Ketahanan Tertunda adalah fitur terbaru tetapi menarik di SQL Server 2014; nada elevator tingkat tinggi dari fitur ini, cukup sederhana:
- "Perdagangkan ketahanan untuk kinerja."
Beberapa latar belakang pertama. Secara default, SQL Server menggunakan write-ahead log (WAL), yang berarti bahwa perubahan ditulis ke log sebelum diizinkan untuk dilakukan. Dalam sistem di mana penulisan log transaksi menjadi hambatan, dan di mana ada toleransi moderat untuk kehilangan data , Anda sekarang memiliki opsi untuk menangguhkan sementara persyaratan untuk menunggu log flush dan pengakuan. Ini terjadi secara harfiah menghilangkan D dari ACID, setidaknya untuk sebagian kecil data (lebih lanjut tentang ini nanti).
Anda agak sudah membuat pengorbanan ini sekarang. Dalam mode pemulihan penuh, selalu ada beberapa risiko kehilangan data, itu hanya diukur dari segi waktu daripada ukuran. Misalnya, jika Anda mencadangkan log transaksi setiap lima menit, Anda dapat kehilangan data hingga kurang dari 5 menit jika terjadi bencana. Saya tidak berbicara tentang failover sederhana di sini, tetapi katakanlah server benar-benar terbakar atau seseorang tersandung kabel daya – database mungkin tidak dapat dipulihkan dan Anda mungkin harus kembali ke titik waktu pencadangan log terakhir . Dan itu dengan asumsi Anda bahkan menguji cadangan Anda dengan memulihkannya di suatu tempat – jika terjadi kegagalan kritis, Anda mungkin tidak memiliki titik pemulihan yang Anda pikir Anda miliki. Kami cenderung tidak memikirkan skenario ini, tentu saja, karena kami tidak pernah mengharapkan hal buruk™ terjadi.
Cara kerjanya
Ketahanan yang tertunda memungkinkan transaksi tulis untuk terus berjalan seolah-olah log telah di-flush ke disk; pada kenyataannya, penulisan ke disk telah dikelompokkan dan ditangguhkan, untuk ditangani di latar belakang. Transaksinya optimis; itu mengasumsikan bahwa log flush akan terjadi. Sistem menggunakan potongan buffer log sebesar 60KB, dan mencoba mem-flush log ke disk saat blok 60KB ini penuh (paling lambat – hal ini dapat dan sering akan terjadi sebelum itu). Anda dapat mengatur opsi ini di tingkat database, di tingkat transaksi individual, atau – dalam kasus prosedur yang dikompilasi secara asli di OLTP Dalam Memori – di tingkat prosedur. Pengaturan database menang dalam kasus konflik; misalnya, jika database disetel ke dinonaktifkan, mencoba melakukan transaksi menggunakan opsi tunda akan diabaikan begitu saja, tanpa pesan kesalahan. Juga, beberapa transaksi selalu sepenuhnya tahan lama, terlepas dari pengaturan basis data atau pengaturan komit; misalnya, transaksi sistem, transaksi lintas basis data, dan operasi yang melibatkan FileTable, Change Tracking, Change Data Capture, dan Replication.
Pada tingkat basis data, Anda dapat menggunakan:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Jika Anda menyetelnya ke ALLOWED , ini berarti bahwa setiap transaksi individu dapat menggunakan Ketahanan Tertunda; FORCED artinya semua transaksi yang dapat menggunakan Delayed Durability akan (pengecualian di atas masih relevan dalam kasus ini). Anda mungkin ingin menggunakan ALLOWED daripada FORCED – tetapi yang terakhir dapat berguna dalam kasus aplikasi yang ada di mana Anda ingin menggunakan opsi ini secara keseluruhan dan juga meminimalkan jumlah kode yang harus disentuh. Hal penting yang perlu diperhatikan tentang ALLOWED adalah bahwa transaksi yang tahan lama sepenuhnya mungkin harus menunggu lebih lama, karena transaksi tahan lama akan dipaksakan terlebih dahulu.
