Kembali pada tahun 2014, saya menulis artikel berjudul Performance Tuning the Whole Query Plan. Itu mencari cara untuk menemukan sejumlah kecil nilai yang berbeda dari kumpulan data yang cukup besar, dan menyimpulkan bahwa solusi rekursif bisa optimal. Postingan tindak lanjut ini meninjau kembali pertanyaan untuk SQL Server 2019, menggunakan jumlah baris yang lebih banyak.
Lingkungan Uji
Saya akan menggunakan database 50GB Stack Overflow 2013, tetapi tabel besar apa pun dengan jumlah nilai berbeda yang rendah dapat digunakan.
Saya akan mencari nilai yang berbeda di BountyAmount kolom dbo.Votes tabel, disajikan dalam urutan jumlah hadiah naik. Tabel Suara memiliki kurang dari 53 juta baris (52.928.720 tepatnya). Hanya ada 19 jumlah bounty yang berbeda, termasuk NULL .
Basis data Stack Overflow 2013 hadir tanpa indeks nonclustered untuk meminimalkan waktu pengunduhan. Ada indeks kunci utama berkerumun di Id kolom dbo.Votes meja. Itu disetel ke kompatibilitas SQL Server 2008 (level 100), tetapi kita akan mulai dengan pengaturan SQL Server 2017 yang lebih modern (level 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Pengujian dilakukan pada laptop saya menggunakan SQL Server 2019 CU 2. Mesin ini memiliki empat CPU i7 (hyperthreaded ke 8) dengan kecepatan dasar 2.4GHz. Ini memiliki RAM 32GB, dengan 24GB tersedia untuk instans SQL Server 2019. Ambang biaya untuk paralelisme disetel ke 50.
Setiap hasil pengujian mewakili yang terbaik dari sepuluh proses, dengan semua data yang diperlukan dan halaman indeks dalam memori.
1. Indeks Gugus Toko Baris
Untuk menetapkan garis dasar, proses pertama adalah kueri serial tanpa pengindeksan baru (dan ingat ini dengan database yang disetel ke tingkat kompatibilitas 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Ini memindai indeks berkerumun dan menggunakan agregat hash mode baris untuk menemukan nilai yang berbeda dari BountyAmount :
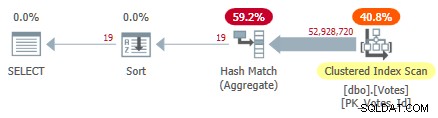 Paket Indeks Clustered Serial
Paket Indeks Clustered Serial
Ini membutuhkan waktu 10.500 md untuk menyelesaikan, menggunakan jumlah waktu CPU yang sama. Ingat ini adalah waktu terbaik lebih dari sepuluh berjalan dengan semua data dalam memori. Statistik sampel yang dibuat secara otomatis di BountyAmount kolom dibuat saat pertama kali dijalankan.
Sekitar setengah dari waktu yang telah berlalu dihabiskan untuk Clustered Index Scan, dan sekitar setengahnya untuk Hash Match Aggregate. Sortir hanya memiliki 19 baris untuk diproses, sehingga hanya membutuhkan 1 ms atau lebih. Semua operator dalam paket ini menggunakan eksekusi mode baris.
Menghapus MAXDOP 1 petunjuk memberikan rencana paralel:
 Paket Indeks Cluster Paralel
Paket Indeks Cluster Paralel
Ini adalah paket yang dipilih pengoptimal tanpa petunjuk apa pun dalam konfigurasi saya. Ini mengembalikan hasil dalam 4.200 md menggunakan total 32.800 md CPU (pada DOP 8).
2. Indeks Nonclustered
Memindai seluruh tabel untuk menemukan BountyAmount tampaknya tidak efisien, jadi wajar untuk mencoba menambahkan indeks nonclustered hanya pada satu kolom yang dibutuhkan kueri ini:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Indeks ini membutuhkan waktu untuk dibuat (1m 40s). MAXDOP 1 kueri sekarang menggunakan Agregat Aliran karena pengoptimal dapat menggunakan indeks nonclustered untuk menyajikan baris dalam BountyAmount pesanan:
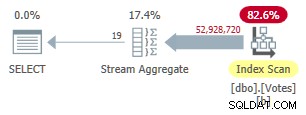 Rencana Mode Baris Serial Nonclustered
Rencana Mode Baris Serial Nonclustered
Ini berjalan selama 9.300 md (memakan jumlah waktu CPU yang sama). Peningkatan yang berguna pada 10.500 mdtk asli tetapi hampir tidak menghancurkan bumi.
