Ada bug regresi di SQL Server 2012 dan SQL Server 2014 di mana, jika Anda membangun kembali indeks online secara paralel, dan Anda juga mengalami kesalahan fatal seperti waktu tunggu kunci, Anda bisa mengalami kehilangan atau kerusakan data . Ini seharusnya menjadi skenario yang relatif jarang (Phil Brammer memiliki repro sederhana di Connect #795134), tetapi kehilangan data adalah kehilangan data, dan saya tidak siap untuk bertaruh. Perbaikan dijelaskan di KB #2969896 :MEMPERBAIKI:Kehilangan data dalam indeks berkerumun terjadi saat Anda menjalankan indeks pembuatan online di SQL Server 2012.
Tidak semua orang perlu khawatir tentang masalah ini. Jika Anda tidak menjalankan Edisi Enterprise (atau yang setara), Anda tidak dapat melakukan pembangunan kembali paralel atau online di tempat pertama (dan mungkin ada beberapa orang di Perusahaan yang tidak membangun kembali atau tidak membangun kembali secara online). Jika Anda memiliki MAXDOP di seluruh instance set ke 1, mereka tidak bisa paralel kecuali Anda menimpanya di tingkat pernyataan. Namun, jika Anda menggunakan edisi 2012 atau 2014, menjalankan edisi yang memadai, dan pembuatan ulang online Anda dapat berjalan paralel, Anda rentan terhadap masalah ini.
Seperti yang saya singgung di atas, masalah ini dapat bermanifestasi dalam SQL Server 2012 RTM, Service Pack 1, dan bahkan Service Pack 2, yang dirilis pada 10 Juni. Bug tersebut tidak diperbaiki sampai lama setelah kode SP2 dibekukan, jadi SP2 tidak. tidak termasuk perbaikan ini atau perbaikan apa pun dari SP1 CU #10 atau #11. Saya membuat blog tentang ini di sini. Cabang RTM secara resmi tidak mendukung, jadi Anda tidak akan melihat perbaikan di sana. Masalah ini juga dapat terjadi di SQL Server 2014.
Sekarang ada pembaruan kumulatif yang tersedia untuk SQL Server 2012 Service Pack 1 &2 serta SQL Server 2014. Ringkasan singkat dari opsi yang saya sarankan:
Jika cabang Anda / @@VERSION adalah…
| …kau harus… | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Tidak melakukan apa-apa; Anda sudah memiliki perbaikannya. | |||||
| |||||
| Tidak melakukan apa-apa; Anda sudah memiliki perbaikannya. | |||||
| SQL Server 2014 RTM |
| ||||
| Tidak melakukan apa-apa; Anda sudah memiliki perbaikannya. | |||||
| * Jika Anda menginstal perbaikan terbaru SP1 atau Pembaruan Kumulatif #11 dan kemudian menginstal SP2, Anda akan membatalkan perubahan tersebut, termasuk perbaikan ini. | |||||
Solusi untuk hotfix/CU penolakan
Karena semua cabang yang terpengaruh (well, kecuali 2012 RTM) memiliki hotfix sesuai permintaan dan/atau pembaruan kumulatif yang mengatasi masalah tersebut, jawaban mudahnya adalah dengan menginstal pembaruan yang relevan. Namun, Anda mungkin berada dalam skenario di mana kebijakan perusahaan atau siklus pengujian mencegah Anda menyebarkan pembaruan ini dengan cepat, atau mungkin selamanya. Jadi apa pilihan lain yang Anda miliki?
- Anda dapat berhenti melakukan pembangunan kembali sampai ada paket layanan baru yang tersedia untuk cabang Anda (mungkin Anda dapat tetap menggunakan
REORGANIZEuntuk sekarang). Sayangnya, jika Anda berada di perusahaan "hanya paket layanan", pilihan Anda sangat terbatas:Anda dapat berjuang lebih keras untuk mengubah kebijakan itu, atau Anda dapat menunggu SQL Server 2012 Service Pack 3 (yang mungkin lama, atau mungkin tidak pernah datang – lihat FAQ #21 di sini) atau SQL Server 2014 Service Pack 1 (yang mungkin tidak akan kita lihat sebelum 2015 bergulir). - Anda dapat mengatur
max degree of parallelismdi seluruh instance ke 1, namun ini mungkin memiliki efek negatif pada sisa beban kerja Anda – pikirkan hal-hal seperti DBCC multi-utas, kueri paralel terhadap atau di antara tabel yang dipartisi, dan operasi lain di mana Anda mungkin ingin mengurangi paralelisme tetapi tidak menghilangkannya sama sekali. Selain itu, setelan ini tidak akan memengaruhi pembuatan ulang online dengan, katakanlah,MAXDOP = 8eksplisit hard-code ke dalam perintah, karena ini akan menimpasp_configurepengaturan.
- Anda dapat menambahkan
WITH (MAXDOP = 1)opsi secara manual ke semua perintah pembangunan kembali Anda. (Catatan:Anda tidak perlu melakukan ini untuk indeks XML, karena indeks tersebut secara inheren menjalankan single-threaded, tetapi saya hanya akan menerapkannya ke semua pembangunan ulang untuk konsistensi dan untuk menghindari logika kondisional yang tidak perlu.)
- Anda dapat menyetel tugas pemeliharaan indeks untuk dijalankan sebagai login tertentu, lalu menggunakan Resource Governor untuk membuat Grup Beban Kerja yang membatasi
MAX_DOPlogin tersebut ke 1, terlepas dari apa yang mereka lakukan. Saya memiliki contohnya dalam buku putih 2008 yang saya tulis bersama Boris Baryshnikov, Using the Resource Governor, di bagian berjudul, "Membatasi Paralelisme untuk Pekerjaan Latar Belakang Intensif."