Pada tingkat transaksi, Anda dapat mengatakan:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Dan dalam prosedur yang dikompilasi secara native OLTP Dalam Memori, Anda dapat menambahkan opsi berikut ke BEGIN ATOMIC blok:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Pertanyaan umum adalah seputar apa yang terjadi dengan penguncian dan isolasi semantik. Tidak ada yang berubah, sungguh. Penguncian dan pemblokiran masih terjadi, dan transaksi dilakukan dengan cara dan aturan yang sama. Satu-satunya perbedaan adalah, dengan membiarkan komit terjadi tanpa menunggu log mengalir ke disk, semua kunci terkait akan dilepaskan lebih cepat.
Kapan Anda Harus Menggunakannya
Selain manfaat yang Anda dapatkan dari mengizinkan transaksi untuk dilanjutkan tanpa menunggu penulisan log terjadi, Anda juga mendapatkan lebih sedikit penulisan log dengan ukuran yang lebih besar. Ini dapat bekerja dengan sangat baik jika sistem Anda memiliki proporsi transaksi tinggi yang sebenarnya lebih kecil dari 60KB, dan terutama ketika disk log lambat (walaupun saya menemukan manfaat serupa pada SSD dan HDD tradisional). Ini tidak berjalan dengan baik jika transaksi Anda, sebagian besar, lebih besar dari 60KB, jika biasanya berjalan lama, atau jika Anda memiliki throughput tinggi dan konkurensi tinggi. Apa yang dapat terjadi di sini adalah Anda dapat mengisi seluruh buffer log sebelum flush selesai, yang berarti mentransfer waktu tunggu Anda ke sumber daya yang berbeda dan, pada akhirnya, tidak meningkatkan kinerja yang dirasakan oleh pengguna aplikasi.
Dengan kata lain, jika log transaksi Anda saat ini tidak menjadi hambatan, jangan aktifkan fitur ini. Bagaimana Anda bisa tahu jika log transaksi Anda saat ini menjadi hambatan? Indikator pertama adalah WRITELOG tinggi menunggu, terutama jika digabungkan dengan PAGEIOLATCH_** . Paul Randal (@PaulRandal) memiliki rangkaian empat bagian yang hebat dalam mengidentifikasi masalah log transaksi, serta mengonfigurasi untuk kinerja yang optimal:
- Memotong Lemak Log Transaksi
- Memotong Lebih Banyak Lemak Log Transaksi
- Masalah Konfigurasi Log Transaksi
- Pemantauan Log Transaksi
Lihat juga posting blog ini dari Kimberly Tripp (@KimberlyLTripp), 8 Langkah untuk Throughput Log Transaksi yang Lebih Baik, dan posting blog tim SQL CAT, Mendiagnosis Masalah Kinerja Log Transaksi dan Batas Manajer Log.
Penyelidikan ini dapat membawa Anda pada kesimpulan bahwa Ketahanan Tertunda layak untuk dilihat; mungkin tidak. Menguji beban kerja Anda akan menjadi cara paling andal untuk mengetahui dengan pasti. Seperti banyak tambahan lain di versi terbaru SQL Server (*cough* Hekaton ), fitur ini TIDAK dirancang untuk meningkatkan setiap beban kerja – dan seperti disebutkan di atas, fitur ini sebenarnya dapat memperburuk beberapa beban kerja. Lihat posting blog ini oleh Simon Harvey untuk beberapa pertanyaan lain yang harus Anda tanyakan pada diri sendiri tentang beban kerja Anda untuk menentukan apakah layak untuk mengorbankan beberapa daya tahan untuk mencapai kinerja yang lebih baik.
Berpotensi kehilangan data
Saya akan menyebutkan ini beberapa kali, dan menambahkan penekanan setiap kali saya melakukannya:Anda harus toleran terhadap kehilangan data . Di bawah disk yang berkinerja baik, jumlah maksimum yang Anda harapkan untuk hilang dalam bencana – atau bahkan shutdown yang terencana dan anggun – adalah hingga satu blok penuh (60KB). Namun, dalam kasus di mana subsistem I/O Anda tidak dapat mengikuti, ada kemungkinan bahwa Anda bisa kehilangan sebanyak buffer log (~7MB).
