Salah satu fitur keren di Galera adalah penyediaan node otomatis dan kontrol keanggotaan. Jika sebuah node gagal atau kehilangan komunikasi, node tersebut akan secara otomatis dikeluarkan dari cluster dan tetap tidak beroperasi. Selama sebagian besar node masih berkomunikasi (Galera menyebut PC ini - komponen utama), ada kemungkinan besar node yang gagal dapat bergabung kembali secara otomatis, menyinkronkan ulang, dan melanjutkan replikasi setelah konektivitas kembali.
Umumnya, semua node Galera adalah sama. Mereka memegang kumpulan data yang sama dan peran yang sama dengan master, mampu menangani baca dan tulis secara bersamaan, berkat komunikasi grup Galera dan plugin replikasi berbasis sertifikasi. Oleh karena itu, sebenarnya tidak ada failover dari sudut pandang database karena keseimbangan ini. Hanya dari sisi aplikasi yang memerlukan failover, untuk melewati node yang tidak beroperasi saat cluster dipartisi.
Dalam posting blog ini, kita akan melihat pemahaman bagaimana Galera Cluster melakukan pemulihan node dan cluster jika terjadi partisi jaringan. Sebagai catatan tambahan, kami telah membahas topik serupa di posting blog ini beberapa waktu lalu. Codership telah menjelaskan konsep pemulihan Galera dengan sangat rinci di halaman dokumentasi, Kegagalan dan Pemulihan Node.
Kegagalan dan Penggusuran Node
Untuk memahami pemulihan, kita harus memahami bagaimana Galera mendeteksi kegagalan node dan proses penggusuran terlebih dahulu. Mari kita masukkan ini ke dalam skenario pengujian terkontrol sehingga kita dapat memahami proses penggusuran dengan lebih baik. Misalkan kita memiliki Cluster Galera dengan tiga node seperti diilustrasikan di bawah ini:
Perintah berikut dapat digunakan untuk mengambil opsi penyedia Galera kami:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GDaftarnya panjang, tapi kita hanya perlu fokus pada beberapa parameter untuk menjelaskan prosesnya:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Pertama-tama, Galera mengikuti format ISO 8601 untuk mewakili durasi. P1D berarti durasinya satu hari, sedangkan PT15S berarti durasinya 15 detik (perhatikan penunjuk waktu, T, yang mendahului nilai waktu). Misalnya jika seseorang ingin meningkatkan evs.view_forget_timeout hingga 1 setengah hari, seseorang akan menetapkan P1DT12H, atau PT36H.
Mengingat semua host belum dikonfigurasi dengan aturan firewall apa pun, kami menggunakan skrip berikut yang disebut block_galera.sh di galera2 untuk mensimulasikan kegagalan jaringan ke/dari node ini:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateDengan mengeksekusi skrip, kita mendapatkan output berikut:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Stempel waktu yang dilaporkan dapat dianggap sebagai awal dari partisi cluster, di mana kita kehilangan galera2, sementara galera1 dan galera3 masih online dan dapat diakses. Pada titik ini, arsitektur Galera Cluster kami terlihat seperti ini:
Dari Perspektif Node yang Dipartisi
Di galera2, Anda akan melihat beberapa cetakan di dalam log kesalahan MySQL. Mari kita pecah menjadi beberapa bagian. Waktu henti dimulai sekitar pukul 16:46:02 waktu UTC dan setelah gmcast.peer_timeout=PT3S , berikut ini muncul:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Saat melewati evs.suspect_timeout =PT5S , kedua node galera1 dan galera3 diduga mati oleh galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveKemudian, Galera akan merevisi tampilan cluster saat ini dan posisi node ini:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Dengan tampilan cluster baru, Galera akan melakukan perhitungan kuorum untuk memutuskan apakah node ini merupakan bagian dari komponen utama. Jika komponen baru melihat "primary =no", Galera akan menurunkan status node lokal dari SYNCED menjadi OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Dengan perubahan terbaru pada tampilan cluster dan status node, Galera mengembalikan tampilan cluster pasca-penggusuran dan status global seperti di bawah ini:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Anda dapat melihat status global galera2 berikut telah berubah selama periode ini:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+Pada titik ini, server MySQL/MariaDB di galera2 masih dapat diakses (database mendengarkan di 3306 dan Galera di 4567) dan Anda dapat menanyakan tabel sistem mysql dan membuat daftar database dan tabel. Namun ketika Anda melompat ke tabel non-sistem dan membuat kueri sederhana seperti ini:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useAnda akan segera mendapatkan kesalahan yang menunjukkan WSREP dimuat tetapi tidak siap digunakan oleh node ini, seperti yang dilaporkan oleh wsrep_ready status. Ini karena node kehilangan koneksinya ke Komponen Utama dan memasuki status non-operasional (status node lokal diubah dari SYNCED menjadi OPEN). Pembacaan data dari node dalam status non-operasional dianggap basi, kecuali jika Anda menyetel wsrep_dirty_reads=ON untuk mengizinkan pembacaan, meskipun Galera masih menolak perintah apa pun yang mengubah atau memperbarui basis data.
Terakhir, Galera akan terus mendengarkan dan terhubung kembali dengan anggota lain di latar belakang tanpa batas:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Alur proses eviction oleh komunikasi grup Galera untuk node yang dipartisi selama masalah jaringan dapat diringkas sebagai berikut:
- Terputus dari kluster setelah gmcast.peer_timeout .
- Mencurigai node lain setelah evs.suspect_timeout .
- Mengambil tampilan cluster baru.
- Melakukan perhitungan kuorum untuk menentukan status node.
- Menurunkan node dari SYNCED menjadi OPEN.
- Mencoba menyambung kembali ke komponen utama (node Galera lainnya) di latar belakang.
Dari Perspektif Komponen Utama
Di galera1 dan galera3 masing-masing, setelah gmcast.peer_timeout=PT3S , berikut ini muncul di log kesalahan MySQL:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Setelah lulus evs.suspect_timeout =PT5S , galera2 diduga mati oleh galera3 (dan galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera memeriksa apakah node lain merespons komunikasi grup di galera3, ia menemukan galera1 dalam keadaan primer dan stabil:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera merevisi tampilan cluster dari node ini (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera kemudian menghapus node yang dipartisi dari Komponen Utama:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Komponen Utama baru sekarang terdiri dari dua node, galera1 dan galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Komponen Utama akan bertukar status antara satu sama lain untuk menyetujui tampilan cluster baru dan status global:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera menghitung dan memverifikasi kuorum pertukaran status antar anggota online:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera memperbarui tampilan cluster baru dan status global setelah pengusiran galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)Pada titik ini, baik galera1 dan galera3 akan melaporkan status global yang serupa:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Mereka mencantumkan anggota yang bermasalah di wsrep_evs_delayed status. Karena status lokal "Disinkronkan", node ini beroperasi dan Anda dapat mengalihkan koneksi klien dari galera2 ke salah satu dari mereka. Jika langkah ini tidak nyaman, pertimbangkan untuk menggunakan penyeimbang beban yang ada di depan database untuk menyederhanakan titik akhir koneksi dari klien.
Pemulihan Node dan Bergabung
Node Galera yang dipartisi akan terus mencoba membuat koneksi dengan Komponen Utama tanpa batas. Mari kita hapus aturan iptables di galera2 agar terhubung dengan node yang tersisa:
# on galera2
$ iptables -FSetelah node dapat terhubung ke salah satu node, Galera akan mulai membangun kembali komunikasi grup secara otomatis:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableNode galera2 kemudian akan terhubung ke salah satu Komponen Utama (dalam hal ini adalah galera1, node ID 737422d6) untuk mendapatkan tampilan cluster saat ini dan status node:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera kemudian akan melakukan pertukaran status dengan anggota lainnya yang dapat membentuk Komponen Utama:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Pertukaran negara memungkinkan galera2 untuk menghitung kuorum dan menghasilkan hasil berikut:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera kemudian akan mempromosikan status node lokal dari OPEN ke PRIMARY, untuk memulai dan membuat koneksi node ke Komponen Utama:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Seperti dilansir dari baris di atas, Galera menghitung gap seberapa jauh node tertinggal dari cluster. Node ini memerlukan transfer status untuk mengejar nomor writeset 2836958 dari 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera menyiapkan pendengar IST pada port 4568 pada node ini dan meminta setiap node yang Disinkronkan di cluster untuk menjadi donor. Dalam hal ini, Galera secara otomatis memilih galera3 (192.168.55.173), atau dapat juga memilih donor dari daftar di bawah wsrep_sst_donor (jika ditentukan) untuk operasi sinkronisasi:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Ini kemudian akan mengubah status node lokal dari PRIMARY ke JOINER. Pada tahap ini, galera2 diberikan dengan permintaan transfer status dan mulai meng-cache write-set:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetNode galera2 mulai menerima writeset yang hilang dari gcache (galera3) donor yang dipilih:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Setelah semua writeset yang hilang diterima dan diterapkan, Galera akan mempromosikan galera2 sebagai BERGABUNG hingga seqno 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Node menerapkan setiap writeset yang di-cache dalam antrian budaknya dan selesai mengejar cluster. Antrian budaknya sekarang kosong. Galera akan mempromosikan galera2 ke SYNCED, yang menunjukkan bahwa node sekarang beroperasi dan siap melayani klien:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsPada titik ini, semua node kembali beroperasi. Anda dapat memverifikasi dengan menggunakan pernyataan berikut di galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size dilaporkan sebagai 3 dan status cluster adalah Primer, menunjukkan galera2 adalah bagian dari Komponen Utama. wsrep_evs_delayed juga telah dihapus dan status lokal sekarang Disinkronkan.
Alur proses pemulihan untuk node yang dipartisi selama masalah jaringan dapat diringkas sebagai berikut:
- Membangun kembali komunikasi grup ke node lain.
- Mengambil tampilan cluster dari salah satu Komponen Utama.
- Melakukan pertukaran status dengan Komponen Utama dan menghitung kuorum.
- Mengubah status node lokal dari OPEN menjadi PRIMARY.
- Menghitung jarak antara node lokal dan cluster.
- Mengubah status node lokal dari PRIMARY menjadi JOINER.
- Mempersiapkan pendengar/penerima IST pada port 4568.
- Meminta transfer status melalui IST dan memilih donor.
- Mulai menerima dan menerapkan writeset yang hilang dari gcache donor yang dipilih.
- Mengubah status simpul lokal dari BERGABUNG menjadi BERGABUNG.
- Mengejar cluster dengan menerapkan writeset yang di-cache di antrean slave.
- Mengubah status node lokal dari BERGABUNG menjadi SYNCED.
Kegagalan Klaster
Cluster Galera dianggap gagal jika tidak ada komponen utama (PC) yang tersedia. Pertimbangkan Galera Cluster tiga simpul yang serupa seperti yang digambarkan dalam diagram di bawah ini:
Sebuah cluster dianggap operasional jika semua node atau mayoritas node sedang online. Online berarti mereka dapat melihat satu sama lain melalui lalu lintas replikasi Galera atau komunikasi grup. Jika tidak ada lalu lintas yang masuk dan keluar dari node, cluster akan mengirimkan sinyal detak jantung agar node merespon tepat waktu. Jika tidak, itu akan dimasukkan ke dalam daftar penundaan atau dugaan sesuai dengan bagaimana node merespons.
Jika sebuah node down, misalkan node C, cluster akan tetap beroperasi karena node A dan B masih dalam kuorum dengan 2 suara dari 3 untuk membentuk komponen utama. Anda harus mendapatkan status cluster berikut pada A dan B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Jika misalkan sebuah saklar primer menjadi kaput, seperti diilustrasikan pada diagram berikut:
Pada titik ini, setiap node kehilangan komunikasi satu sama lain, dan status cluster akan dilaporkan sebagai non-Primary pada semua node (seperti yang terjadi pada galera2 dalam kasus sebelumnya). Setiap node akan menghitung kuorum dan mengetahui bahwa itu adalah minoritas (1 suara dari 3) sehingga kehilangan kuorum, yang berarti tidak ada Komponen Utama yang terbentuk dan akibatnya semua node menolak untuk melayani data apa pun. Ini dianggap sebagai kegagalan cluster.
Setelah masalah jaringan teratasi, Galera akan secara otomatis membangun kembali komunikasi antar anggota, menukar status node dan menentukan kemungkinan mereformasi komponen utama dengan membandingkan status node, UUID, dan seqnos. Jika probabilitas ada, Galera akan menggabungkan komponen utama seperti yang ditunjukkan pada baris berikut:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
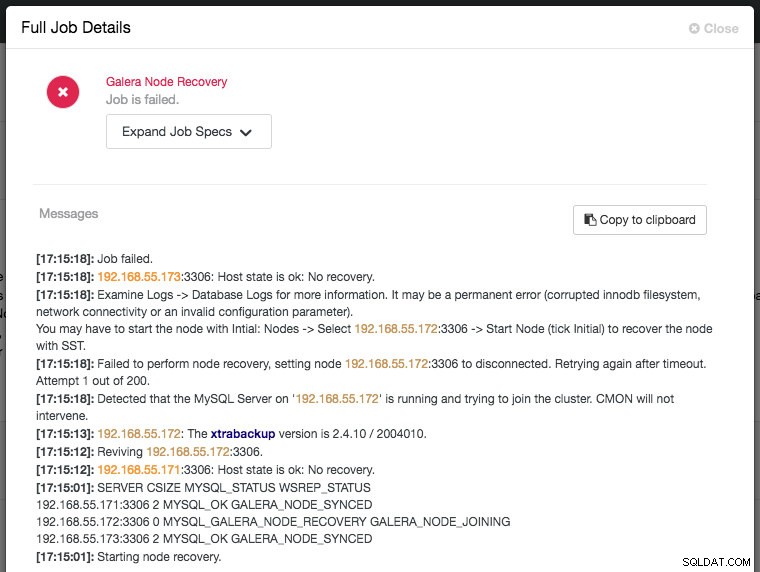
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Kesimpulan
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.



