Kita semua telah dimanjakan oleh kemampuan mesin pencari untuk "menyelesaikan" hal-hal seperti kesalahan ejaan, perbedaan ejaan nama, atau situasi lain di mana istilah pencarian mungkin cocok pada halaman yang penulisnya mungkin lebih suka menggunakan ejaan kata yang berbeda. Menambahkan fitur tersebut ke aplikasi berbasis basis data kami sendiri dapat memperkaya dan menyempurnakan aplikasi kami, dan sementara penawaran sistem manajemen basis data relasional (RDBMS) komersial memberikan solusi khusus yang dikembangkan sepenuhnya untuk masalah ini, biaya lisensi alat ini dapat menjadi lebih mahal. menjangkau pengembang kecil atau perusahaan pengembangan perangkat lunak kecil.
Orang bisa berargumen bahwa ini bisa dilakukan dengan menggunakan pemeriksa ejaan. Namun, pemeriksa ejaan biasanya tidak berguna saat mencocokkan ejaan nama atau kata lain yang benar, tetapi alternatif. Pencocokan dengan suara mengisi celah fungsional ini. Itulah topik tutorial pemrograman hari ini:cara meng-query suara dengan Python menggunakan Metaphones.
Apa itu Soundex?
Soundex dikembangkan pada awal abad ke-20 sebagai sarana bagi Sensus AS untuk mencocokkan nama berdasarkan bunyinya. Itu kemudian digunakan oleh berbagai perusahaan telepon untuk mencocokkan nama pelanggan. Ini terus digunakan untuk pencocokan data fonetik hingga hari ini meskipun terbatas pada ejaan dan pengucapan bahasa Inggris Amerika. Hal ini juga terbatas pada huruf bahasa Inggris. Sebagian besar RDBMS, seperti SQL Server dan Oracle, bersama dengan MySQL dan variannya, menerapkan fungsi Soundex dan, terlepas dari keterbatasannya, fungsi ini terus digunakan untuk mencocokkan banyak kata non-Inggris.
Apa itu Metafon Ganda?
Metafon algoritma dikembangkan pada tahun 1990 dan mengatasi beberapa keterbatasan Soundex. Pada tahun 2000, tindak lanjut yang ditingkatkan, Metafon Ganda , Dikembangkan. Double Metaphone mengembalikan nilai primer dan sekunder yang sesuai dengan dua cara pengucapan satu kata. Sampai hari ini algoritme ini tetap menjadi salah satu algoritme fonetik sumber terbuka yang lebih baik. Metaphone 3 dirilis pada tahun 2009 sebagai peningkatan dari Double Metaphone, tetapi ini adalah produk komersial.
Sayangnya, banyak RDBMS terkemuka yang disebutkan di atas tidak mengimplementasikan Metafon Ganda, dan sebagian besar bahasa skrip terkemuka tidak menyediakan implementasi Metafon Ganda yang didukung. Namun, Python menyediakan modul yang mengimplementasikan Double Metaphone.
Contoh yang disajikan dalam tutorial pemrograman Python ini menggunakan MariaDB versi 10.5.12 dan Python 3.9.2, keduanya berjalan di Kali/Debian Linux.