Untuk memperjelas, dari dokumentasi (penekanan milik saya):
Untuk ketahanan yang tertunda, tidak ada perbedaan antara shutdown yang tidak terduga dan shutdown/restart SQL Server yang diharapkan . Seperti peristiwa bencana, Anda harus merencanakan kehilangan data . Dalam shutdown/restart yang direncanakan, beberapa transaksi yang belum ditulis ke disk mungkin pertama kali disimpan ke disk, tetapi Anda tidak boleh merencanakannya. Rencanakan seolah-olah shutdown/restart, baik direncanakan atau tidak direncanakan, kehilangan data yang sama seperti peristiwa bencana.Jadi, sangat penting bagi Anda untuk menimbang risiko kehilangan data dengan kebutuhan Anda untuk mengurangi masalah kinerja log transaksi. Jika Anda menjalankan bank atau apa pun yang berhubungan dengan uang, mungkin jauh lebih aman dan lebih tepat bagi Anda untuk memindahkan log Anda ke disk yang lebih cepat daripada melempar dadu menggunakan fitur ini. Jika Anda mencoba meningkatkan waktu respons di aplikasi Ruang Obrolan Gamerz Web Anda, mungkin risikonya tidak terlalu parah.
Anda dapat mengontrol perilaku ini sampai tingkat tertentu untuk meminimalkan risiko kehilangan data. Anda dapat memaksa semua transaksi tahan lama yang tertunda untuk dipindahkan ke disk dengan salah satu dari dua cara:
- Lakukan semua transaksi yang tahan lama.
- Hubungi
sys.sp_flush_logsecara manual.
Ini memungkinkan Anda untuk kembali mengontrol kehilangan data dalam hal waktu, bukan ukuran; Anda dapat menjadwalkan flush setiap 5 detik, misalnya. Tetapi Anda akan ingin menemukan sweet spot Anda di sini; pembilasan terlalu sering dapat mengimbangi manfaat Ketahanan Tertunda sejak awal. Bagaimanapun, Anda tetap harus toleran terhadap kehilangan data , meskipun hanya bernilai
Anda akan berpikir bahwa CHECKPOINT mungkin membantu di sini, tetapi operasi ini sebenarnya tidak menjamin secara teknis log akan di-flush ke disk.
Interaksi dengan HA/DR
Anda mungkin bertanya-tanya bagaimana Ketahanan Tertunda berfungsi dengan fitur HA/DR seperti pengiriman log, replikasi, dan Grup Ketersediaan. Dengan sebagian besar ini berfungsi tidak berubah. Pengiriman dan replikasi log akan memutar ulang catatan log yang telah dikeraskan, sehingga potensi kehilangan data yang sama ada di sana. Dengan AG dalam mode asinkron, kami tidak menunggu pengakuan sekunder, sehingga akan berperilaku sama seperti hari ini. Namun, dengan sinkron, kami tidak dapat melakukan pada primer sampai transaksi dilakukan dan dikeraskan ke log jarak jauh. Bahkan dalam skenario itu kita mungkin mendapat keuntungan secara lokal dengan tidak harus menunggu log lokal untuk menulis, kita masih harus menunggu aktivitas jarak jauh. Jadi dalam skenario itu ada lebih sedikit manfaat, dan berpotensi tidak ada; kecuali mungkin dalam skenario yang jarang terjadi di mana disk log primer sangat lambat dan disk log sekunder sangat cepat. Saya menduga kondisi yang sama berlaku untuk pencerminan sinkronisasi/asinkron, tetapi Anda tidak akan mendapatkan komitmen resmi dari saya tentang cara kerja fitur baru yang mengilap dengan fitur yang sudah usang. :-)
Pengamatan Kinerja
Ini tidak akan banyak posting di sini jika saya tidak menunjukkan beberapa pengamatan kinerja yang sebenarnya. Saya menyiapkan 8 database untuk menguji efek dari dua pola beban kerja yang berbeda dengan atribut berikut:
- Model pemulihan:sederhana vs. penuh
- Lokasi log:SSD vs. HDD
- Daya tahan:tertunda vs. sepenuhnya tahan lama
