Sebelumnya kami memposting blog yang membahas Pencapaian MySQL Failover &Failback di Google Cloud Platform (GCP) dan di blog ini kita akan melihat bagaimana saingannya, Amazon Relational Database Service (RDS), menangani failover. Kami juga akan melihat bagaimana Anda dapat melakukan failback dari node master sebelumnya, mengembalikannya ke urutan aslinya sebagai master.
Saat membandingkan cloud publik raksasa teknologi yang mendukung layanan database relasional terkelola, Amazon adalah satu-satunya yang menawarkan opsi alternatif (bersama dengan MySQL/MariaDB, PostgreSQL, Oracle, dan SQL Server) untuk memberikan jenis manajemen basis datanya sendiri yang disebut Amazon Aurora. Bagi mereka yang tidak terbiasa dengan Aurora, ini adalah mesin database relasional terkelola sepenuhnya yang kompatibel dengan MySQL dan PostgreSQL. Aurora adalah bagian dari layanan database terkelola Amazon RDS, layanan web yang memudahkan untuk menyiapkan, mengoperasikan, dan menskalakan database relasional di cloud.
Mengapa Anda Perlu Failover atau Failback?
Mendesain sistem besar yang toleran terhadap kesalahan, sangat tersedia, tanpa Single-Point-Of-Failure (SPOF) memerlukan pengujian yang tepat untuk menentukan bagaimana reaksinya saat terjadi kesalahan.
Jika Anda khawatir tentang bagaimana kinerja sistem Anda saat merespons Fault Detection, Isolation, and Recovery (FDIR) sistem Anda, maka failover dan failback harus menjadi sangat penting.
Kegagalan Basis Data di Amazon RDS
Failover terjadi secara otomatis (karena failover manual disebut peralihan). Seperti yang dibahas di blog sebelumnya, kebutuhan untuk melakukan failover terjadi setelah master database Anda saat ini mengalami kegagalan jaringan atau penghentian sistem host yang tidak normal. Failover mengalihkannya ke status redundansi yang stabil atau ke server komputer siaga, sistem, komponen perangkat keras, atau jaringan.
Di Amazon RDS Anda tidak perlu melakukan ini, Anda juga tidak perlu memantaunya sendiri, karena RDS adalah layanan database terkelola (artinya Amazon menangani pekerjaan untuk Anda). Layanan ini mengelola hal-hal seperti masalah perangkat keras, pencadangan dan pemulihan, pembaruan perangkat lunak, peningkatan penyimpanan, dan bahkan penambalan perangkat lunak. Kita akan membicarakannya nanti di blog ini.
Database Failback di Amazon RDS
Di blog sebelumnya kami juga membahas mengapa Anda perlu melakukan failback. Dalam lingkungan yang direplikasi, master harus cukup kuat untuk membawa beban besar, terutama ketika persyaratan beban kerja tinggi. Penyiapan master Anda memerlukan spesifikasi perangkat keras yang memadai untuk memastikannya dapat memproses penulisan, menghasilkan peristiwa replikasi, memproses pembacaan kritis, dll, dengan cara yang stabil. Ketika failover diperlukan selama pemulihan bencana (atau untuk pemeliharaan), tidak jarang ketika mempromosikan master baru, Anda mungkin menggunakan perangkat keras yang lebih rendah. Situasi ini mungkin baik-baik saja untuk sementara, tetapi dalam jangka panjang, master yang ditunjuk harus dibawa kembali untuk memimpin replikasi setelah dianggap sehat (atau pemeliharaan selesai).
Berlawanan dengan failover, operasi failback biasanya terjadi di lingkungan yang terkendali dengan menggunakan peralihan. Ini jarang dilakukan ketika dalam mode panik. Pendekatan ini memberikan waktu yang cukup bagi teknisi Anda untuk merencanakan dengan cermat dan melatih latihan untuk memastikan transisi yang mulus. Tujuan utamanya adalah mengembalikan master lama yang baik ke status terbaru dan mengembalikan pengaturan replikasi ke topologi aslinya. Karena kita berurusan dengan Amazon RDS, Anda tidak perlu terlalu khawatir tentang jenis masalah ini karena ini adalah layanan terkelola dengan sebagian besar pekerjaan ditangani oleh Amazon.
