Tahun lalu, Andy Mallon membuat blog tentang meningkatkan ukuran kolom dari int ke bigint tanpa waktu henti. (Mengapa ini bukan operasi metadata-saja di versi modern SQL Server adalah di luar jangkauan saya, tapi itu adalah posting lain.)
Biasanya ketika kita menangani masalah ini, mereka adalah tabel yang lebar dan masif (baik dalam jumlah baris dan ukuran tipis), dan kolom yang perlu kita ubah adalah satu-satunya/kolom terdepan di kunci pengelompokan. Biasanya ada komplikasi lain yang terlibat juga – batasan kunci asing masuk, banyak indeks non-cluster, dan database sibuk yang sangat sensitif terhadap aktivitas log (karena terlibat dalam Pelacakan Perubahan, replikasi, Grup Ketersediaan, atau ketiganya ).
Untuk alasan ini, kita perlu mengambil pendekatan seperti yang dijelaskan Andy, di mana kita membangun tabel bayangan dengan skema baru, membuat pemicu untuk menjaga kedua salinan tetap sinkron, dan kemudian mengelompokkan/mengisi ulang dengan kecepatan tim itu sendiri sampai mereka siap untuk bertukar di copy sebagai real deal.
Tapi aku malas!
Ada beberapa kasus di mana Anda dapat mengubah kolom secara langsung, jika Anda mampu membayar jendela kecil waktu henti/pemblokiran, dan itu menjadi operasi yang jauh lebih sederhana. Minggu lalu satu kasus seperti itu muncul, dengan tabel lebih dari 1TB, tetapi hanya 100K baris. Hampir semua data berada di luar baris (LOB), mereka dapat membayar sedikit waktu henti jika diperlukan, dan mereka berencana untuk menonaktifkan Pelacakan Perubahan dan mengonfigurasinya kembali. Yakin bahwa membuat ulang PK berkerumun tidak harus menyentuh data LOB (banyak), saya menyarankan bahwa ini mungkin kasus di mana kita bisa menerapkan perubahan secara langsung.
Dalam skenario yang terisolasi (tidak ada kunci asing masuk, tidak ada indeks tambahan, tidak ada aktivitas yang bergantung pada pembaca log, dan tidak ada kekhawatiran tentang konkurensi), saya melakukan beberapa tes untuk melihat, dalam ruang hampa, apa yang diperlukan perubahan ini dalam hal durasi dan berdampak pada log transaksi. Pertanyaan utama yang saya tidak tahu bagaimana menjawabnya sebelumnya adalah, "Berapa biaya tambahan untuk memperbarui tabel di tempat ketika ada sejumlah besar data non-kunci?"
Saya akan mencoba mengemas banyak hal menjadi satu posting di sini. Saya melakukan banyak pengujian, dan semuanya terkait, meskipun tidak semua skenario pengujian berlaku untuk Anda. Mohon bersabar.
Tabel
Saya membuat 6 tabel, termasuk garis dasar yang hanya memiliki kolom kunci, satu tabel dengan 4K disimpan dalam baris, dan kemudian empat tabel masing-masing dengan kolom varchar(maks) yang diisi dengan jumlah data string yang bervariasi (4K, 16K, 64K, dan 256K).
CREATE TABLE dbo.withJustId( id int NOT NULL, CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob016( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)), CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob064 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)), CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob256 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)), CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id));
Saya mengisi masing-masing dengan 100.000 baris:
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() OVER (ORDER BY c1.name) DARI sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;INSERT SELECTdbo.with id DARI dbo.withJustId;INSERT dbo.withLob256 (id) PILIH id DARI dbo.withJustId;
Saya mengakui hal di atas tidak realistis; seberapa sering kita memiliki tabel yang hanya berupa pengenal + data LOB? Saya menjalankan tes lagi dengan empat kolom tambahan ini untuk memberikan halaman data non-LOB sedikit lebih banyak substansi dunia nyata:
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int NOT NULL DEFAULT (0), dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
Tabel ini hanya sedikit lebih besar dalam hal ukuran keseluruhan, tetapi peningkatan proporsional dalam jumlah data non-LOB (tidak diilustrasikan dalam bagan ini) adalah perbedaan besar tetapi tersembunyi:
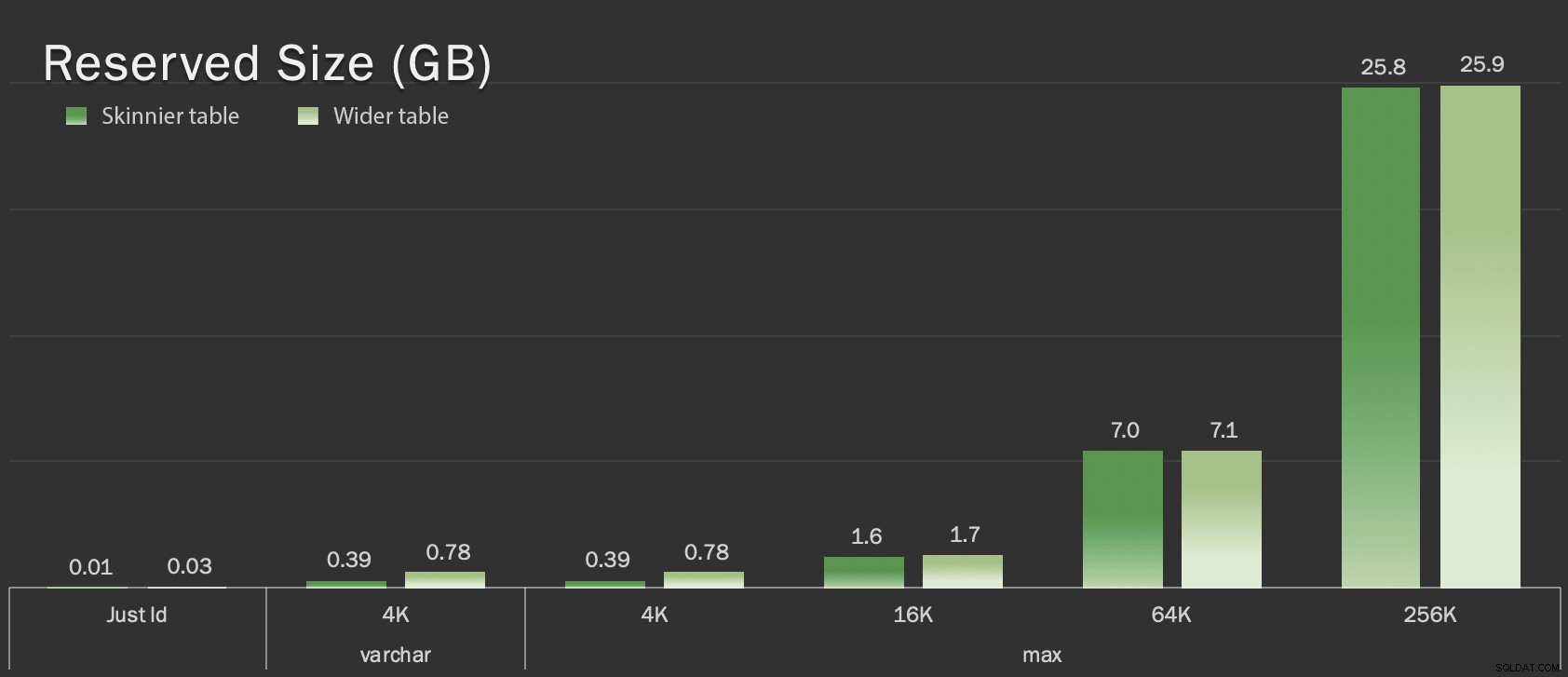 Ukuran tabel yang dicadangkan, dalam GB
Ukuran tabel yang dicadangkan, dalam GB
Tes
Kemudian saya menghitung waktu dan mengumpulkan data log untuk setiap operasi ini (dengan dan tanpa ONLINE = ON ) terhadap setiap variasi tabel:
ALTER TABLE dbo. DROP CONSTRAINT pk_; ALTER TABLE dbo. ALTER COLUMN id bigint NOT NULL; -- DENGAN (ONLINE =AKTIF); ALTER TABLE dbo. ADD CONSTRAINT pk_ PRIMARY KEY CLUSTERED (id);
Pada kenyataannya, saya menggunakan SQL dinamis untuk menghasilkan semua tes ini, sehingga saya tidak mengutak-atik skrip secara manual sebelum setiap tes.
Di posting lain, saya akan membagikan SQL dinamis yang saya gunakan untuk menghasilkan tes tersebut, dan mengumpulkan pengaturan waktu di setiap langkah.