Saya benar-benar malas efisien tentang hal semacam ini. Karena saya ingin menghindari pengulangan operasi yang sama dalam setiap database, saya membuat tabel berikut untuk sementara di model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Kemudian saya membangun satu set perintah SQL dinamis untuk membangun 8 database ini, daripada membuat database satu per satu dan kemudian mengacaukan pengaturannya:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Jangan ragu untuk menjalankan kode ini sendiri (dengan EXEC masih berkomentar) untuk melihat bahwa ini akan membuat 4 database dengan Delayed Durability OFF (dua dalam pemulihan LENGKAP, dua dalam SEDERHANA, masing-masing dengan log pada disk lambat, dan masing-masing dengan log on SSD). Ulangi pola itu untuk 4 database dengan Delayed Durability FORCED – Saya melakukan ini untuk menyederhanakan kode dalam pengujian, daripada mencerminkan apa yang akan saya lakukan dalam kehidupan nyata (di mana saya mungkin ingin memperlakukan beberapa transaksi sebagai hal yang kritis, dan beberapa sebagai, baik, kurang kritis).
Untuk pemeriksaan kewarasan, saya menjalankan kueri berikut untuk memastikan bahwa database memiliki matriks atribut yang tepat:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Hasil:
Konfigurasi yang relevan dari 8 database pengujian
Saya juga menjalankan pengujian dengan rapi beberapa kali untuk memastikan bahwa file data 1 GB dan file log 1 GB akan cukup untuk menjalankan seluruh rangkaian beban kerja tanpa memasukkan peristiwa pertumbuhan otomatis ke dalam persamaan. Sebagai praktik terbaik, saya secara rutin berusaha keras untuk memastikan sistem pelanggan memiliki cukup ruang yang dialokasikan (dan peringatan yang tepat terpasang) sehingga tidak ada peristiwa pertumbuhan yang terjadi pada waktu yang tidak terduga. Di dunia nyata saya tahu ini tidak selalu terjadi, tapi ini ideal.
Saya mengatur sistem yang akan dipantau dengan SQL Sentry – ini akan memungkinkan saya untuk dengan mudah menunjukkan sebagian besar metrik kinerja yang ingin saya soroti. Tetapi saya juga membuat tabel sementara untuk menyimpan metrik batch termasuk durasi dan keluaran yang sangat spesifik dari sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Ini akan memungkinkan saya untuk merekam waktu mulai dan selesai setiap batch individu, dan mengukur delta di DMV antara waktu mulai dan waktu akhir (hanya dapat diandalkan dalam kasus ini karena saya tahu saya satu-satunya pengguna di sistem).
Banyak transaksi kecil
Tes pertama yang ingin saya lakukan adalah banyak transaksi kecil. Untuk setiap database, saya ingin mendapatkan 500.000 batch terpisah dari satu sisipan masing-masing:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Ingat, saya mencoba untuk malas efisien tentang hal semacam ini. Jadi untuk menghasilkan kode untuk semua 8 database, saya menjalankan ini:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Saya menjalankan tes ini dan kemudian melihat #Metrics tabel dengan kueri berikut:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Ini menghasilkan hasil berikut (dan saya mengkonfirmasi melalui beberapa tes bahwa hasilnya konsisten):
| database | menulis | byte | byte/tulis | io_stall_ms | waktu_mulai | akhir_waktu | durasi (detik) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 26-04-2014 17:20:00 | 26-04-2014 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418.56 | 2,740 | 26-04-2014 17:21:08 | 26-04-2014 17:22:16 | 68 |
| dd3 | 8,246 | 262.254.592 | 31,803,85 | 3.996 | 26-04-2014 17:22:16 | 26-04-2014 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32.487,68 | 4,231 | 26-04-2014 17:23:24 | 26-04-2014 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052.87 | 35.593 | 26-04-2014 17:24:32 | 26-04-2014 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051.71 | 35.435 | 26-04-2014 17:26:32 | 26-04-2014 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1.052.20 | 50,857 | 26-04-2014 17:28:31 | 26-04-2014 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051.73 | 49,680 | 133 |
Transaksi kecil:Durasi dan hasil dari sys.dm_io_virtual_file_stats
Pasti ada beberapa pengamatan menarik di sini:
- Jumlah operasi penulisan individual sangat kecil untuk database Ketahanan Tertunda (~60X untuk tradisional).