Bagaimana Amazon RDS Menangani Kegagalan Basis Data?
Saat menerapkan node Amazon RDS, Anda dapat menyiapkan klaster database dengan Multi-Availability Zone (AZ) atau ke Single-Availability Zone. Mari kita periksa masing-masing tentang bagaimana failover diproses.
Apa itu Pengaturan Multi-AZ?
Saat bencana atau bencana terjadi, seperti pemadaman yang tidak direncanakan atau bencana alam di mana instans database Anda terpengaruh, Amazon RDS secara otomatis beralih ke replika siaga di Availability Zone lain. AZ ini biasanya berada di cabang lain dari pusat data, sering kali jauh dari zona ketersediaan saat ini tempat instans berada. AZ ini sangat tersedia, fasilitas canggih yang melindungi instans database Anda. Waktu failover bergantung pada penyelesaian penyiapan yang sering kali didasarkan pada ukuran dan aktivitas database serta kondisi lain yang ada pada saat instans DB utama tidak tersedia.
Waktu failover biasanya 60-120 detik. Mereka bisa lebih lama, karena transaksi besar atau proses pemulihan yang lama dapat meningkatkan waktu failover. Saat failover selesai, perlu waktu tambahan bagi Konsol RDS (UI) untuk mencerminkan Availability Zone yang baru.
Apa itu Pengaturan Single-AZ?
Penyiapan Single-AZ hanya boleh digunakan untuk instans database Anda jika RTO (Tujuan Waktu Pemulihan) dan RPO (Tujuan Titik Pemulihan) Anda cukup tinggi untuk memungkinkannya. Ada risiko yang terkait dengan penggunaan Single-AZ, seperti waktu henti yang besar yang dapat mengganggu operasi bisnis.
Skenario Kegagalan RDS Umum
Jumlah waktu henti tergantung pada jenis kegagalan. Mari kita bahas apa itu dan bagaimana pemulihan instance ditangani.
Kegagalan Instance yang Dapat Dipulihkan
Kegagalan instans Amazon RDS terjadi saat instans EC2 yang mendasarinya mengalami kegagalan. Saat terjadi, AWS akan memicu pemberitahuan peristiwa dan mengirimkan peringatan kepada Anda menggunakan Pemberitahuan Peristiwa Amazon RDS. Sistem ini menggunakan AWS Simple Notification Service (SNS) sebagai pemroses peringatan.
RDS akan secara otomatis mencoba meluncurkan instans baru di Availability Zone yang sama, melampirkan volume EBS, dan mencoba pemulihan. Dalam skenario ini, RTO biasanya di bawah 30 menit. RPO adalah nol karena volume EBS dapat dipulihkan. Volume EBS berada dalam satu Availability Zone dan jenis pemulihan ini terjadi di Availability Zone yang sama dengan instans asli.
Kegagalan Instans yang Tidak Dapat Dipulihkan atau Kegagalan Volume EBS
Untuk pemulihan instans RDS yang gagal (atau jika volume EBS yang mendasarinya mengalami kegagalan kehilangan data), pemulihan titik-dalam-waktu (PITR) diperlukan. PITR tidak ditangani secara otomatis oleh Amazon, jadi Anda perlu membuat skrip untuk mengotomatiskannya (menggunakan AWS Lambda) atau melakukannya secara manual.
Waktu RTO memerlukan memulai instans Amazon RDS baru, yang akan memiliki nama DNS baru setelah dibuat, dan kemudian menerapkan semua perubahan sejak pencadangan terakhir.