Menghapus MAXDOP 1 petunjuk memberikan rencana paralel dengan agregasi lokal (per-utas):
 Rencana Mode Baris Paralel Nonclustered
Rencana Mode Baris Paralel Nonclustered
Ini dijalankan dalam 3,400 md menggunakan 25.800ms waktu CPU. Kami mungkin bisa lebih baik dengan kompresi baris atau halaman pada indeks baru, tetapi saya ingin beralih ke opsi yang lebih menarik.
3. Batch Mode di Row Store (BMOR)
Sekarang atur database ke mode kompatibilitas SQL Server 2019 menggunakan:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Ini memberikan kebebasan kepada pengoptimal untuk memilih mode batch di penyimpanan baris jika dianggap bermanfaat. Ini dapat memberikan beberapa manfaat dari eksekusi mode batch tanpa memerlukan indeks penyimpanan kolom. Untuk detail teknis yang mendalam dan opsi yang tidak terdokumentasi, lihat artikel bagus Dmitry Pilugin tentang masalah ini.
Sayangnya, pengoptimal masih memilih eksekusi mode baris sepenuhnya menggunakan agregat aliran untuk kueri pengujian serial dan paralel. Untuk mendapatkan mode batch pada rencana eksekusi penyimpanan baris, kita dapat menambahkan petunjuk untuk mendorong agregasi menggunakan pencocokan hash (yang dapat berjalan dalam mode batch):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Ini memberi kami rencana dengan semua operator yang berjalan dalam mode batch:
 Mode Kumpulan Serial pada Paket Toko Baris
Mode Kumpulan Serial pada Paket Toko Baris
Hasil dikembalikan dalam 2.600 md (semua CPU seperti biasa). Ini sudah lebih cepat dari paralel paket mode baris (3.400 mdtk berlalu) saat menggunakan CPU yang jauh lebih sedikit (2.600 md versus 25.800 md).
Menghapus MAXDOP 1 petunjuk (tetapi tetap menggunakan HASH GROUP ) memberikan mode batch paralel pada rencana penyimpanan baris:
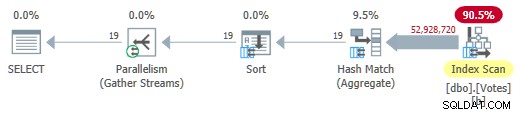 Mode Batch Paralel pada Rencana Toko Baris
Mode Batch Paralel pada Rencana Toko Baris
Ini berjalan hanya dalam 725 md menggunakan 5.700 md CPU.
4. Mode Batch di Toko Kolom
Mode batch paralel pada hasil penyimpanan baris adalah peningkatan yang mengesankan. Kita dapat melakukan lebih baik lagi dengan menyediakan representasi penyimpanan kolom dari data. Untuk menjaga semuanya tetap sama, saya akan menambahkan nonclustered indeks toko kolom hanya pada kolom yang kita butuhkan:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Ini diisi dari indeks b-tree nonclustered yang ada dan hanya membutuhkan waktu 15 detik untuk membuatnya.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Pengoptimal memilih paket mode batch penuh termasuk pemindaian indeks penyimpanan kolom:
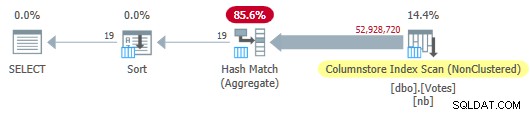 Rencana Toko Kolom Serial
Rencana Toko Kolom Serial
Ini berjalan dalam 115 md menggunakan jumlah waktu CPU yang sama. Pengoptimal memilih paket ini tanpa petunjuk apa pun tentang konfigurasi sistem saya karena perkiraan biaya paket di bawah ambang biaya untuk paralelisme .
Untuk mendapatkan paket paralel, kami dapat mengurangi ambang biaya atau menggunakan petunjuk yang tidak terdokumentasi:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Bagaimanapun, paket paralelnya adalah:
 Paket Toko Kolom Paralel
Paket Toko Kolom Paralel
Waktu berlalu kueri sekarang turun menjadi 30 md , sambil menggunakan 210ms CPU.
5. Mode Batch di Toko Kolom dengan Tekan ke Bawah
Waktu eksekusi terbaik saat ini, 30 md, sangat mengesankan, terutama jika dibandingkan dengan 10.500 md yang asli. Namun demikian, agak memalukan bahwa kami harus melewati hampir 53 juta baris (dalam 58.868 batch) dari Scan ke Hash Match Aggregate.
Akan lebih baik jika SQL Server dapat mendorong agregasi ke dalam pemindaian dan hanya mengembalikan nilai yang berbeda dari penyimpanan kolom secara langsung. Anda mungkin berpikir kami perlu mengekspresikan DISTINCT sebagai GROUP BY untuk mendapatkan Pushdown Agregat Terkelompok, tetapi itu secara logis berlebihan dan bukan keseluruhan cerita dalam hal apa pun.
