Ada banyak penyedia cloud saat ini. Mereka bisa kecil atau besar, lokal atau dengan pusat data yang tersebar di seluruh dunia. Banyak dari penyedia cloud ini menawarkan semacam solusi database relasional terkelola. Basis data yang didukung cenderung MySQL atau PostgreSQL atau beberapa jenis basis data relasional lainnya.
Saat merancang segala jenis infrastruktur basis data, penting untuk memahami kebutuhan bisnis Anda dan memutuskan jenis ketersediaan yang perlu Anda capai.
Dalam entri blog ini, kita akan melihat opsi ketersediaan tinggi untuk solusi berbasis MySQL dari salah satu penyedia cloud terbesar - Google Cloud Platform.
Men-deploy Lingkungan yang Sangat Tersedia Menggunakan Instance SQL GCP
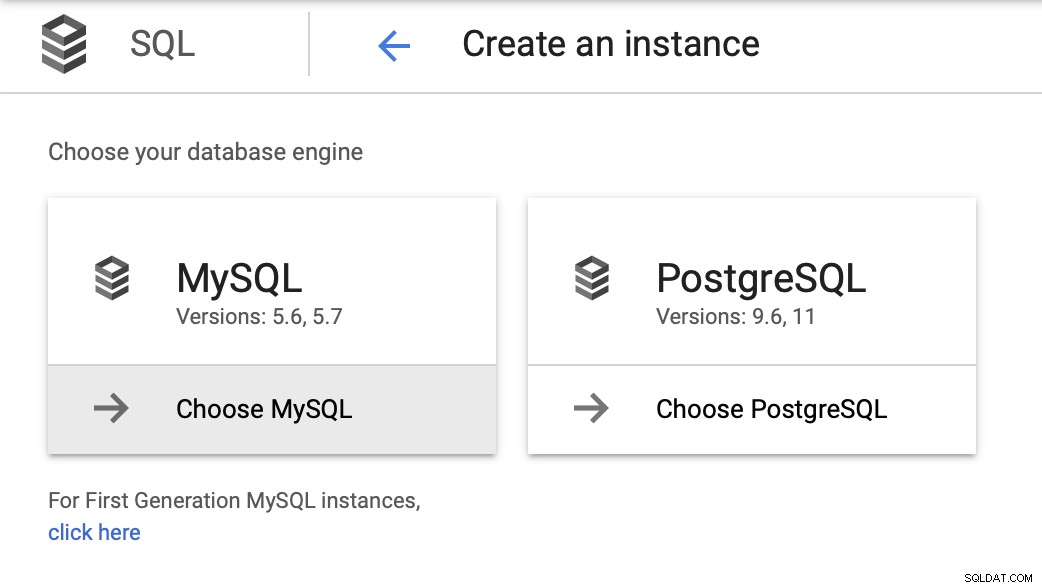
Untuk blog ini kami menginginkan lingkungan yang sangat sederhana - satu database, dengan mungkin satu atau dua