Saya sudah mulai menulis tentang alat (pglupgrade) yang saya kembangkan untuk melakukan pemutakhiran otomatis klaster PostgreSQL dengan waktu henti hampir nol. Dalam postingan ini, saya akan berbicara tentang alat dan mendiskusikan detail desainnya.
Anda dapat memeriksa bagian pertama dari seri ini di sini: Peningkatan Otomatis Cluster PostgreSQL Hampir Nol Waktu Henti di Cloud (Bagian I).

Alat ini ditulis dalam Ansible. Saya memiliki pengalaman sebelumnya bekerja dengan Ansible, dan saat ini saya juga bekerja dengannya di Kuadran ke-2, itulah sebabnya itu adalah pilihan yang nyaman bagi saya. Meskipun demikian, Anda dapat menerapkan logika pemutakhiran waktu henti minimal, yang akan dijelaskan nanti dalam posting ini, dengan alat otomatisasi favorit Anda.
Bacaan lebih lanjut:Entri blog Ansible Mencintai PostgreSQL , Planet PostgreSQL di Galaksi Ansible dan presentasi Mengelola PostgreSQL dengan Ansible.
Pglupgrade Playbook
Di Ansible, buku pedoman adalah skrip utama yang dikembangkan untuk mengotomatisasi proses seperti penyediaan instans cloud dan peningkatan klaster basis data. Playbook dapat berisi satu atau beberapa permainan . Playbook juga dapat berisi variabel , peran , dan penangan jika ditentukan.
Alat ini terdiri dari dua buku pedoman utama. Buku pedoman pertama adalah provision.yml yang mengotomatiskan proses untuk membuat mesin Linux di cloud, sesuai dengan spesifikasi (Ini adalah buku pedoman opsional yang ditulis hanya untuk menyediakan instance cloud dan tidak terkait langsung dengan peningkatan ). Buku pedoman kedua (dan utama) adalah pglupgrade.yml yang mengotomatiskan proses peningkatan klaster basis data.
Playbook Pglupgrade memiliki delapan permainan untuk mengatur peningkatan. Setiap pemutaran, gunakan satu file konfigurasi (config.yml ), melakukan beberapa tugas pada host atau grup host yang ditentukan di file inventaris host host (host.ini ).
File Inventaris
File inventaris memungkinkan Ansible mengetahui server mana yang perlu disambungkan menggunakan SSH, informasi koneksi apa yang diperlukan, dan secara opsional variabel mana yang terkait dengan server tersebut. Di bawah ini Anda dapat melihat contoh file inventaris, yang telah digunakan untuk menjalankan pemutakhiran klaster otomatis untuk salah satu studi kasus yang dirancang untuk alat tersebut. Kami akan membahas studi kasus ini di postingan berikutnya dari seri ini.
[primer lama]54.171.211.188[primer baru]54.246.183.100[lama-siaga]54.77.249.8154.154.49.180[siaga baru:anak-anak]siaga lama[pgbouncer]54.154.49.180File Inventaris (
host.ini)File inventaris sampel berisi lima host di bawah lima grup tuan rumah yang menyertakan
old-primary,new-primary,old-standbys,new-standbysdanpgbouncer. Sebuah server dapat dimiliki oleh lebih dari satu grup. Misalnya,old-standbysadalah grup yang berisinew-standbysgroup, yang berarti host yang didefinisikan di bawahold-standbysgrup (54.77.249.81 dan 54.154.49.180) juga termasuk dalamnew-standbyskelompok. Dengan kata lain,new-standbysgrup diwarisi dari (anak-anak)old-standbyskelompok. Hal ini dicapai dengan menggunakan:childrenkhusus akhiran.Setelah file inventaris siap, Playbook Ansible dapat dijalankan melalui
ansible-playbookperintah dengan menunjuk ke file inventaris (jika file inventaris tidak berada di lokasi default jika tidak maka akan menggunakan file inventaris default) seperti yang ditunjukkan di bawah ini:$ ansible-playbook -i hosts.ini pglupgrade.ymlMenjalankan playbook yang Memungkinkan
File Konfigurasi
Playbook Pglupgrade menggunakan file konfigurasi (
config.yml) yang memungkinkan pengguna menentukan nilai untuk variabel peningkatan logis.Seperti yang ditunjukkan di bawah ini,