Cara Menambahkan Metafon Ganda ke Python
Seperti modul Python lainnya, alat pip dapat digunakan untuk menginstal Double Metaphone. Sintaksnya tergantung pada instalasi Python Anda. Instalasi Double Metaphone biasanya terlihat seperti contoh berikut:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Perhatikan, bahwa kapitalisasi ekstra disengaja. Kode berikut adalah contoh cara menggunakan Double Metaphone dengan Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
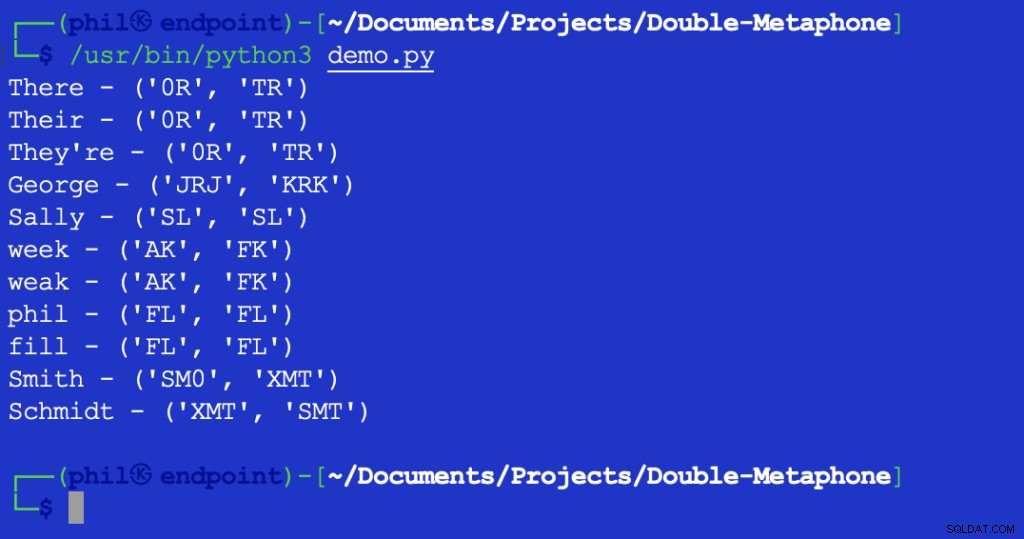
Skrip Python di atas memberikan output berikut saat dijalankan di lingkungan pengembangan terintegrasi (IDE) atau editor kode Anda:
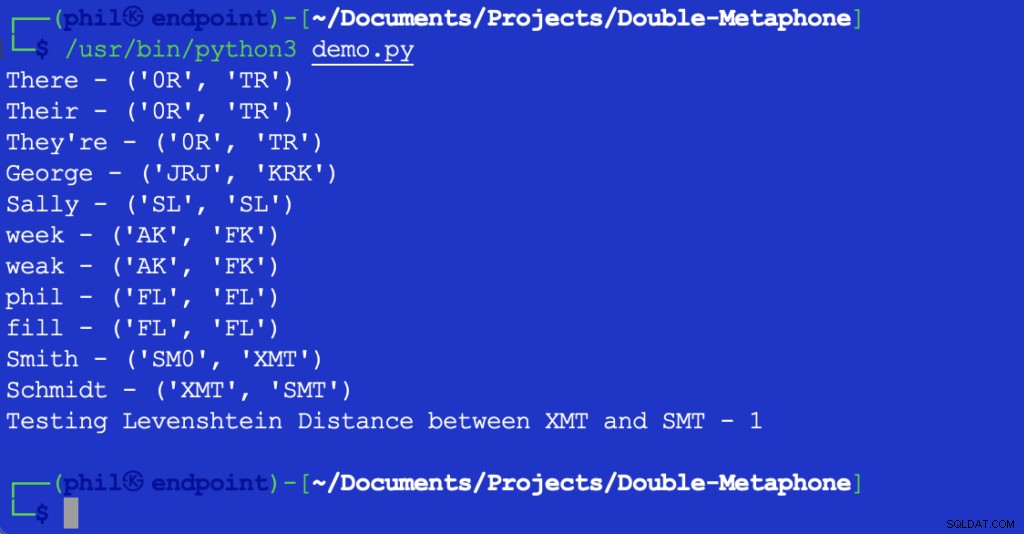
Gambar 1 – Keluaran Skrip Demo
Seperti dapat dilihat di sini, setiap kata memiliki nilai fonetik primer dan sekunder. Kata-kata yang cocok pada kedua nilai primer atau sekunder dikatakan cocok fonetik. Kata-kata yang memiliki setidaknya satu nilai fonetik, atau yang memiliki pasangan karakter pertama dalam nilai fonetik apa pun, dikatakan saling berdekatan secara fonetis.
Sebagian besar huruf yang ditampilkan sesuai dengan pengucapan bahasa Inggris mereka. X dapat sesuai dengan KS , SH , atau C . 0 sesuai dengan th suara di the atau di sana . Vokal hanya cocok di awal kata. Karena jumlah perbedaan aksen daerah yang tak terhitung, tidak mungkin untuk mengatakan bahwa kata-kata bisa menjadi kecocokan yang tepat secara objektif, bahkan jika mereka memiliki nilai fonetik yang sama.