replika. Kami ingin dapat melakukan failover dengan mudah dan memulihkan operasi sesegera mungkin jika master gagal. Kami akan menggunakan MySQL 5.7 sebagai versi pilihan dan mulai dengan wizard penerapan instance:
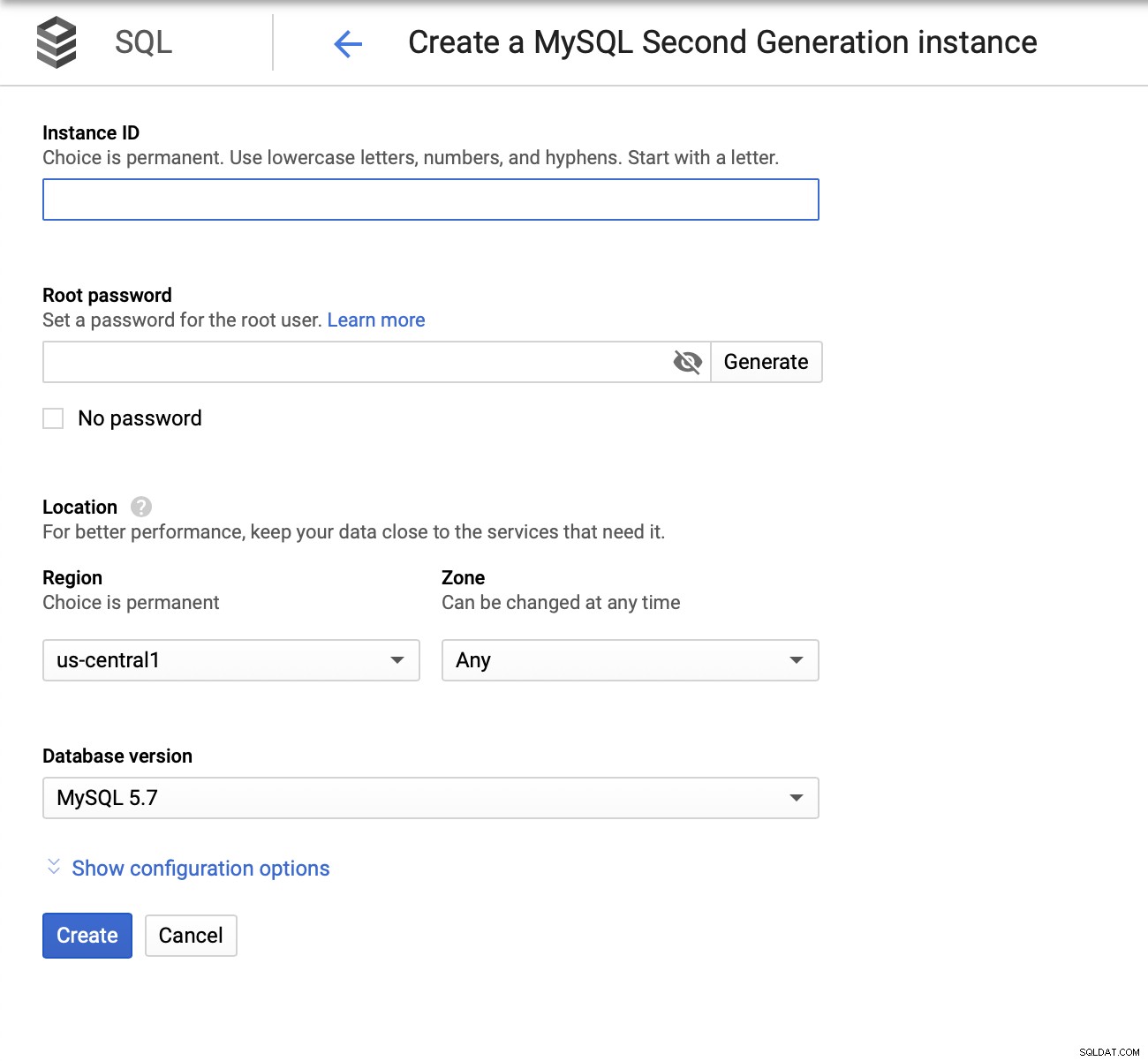
Kemudian kita harus membuat kata sandi root, menetapkan nama instance, dan tentukan di mana lokasinya:
Selanjutnya, kita akan melihat opsi konfigurasi:
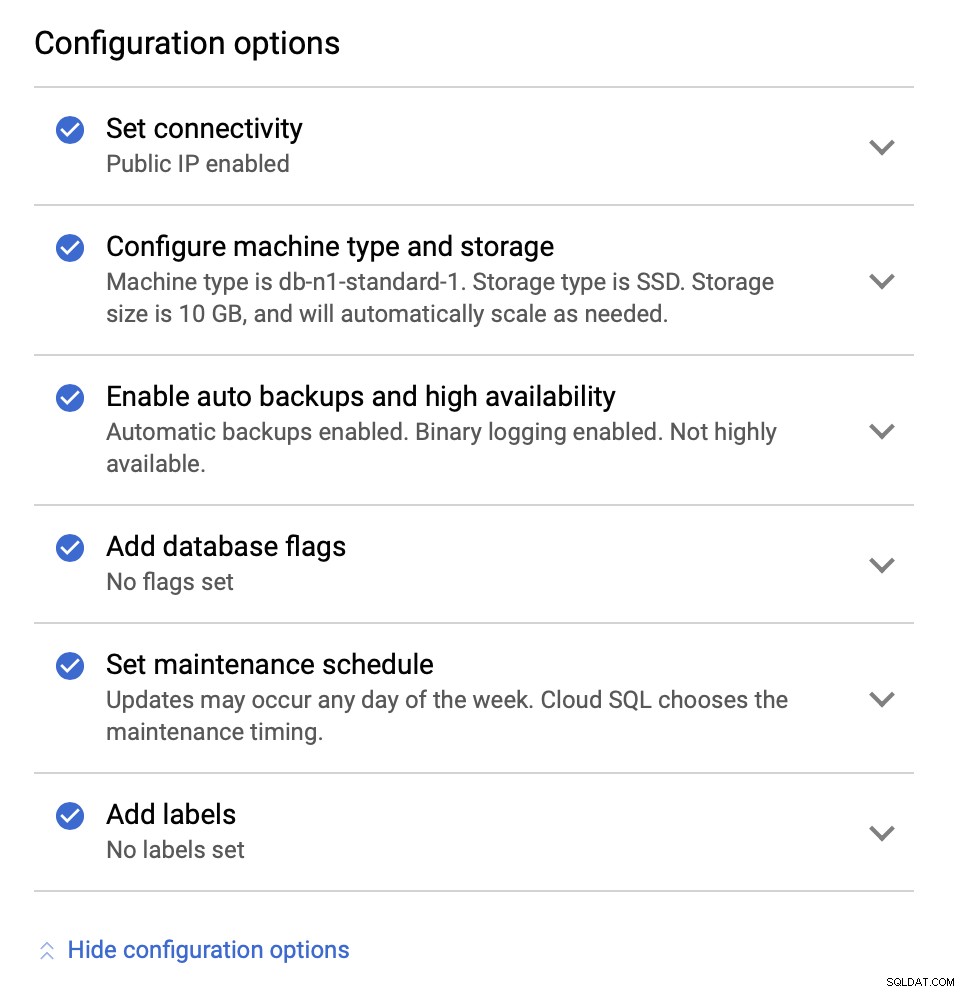