- Jumlah total byte yang ditulis dipotong menjadi dua menggunakan Delayed Durability (saya kira karena semua penulisan dalam kasus tradisional mengandung banyak ruang yang terbuang).
- Jumlah byte per penulisan jauh lebih tinggi untuk Ketahanan Tertunda. Ini tidak terlalu mengejutkan, karena seluruh tujuan dari fitur ini adalah untuk menggabungkan penulisan bersama dalam kumpulan yang lebih besar.
- Total durasi I/O stall tidak stabil, tetapi kira-kira urutan besarnya lebih rendah untuk Delayed Durability. Kios di bawah transaksi yang sepenuhnya tahan lama jauh lebih sensitif terhadap jenis disk.
- Jika ada yang belum meyakinkan Anda sejauh ini, kolom durasi sangat jitu. Batch yang sepenuhnya tahan lama yang membutuhkan waktu dua menit atau lebih dipotong hampir setengahnya.
Kolom waktu mulai/berakhir memungkinkan saya untuk fokus pada dasbor Performance Advisor untuk periode yang tepat di mana transaksi ini terjadi, di mana kita dapat menggambar banyak indikator visual tambahan:
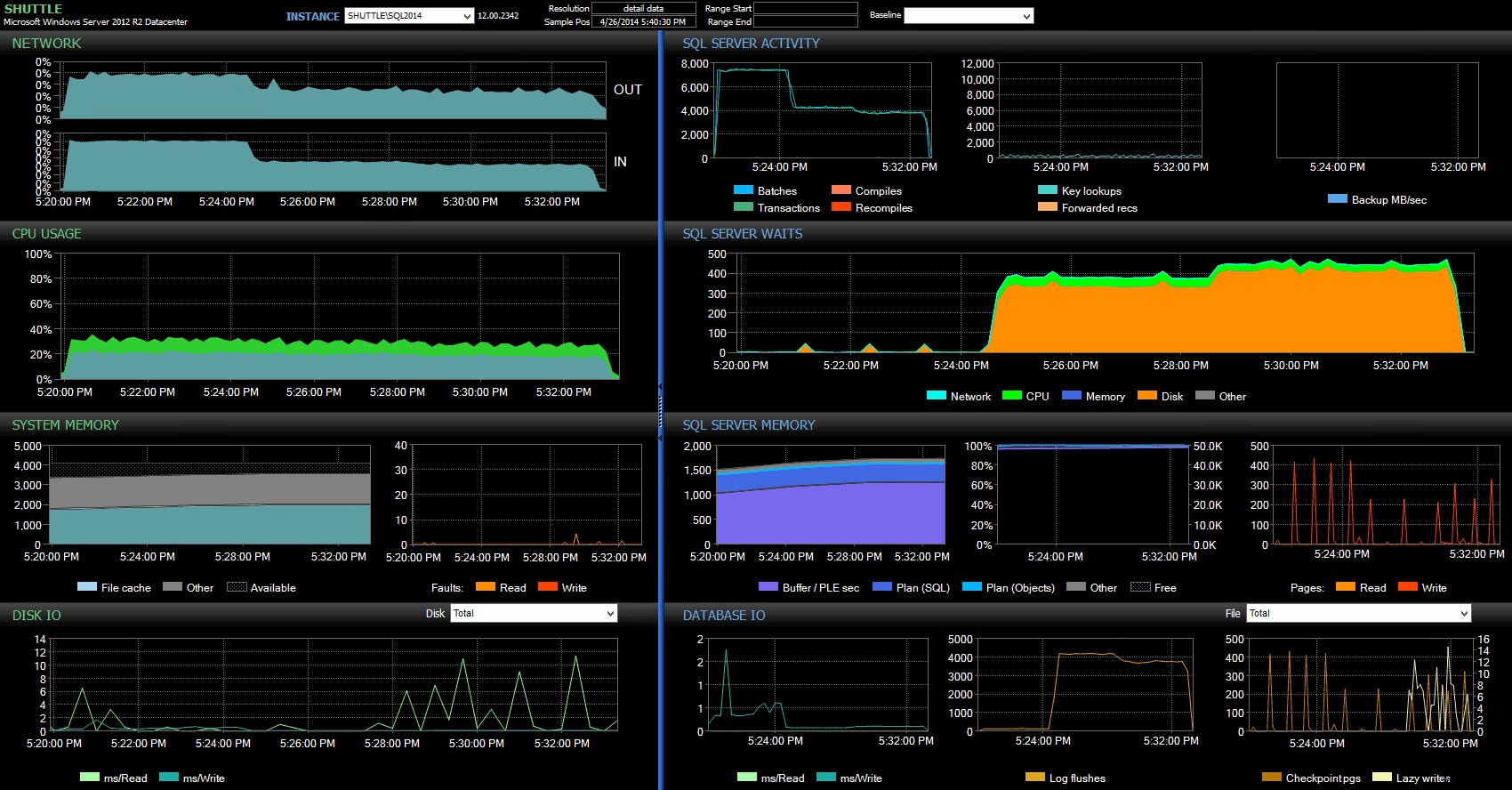
Dasbor SQL Sentry – klik untuk memperbesar
Pengamatan lebih lanjut di sini:
- Pada beberapa grafik, Anda dapat melihat dengan jelas kapan porsi Ketahanan Non-Delayed dari batch mengambil alih (~5:24:32 PM).
- Tidak ada dampak yang terlihat pada CPU atau memori saat menggunakan Ketahanan Tertunda.
- Anda dapat melihat dampak luar biasa pada kumpulan/transaksi per detik di grafik pertama di bawah Aktivitas SQL Server.
- SQL Server menunggu melalui atap ketika transaksi yang sepenuhnya tahan lama dimulai. Ini hampir secara eksklusif terdiri dari
WRITELOGmenunggu, dengan sejumlah kecilPAGEIOLOATCH_EXdanPAGEIOLATCH_UPmenunggu ukuran yang baik. - Jumlah total log flush selama operasi Ketahanan Tertunda cukup kecil (rendah 100 detik/detik), sementara ini melonjak menjadi lebih dari 4.000/detik untuk perilaku tradisional (dan sedikit lebih rendah untuk durasi pengujian HDD).
Transaksi lebih sedikit dan lebih besar
Untuk pengujian berikutnya, saya ingin melihat apa yang akan terjadi jika kami melakukan lebih sedikit operasi, tetapi memastikan setiap pernyataan memengaruhi jumlah data yang lebih besar. Saya ingin batch ini dijalankan terhadap setiap database:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Jadi sekali lagi saya menggunakan metode lazy untuk menghasilkan 8 salinan skrip ini, satu per database:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Saya menjalankan kumpulan ini, lalu mengubah kueri menjadi #Metrics di atas untuk melihat tes kedua, bukan yang pertama. Hasilnya:
| database | menulis | byte | byte/tulis | io_stall_ms | waktu_mulai | akhir_waktu | durasi (detik) |
|---|---|---|---|---|---|---|---|
| dd1 | 20.970 | 1.271.911.936 | 60,653.88 | 12.577 | 26-04-2014 17:41:21 | 26-04-2014 17:43:46 | 145 |
| dd2 | 20.997 | 1.272.145.408 | 60.587,00 | 14.698 | 26-04-2014 17:43:46 | 26-04-2014 17:46:11 | 145 |
| dd3 | 20.973 | 1.272.982.016 | 60,696.22 | 12.085 | 26-04-2014 17:46:11 | 26-04-2014 17:48:33 | 142 |
| dd4 | 20.958 | 1.272.064.512 | 60.695,89 | 11.795 | 143 | ||
| dd5 | 30.138 | 1.282.231.808 | 42.545,35 | 7.402 | 26-04-2014 17:50:56 | 26-04-2014 17:53:23 | 147 |
| dd6 | 30.138 | 1.282.260.992 | 42.546,31 | 7.806 | 26-04-2014 17:53:23 | 26-04-2014 17:55:53 | 150 |
| dd7 | 30.129 | 1.281.575.424 | 42.536,27 | 9.888 | 26-04-2014 17:55:53 | 26-04-2014 17:58:25 | 152 |
| dd8 | 30.130 | 1.281.449.472 | 42.530,68 | 11,452 | 26-04-2014 17:58:25 | 26-04-2014 18:00:55 | 150 |
Transaksi lebih besar:Durasi dan hasil dari sys.dm_io_virtual_file_stats
Kali ini, dampak Delayed Durability tidak terlalu terlihat. Kami melihat jumlah operasi tulis yang sedikit lebih kecil, dengan jumlah byte per penulisan yang sedikit lebih besar, dengan total byte yang ditulis hampir sama. Dalam kasus ini kita benar-benar melihat bahwa I/O stall lebih tinggi untuk Delayed Durability, dan kemungkinan ini menjelaskan fakta bahwa durasinya juga hampir sama.
Dari dasbor Performance Advisor, kami memiliki beberapa kesamaan dengan pengujian sebelumnya, dan beberapa perbedaan mencolok juga:
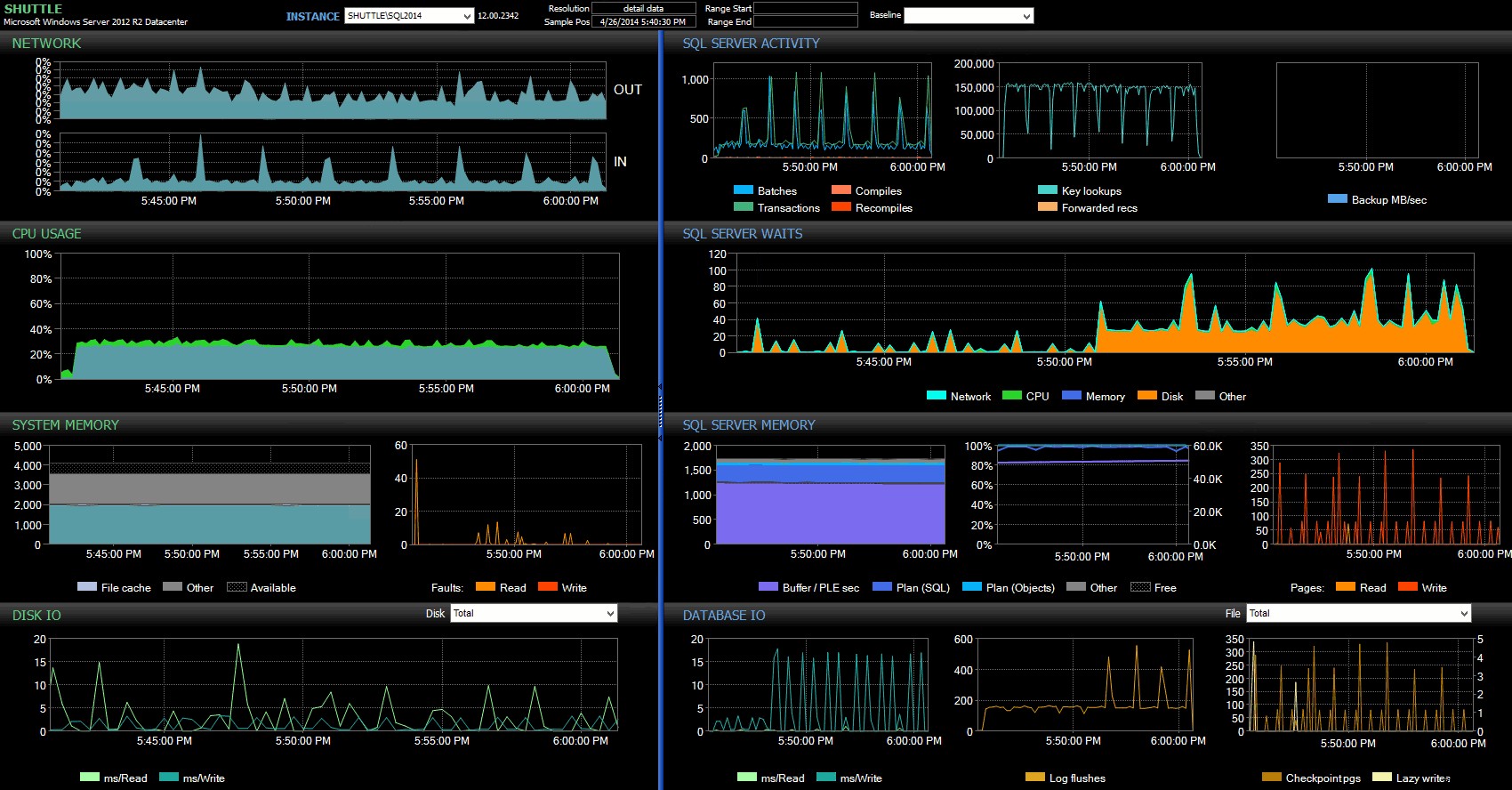
Dasbor SQL Sentry – klik untuk memperbesar
Salah satu perbedaan besar untuk ditunjukkan di sini adalah bahwa delta dalam statistik tunggu tidak begitu jelas seperti pada tes sebelumnya – masih ada frekuensi WRITELOG yang jauh lebih tinggi. menunggu batch yang sepenuhnya tahan lama, tetapi tidak mendekati level yang terlihat dengan transaksi yang lebih kecil. Hal lain yang dapat Anda temukan segera adalah bahwa dampak yang diamati sebelumnya pada batch dan transaksi per detik tidak lagi ada. Dan terakhir, meskipun terdapat lebih banyak log flush dengan transaksi yang sepenuhnya tahan lama daripada saat tertunda, perbedaan ini jauh lebih kecil dibandingkan dengan transaksi yang lebih kecil.
Kesimpulan
Harus jelas bahwa ada jenis beban kerja tertentu yang mungkin sangat diuntungkan dari Ketahanan Tertunda – dengan syarat, tentu saja, Anda memiliki toleransi terhadap kehilangan data . Fitur ini tidak terbatas pada In-Memory OLTP, tersedia di semua edisi SQL Server 2014, dan dapat diimplementasikan dengan sedikit atau tanpa perubahan kode. Ini tentu bisa menjadi teknik yang ampuh jika beban kerja Anda dapat mendukungnya. Namun sekali lagi, Anda perlu menguji beban kerja Anda untuk memastikan bahwa itu akan mendapat manfaat dari fitur ini, dan juga sangat mempertimbangkan apakah ini meningkatkan eksposur Anda terhadap risiko kehilangan data.
Selain itu, ini mungkin tampak bagi kerumunan SQL Server seperti ide baru yang segar, tetapi sebenarnya Oracle memperkenalkan ini sebagai "Asynchronous Commit" pada tahun 2006 (lihat COMMIT WRITE ... NOWAIT seperti yang didokumentasikan di sini dan di blog pada tahun 2007). Dan ide itu sendiri telah ada selama hampir 3 dekade; lihat riwayat singkat Hal Berenson tentang sejarahnya.
Lain kali
Satu ide yang saya perjuangkan adalah mencoba meningkatkan kinerja tempdb dengan memaksa Ketahanan Tertunda di sana. Satu properti khusus tempdb yang membuatnya menjadi kandidat yang menggoda adalah sifatnya yang sementara – apa pun di tempdb dirancang, secara eksplisit, untuk dapat dilemparkan setelah berbagai macam peristiwa sistem. Saya mengatakan ini sekarang tanpa tahu apakah ada bentuk beban kerja di mana ini akan berjalan dengan baik; tapi saya berencana untuk mencobanya, dan jika saya menemukan sesuatu yang menarik, Anda pasti akan mempostingnya di sini.