Dengan implementasi SQL Server saat ini, kita sebenarnya perlu menghitung agregat untuk mengaktifkan agregat pushdown. Lebih dari itu, kita perlu menggunakan hasil agregat entah bagaimana, atau pengoptimal hanya akan menghapusnya karena tidak perlu.
Salah satu cara untuk menulis kueri untuk mencapai pushdown agregat adalah dengan menambahkan persyaratan pemesanan sekunder yang berlebihan secara logis:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Paket serial sekarang:
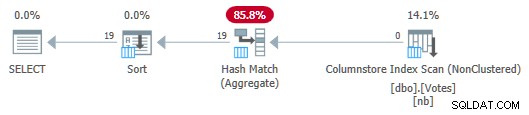 Rencana Penyimpanan Kolom Serial dengan Push Down Agregat
Rencana Penyimpanan Kolom Serial dengan Push Down Agregat
Perhatikan bahwa tidak ada baris yang dilewatkan dari Scan ke Agregat! Di bawah selimut, sebagian agregat dari BountyAmount nilai dan jumlah baris terkaitnya diteruskan ke Agregat Pencocokan Hash, yang menjumlahkan agregat parsial untuk membentuk agregat akhir (global) yang diperlukan. Ini sangat efisien, sebagaimana dikonfirmasi oleh waktu berlalu 13 md (semuanya adalah waktu CPU). Sebagai pengingat, paket serial sebelumnya membutuhkan waktu 115 md.
Untuk melengkapi set, kita bisa mendapatkan versi paralel dengan cara yang sama seperti sebelumnya:
 Rencana Penyimpanan Kolom Paralel dengan Push Down Agregat
Rencana Penyimpanan Kolom Paralel dengan Push Down Agregat
Ini berjalan selama 7 md menggunakan total 40ms CPU.
Sayang sekali kita perlu menghitung dan menggunakan agregat yang tidak kita butuhkan hanya untuk menekan. Mungkin kedepannya akan diperbaiki agar DISTINCT dan GROUP BY tanpa agregat dapat didorong ke bawah untuk memindai.
6. Ekspresi Tabel Umum Rekursif Mode Baris
Pada awalnya, saya berjanji untuk meninjau kembali solusi CTE rekursif yang digunakan untuk menemukan sejumlah kecil duplikat dalam kumpulan data yang besar. Menerapkan persyaratan saat ini menggunakan teknik itu cukup mudah, meskipun kodenya tentu lebih panjang dari apa pun yang telah kita lihat hingga saat ini:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Idenya berakar pada apa yang disebut pemindaian indeks lewati:Kami menemukan nilai minat terendah di awal indeks b-tree yang diurutkan naik, kemudian mencari nilai berikutnya dalam urutan indeks, dan seterusnya. Struktur indeks b-tree membuat pencarian nilai tertinggi berikutnya menjadi sangat efisien — tidak perlu memindai duplikat.
Satu-satunya trik nyata di sini adalah meyakinkan pengoptimal untuk mengizinkan kita menggunakan TOP di bagian 'rekursif' dari CTE untuk mengembalikan satu salinan dari setiap nilai yang berbeda. Silakan lihat artikel saya sebelumnya jika Anda membutuhkan penyegaran tentang detailnya.
Rencana eksekusi (dijelaskan secara umum oleh Craig Freedman di sini) adalah:
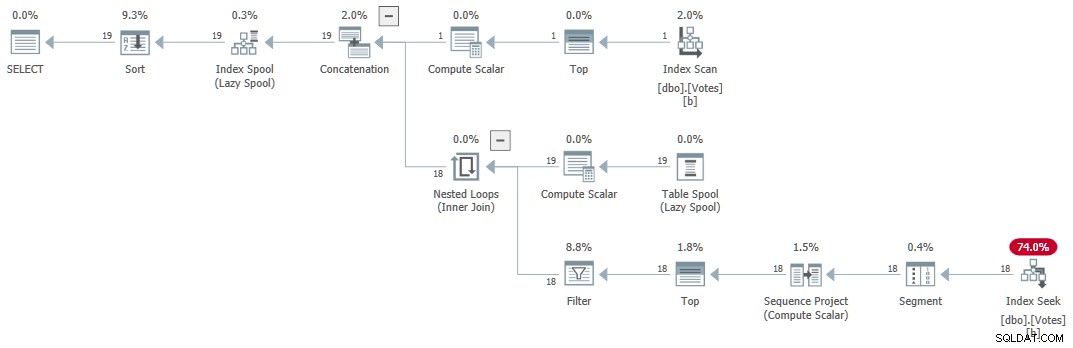 CTE Rekursif Serial
CTE Rekursif Serial
Kueri mengembalikan hasil yang benar dalam 1 md menggunakan 1ms CPU, menurut Sentry One Plan Explorer.