RPO biasanya 5 menit, tetapi Anda dapat menemukannya dengan memanggil RDS:describe-db-instances:LatestRestorableTime. Waktu dapat bervariasi dari 10 menit hingga jam tergantung pada jumlah log yang perlu diterapkan. Ini hanya dapat ditentukan dengan pengujian karena bergantung pada ukuran database, jumlah perubahan yang dibuat sejak pencadangan terakhir, dan tingkat beban kerja pada database. Karena cadangan dan log transaksi disimpan di Amazon S3, pemulihan ini dapat terjadi di Availability Zone yang didukung di Wilayah.
Setelah instance baru dibuat, Anda perlu memperbarui nama endpoint klien Anda. Anda juga memiliki opsi untuk mengganti namanya menjadi nama titik akhir instans DB lama (tetapi itu mengharuskan Anda untuk menghapus instans lama yang gagal) tetapi hal itu membuat penentuan akar penyebab masalah menjadi tidak mungkin.
Gangguan Zona Ketersediaan
Gangguan Availability Zone dapat bersifat sementara dan jarang terjadi, namun, jika kegagalan AZ lebih permanen, instans akan disetel ke status gagal. Pemulihan akan bekerja seperti yang dijelaskan sebelumnya dan instans baru dapat dibuat di AZ yang berbeda, menggunakan pemulihan point-in-time. Langkah ini harus dilakukan secara manual atau dengan scripting. Strategi untuk jenis skenario pemulihan ini harus menjadi bagian dari rencana pemulihan bencana (DR) Anda yang lebih besar.
Jika kegagalan Availability Zone bersifat sementara, database akan mati tetapi tetap dalam status tersedia. Anda bertanggung jawab untuk pemantauan tingkat aplikasi (menggunakan alat Amazon atau pihak ketiga) untuk mendeteksi jenis skenario ini. Jika ini terjadi, Anda dapat menunggu Availability Zone pulih, atau Anda dapat memilih untuk memulihkan instans ke Availability Zone lain dengan pemulihan point-in-time.