Kita dapat membuat perubahan dalam hal ukuran instance (kita akan menggunakan db-n1-standard-4), penyimpanan, dan jadwal pemeliharaan. Yang terpenting bagi kami dalam penyiapan ini adalah opsi ketersediaan tinggi:
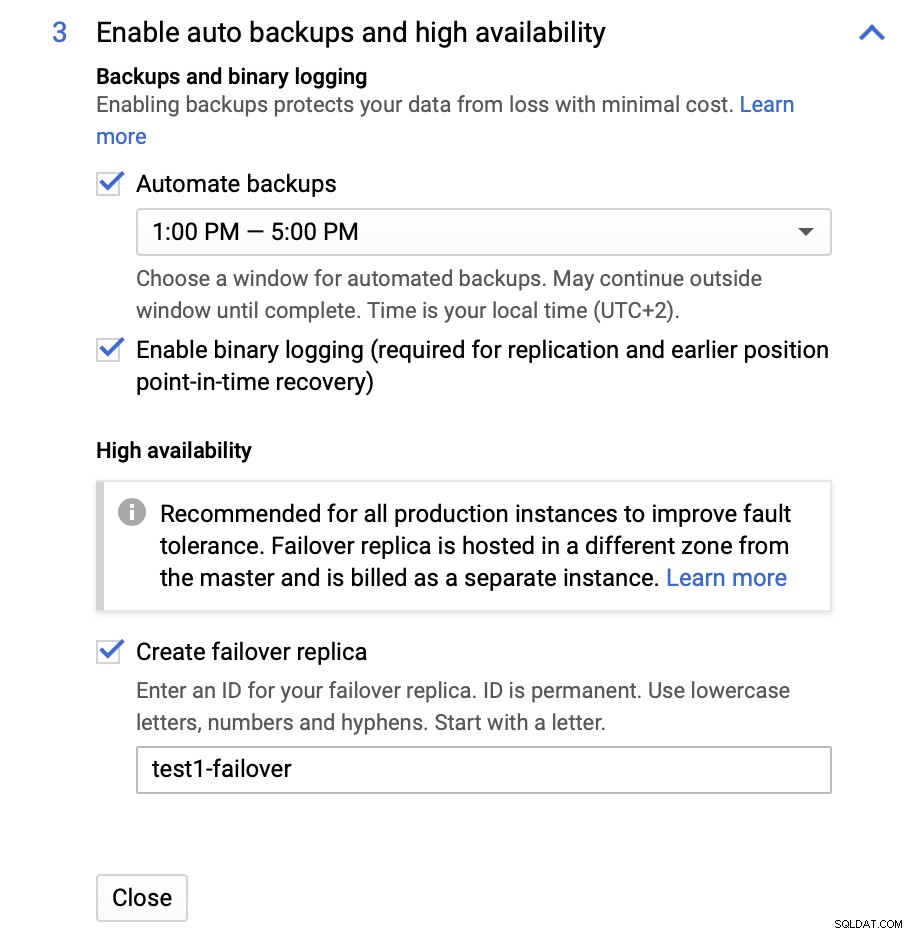
Di sini kita dapat memilih untuk membuat replika failover. Replika ini akan dipromosikan menjadi master jika master aslinya gagal.

Setelah kita men-deploy setup, mari tambahkan replikasi slave:
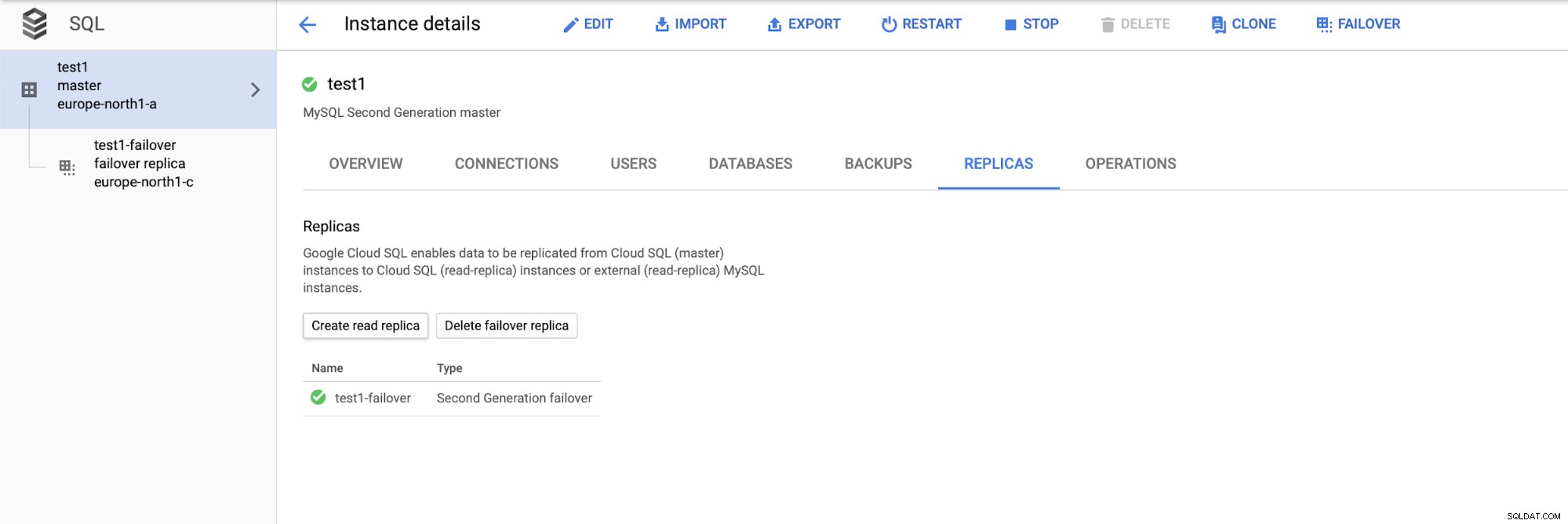
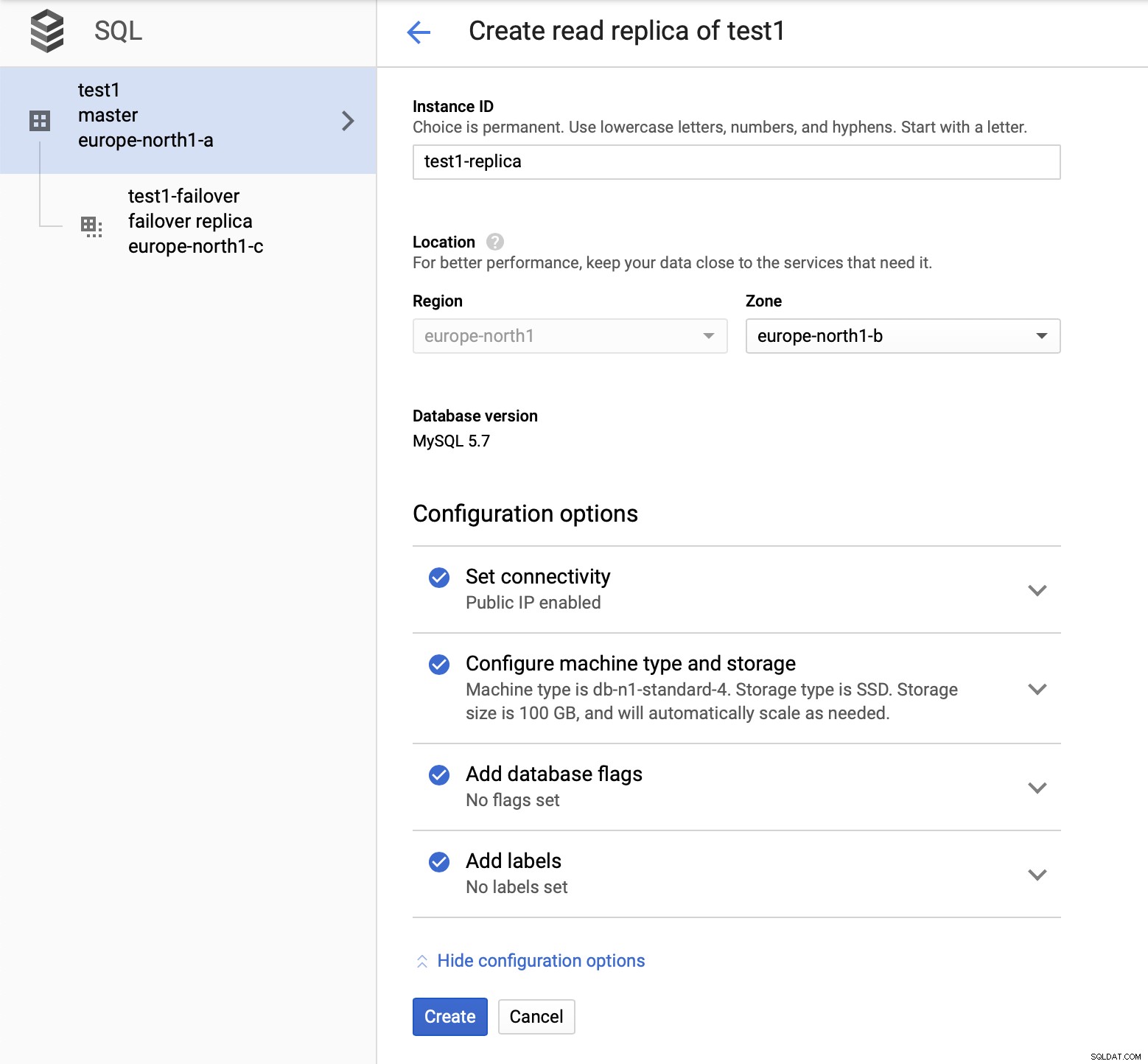
Setelah proses penambahan replika selesai, kami siap untuk beberapa tes. Kami akan menjalankan beban kerja pengujian menggunakan Sysbench pada master kami, replika failover, dan replika baca untuk melihat bagaimana ini akan berhasil. Kami akan menjalankan tiga contoh Sysbench, menggunakan titik akhir untuk ketiga jenis node.