config.ymlmenyimpan sebagian besar variabel khusus PostgreSQL yang diperlukan untuk menyiapkan cluster PostgreSQL sepertipostgres_old_datadirdanpostgres_new_datadiruntuk menyimpan jalur direktori data PostgreSQL untuk versi PostgreSQL lama dan baru;postgres_new_confdiruntuk menyimpan jalur direktori konfigurasi PostgreSQL untuk versi PostgreSQL yang baru;postgres_old_dsndanpostgres_new_dsnuntuk menyimpan string koneksi untukpglupgrade_useruntuk dapat terhubung kepglupgrade_databasedari server utama baru dan lama. String koneksi itu sendiri terdiri dari variabel yang dapat dikonfigurasi sehingga pengguna (pglupgrade_user) dan database (pglupgrade_database) informasi dapat diubah untuk kasus penggunaan yang berbeda.ansible_user:adminpglupgrade_user:pglupgradepglupgrade_pass:pglupgrade123pglupgrade_database:postgresreplica_user:postgresreplica_pass:""pgbouncer_user:pgbouncerpostgres_old_version:9.5postgres_new_version:9.6subscription_name_name:upgradereplication} primer'][0]}} pengguna {{pglupgrade_user}}"postgres_new_dsn:"dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} pengguna={{pglupgrade_user}}" postgres_old_datadir:"/var/lib/postgresql/{{postgres_old_version}}/main" postgres_new_datadir:"/var/lib/postgresql/{{postgres_new_version}}/main"postgres_new_confdir:"/etc/postgresql/{{postgres_new_version}}/ utama"
File Konfigurasi (config.yml )
Sebagai langkah kunci untuk setiap peningkatan, informasi versi PostgreSQL dapat ditentukan untuk versi saat ini (postgres_old_version ) dan versi yang akan ditingkatkan ke (postgres_new_version ). Berbeda dengan replikasi fisik di mana replikasi adalah salinan sistem pada tingkat byte/blok, replikasi logis memungkinkan replikasi selektif di mana replikasi dapat menyalin data logis termasuk database tertentu dan tabel dalam database tersebut. Untuk alasan ini, config.yml memungkinkan konfigurasi database mana yang akan direplikasi melalui pglupgrade_database variabel. Selain itu, pengguna replikasi logis perlu memiliki hak replikasi, itulah sebabnya pglupgrade_user variabel harus ditentukan dalam file konfigurasi. Ada variabel lain yang terkait dengan kerja internal pglogical seperti subscription_name dan replication_set yang digunakan dalam peran pglogical.
Desain Ketersediaan Tinggi dari Alat Pglupgrade
Alat Pglupgrade dirancang untuk memberikan fleksibilitas dalam hal properti Ketersediaan Tinggi (HA) kepada pengguna untuk kebutuhan sistem yang berbeda. initial_standbys variabel (lihat config.yml ) adalah kunci untuk menetapkan properti HA dari cluster saat operasi peningkatan sedang berlangsung.
Misalnya, jika initial_standbys diatur ke 1 (dapat diatur ke nomor berapa pun yang memungkinkan kapasitas cluster), itu berarti akan ada 1 standby yang dibuat di cluster yang ditingkatkan bersama dengan master sebelum replikasi dimulai. Dengan kata lain, jika Anda memiliki 4 server dan Anda menyetel initial_standbys ke 1, Anda akan memiliki 1 server utama dan 1 server siaga di versi baru yang ditingkatkan, serta 1 server utama dan 1 server siaga di versi lama.
Opsi ini memungkinkan untuk menggunakan kembali server yang ada saat peningkatan masih berlangsung. Dalam contoh 4 server, server utama dan server siaga lama dapat dibangun kembali sebagai 2 server siaga baru setelah replikasi selesai.
Saat initial_standbys variabel disetel ke 0, tidak akan ada server siaga awal yang dibuat di cluster baru sebelum replikasi dimulai.
Jika initial_standbys konfigurasi terdengar membingungkan, jangan khawatir. Ini akan dijelaskan lebih baik di posting blog berikutnya ketika kita membahas dua studi kasus yang berbeda.
Terakhir, file konfigurasi memungkinkan untuk menentukan grup server lama dan baru. Ini dapat diberikan dalam dua cara. Pertama, jika ada cluster yang ada, alamat IP server (bisa berupa server bare-metal atau virtual ) harus dimasukkan ke hosts.ini file dengan mempertimbangkan properti HA yang diinginkan saat mengupgrade operasi.