RTO adalah waktu yang diperlukan untuk memulai instans RDS baru dan kemudian menerapkan semua perubahan sejak pencadangan terakhir. RPO mungkin lebih lama, hingga saat kegagalan Availability Zone terjadi.
Menguji Failover dan Failback di Amazon RDS
Kami membuat dan menyiapkan Amazon RDS Aurora menggunakan db.r4.large dengan penerapan Multi-AZ (yang akan membuat replika/pembaca Aurora di AZ berbeda) yang hanya dapat diakses melalui EC2. Anda harus memastikan untuk memilih opsi ini saat pembuatan jika Anda bermaksud menjadikan Amazon RDS sebagai mekanisme failover.
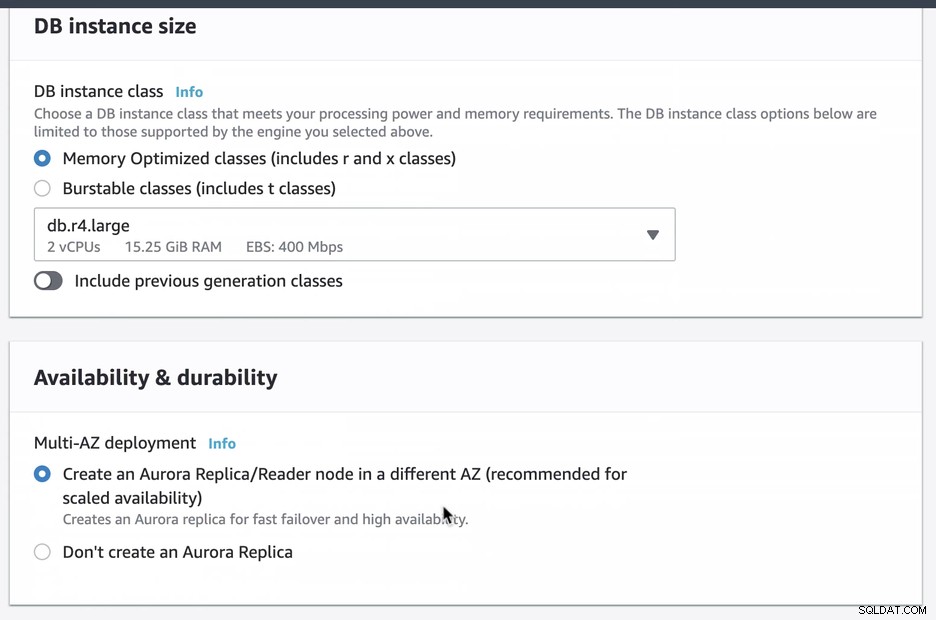
Selama penyediaan instans RDS kami, dibutuhkan sekitar ~11 menit sebelum instans menjadi tersedia dan dapat diakses. Di bawah ini adalah screenshot dari node yang tersedia di RDS setelah pembuatan:
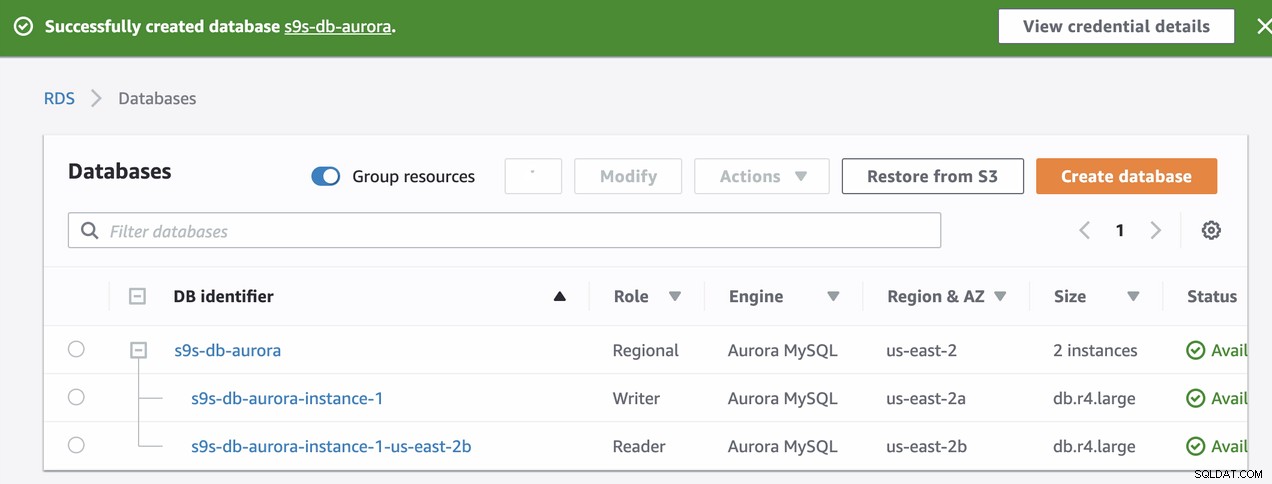
Kedua node ini akan memiliki nama titik akhir yang ditentukan, yang akan kita gunakan untuk terhubung dari perspektif klien. Verifikasi terlebih dahulu dan periksa nama host yang mendasari untuk masing-masing node ini. Untuk memeriksa, Anda dapat menjalankan perintah bash di bawah ini dan cukup ganti nama host/nama titik akhir yang sesuai:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Hasilnya menjelaskan sebagai berikut,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Mensimulasikan Kegagalan Amazon RDS
Sekarang, mari simulasikan crash untuk mensimulasikan failover untuk instans penulis Amazon RDS Aurora, yaitu s9s-db-aurora-instance-1 dengan titik akhir s9s-db-aurora.cluster-cmu8qdlvkepg.us -timur-2.rds.amazonaws.com.
