Saya rasa semua orang sudah mengetahui pendapat saya tentang MERGE dan mengapa saya menjauhinya. Tapi inilah pola (anti-) lain yang saya lihat di semua tempat ketika orang ingin melakukan upsert (perbarui satu baris jika ada dan masukkan jika tidak):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Ini terlihat seperti alur yang cukup logis yang mencerminkan cara kita memikirkan hal ini dalam kehidupan nyata:
- Apakah sudah ada baris untuk kunci ini?
- YA :Oke, perbarui baris itu.
- TIDAK :Oke, lalu tambahkan.
Tapi ini sia-sia.
Menemukan baris untuk mengonfirmasi keberadaannya, hanya perlu menemukannya lagi untuk memperbaruinya, melakukan dua kali pekerjaan untuk apa-apa. Bahkan jika kuncinya diindeks (yang saya harap selalu demikian). Jika saya memasukkan logika ini ke dalam diagram alur dan mengaitkan, pada setiap langkah, jenis operasi yang harus terjadi dalam database, saya akan memiliki ini:
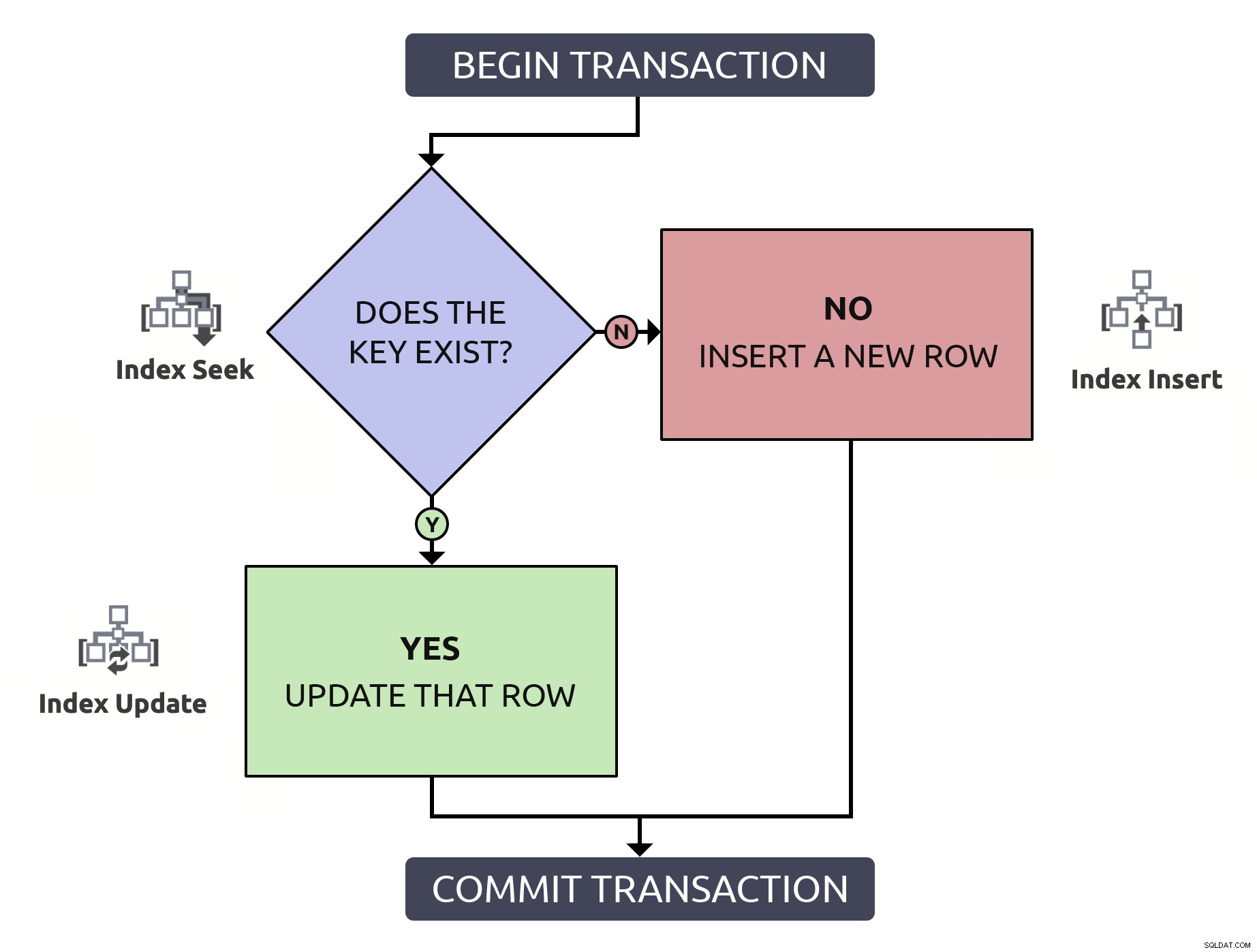 Perhatikan bahwa semua jalur akan dikenakan dua operasi indeks.