Kemudian kita akan memicu failover manual melalui UI:
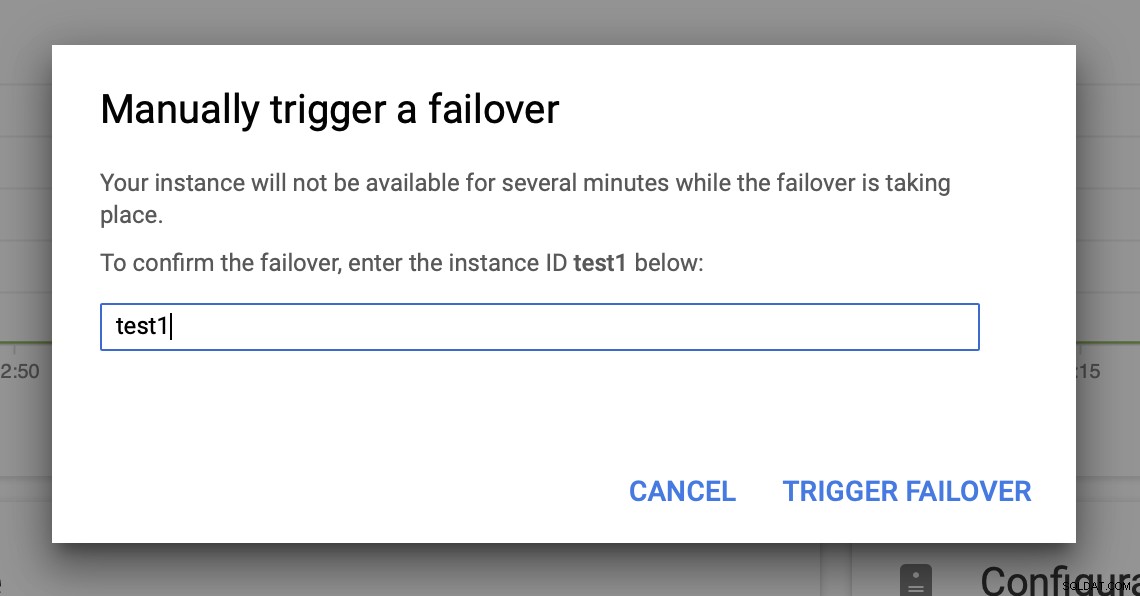
Menguji Kegagalan MySQL di Google Cloud Platform?
Saya sampai pada titik ini tanpa pengetahuan mendetail tentang cara kerja node SQL di GCP. Namun, saya memiliki beberapa harapan, berdasarkan pengalaman MySQL sebelumnya dan apa yang saya lihat di penyedia cloud lainnya. Sebagai permulaan, failover ke node failover harus sangat cepat. Yang kami inginkan adalah menjaga agar slave replikasi tetap tersedia, tanpa perlu membangun kembali. Kami juga ingin melihat seberapa cepat kami dapat mengeksekusi failover untuk kedua kalinya (karena tidak jarang masalah menyebar dari satu database ke database lain).
Apa yang kami tentukan selama pengujian kami...
- Saat gagal, master tersedia kembali dalam 75 - 80 detik.
- Replika failover tidak tersedia selama 5-6 menit.