Untuk melakukannya, sambungkan ke instance penulis Anda menggunakan prompt perintah klien mysql dan kemudian jalankan sintaks di bawah ini:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Menerbitkan perintah ini memiliki deteksi pemulihan Amazon RDS dan bertindak cukup cepat. Meskipun kueri untuk tujuan pengujian, kueri mungkin berbeda ketika kejadian ini terjadi dalam peristiwa faktual. Anda mungkin tertarik untuk mengetahui lebih banyak tentang pengujian instance crash dalam dokumentasi mereka. Lihat bagaimana kita berakhir di bawah ini:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Menjalankan perintah SQL di atas berarti harus mensimulasikan kegagalan disk setidaknya selama 3 menit. Saya memantau titik waktu untuk memulai simulasi dan butuh sekitar 18 detik sebelum failover dimulai.
Lihat di bawah tentang bagaimana RDS menangani kegagalan simulasi dan kegagalan,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Hasil simulasi ini cukup menarik. Mari kita ambil ini satu per satu.
- Sekitar 10:06:29, saya mulai menjalankan kueri simulasi seperti yang disebutkan di atas.
- Sekitar 10:06:44, ini menunjukkan bahwa titik akhir s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com dengan nama host yang ditetapkan ip-10-20-1- 139 di mana sebenarnya itu adalah instance read-only, tidak dapat diakses namun perintah simulasi dijalankan di bawah instance read-write.