Membandingkan Nilai Fonetik dengan Python
Ada banyak sumber online yang dapat menjelaskan cara kerja penuh dari algoritma Double Metaphone; namun, ini tidak diperlukan untuk menggunakannya karena kami lebih tertarik untuk membandingkan nilai yang dihitung, lebih dari yang kita tertarik untuk menghitung nilai. Seperti yang dinyatakan sebelumnya, jika setidaknya ada satu nilai yang sama di antara dua kata, dapat dikatakan bahwa nilai-nilai ini adalah kecocokan fonetik , dan nilai fonetik yang mirip dekat secara fonetis .
Membandingkan nilai absolut itu mudah, tetapi bagaimana string dapat ditentukan agar serupa? Meskipun tidak ada batasan teknis yang menghentikan Anda untuk membandingkan string multi-kata, perbandingan ini biasanya tidak dapat diandalkan. Tetap membandingkan satu kata.
Berapa Jarak Levenshtein?
Jarak Levenshtein antara dua string adalah jumlah karakter tunggal yang harus diubah dalam satu string agar cocok dengan string kedua. Sepasang string yang memiliki jarak Levenshtein lebih rendah lebih mirip satu sama lain daripada sepasang string yang memiliki jarak Levenshtein lebih tinggi. Jarak Levenshtein mirip dengan Jarak Hamming , tetapi yang terakhir terbatas pada string dengan panjang yang sama, karena nilai fonetik Metafon Ganda dapat bervariasi panjangnya, lebih masuk akal untuk membandingkannya menggunakan Jarak Levenshtein.
Perpustakaan Jarak Python Levenshtein
Python dapat diperluas untuk mendukung perhitungan Jarak Levenshtein melalui Modul Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Perhatikan bahwa, seperti halnya pemasangan DoubleMetaphone di atas, sintaks panggilan ke pip bisa beragam. Modul python-Levenshtein menyediakan fungsionalitas yang jauh lebih banyak daripada sekadar penghitungan Jarak Levenshtein.
Kode di bawah ini menunjukkan tes untuk perhitungan Jarak Levenshtein dengan Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Menjalankan skrip ini memberikan output berikut:
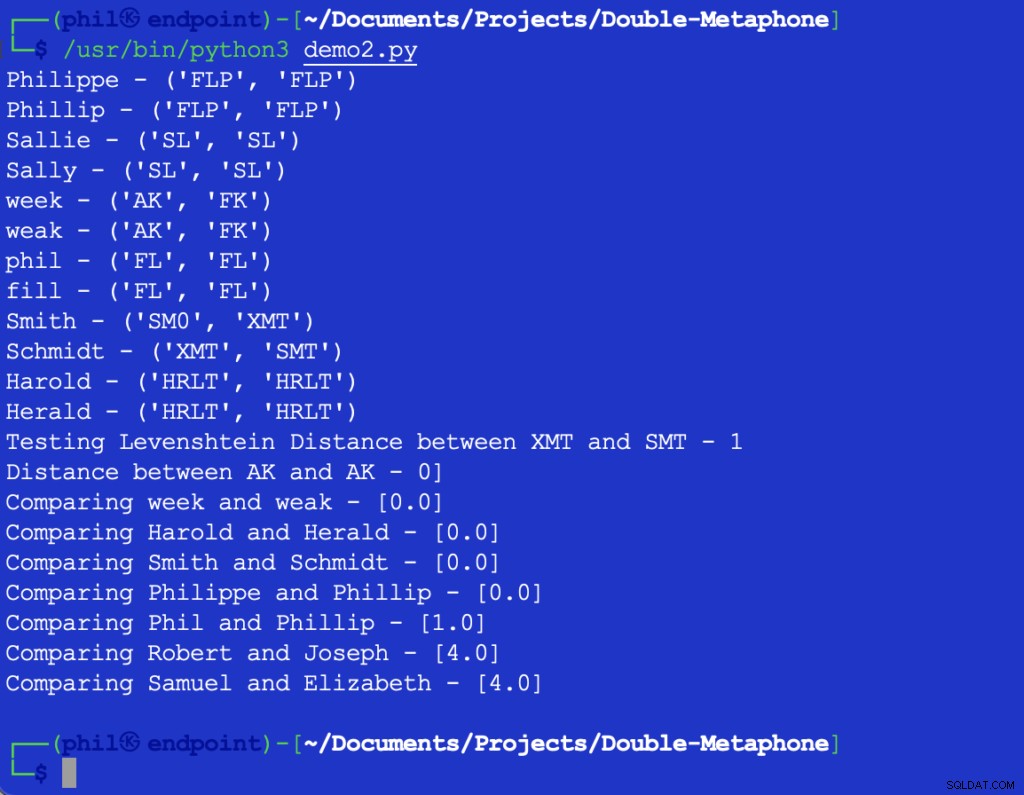
Gambar 2 – Output dari uji Jarak Levenshtein
Nilai yang dikembalikan dari 1 menunjukkan bahwa ada satu karakter di antara XMT dan SMT itu berbeda. Dalam hal ini, ini adalah karakter pertama di kedua string.