Perhatikan bahwa semua jalur akan dikenakan dua operasi indeks.
Lebih penting lagi, selain kinerja, kecuali Anda berdua menggunakan transaksi eksplisit dan meningkatkan tingkat isolasi, banyak hal bisa salah jika baris belum ada:
- Jika kunci ada dan dua sesi mencoba memperbarui secara bersamaan, keduanya akan berhasil memperbarui (seseorang akan "menang"; "pecundang" akan mengikuti dengan perubahan yang melekat, yang mengarah ke "pembaruan yang hilang"). Ini bukan masalah tersendiri, dan begitulah seharusnya mengharapkan sistem dengan konkurensi untuk bekerja. Paul White berbicara tentang mekanisme internal secara lebih rinci di sini, dan Martin Smith berbicara tentang beberapa nuansa lain di sini.
- Jika kunci tidak ada, tetapi kedua sesi melewati pemeriksaan keberadaan dengan cara yang sama, apa pun bisa terjadi saat keduanya mencoba menyisipkan:
- kebuntuan karena kunci yang tidak kompatibel;
- meningkatkan kesalahan pelanggaran utama yang seharusnya tidak terjadi; atau,
- masukkan nilai kunci duplikat jika kolom tersebut tidak dibatasi dengan benar.
Yang terakhir itu yang terburuk, IMHO, karena itu yang berpotensi mengkorupsi data . Kebuntuan dan pengecualian dapat ditangani dengan mudah dengan hal-hal seperti penanganan kesalahan, XACT_ABORT , dan coba lagi logika, bergantung pada seberapa sering Anda mengharapkan tabrakan. Tetapi jika Anda terbuai dengan rasa aman bahwa IF EXISTS check melindungi Anda dari duplikat (atau pelanggaran utama), itu adalah kejutan yang menunggu untuk terjadi. Jika Anda mengharapkan kolom berfungsi seperti kunci, buatlah menjadi resmi dan tambahkan batasan.
"Banyak orang mengatakan..."
Dan Guzman berbicara tentang kondisi balapan lebih dari satu dekade lalu di Conditional INSERT/UPDATE Race Condition dan kemudian di "UPSERT" Race Condition With MERGE.
Michael Swart juga telah membahas topik ini beberapa kali:
- Mythbusting:Concurrent Update/Insert Solutions – di mana dia mengakui bahwa membiarkan logika awal di tempatnya dan hanya meningkatkan level isolasi baru saja mengubah pelanggaran kunci menjadi kebuntuan;
- Hati-hati dengan Pernyataan Penggabungan – di mana dia memeriksa antusiasmenya tentang
MERGE; dan, - Yang Harus Dihindari Jika Anda Ingin Menggunakan MERGE – di mana dia menegaskan sekali lagi bahwa masih banyak alasan yang sah untuk terus menghindari
MERGE.
Pastikan Anda juga membaca semua komentar di ketiga postingan.
Solusinya
Saya telah memperbaiki banyak kebuntuan dalam karir saya hanya dengan menyesuaikan dengan pola berikut (buang cek yang berlebihan, bungkus urutan dalam transaksi, dan lindungi akses tabel pertama dengan penguncian yang sesuai):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Mengapa kita membutuhkan dua petunjuk? Bukankah UPDLOCK cukup?
UPDLOCKdigunakan untuk melindungi dari kebuntuan konversi di pernyataan level (biarkan sesi lain menunggu alih-alih mendorong korban untuk mencoba lagi).SERIALIZABLEdigunakan untuk melindungi dari perubahan pada data pokok selama transaksi (pastikan baris yang tidak ada tetap tidak ada).