Sebagai perbandingan, saya juga menguji metode Andy (walaupun tanpa batching, dan hanya pada tabel versi kurus):
CREATE TABLE dbo._copy ( id bigint NOT NULL -- <, kolom ekstradata bila relevan> CONSTRAINT pk_copy_ PRIMARY KEY CLUSTERED (id)); INSERT dbo._copy SELECT * FROM dbo.; EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';EXEC sys.sp_rename N'dbo._copy', N'dbo.' , N'OBJECT';
Saya melewatkan tabel yang lebih luas di sini; Saya tidak ingin memperkenalkan kompleksitas pengkodean dan pengukuran operasi batch. Titik sakit yang jelas di sini adalah bahwa, tidak seperti mengubah kolom di tempat, dengan metode bayangan Anda harus menyalin setiap byte dari data LOB itu. Batching dapat meminimalkan dampak besar dari mencoba melakukan itu dalam satu transaksi, tetapi semua pengocokan itu pada akhirnya harus dilakukan kembali di hilir. Batching di sumber tidak dapat sepenuhnya mengontrol seberapa banyak yang akan merugikan di tujuan.
Hasilnya
Hasil pertama yang akan saya tunjukkan hanyalah durasi rata-rata untuk perubahan di tempat, untuk semua 12 konfigurasi tabel, dan dengan dan tanpa ONLINE = ON :
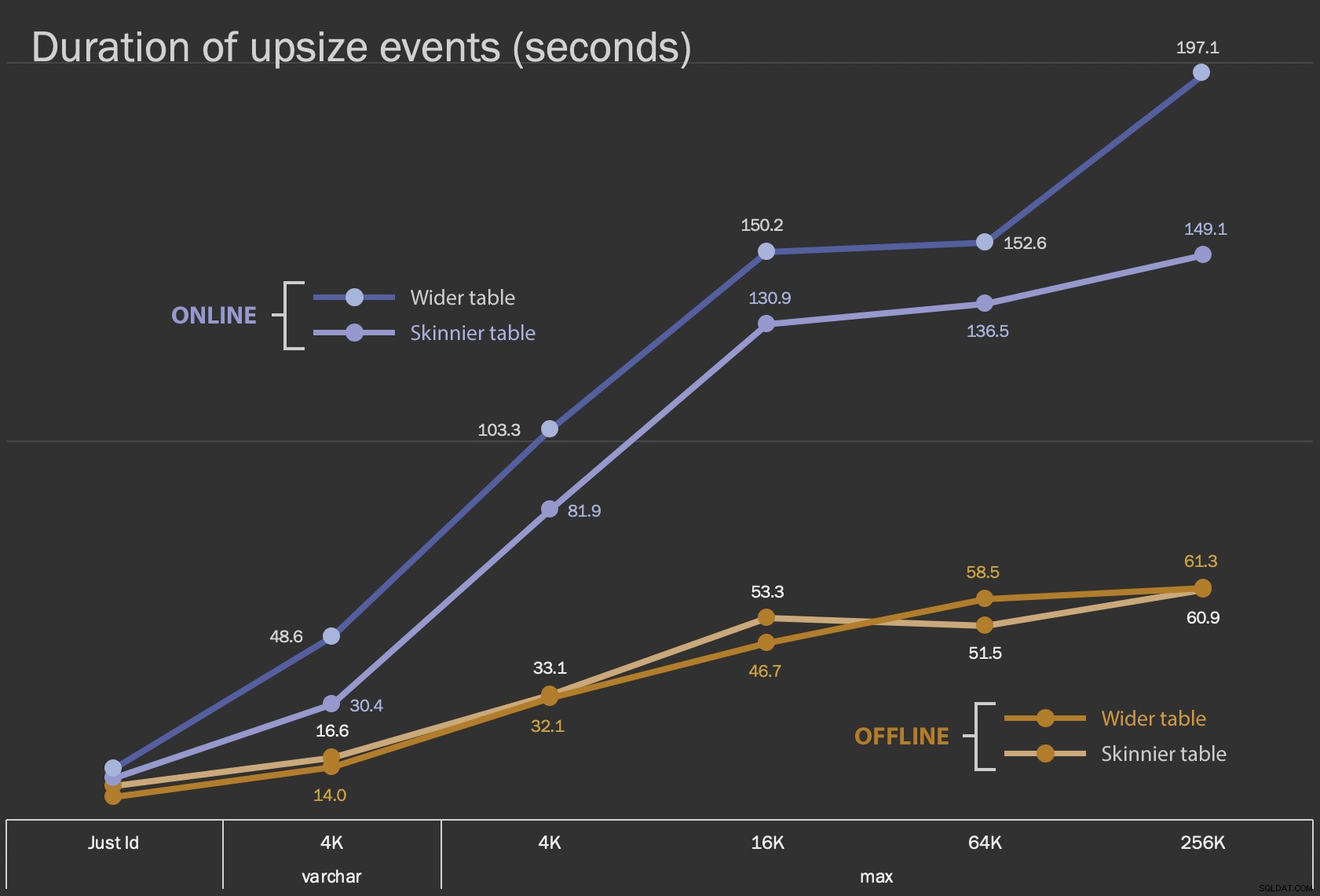 Durasi, dalam detik, untuk mengubah kolom di tempat
Durasi, dalam detik, untuk mengubah kolom di tempat
Melakukan ini sebagai operasi online membutuhkan lebih banyak waktu (200 detik dalam kasus terburuk), tetapi tidak memblokir pengguna. Itu tampaknya meningkat seiring ukuran, tetapi tidak cukup linier. Melakukan operasi ini secara offline menyebabkan pemblokiran, tetapi jauh lebih cepat, dan tidak berubah secara drastis saat tabel menjadi lebih besar (bahkan pada ukuran terbesar, ini masih terjadi dalam waktu sekitar satu menit).