Membandingkan Metafon Ganda dengan Python
Berikut ini bukanlah perbandingan fonetis yang menjadi segalanya dan akhir segalanya. Ini hanyalah salah satu dari banyak cara untuk melakukan perbandingan seperti itu. Untuk secara efektif membandingkan kedekatan fonetik dari dua string yang diberikan, maka setiap nilai fonetik Metafon Ganda dari satu string harus dibandingkan dengan nilai fonetik Metafon Ganda yang sesuai dari string lain. Karena kedua nilai fonetik dari string tertentu diberi bobot yang sama, maka rata-rata dari nilai perbandingan ini akan memberikan perkiraan kedekatan fonetik yang cukup baik:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Dimana:
- DM1(1) :Nilai Metafon Ganda Pertama dari String 1,
- DM1(2) :Nilai Metafon Ganda Kedua dari String 1
- DM2(1) :Nilai Metafon Ganda Pertama dari String 2
- DM2(2) :Nilai Metafon Ganda Kedua dari String 2
- PN :Kedekatan Fonetik, dengan nilai yang lebih rendah lebih dekat daripada nilai yang lebih tinggi. Nilai nol menunjukkan kesamaan fonetik. Nilai tertinggi untuk ini adalah jumlah huruf dalam string terpendek.
Rumus ini rusak dalam kasus seperti Schmidt (XMT, SMT) dan Smith (SM0, XMT) di mana nilai fonetik pertama dari string pertama cocok dengan nilai fonetik kedua dari string kedua. Dalam situasi seperti itu, keduanya Schmidt dan Smith dapat dianggap serupa secara fonetis karena nilai bersama. Kode untuk fungsi kedekatan harus menerapkan rumus di atas hanya jika keempat nilai fonetiknya berbeda. Rumus ini juga memiliki kelemahan saat membandingkan string dengan panjang yang berbeda.
Catatan, tidak ada cara yang efektif untuk membandingkan string dengan panjang yang berbeda, meskipun menghitung Jarak Levenshtein antara dua string faktor perbedaan panjang string. Solusi yang mungkin adalah membandingkan kedua string hingga panjang yang lebih pendek dari dua string.
Di bawah ini adalah contoh cuplikan kode yang mengimplementasikan kode di atas, bersama dengan beberapa contoh pengujian:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Contoh kode Python memberikan output berikut:
Gambar 3 – Output dari Algoritma Kedekatan
Kumpulan sampel mengonfirmasi tren umum bahwa semakin besar perbedaan kata, semakin tinggi output Kedekatan fungsi.
Integrasi Basis Data dengan Python
Kode di atas melanggar kesenjangan fungsional antara RDBMS yang diberikan dan implementasi Metafon Ganda. Selain itu, dengan menerapkan Kedekatan fungsi dalam Python, menjadi mudah untuk diganti jika algoritma perbandingan yang berbeda lebih disukai.