- Replika baca tersedia selama proses failover, tetapi menjadi tidak tersedia selama 55 - 60 detik setelah replika failover tersedia
Apa yang kami tidak yakin tentang...
Apa yang terjadi jika replika failover tidak tersedia? Berdasarkan waktu, sepertinya replika failover sedang dibangun kembali. Ini masuk akal, tetapi kemudian waktu pemulihan akan sangat terkait dengan ukuran instans (terutama kinerja I/O) dan ukuran file data.
Apa yang terjadi dengan replika baca setelah replika failover dibangun kembali? Awalnya, replika baca terhubung ke master. Saat master gagal, kami berharap replika baca memberikan tampilan dataset yang sudah ketinggalan zaman. Setelah master baru muncul, itu harus terhubung kembali melalui replikasi ke instance (yang dulunya adalah replika failover dan yang telah dipromosikan menjadi master). Tidak perlu satu menit waktu henti saat CHANGE MASTER sedang dijalankan.
Lebih penting lagi, selama proses failover tidak ada cara untuk mengeksekusi failover lain (yang masuk akal):
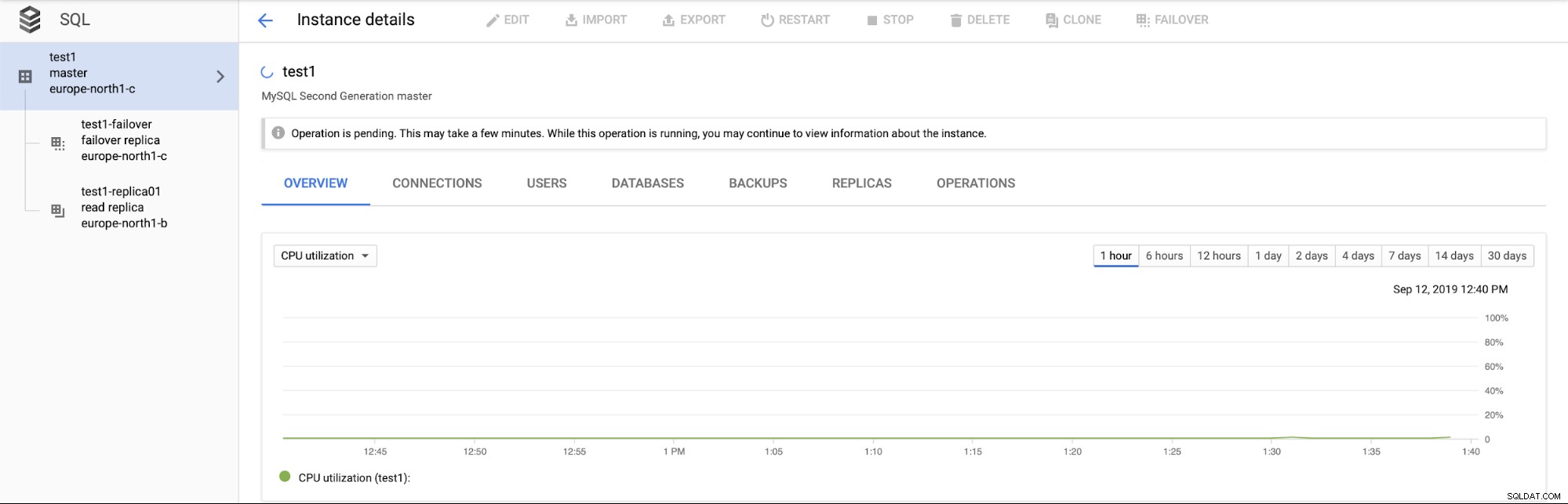
Juga tidak mungkin untuk mempromosikan replika baca (yang belum tentu masuk akal - kami berharap dapat mempromosikan replika baca kapan saja).

Penting untuk diperhatikan, mengandalkan replika baca untuk menyediakan ketersediaan tinggi (tanpa membuat replika failover) bukanlah solusi yang layak. Anda dapat mempromosikan replika baca untuk menjadi master, namun cluster baru akan dibuat; terlepas dari node lainnya.