Ini sedikit lebih banyak kode, tetapi 1000% lebih aman, dan bahkan dalam terburuk case (baris belum ada), ia melakukan hal yang sama dengan anti-pola. Dalam kasus terbaik, jika Anda memperbarui baris yang sudah ada, akan lebih efisien untuk hanya menemukan baris itu sekali. Menggabungkan logika ini dengan operasi tingkat tinggi yang harus terjadi dalam database, ini sedikit lebih sederhana:
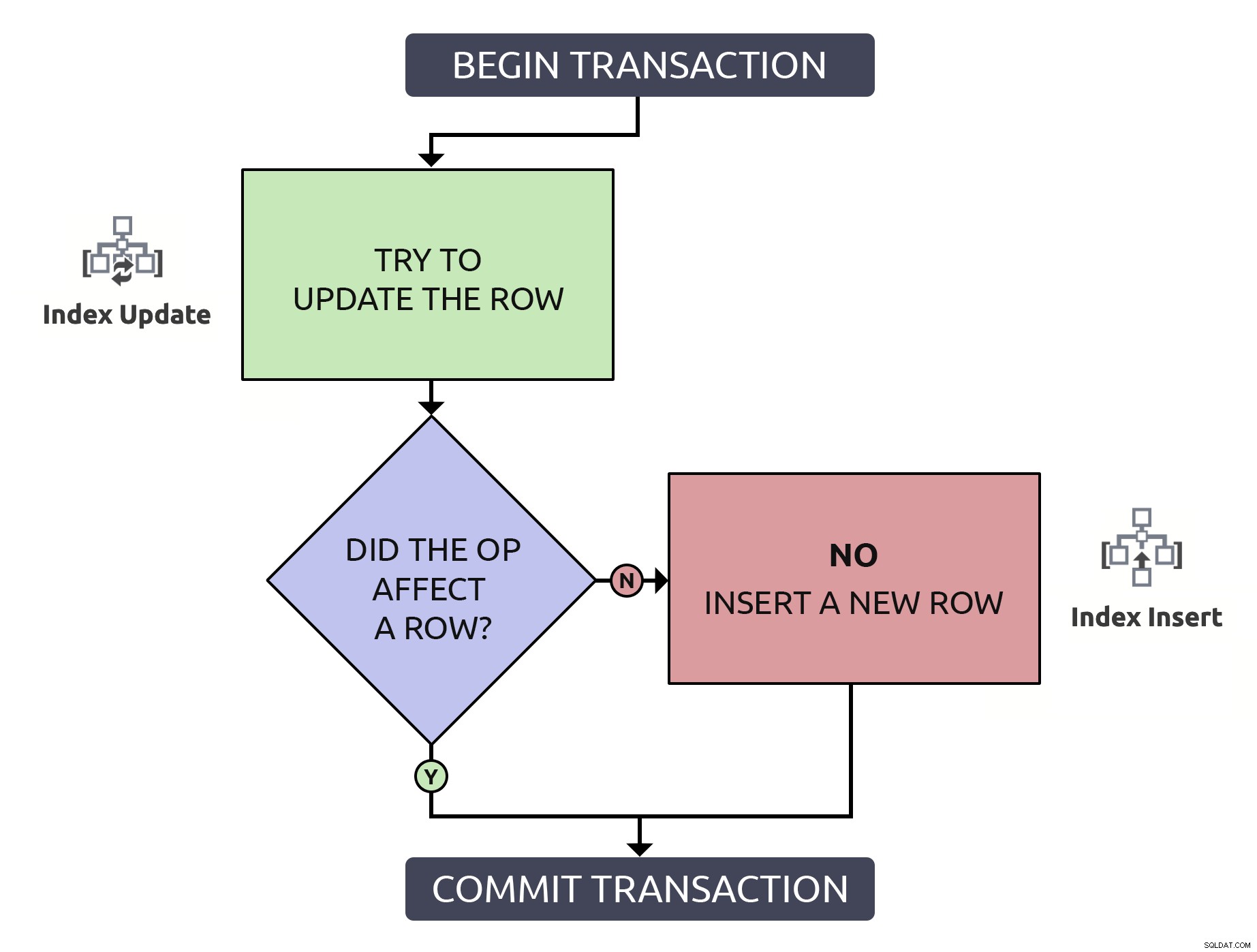 Dalam kasus ini, satu jalur hanya menimbulkan satu operasi indeks.