- Sekitar 10:06:51, itu menunjukkan bahwa titik akhir s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com dengan nama host yang ditetapkan ip-10-20-1- 139 naik tetapi memiliki tanda sebagai status baca-tulis. Perhatikan bahwa variabel innodb_read_only, untuk instans yang dikelola MySQL Aurora, ini adalah pengenalnya untuk menentukan apakah host adalah node baca-tulis atau baca-saja dan Aurora juga hanya berjalan pada mesin penyimpanan InnoDB untuk instans yang kompatibel dengan MySQL.
- Sekitar 10:07:13, urutannya berubah. Ini berarti bahwa failover telah dilakukan dan instance telah ditetapkan ke titik akhir yang ditentukan.
Lihat hasil di bawah yang ditampilkan di konsol RDS:
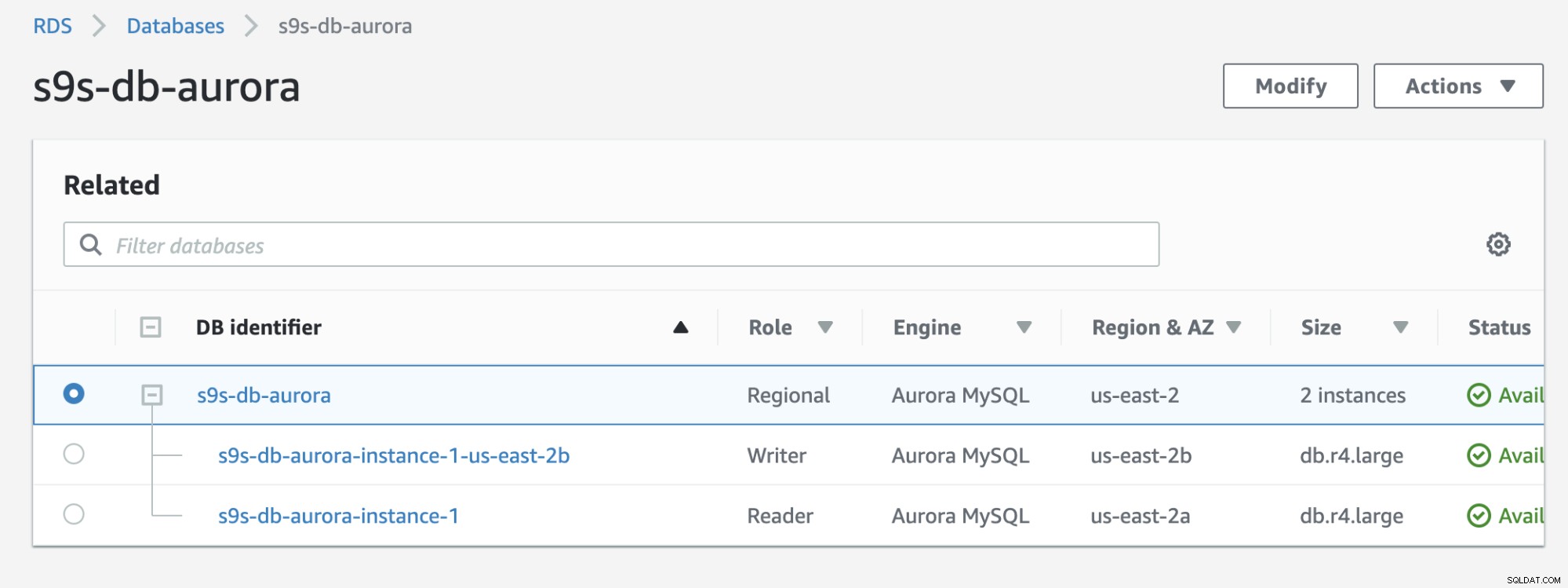
Jika dibandingkan dengan yang sebelumnya, s9s-db-aurora- instance-1 adalah seorang pembaca, tetapi kemudian dipromosikan sebagai penulis setelah failover. Proses termasuk pengujian membutuhkan waktu sekitar 44 detik untuk menyelesaikan tugas, tetapi kegagalan menunjukkan selesai hampir 30 detik. Itu mengesankan dan cepat untuk failover, terutama mengingat ini adalah database layanan terkelola; artinya Anda tidak perlu khawatir tentang masalah perangkat keras atau pemeliharaan.
Melakukan Failback di Amazon RDS
Failback di Amazon RDS cukup sederhana. Sebelum membahasnya, mari tambahkan replika pembaca baru. Kami memerlukan opsi untuk menguji dan mengidentifikasi node apa yang akan dipilih AWS RDS saat mencoba melakukan failback ke master yang diinginkan (atau failback ke master sebelumnya) dan untuk melihat apakah node yang tepat dipilih berdasarkan prioritas. Daftar instance saat ini dan titik akhirnya ditunjukkan di bawah ini.
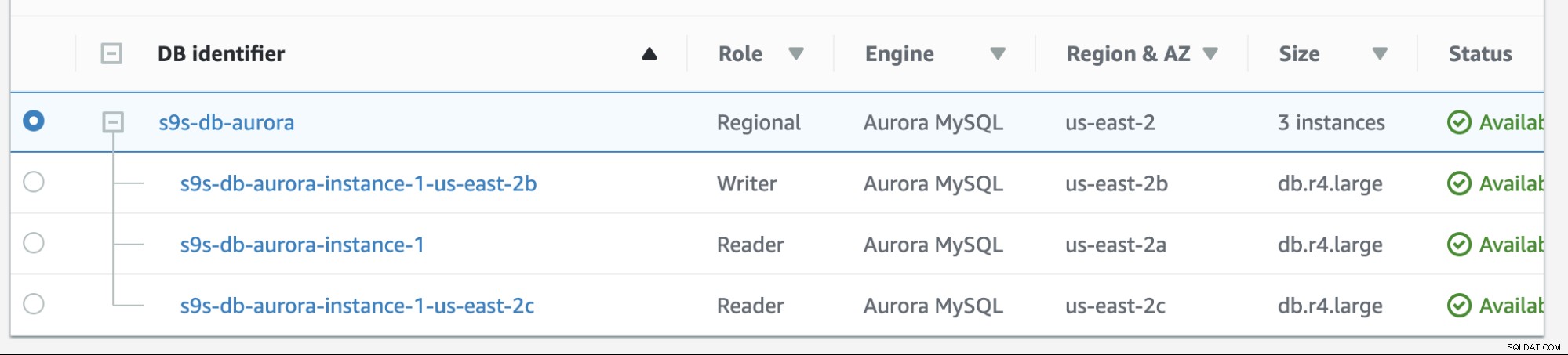

Replika baru terletak di us-east-2c AZ dengan nama host db dari ip-10-20-2-239.
Kami akan mencoba melakukan failback menggunakan instance s9s-db-aurora-instance-1 sebagai target failback yang diinginkan. Dalam pengaturan ini kami memiliki dua contoh pembaca. Untuk memastikan bahwa node yang benar diambil selama failover, Anda perlu menetapkan apakah prioritas atau ketersediaan ada di atas (tier-0> tier-1> tier-2 dan seterusnya hingga tier-15). Ini dapat dilakukan dengan memodifikasi instance atau selama pembuatan replika.
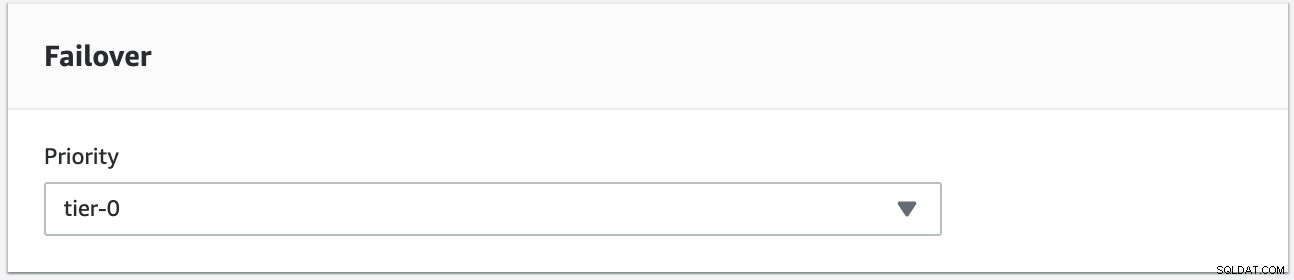
Anda dapat memverifikasi ini di konsol RDS Anda.
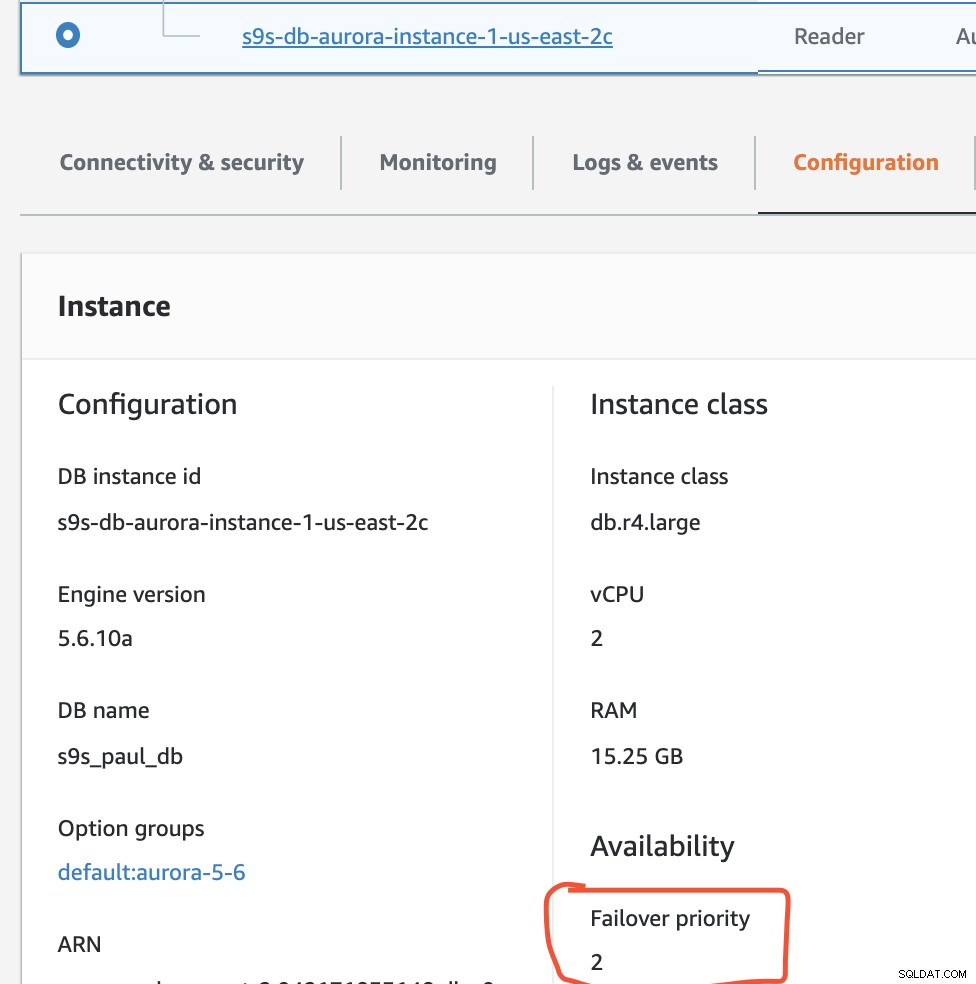
Dalam pengaturan ini s9s-db-aurora-instance-1 memiliki prioritas =0 (dan merupakan replika baca), s9s-db-aurora-instance-1-us-east-2b memiliki prioritas =1 (dan merupakan penulis saat ini), dan s9s-db-aurora-instance-1-us- east-2c memiliki prioritas =2 (dan juga merupakan replika baca). Mari kita lihat apa yang terjadi ketika kita mencoba melakukan failback.
Anda dapat memantau status dengan menggunakan perintah ini.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Setelah failover dipicu, itu akan failback ke target yang kita inginkan, yaitu node s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Upaya failback dimulai pada 13:30:59 dan selesai sekitar 13:31:38 (tanda 30 detik terdekat). Itu berakhir ~ 32 detik pada tes ini, yang masih cepat.
Saya telah memverifikasi failover/failback beberapa kali dan secara konsisten menukar status baca-tulisnya antara instance s9s-db-aurora-instance-1 dan s9s-db-aurora-instance-1- kami-timur-2b. Ini membuat s9s-db-aurora-instance-1-us-east-2c dibiarkan tidak dipilih kecuali kedua node mengalami masalah (yang sangat jarang karena semuanya terletak di AZ yang berbeda).
Selama upaya failover/failback, RDS berjalan dengan kecepatan transisi yang cepat selama failover sekitar 15 - 25 detik (yang sangat cepat). Perlu diingat, kami tidak memiliki file data besar yang disimpan pada instance ini, tetapi masih cukup mengesankan mengingat tidak ada lagi yang harus dikelola.
Kesimpulan
Menjalankan Single-AZ menimbulkan bahaya saat melakukan failover. Amazon RDS memungkinkan Anda untuk memodifikasi dan mengonversi Single-AZ Anda ke pengaturan yang mendukung Multi-AZ, meskipun ini akan menambah beberapa biaya untuk Anda. Single-AZ mungkin baik-baik saja jika Anda setuju dengan waktu RTO dan RPO yang lebih tinggi, tetapi jelas tidak direkomendasikan untuk aplikasi bisnis dengan lalu lintas tinggi, kritis, dan bisnis.
Dengan Multi-AZ, Anda dapat mengotomatiskan failover dan failback di Amazon RDS, menghabiskan waktu Anda berfokus pada penyetelan atau pengoptimalan kueri. Ini memudahkan banyak masalah yang dihadapi oleh DevOps atau DBA.
Meskipun Amazon RDS dapat menyebabkan dilema di beberapa organisasi (karena ini bukan agnostik platform), ini tetap layak untuk dipertimbangkan; terutama jika aplikasi Anda memerlukan paket DR jangka panjang dan Anda tidak ingin menghabiskan waktu untuk mengkhawatirkan perangkat keras dan perencanaan kapasitas.