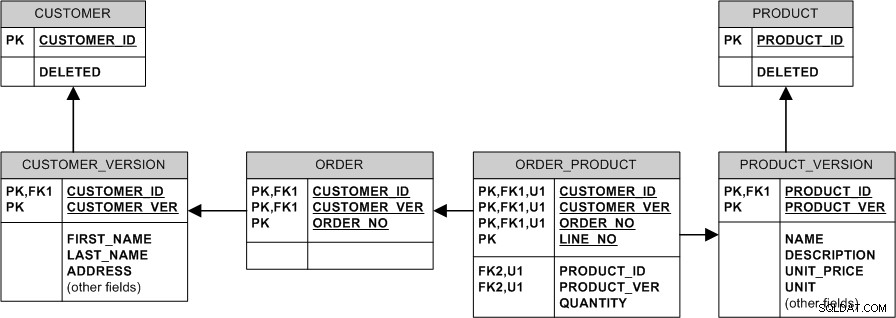
Model ekuivalen dengan hubungan non-identifikasi dan kunci pengganti akan terlihat seperti ini: