Sudah lama diketahui bahwa variabel tabel dengan banyak baris dapat menjadi masalah, karena pengoptimal selalu melihatnya memiliki satu baris. Tanpa kompilasi ulang setelah variabel tabel telah diisi (sejak sebelum itu kosong), tidak ada kardinalitas untuk tabel, dan kompilasi ulang otomatis tidak terjadi karena variabel tabel bahkan tidak tunduk pada ambang kompilasi ulang. Oleh karena itu, rencana didasarkan pada kardinalitas tabel nol, bukan satu, tetapi minimum ditingkatkan menjadi satu seperti yang dijelaskan oleh Paul White (@SQL_Kiwi) dalam jawaban dba.stackexchange ini.
Cara yang biasanya kami lakukan untuk mengatasi masalah ini adalah dengan menambahkan OPTION (RECOMPILE) ke kueri yang mereferensikan variabel tabel, memaksa pengoptimal untuk memeriksa kardinalitas variabel tabel setelah diisi. Untuk menghindari kebutuhan untuk pergi dan secara manual mengubah setiap kueri untuk menambahkan petunjuk kompilasi ulang eksplisit, tanda pelacakan baru (2453) telah diperkenalkan di SQL Server 2012 Paket Layanan 2 dan Pembaruan Kumulatif SQL Server 2014 #3:
- KB #2952444 :MEMPERBAIKI:Performa buruk saat Anda menggunakan variabel tabel di SQL Server 2012 atau SQL Server 2014
Saat bendera pelacakan 2453 aktif, pengoptimal dapat memperoleh gambaran kardinalitas tabel yang akurat setelah variabel tabel dibuat. Ini bisa menjadi A Good Thing™ untuk banyak pertanyaan, tetapi mungkin tidak semua, dan Anda harus mengetahui cara kerjanya yang berbeda dari OPTION (RECOMPILE) . Terutama, optimasi penyematan parameter yang dibicarakan oleh Paul White dalam posting ini terjadi di bawah OPTION (RECOMPILE) , tetapi tidak di bawah tanda jejak baru ini.
Tes Sederhana
Tes awal saya terdiri dari hanya mengisi variabel tabel dan memilih darinya; ini menghasilkan perkiraan jumlah baris 1. Ini adalah tes yang saya jalankan (dan saya menambahkan petunjuk kompilasi ulang untuk membandingkan):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Menggunakan SQL Sentry Plan Explorer, kita dapat melihat bahwa rencana grafis untuk kedua kueri dalam kasus ini identik, mungkin setidaknya sebagian karena ini secara harfiah merupakan rencana sepele:

Rencana grafis untuk pemindaian indeks sepele terhadap @t
Namun, perkiraannya tidak sama. Meskipun tanda jejak diaktifkan, kami masih mendapatkan perkiraan 1 yang keluar dari pemindaian indeks jika kami tidak menggunakan petunjuk kompilasi ulang:
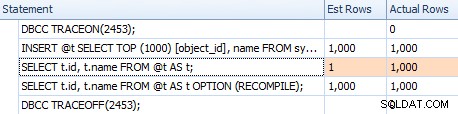
Membandingkan perkiraan untuk rencana sepele dalam kisi pernyataan
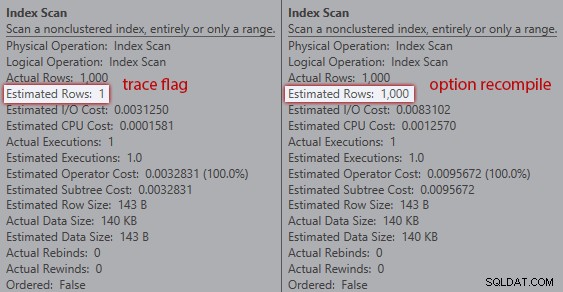
Membandingkan perkiraan antara tanda jejak (kiri) dan kompilasi ulang (kanan)
Jika Anda pernah berada di sekitar saya secara langsung, Anda mungkin dapat membayangkan wajah yang saya buat saat ini. Saya yakin bahwa artikel KB mencantumkan nomor tanda jejak yang salah, atau bahwa saya memerlukan pengaturan lain yang diaktifkan agar benar-benar aktif.
Benjamin Nevarez (@BenjaminNevarez) dengan cepat menunjukkan kepada saya bahwa saya perlu melihat lebih dekat pada artikel KB "Bugs yang diperbaiki di SQL Server 2012 Service Pack 2". Meskipun mereka telah mengaburkan teks di balik peluru tersembunyi di bawah Sorotan> Mesin Relasional, artikel daftar perbaikan melakukan pekerjaan yang sedikit lebih baik dalam menggambarkan perilaku tanda jejak daripada artikel asli (penekanan milik saya):
Jika variabel tabel digabungkan dengan tabel lain di SQL Server, ini dapat mengakibatkan kinerja yang lambat karena pemilihan rencana kueri yang tidak efisien karena SQL Server tidak mendukung statistik atau melacak jumlah baris dalam variabel tabel saat menyusun rencana kueri.Jadi akan tampak dari deskripsi ini bahwa tanda jejak hanya dimaksudkan untuk mengatasi masalah ketika variabel tabel berpartisipasi dalam gabungan. (Mengapa perbedaan itu tidak dibuat dalam artikel aslinya, saya tidak tahu.) Tetapi itu juga berfungsi jika kita membuat kueri melakukan sedikit lebih banyak pekerjaan – kueri di atas dianggap sepele oleh pengoptimal, dan tanda jejak tidak' t bahkan mencoba untuk melakukan apa pun dalam kasus itu. Tapi itu akan muncul jika optimasi berbasis biaya dilakukan, bahkan tanpa bergabung; bendera jejak sama sekali tidak berpengaruh pada rencana sepele. Berikut adalah contoh paket non-sepele yang tidak melibatkan penggabungan:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Rencana ini tidak lagi sepele; pengoptimalan ditandai sebagai penuh. Sebagian besar biaya dipindahkan ke operator sortir:
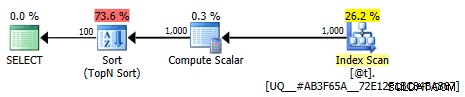
Rencana grafis yang tidak terlalu sepele
Dan perkiraan berbaris untuk kedua kueri (saya akan menyimpan tips alat kali ini, tetapi saya dapat meyakinkan Anda bahwa keduanya sama):

Kisi pernyataan untuk rencana yang tidak terlalu sepele dengan dan tanpa petunjuk kompilasi ulang
Jadi sepertinya artikel KB tidak sepenuhnya akurat – saya bisa memaksakan perilaku yang diharapkan dari tanda jejak tanpa memperkenalkan gabungan. Tapi saya juga ingin mengujinya dengan bergabung.
Tes yang Lebih Baik
Mari kita ambil contoh sederhana ini, dengan dan tanpa tanda jejak:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Tanpa tanda jejak, pengoptimal memperkirakan bahwa satu baris akan berasal dari pemindaian indeks terhadap variabel tabel. Namun, dengan tanda jejak diaktifkan, itu membuat 1.000 baris menggedor:
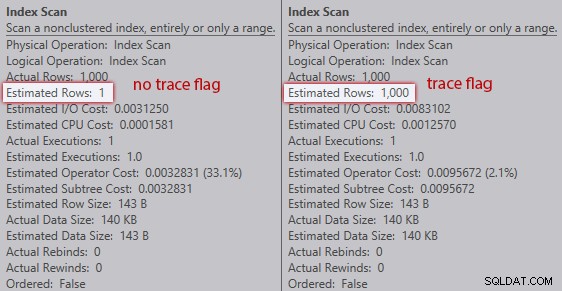
Perbandingan perkiraan pemindaian indeks (tidak ada tanda jejak di sebelah kiri, jejak bendera di sebelah kanan)
Perbedaan tidak berhenti di situ. Jika kita melihat lebih dekat, kita dapat melihat berbagai keputusan berbeda yang telah dibuat oleh pengoptimal, semuanya berasal dari perkiraan yang lebih baik ini:
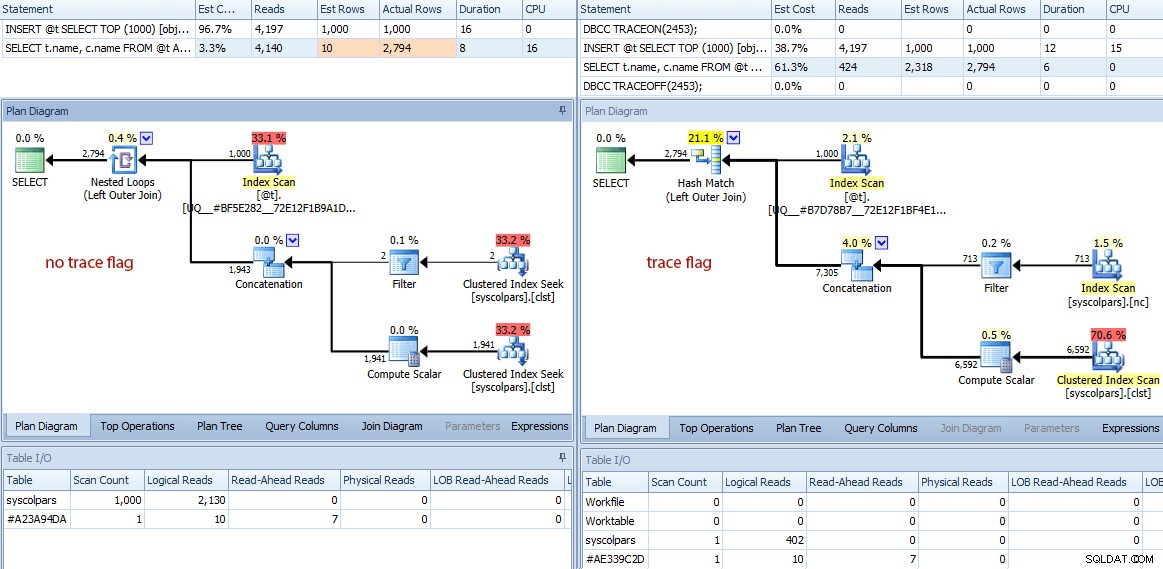
Perbandingan rencana (tidak ada tanda jejak di sebelah kiri, tanda jejak di sebelah kanan)
Ringkasan singkat tentang perbedaannya:
- Kueri tanpa tanda jejak telah melakukan 4.140 operasi baca, sedangkan kueri dengan perkiraan yang ditingkatkan hanya melakukan 424 (pengurangan sekitar 90%).
- Pengoptimal memperkirakan bahwa seluruh kueri akan mengembalikan 10 baris tanpa tanda pelacakan, dan 2.318 baris yang jauh lebih akurat saat menggunakan tanda pelacakan.
- Tanpa tanda jejak, pengoptimal memilih untuk melakukan penggabungan loop bersarang (yang masuk akal ketika salah satu input diperkirakan sangat kecil). Hal ini menyebabkan operator penggabungan dan kedua indeks berusaha mengeksekusi 1.000 kali, berbeda dengan pencocokan hash yang dipilih di bawah tanda pelacakan, di mana operator penggabungan dan kedua pemindaian hanya dieksekusi sekali.
- Tab Tabel I/O juga menampilkan 1.000 pemindaian (pemindaian rentang yang disamarkan sebagai pencarian indeks) dan jumlah pembacaan logis yang jauh lebih tinggi dibandingkan
syscolpars(tabel sistem di belakangsys.all_columns). - Meskipun durasi tidak terpengaruh secara signifikan (24 milidetik vs. 18 milidetik), Anda mungkin dapat membayangkan jenis dampak yang mungkin ditimbulkan oleh perbedaan lain ini pada kueri yang lebih serius.
- Jika kita mengalihkan diagram ke perkiraan biaya, kita dapat melihat betapa berbedanya variabel tabel dapat menipu pengoptimal tanpa tanda jejak:
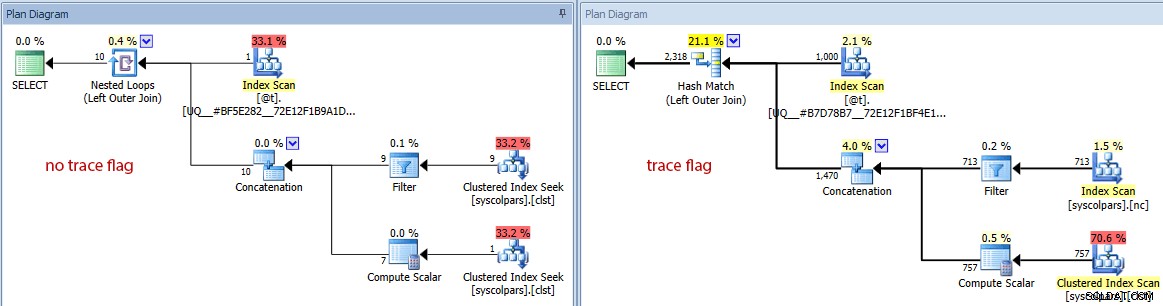
Membandingkan perkiraan jumlah baris (tidak ada tanda jejak di sebelah kiri, jejak bendera di sebelah kanan)
Jelas dan tidak mengejutkan bahwa pengoptimal melakukan pekerjaan yang lebih baik dalam memilih rencana yang tepat ketika memiliki pandangan yang akurat tentang kardinalitas yang terlibat. Tapi berapa biayanya?
Mengkompilasi Ulang dan Overhead
Saat kita menggunakan OPTION (RECOMPILE) dengan kumpulan di atas, tanpa tanda jejak diaktifkan, kami mendapatkan paket berikut – yang cukup mirip dengan rencana dengan bendera jejak (satu-satunya perbedaan mencolok adalah perkiraan baris adalah 2.316 bukannya 2.318):
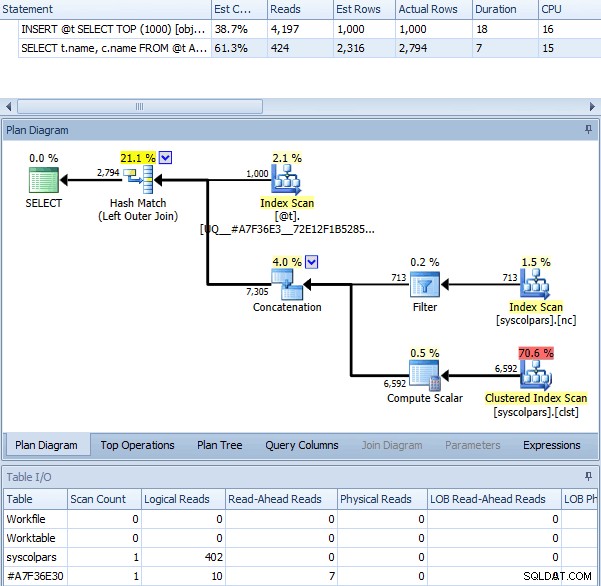
Kueri yang sama dengan OPTION (RECOMPILE)
Jadi, ini mungkin membuat Anda percaya bahwa tanda pelacakan menyelesaikan hasil yang serupa dengan memicu kompilasi ulang untuk Anda setiap saat. Kami dapat menyelidiki ini menggunakan sesi Acara Diperpanjang yang sangat sederhana:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Saya menjalankan kumpulan kumpulan berikut, yang mengeksekusi 20 kueri dengan (a) tidak ada opsi kompilasi ulang atau tanda pelacakan, (b) opsi kompilasi ulang, dan (c) tanda pelacakan tingkat sesi.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Kemudian saya melihat data acara:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Hasilnya menunjukkan bahwa tidak ada kompilasi ulang yang terjadi di bawah kueri standar, pernyataan yang mereferensikan variabel tabel dikompilasi ulang sekali di bawah bendera jejak dan, seperti yang Anda duga, setiap saat dengan RECOMPILE pilihan:
| sql_text | recompile_count |
|---|---|
| /* kompilasi ulang */ DECLARE @t TABLE (i INT … | 20 |
| /* tanda jejak */ DBCC TRACEON(2453); MENYATAKAN @t … | 1 |
Hasil kueri terhadap data XEvents
Selanjutnya, saya mematikan sesi Extended Events, lalu mengubah batch untuk mengukur pada skala. Pada dasarnya kode ini mengukur 1.000 iterasi untuk membuat dan mengisi variabel tabel, lalu memilih hasilnya menjadi tabel #temp (salah satu cara untuk menekan output dari banyak kumpulan hasil sekali pakai), menggunakan masing-masing dari tiga metode.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Saya menjalankan batch ini 10 kali dan mengambil rata-rata; mereka adalah:
(milidetik)
Durasi rata-rata untuk 1.000 iterasi
Dalam hal ini, mendapatkan perkiraan yang tepat setiap kali menggunakan petunjuk kompilasi ulang jauh lebih lambat daripada perilaku default, tetapi menggunakan tanda jejak sedikit lebih cepat. Ini masuk akal karena – sementara kedua metode memperbaiki perilaku default menggunakan perkiraan palsu (dan mendapatkan rencana yang buruk sebagai hasilnya), kompilasi ulang mengambil sumber daya dan, ketika mereka tidak atau tidak dapat menghasilkan rencana yang lebih efisien, cenderung berkontribusi pada durasi batch keseluruhan.
Sepertinya mudah, tapi tunggu…
Tes di atas sedikit – dan sengaja – cacat. Kami memasukkan jumlah baris yang sama (1.000) ke dalam variabel tabel setiap saat . Apa yang terjadi jika populasi awal dari variabel tabel bervariasi untuk batch yang berbeda? Tentunya kita akan melihat kompilasi ulang, bahkan di bawah bendera jejak, bukan? Waktunya ujian lagi. Mari siapkan sesi Acara yang Diperpanjang yang sedikit berbeda, hanya dengan nama file target yang berbeda (agar tidak mencampur data apa pun dari sesi lain):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Sekarang, mari kita periksa batch ini, menyiapkan jumlah baris untuk setiap iterasi yang berbeda secara signifikan. Kami akan menjalankan ini tiga kali, menghapus komentar yang sesuai sehingga kami memiliki satu kumpulan tanpa tanda jejak atau kompilasi ulang eksplisit, satu kumpulan dengan tanda jejak, dan satu kumpulan dengan OPTION (RECOMPILE) (memiliki komentar yang akurat di awal membuat kumpulan ini lebih mudah diidentifikasi di tempat-tempat seperti keluaran Acara yang Diperpanjang):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Saya menjalankan kumpulan ini di Management Studio, membukanya satu per satu di Plan Explorer, dan memfilter pohon pernyataan hanya di SELECT pertanyaan. Kita dapat melihat perilaku yang berbeda dalam tiga kumpulan dengan melihat baris yang diperkirakan dan yang sebenarnya:

Perbandingan tiga kumpulan, melihat perkiraan vs. baris aktual
Pada kisi paling kanan, Anda dapat dengan jelas melihat di mana kompilasi ulang tidak terjadi di bawah tanda jejak
Kami dapat memeriksa data XEvents untuk melihat apa yang sebenarnya terjadi dengan kompilasi ulang:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Hasil:
| sql_text | recompile_count |
|---|---|
| /* kompilasi ulang */ DECLARE @i INT =1; SEMENTARA … | 6 |
| /* tanda jejak */ DECLARE @i INT =1; SEMENTARA … | 4 |
Hasil kueri terhadap data XEvents
Sangat menarik! Di bawah bendera jejak, kita *melakukan* melihat kompilasi ulang, tetapi hanya ketika nilai parameter runtime telah bervariasi secara signifikan dari nilai yang di-cache. Ketika nilai runtime berbeda, tetapi tidak terlalu banyak, kami tidak mendapatkan kompilasi ulang, dan perkiraan yang sama digunakan. Jadi jelas bahwa bendera jejak memperkenalkan ambang kompilasi ulang ke variabel tabel, dan saya telah mengkonfirmasi (melalui tes terpisah) bahwa ini menggunakan algoritma yang sama seperti yang dijelaskan untuk tabel #temp dalam makalah "kuno" tetapi masih relevan ini. Saya akan membuktikannya di postingan selanjutnya.
Sekali lagi kami akan menguji kinerja, menjalankan batch 1.000 kali (dengan sesi Acara yang Diperpanjang dimatikan), dan mengukur durasi:
(milidetik)
Durasi rata-rata untuk 1.000 iterasi
Dalam skenario khusus ini, kami kehilangan sekitar 10% kinerja dengan memaksa kompilasi ulang setiap kali atau dengan menggunakan tanda jejak. Tidak begitu yakin bagaimana delta didistribusikan:Apakah rencana berdasarkan perkiraan yang lebih baik tidak secara signifikan lebih baik? Apakah kompilasi ulang mengimbangi peningkatan kinerja apa pun dengan sebanyak itu ? Saya tidak ingin menghabiskan terlalu banyak waktu untuk ini, dan itu adalah contoh sepele, tetapi ini menunjukkan kepada Anda bahwa bermain dengan cara kerja pengoptimal bisa menjadi urusan yang tidak terduga. Terkadang Anda mungkin lebih baik dengan perilaku default kardinalitas =1, mengetahui bahwa Anda tidak akan pernah menyebabkan kompilasi ulang yang tidak semestinya. Di mana tanda jejak mungkin sangat masuk akal adalah jika Anda memiliki kueri di mana Anda berulang kali mengisi variabel tabel dengan kumpulan data yang sama (misalnya, tabel pencarian Kode Pos) atau Anda selalu menggunakan 50 atau 1.000 baris (misalnya, mengisi variabel tabel untuk digunakan dalam pagination). Bagaimanapun, Anda tentu harus menguji dampaknya pada beban kerja apa pun di mana Anda berencana untuk memperkenalkan tanda pelacakan atau kompilasi ulang eksplisit.
TVP dan Jenis Tabel
Saya juga ingin tahu bagaimana ini akan memengaruhi jenis tabel, dan apakah kita akan melihat peningkatan kardinalitas untuk TVP, di mana gejala yang sama ada. Jadi saya membuat tipe tabel sederhana yang meniru variabel tabel yang digunakan sejauh ini:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Kemudian saya mengambil batch di atas dan cukup mengganti DECLARE @t TABLE(id INT PRIMARY KEY); dengan DECLARE @t dbo.t; - segala sesuatu yang lain tetap sama persis. Saya menjalankan tiga batch yang sama, dan inilah yang saya lihat:

Membandingkan perkiraan dan aktual antara perilaku default, kompilasi ulang opsi, dan bendera pelacakan 2453
Jadi ya, tampaknya tanda pelacakan bekerja dengan cara yang sama persis dengan TVP – kompilasi ulang menghasilkan perkiraan baru untuk pengoptimal saat jumlah baris melampaui ambang kompilasi ulang, dan dilewati saat jumlah baris "cukup dekat".
Pro, Kontra, dan Peringatan
Salah satu keuntungan dari tanda jejak adalah Anda dapat menghindari beberapa mengkompilasi ulang dan masih melihat kardinalitas tabel – selama Anda mengharapkan jumlah baris dalam variabel tabel stabil, atau tidak mengamati penyimpangan rencana yang signifikan karena kardinalitas yang bervariasi. Lain adalah bahwa Anda dapat mengaktifkannya secara global atau pada tingkat sesi dan tidak harus memperkenalkan petunjuk kompilasi ulang untuk semua pertanyaan Anda. Dan terakhir, setidaknya dalam kasus di mana kardinalitas variabel tabel stabil, perkiraan yang tepat menghasilkan kinerja yang lebih baik daripada default, dan juga kinerja yang lebih baik daripada menggunakan opsi kompilasi ulang – semua kompilasi itu pasti bisa bertambah.
Ada beberapa kelemahan juga, tentu saja. Salah satu yang saya sebutkan di atas adalah yang dibandingkan dengan OPTION (RECOMPILE) Anda kehilangan pengoptimalan tertentu, seperti penyematan parameter. Lain adalah bahwa bendera jejak tidak akan memiliki dampak yang Anda harapkan pada rencana sepele. Dan satu yang saya temukan di sepanjang jalan adalah menggunakan QUERYTRACEON petunjuk untuk menegakkan tanda pelacakan di tingkat kueri tidak berfungsi – sejauh yang saya tahu, tanda pelacakan harus ada saat variabel tabel atau TVP dibuat dan/atau diisi agar pengoptimal melihat kardinalitas di atas 1.
Ingatlah bahwa menjalankan tanda pelacakan secara global memperkenalkan kemungkinan regresi rencana kueri ke setiap kueri yang melibatkan variabel tabel (itulah sebabnya fitur ini diperkenalkan di bawah tanda pelacakan sejak awal), jadi pastikan untuk menguji seluruh beban kerja Anda tidak peduli bagaimana Anda menggunakan tanda jejak. Juga, saat Anda menguji perilaku ini, lakukan di database pengguna; beberapa pengoptimalan dan penyederhanaan yang biasanya Anda harapkan terjadi tidak terjadi saat konteks disetel ke tempdb, jadi perilaku apa pun yang Anda amati di sana mungkin tidak tetap konsisten saat Anda memindahkan kode dan setelan ke database pengguna.
Kesimpulan
Jika Anda menggunakan variabel tabel atau TVP dengan jumlah baris yang besar namun relatif konsisten, Anda mungkin perlu mengaktifkan tanda pelacakan ini untuk kumpulan atau prosedur tertentu guna mendapatkan kardinalitas tabel yang akurat tanpa memaksakan kompilasi ulang secara manual pada kueri individual. Anda juga dapat menggunakan tanda pelacakan di tingkat instans, yang akan memengaruhi semua kueri. Tetapi seperti perubahan apa pun, dalam kedua kasus, Anda harus rajin menguji kinerja seluruh beban kerja Anda, mencari secara eksplisit untuk setiap regresi, dan memastikan bahwa Anda menginginkan perilaku tanda jejak karena Anda dapat mempercayai stabilitas variabel tabel Anda jumlah baris.
Saya senang melihat tanda jejak ditambahkan ke SQL Server 2014, tetapi akan lebih baik jika itu menjadi perilaku default. Bukannya ada keuntungan yang signifikan untuk menggunakan variabel tabel besar di atas tabel #temp besar, tetapi akan lebih baik untuk melihat lebih banyak paritas antara dua jenis struktur sementara ini yang dapat didiktekan pada tingkat yang lebih tinggi. Semakin banyak paritas yang kita miliki, semakin sedikit orang yang harus mempertimbangkan mana yang harus mereka gunakan (atau setidaknya memiliki lebih sedikit kriteria untuk dipertimbangkan saat memilih). Martin Smith memiliki Q &A yang bagus di dba.stackexchange yang mungkin sekarang karena pembaruan:Apa perbedaan antara tabel temp dan variabel tabel di SQL Server?
Catatan Penting
Jika Anda akan menginstal SQL Server 2012 Service Pack 2 (apakah menggunakan tanda jejak ini atau tidak), silakan lihat juga posting saya tentang regresi di SQL Server 2012 dan 2014 yang dapat – dalam skenario yang jarang – memperkenalkan potensi kehilangan data atau kerusakan selama pembuatan ulang indeks online. Ada pembaruan kumulatif yang tersedia untuk SQL Server 2012 SP1 dan SP2 dan juga untuk SQL Server 2014. Tidak akan ada perbaikan untuk cabang RTM 2012.
Pengujian lebih lanjut
Saya memiliki hal-hal lain di daftar saya untuk diuji. Pertama, saya ingin melihat apakah bendera jejak ini memiliki efek pada tipe tabel Dalam Memori di SQL Server 2014. Saya juga akan membuktikan tanpa keraguan bahwa bendera jejak 2453 menggunakan ambang kompilasi ulang yang sama untuk tabel variabel dan TVP seperti halnya untuk tabel #temp.