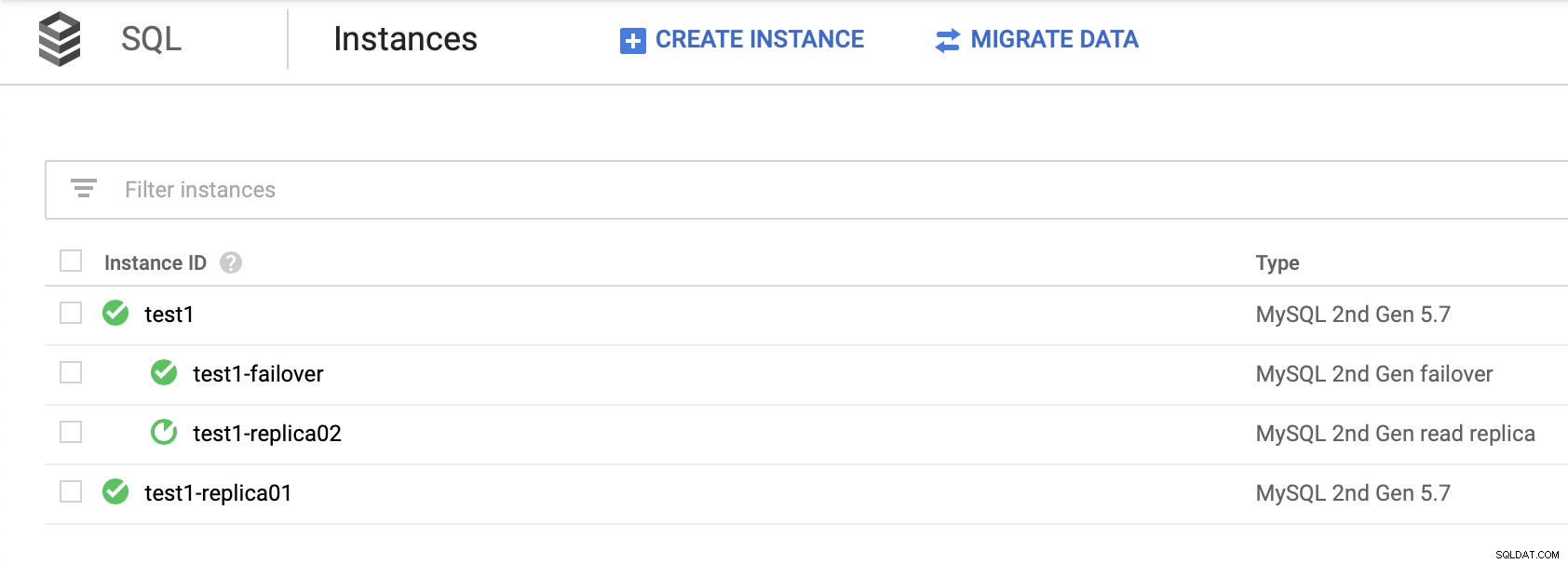
Tidak ada cara untuk membuang replika Anda yang lain dari cluster baru. Satu-satunya cara untuk melakukannya adalah dengan membuat replika baru, tetapi ini adalah proses yang memakan waktu. Ini juga hampir tidak dapat digunakan, menjadikan replika failover menjadi satu-satunya opsi nyata untuk ketersediaan tinggi untuk node SQL di Google Cloud Platform.
Kesimpulan
Meskipun dimungkinkan untuk membuat lingkungan yang sangat tersedia untuk node SQL di GCP, master tidak akan tersedia selama kira-kira satu setengah menit. Seluruh proses (termasuk membangun kembali replika failover dan beberapa tindakan pada replika baca) memakan waktu beberapa menit. Selama waktu itu, kami tidak dapat memicu failover tambahan, kami juga tidak dapat mempromosikan replika baca.
Apakah kami memiliki pengguna GCP di luar sana? Bagaimana Anda mencapai ketersediaan tinggi?