Dalam kasus ini, satu jalur hanya menimbulkan satu operasi indeks.
Tapi sekali lagi, selain performa:
- Jika kunci ada dan dua sesi mencoba memperbaruinya secara bersamaan, keduanya akan bergantian dan berhasil memperbarui baris , seperti sebelumnya.
- Jika kunci tidak ada, satu sesi akan "menang" dan menyisipkan baris . Yang lain harus menunggu sampai kunci dilepaskan bahkan untuk memeriksa keberadaan, dan dipaksa untuk memperbarui.
Dalam kedua kasus tersebut, penulis yang memenangkan perlombaan kehilangan data mereka karena apa pun yang diperbarui oleh "pecundang" setelah mereka.
Perhatikan bahwa throughput keseluruhan pada sistem yang sangat bersamaan mungkin menderita, tetapi itu adalah pertukaran yang harus Anda lakukan. Bahwa Anda mendapatkan banyak korban kebuntuan atau kesalahan pelanggaran utama, tetapi terjadi dengan cepat, bukanlah metrik kinerja yang baik. Beberapa orang akan senang melihat semua pemblokiran dihapus dari semua skenario, tetapi beberapa di antaranya memblokir yang benar-benar Anda inginkan untuk integritas data.
Tetapi bagaimana jika pembaruan tidak mungkin dilakukan?
Jelas bahwa solusi di atas mengoptimalkan pembaruan, dan mengasumsikan bahwa kunci yang Anda coba tulis sudah ada di tabel sesering mungkin. Jika Anda lebih suka mengoptimalkan penyisipan, mengetahui atau menebak bahwa penyisipan akan lebih mungkin dilakukan daripada pembaruan, Anda dapat membalik logikanya dan tetap memiliki operasi penyisipan yang aman:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Ada juga pendekatan "lakukan saja", di mana Anda menyisipkan secara membabi buta dan membiarkan tabrakan memunculkan pengecualian pada pemanggil:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Biaya pengecualian tersebut sering kali lebih besar daripada biaya pemeriksaan terlebih dahulu; Anda harus mencobanya dengan perkiraan hit/miss rate yang kurang lebih akurat. Saya menulis tentang ini di sini dan di sini.
Bagaimana dengan menyisipkan beberapa baris?
Di atas berkaitan dengan keputusan penyisipan/pembaruan tunggal, tetapi Justin Pealing bertanya apa yang harus dilakukan ketika Anda memproses beberapa baris tanpa mengetahui mana yang sudah ada?
Dengan asumsi Anda mengirim satu set baris menggunakan sesuatu seperti parameter bernilai tabel, Anda akan memperbarui menggunakan gabungan, dan kemudian menyisipkan menggunakan NOT EXISTS, tetapi polanya masih akan setara dengan pendekatan pertama di atas:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Jika Anda mendapatkan beberapa baris bersama dengan cara lain selain TVP (XML, comma-separated list, voodoo), masukkan ke dalam bentuk tabel terlebih dahulu, dan gabungkan dengan apa pun itu. Berhati-hatilah untuk tidak mengoptimalkan sisipan terlebih dahulu dalam skenario ini, jika tidak, Anda berpotensi memperbarui beberapa baris dua kali.
Kesimpulan
Pola upsert ini lebih unggul daripada yang sering saya lihat, dan saya harap Anda mulai menggunakannya. Saya akan menunjuk ke posting ini setiap kali saya melihat IF EXISTS pola di alam liar. Dan, hei, seruan lain untuk Paul White (sql.kiwi | @SQK_Kiwi), karena dia sangat hebat dalam membuat konsep sulit menjadi mudah dipahami dan, pada gilirannya, menjelaskan.
Dan jika Anda merasa harus gunakan MERGE , tolong jangan @ saya; apakah Anda punya alasan yang bagus (mungkin Anda memerlukan MERGE yang tidak jelas) -hanya fungsi), atau Anda tidak menganggap serius tautan di atas.