Membandingkan operasi di tempat ini dengan operasi swap dan drop sulit menggunakan diagram garis karena perbedaan skala yang sangat besar. Sebagai gantinya saya akan menunjukkan diagram batang horizontal untuk durasi yang terlibat dengan setiap konfigurasi tabel. Saat pembuatan ulang lebih cepat, saya akan mengecat latar belakang baris itu dengan warna hijau; ketika lebih lambat (atau jatuh di antara metode offline dan online), saya mungkin tidak perlu melakukannya, tetapi saya akan mengecat latar belakang baris itu dengan warna merah.
Ukuran LOB | Pendekatan | Konfigurasi tabel Durasi (detik) Hanya Id ALTER Offline Meja lebih kurus (10 MB) 8,8 Tabel lebih lebar (30 MB) 6.3 ALTER Online Meja lebih kurus 11.0 Tabel lebih lebar 13.6 Buat ulang Meja lebih kurus 3.4 varchar 4K Luring Meja lebih kurus (390 MB) 16.6 Tabel lebih lebar (780 MB) 14.0 Online Meja lebih kurus 30.4 Tabel lebih lebar 48.6 Buat ulang Meja lebih kurus 1.290,0 maks 4rb Luring Meja lebih kurus (390 MB) 33.1 Tabel lebih lebar (780 MB) 32.1 Online Meja lebih kurus 81.9 Tabel lebih lebar 103,3 Buat ulang Meja lebih kurus 28.9 maks 16rb Luring Meja lebih kurus (1,6 GB) 53,3 Tabel lebih lebar (1,7 GB) 46,7 Online Meja lebih kurus 130.9 Tabel lebih lebar 150.2 Buat ulang Meja lebih kurus 81,8 maks 64rb Luring Meja lebih kurus (7,0 GB) 51,5 Tabel lebih lebar (7,1 GB) 58.5 Online Meja lebih kurus 136,5 Tabel lebih lebar 152.6 Buat ulang Meja lebih kurus 226,5 maks 256rb Luring Meja lebih kurus (25,8 GB) 60,9 Tabel lebih lebar (25,9 GB) 61,3 Online Meja lebih kurus 149.1 Tabel lebih lebar 197.1 Buat ulang Meja lebih kurus 1,576.7
Ini adalah guncangan yang tidak adil pada metode Andy, karena – di dunia nyata – Anda tidak akan melakukan seluruh operasi itu dalam satu kesempatan. Saya tidak menunjukkan penggunaan log transaksi di sini untuk singkatnya, tetapi akan lebih mudah untuk mengontrolnya melalui batching dalam operasi berdampingan juga. Meskipun pendekatannya membutuhkan lebih banyak pekerjaan di awal, ini jauh lebih aman dalam hal waktu henti dan/atau pemblokiran. Tetapi Anda dapat melihat dalam kasus di mana Anda memiliki banyak data off-row dan dapat melakukan pemadaman singkat, bahwa mengubah kolom secara langsung jauh lebih tidak menyakitkan. "Terlalu besar untuk diubah di tempat" bersifat subjektif dan dapat menghasilkan hasil yang berbeda tergantung pada apa artinya "besar". Sebelum melakukan pendekatan, mungkin masuk akal untuk menguji perubahan terhadap salinan yang wajar, karena operasi di tempat mungkin mewakili pertukaran yang dapat diterima.
Kesimpulan
Saya tidak menulis ini untuk berdebat dengan Andy. Pendekatan dalam posting asli adalah suara, 100% dapat diandalkan, dan kami menggunakannya sepanjang waktu. Namun, ketika kekuatan kasar dinilai lebih dari presisi bedah, dan terutama jika Anda dapat mengambil sedikit waktu henti, mungkin ada nilai dalam pendekatan yang lebih sederhana untuk bentuk tabel tertentu.