Cara kedua adalah menjalankan provision.yml playbook (inilah cara saya menyediakan instance cloud, tetapi Anda dapat menggunakan skrip penyediaan Anda sendiri atau menyediakan instance secara manual ) untuk menyediakan server Linux kosong di cloud (instance AWS EC2) dan memasukkan alamat IP server ke hosts.ini mengajukan. Apa pun itu, config.yml akan mendapatkan informasi host melalui hosts.ini berkas.
Alur Kerja Proses Upgrade
Setelah menjelaskan file konfigurasi (config.yml ) yang digunakan oleh pglupgrade playbook, kami dapat menjelaskan alur kerja proses peningkatan.
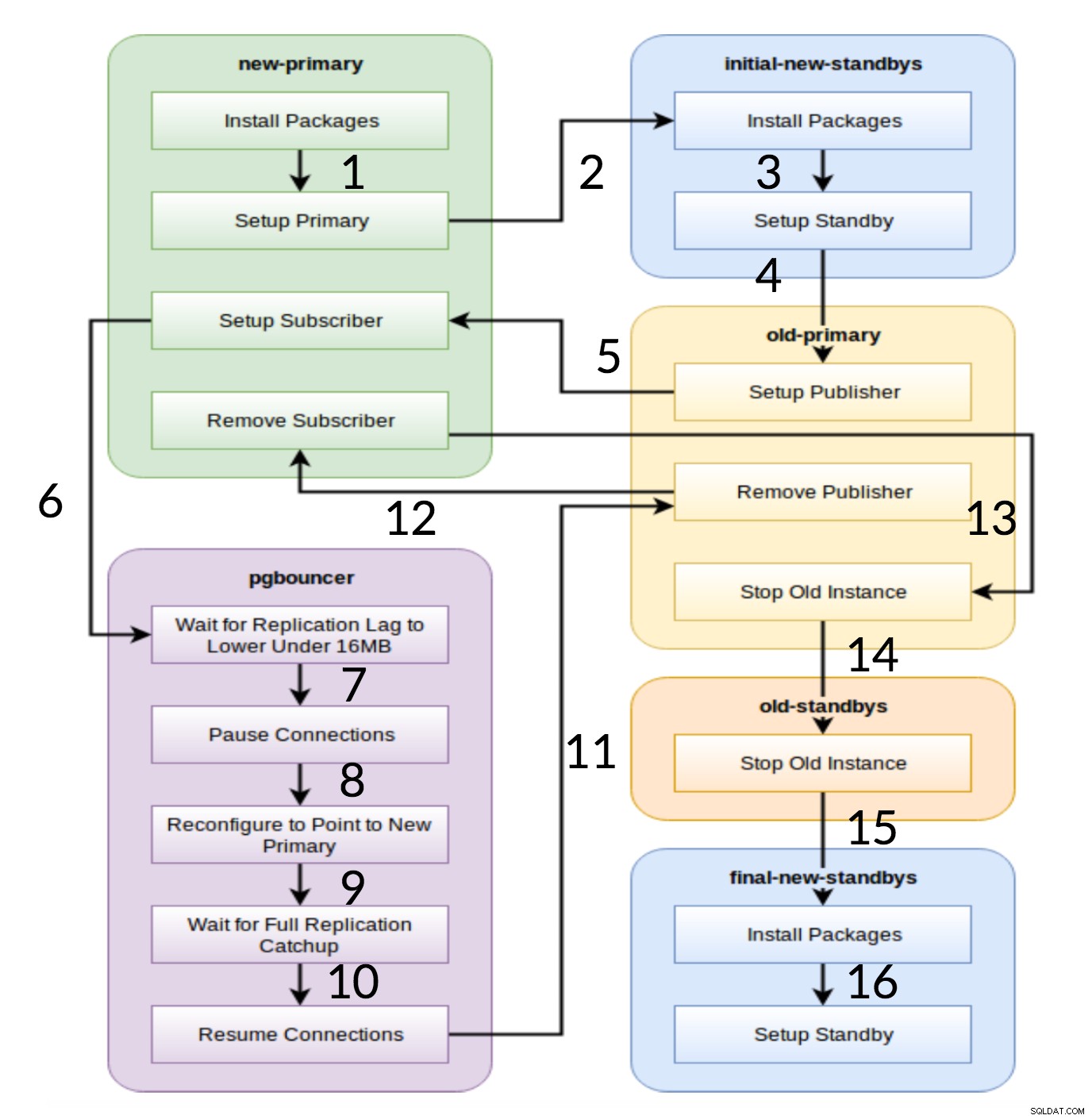
Pglupgrade Alur Kerja
Seperti yang terlihat dari diagram di atas, ada enam grup server yang dibangkitkan pada awalnya berdasarkan konfigurasi (keduanya hosts.ini dan config.yml ). new-primary dan old-primary grup akan selalu memiliki satu server, pgbouncer grup dapat memiliki satu atau lebih server dan semua grup siaga dapat memiliki nol atau lebih server di dalamnya. Dari segi implementasi, seluruh proses dibagi menjadi delapan langkah. Setiap langkah sesuai dengan permainan di buku pedoman pglupgrade, yang melakukan tugas yang diperlukan pada grup host yang ditetapkan. Proses peningkatan dijelaskan melalui permainan berikut:
- Bangun host berdasarkan konfigurasi: Permainan persiapan yang membangun grup internal server berdasarkan konfigurasi. Hasil dari permainan ini (dikombinasikan dengan
hosts.iniisi) adalah enam grup server (diilustrasikan dengan warna berbeda dalam diagram alur kerja) yang akan digunakan oleh tujuh drama berikut. - Siapkan cluster baru dengan standby awal: Menyiapkan cluster PostgreSQL kosong dengan standby utama dan awal baru (jika ada yang ditentukan). Ini memastikan bahwa tidak ada sisa instalasi PostgreSQL dari penggunaan sebelumnya.
- Ubah primer lama untuk mendukung replikasi logis: Menginstal ekstensi pglogical. Kemudian atur penerbit dengan menambahkan semua tabel dan urutan ke replikasi.
- Replikasi ke sekolah utama baru: Mengatur pelanggan pada master baru yang bertindak sebagai pemicu untuk memulai replikasi logis. Drama ini selesai mereplikasi data yang ada dan mulai mengejar apa yang telah berubah sejak dimulainya replikasi.