7. T-SQL berulang
Logika serupa dapat diekspresikan menggunakan WHILE lingkaran. Kode mungkin lebih mudah dibaca dan dipahami daripada CTE rekursif. Itu juga menghindari keharusan menggunakan trik untuk mengatasi banyak batasan pada bagian rekursif dari CTE. Performanya kompetitif di sekitar 15ms. Kode ini disediakan untuk kepentingan dan tidak disertakan dalam tabel ringkasan kinerja.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tabel Ringkasan Kinerja
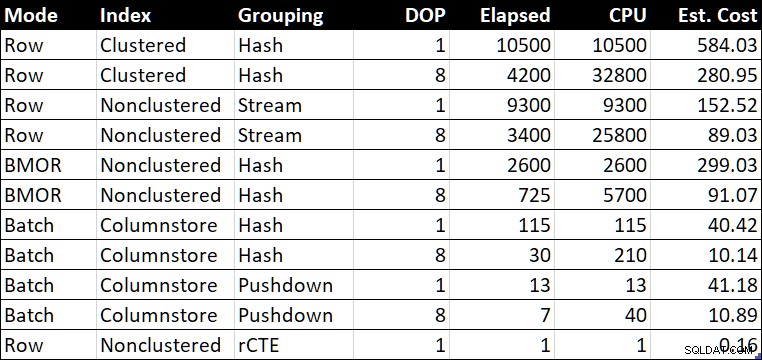 Tabel Ringkasan Kinerja (durasi / CPU dalam milidetik)
Tabel Ringkasan Kinerja (durasi / CPU dalam milidetik)
"Taks. Kolom Cost” menunjukkan perkiraan biaya pengoptimal untuk setiap kueri seperti yang dilaporkan pada sistem pengujian.
Pemikiran Terakhir
Menemukan sejumlah kecil nilai yang berbeda mungkin tampak seperti persyaratan yang cukup spesifik, tetapi saya telah menemukannya cukup sering selama bertahun-tahun, biasanya sebagai bagian dari penyetelan kueri yang lebih besar.
Beberapa contoh terakhir cukup dekat dalam kinerja. Banyak orang akan senang dengan salah satu hasil sub-detik, tergantung pada prioritas. Bahkan mode batch serial pada hasil penyimpanan baris 2.600 md dapat dibandingkan dengan baik dengan paralel terbaik paket mode baris, yang menjadi pertanda baik untuk percepatan yang signifikan hanya dengan memutakhirkan ke SQL Server 2019 dan mengaktifkan tingkat kompatibilitas basis data 150. Tidak semua orang akan dapat pindah ke penyimpanan penyimpanan kolom dengan cepat, dan itu tidak akan selalu menjadi solusi yang tepat. . Mode batch pada penyimpanan baris menyediakan cara yang rapi untuk mencapai beberapa keuntungan yang mungkin diperoleh dengan penyimpanan kolom, dengan asumsi Anda dapat meyakinkan pengoptimal untuk memilih menggunakannya.
Agregat penyimpanan kolom paralel menghasilkan 57 juta baris diproses dalam 7 md (menggunakan 40ms CPU) luar biasa, terutama mengingat perangkat kerasnya. Hasil push down agregat serial 13ms sama-sama mengesankan. Akan sangat bagus jika saya tidak harus menambahkan hasil agregat yang tidak berarti untuk mendapatkan rencana ini.
Bagi mereka yang belum dapat pindah ke SQL Server 2019 atau penyimpanan penyimpanan kolom, CTE rekursif masih merupakan solusi yang layak dan efisien ketika ada indeks b-tree yang sesuai, dan jumlah nilai berbeda yang diperlukan dijamin cukup kecil. Akan lebih rapi jika SQL Server dapat mengakses b-tree seperti ini tanpa perlu menulis CTE rekursif (atau kode T-SQL perulangan berulang yang setara menggunakan WHILE ).
Solusi lain yang mungkin untuk masalah ini adalah membuat tampilan yang diindeks. Ini akan memberikan nilai yang berbeda dengan efisiensi yang besar. Sisi bawahnya, seperti biasa, adalah bahwa setiap perubahan pada tabel yang mendasarinya perlu memperbarui jumlah baris yang disimpan dalam tampilan terwujud.
Setiap solusi yang disajikan di sini memiliki tempatnya, tergantung pada persyaratannya. Memiliki berbagai alat yang tersedia secara umum merupakan hal yang baik saat menyetel kueri. Sebagian besar waktu, saya akan memilih salah satu solusi mode batch karena kinerjanya akan cukup dapat diprediksi tidak peduli berapa banyak duplikat yang ada.