Perhatikan tabel MySQL/MariaDB berikut:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
Di sebagian besar aplikasi berbasis basis data, middleware menyusun Pernyataan SQL untuk mengelola data, termasuk memasukkannya. Kode berikut akan memasukkan beberapa contoh nama ke dalam tabel ini, tetapi dalam praktiknya, kode apa pun dari aplikasi web atau desktop yang mengumpulkan data tersebut dapat melakukan hal yang sama.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Menjalankan kode ini tidak mencetak apa pun, tetapi mengisi tabel pengujian dalam database untuk digunakan daftar berikutnya. Menanyakan tabel secara langsung di klien MySQL dapat memverifikasi bahwa kode di atas berfungsi:
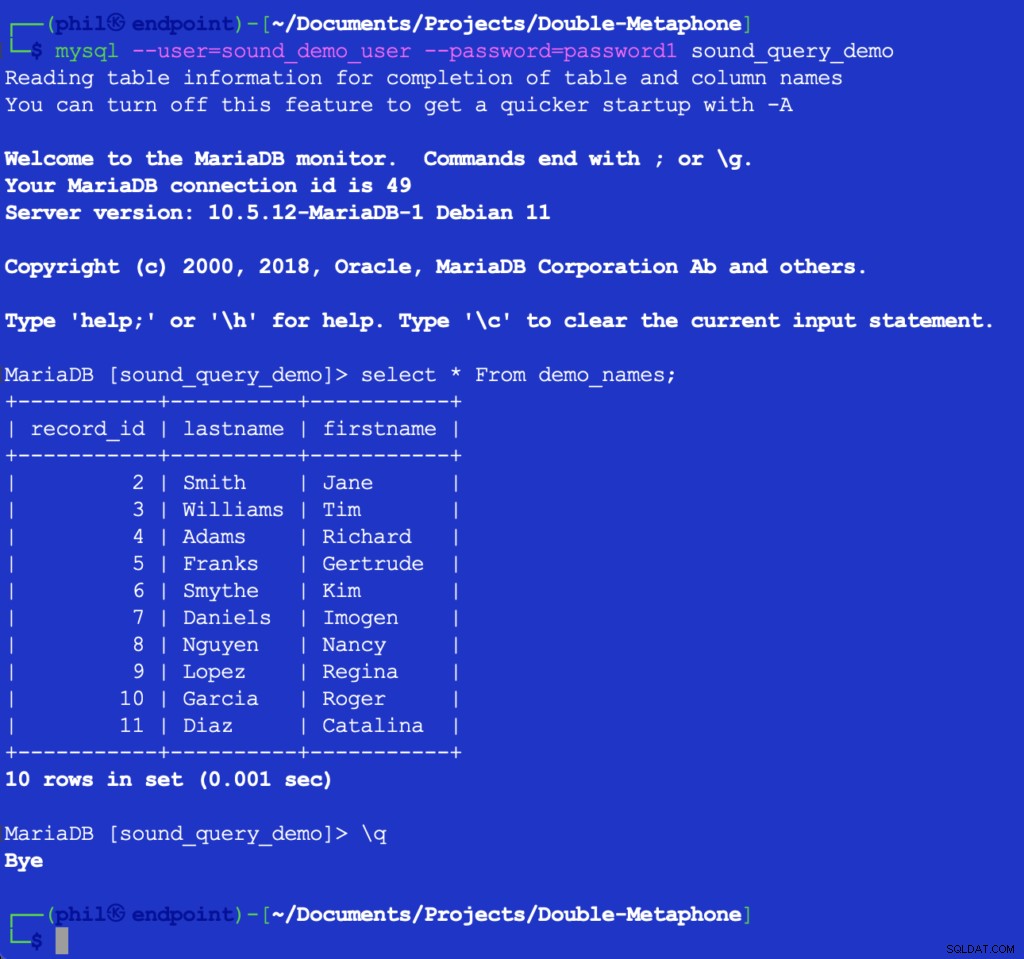
Gambar 4- Data Tabel yang Disisipkan
Kode di bawah ini akan memasukkan beberapa data perbandingan ke dalam data tabel di atas dan melakukan perbandingan kedekatan terhadapnya:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Menjalankan kode ini memberi kita output di bawah ini:
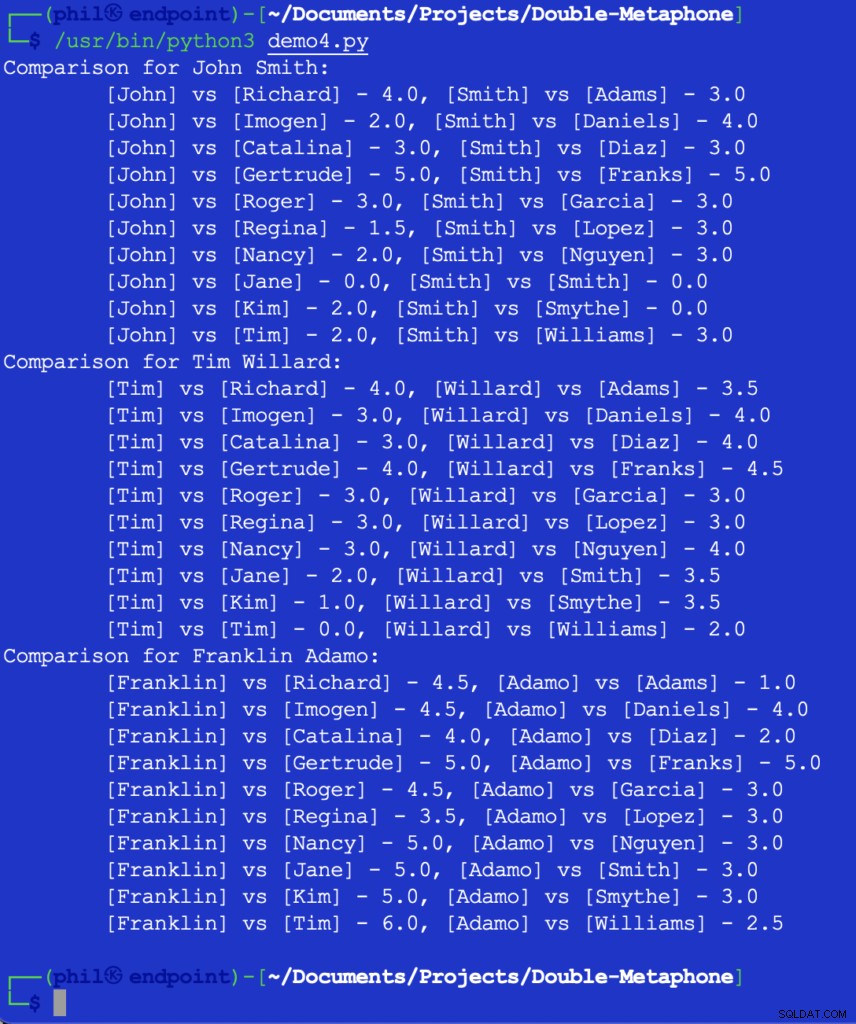
Gambar 5 – Hasil Perbandingan Kedekatan
Pada titik ini, terserah kepada pengembang untuk memutuskan apa ambang batas untuk apa yang merupakan perbandingan yang berguna. Beberapa angka di atas mungkin tampak tidak terduga atau mengejutkan, tetapi satu kemungkinan tambahan pada kode tersebut adalah JIKA pernyataan untuk menyaring nilai perbandingan yang lebih besar dari 2 .