- Jika Anda menggunakan solusi pemeliharaan indeks Ola Hallengren, Anda dapat menambahkan
@MaxDopparameter untuk panggilan Anda kedbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Jika Anda menggunakan SQL Sentry Fragmentation Manager, Anda dapat menentukan level
MAXDOPuntuk digunakan di bawah Pengaturan – dan Anda dapat melakukan ini di seluruh perusahaan, per instans, per database, atau bahkan per indeks individu (dalam hal ini, Anda mungkin ingin mengatur ini per instans, untuk semua instans tanpa perbaikan yang tersedia):
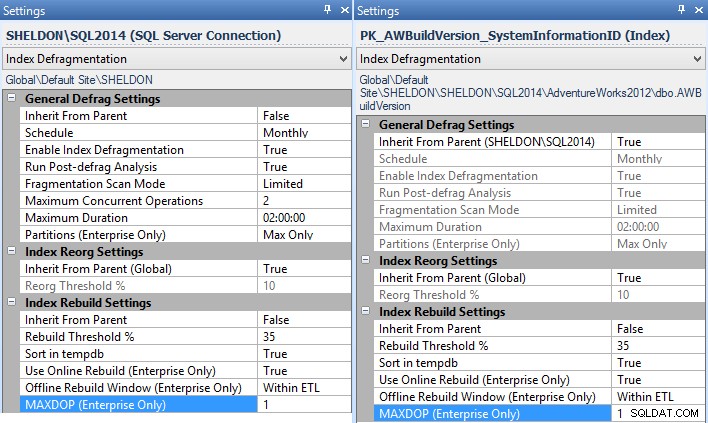
Pengaturan Pengelola Fragmentasi untuk instans (kiri) dan indeks individual (kanan). - Jika Anda menggunakan Rencana Pemeliharaan untuk pembangunan kembali indeks, Anda harus mengubahnya untuk menggunakan Tugas Pernyataan T-SQL Jalankan, dan tulis
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);perintah secara manual (sebaiknya beralih ke solusi otomatis). Lihat, Tugas Pembuatan Ulang Indeks tidak memiliki properti terbuka untukMAXDOP, meskipun telah diminta beberapa kali (terakhir pada tahun 2012, oleh Alberto Morillo, dan sejauh tahun 2006, oleh Linchi Shea). Dan lihat saja semua properti berguna lainnya yang diekspos, sepertiAdvSortInTempdb,ObjectTypeSelection, danTaskAllowesDatbaseSelection[sic!]:
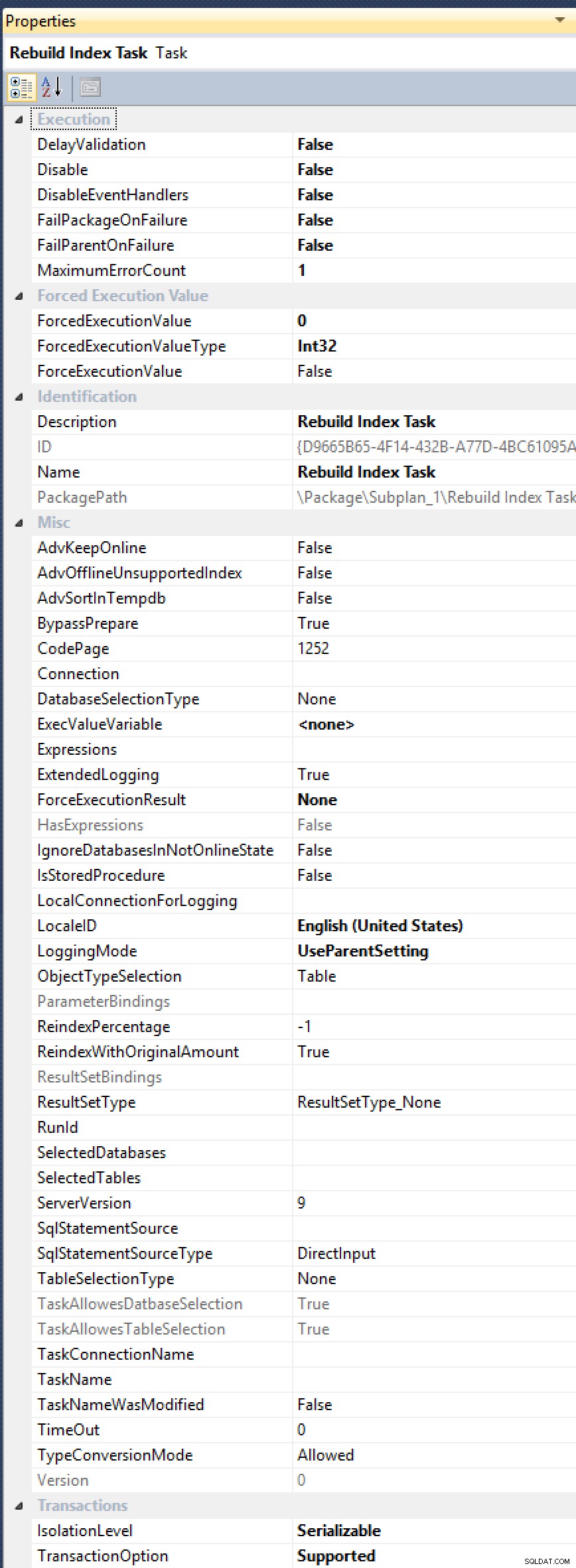
Semua opsi itu, tetapi masih belum ada obat untuk MAXDOP.