- Beralih pgbouncer (dan aplikasi) ke utama baru: Saat jeda replikasi menyatu ke nol, jeda pgbouncer untuk mengganti aplikasi secara bertahap. Kemudian ia mengarahkan konfigurasi pgbouncer ke primer baru dan menunggu hingga perbedaan replikasi menjadi nol. Akhirnya, pgbouncer dilanjutkan dan semua transaksi menunggu disebarkan ke primer baru dan mulai memproses di sana. Siaga awal sudah digunakan dan membalas permintaan baca.
- Bersihkan penyiapan replikasi antara primer lama dan primer baru: Mengakhiri koneksi antara server utama lama dan baru. Karena semua aplikasi dipindahkan ke server utama baru dan pemutakhiran selesai, replikasi logis tidak lagi diperlukan. Replikasi antara server utama dan server siaga dilanjutkan dengan replikasi fisik.
- Hentikan cluster lama: Layanan Postgres dihentikan di host lama untuk memastikan tidak ada aplikasi yang dapat terhubung lagi.
- Konfigurasi ulang sisa siaga untuk primer baru: Membangun kembali standby lain jika ada host yang tersisa selain standby awal. Dalam studi kasus kedua, tidak ada server siaga yang tersisa untuk dibangun kembali. Langkah ini memberi kesempatan untuk membangun kembali server utama lama sebagai siaga baru jika diarahkan ke grup siaga baru di hosts.ini. Penggunaan kembali server yang ada (bahkan server utama lama) dicapai dengan menggunakan desain konfigurasi siaga dua langkah dari alat pglupgrade. Pengguna dapat menentukan server mana yang harus menjadi standby dari cluster baru sebelum upgrade, dan mana yang harus standby setelah upgrade.
Kesimpulan
Dalam posting ini, kami membahas detail implementasi dan desain ketersediaan tinggi dari alat pglupgrade. Dalam melakukannya, kami juga menyebutkan beberapa konsep kunci pengembangan Ansible (yaitu, buku pedoman, inventaris, dan file konfigurasi) menggunakan alat sebagai contoh. Kami mengilustrasikan alur kerja proses peningkatan dan meringkas bagaimana setiap langkah bekerja dengan permainan yang sesuai. Kami akan terus menjelaskan pglupgrade dengan menunjukkan studi kasus di postingan yang akan datang dari seri ini.
Terima kasih telah membaca!