Mungkin perlu dicatat bahwa nilai fonetik itu sendiri tidak disimpan dalam database. Ini karena mereka dihitung sebagai bagian dari kode Python dan tidak ada kebutuhan nyata untuk menyimpannya di mana saja karena akan dibuang ketika program keluar, namun, pengembang dapat menemukan nilai dalam menyimpannya di database dan kemudian mengimplementasikan perbandingan fungsi dalam database prosedur yang tersimpan. Namun, satu kelemahan utama dari hal ini adalah hilangnya portabilitas kode.
Pemikiran Terakhir tentang Kueri Data dengan Suara dengan Python
Membandingkan data dengan suara tampaknya tidak mendapatkan "cinta" atau perhatian yang mungkin didapat dengan membandingkan data dengan analisis gambar, tetapi jika suatu aplikasi harus berurusan dengan beberapa varian kata yang terdengar serupa dalam berbagai bahasa, itu bisa menjadi sangat berguna alat. Salah satu fitur yang berguna dari jenis analisis ini adalah bahwa pengembang tidak perlu menjadi ahli linguistik atau fonetik untuk menggunakan alat ini. Pengembang juga memiliki fleksibilitas tinggi dalam menentukan bagaimana data tersebut dapat dibandingkan; perbandingan dapat disesuaikan berdasarkan aplikasi atau kebutuhan logika bisnis.
Semoga bidang studi ini mendapat perhatian lebih di bidang penelitian dan akan ada alat analisis yang lebih mumpuni dan tangguh ke depan.