Dari waktu ke waktu saya melihat seseorang menyatakan persyaratan untuk membuat nomor acak untuk sebuah kunci. Biasanya ini untuk membuat beberapa jenis ID Pelanggan atau ID Pengguna pengganti yang merupakan nomor unik dalam rentang tertentu, tetapi tidak dikeluarkan secara berurutan, dan karena itu jauh lebih mudah ditebak daripada IDENTITY nilai.
NEWID() memecahkan masalah menebak, tetapi penalti kinerja biasanya merupakan pemecah kesepakatan, terutama ketika dikelompokkan:kunci yang jauh lebih luas daripada bilangan bulat, dan pemisahan halaman karena nilai yang tidak berurutan. NEWSEQUENTIALID() memecahkan masalah pemisahan halaman, tetapi masih merupakan kunci yang sangat lebar, dan memperkenalkan kembali masalah yang dapat Anda tebak nilai berikutnya (atau nilai yang baru-baru ini diterbitkan) dengan beberapa tingkat akurasi.
Akibatnya, mereka menginginkan teknik untuk menghasilkan dan random acak bilangan bulat unik. Menghasilkan angka acak sendiri tidaklah sulit, menggunakan metode seperti RAND() atau CHECKSUM(NEWID()) . Masalah muncul ketika Anda harus mendeteksi tabrakan. Mari kita lihat sekilas pendekatan umum, dengan asumsi kita menginginkan nilai CustomerID antara 1 dan 1.000.000:
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END Saat tabel semakin besar, pemeriksaan duplikat tidak hanya menjadi lebih mahal, tetapi peluang Anda untuk menghasilkan duplikat juga meningkat. Jadi pendekatan ini mungkin tampak bekerja dengan baik ketika tabelnya kecil, tetapi saya menduga bahwa itu pasti akan semakin menyakitkan seiring waktu.
Pendekatan Berbeda
Saya penggemar berat tabel tambahan; Saya telah menulis secara publik tentang tabel kalender dan tabel angka selama satu dekade, dan menggunakannya lebih lama. Dan ini adalah kasus di mana saya pikir tabel yang sudah diisi sebelumnya bisa sangat berguna. Mengapa mengandalkan menghasilkan angka acak saat runtime dan menangani kemungkinan duplikat, ketika Anda dapat mengisi semua nilai tersebut sebelumnya dan mengetahui – dengan kepastian 100%, jika Anda melindungi tabel Anda dari DML yang tidak sah – bahwa nilai berikutnya yang Anda pilih tidak pernah ada digunakan sebelumnya?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; Populasi ini membutuhkan waktu 9 detik untuk dibuat (dalam VM pada laptop), dan menempati sekitar 17 MB pada disk. Data dalam tabel terlihat seperti ini:
(Jika kami khawatir tentang bagaimana angka-angka itu terisi, kami dapat menambahkan batasan unik pada kolom Nilai, yang akan membuat tabel menjadi 30 MB. Jika kami menerapkan kompresi halaman, itu akan menjadi 11 MB atau 25 MB, masing-masing. )
Saya membuat salinan tabel yang lain, dan mengisinya dengan nilai yang sama, sehingga saya dapat menguji dua metode berbeda untuk menurunkan nilai berikutnya:
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Sekarang, kapan pun kita menginginkan nomor acak baru, kita cukup mengeluarkan satu dari tumpukan nomor yang ada, dan menghapusnya. Ini mencegah kita dari harus khawatir tentang duplikat, dan memungkinkan kita untuk menarik angka – menggunakan indeks berkerumun – yang sebenarnya sudah dalam urutan acak. (Sebenarnya, kita tidak perlu menghapus nomor yang kami gunakan; kita dapat menambahkan kolom untuk menunjukkan apakah suatu nilai telah digunakan – ini akan memudahkan untuk mengembalikan dan menggunakan kembali nilai tersebut jika Pelanggan kemudian dihapus atau terjadi kesalahan di luar transaksi ini tetapi sebelum sepenuhnya dibuat.)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
Saya menggunakan variabel tabel untuk menampung output perantara, karena ada berbagai batasan dengan DML yang dapat dikomposisi sehingga tidak memungkinkan untuk menyisipkan ke tabel Pelanggan langsung dari DELETE (misalnya, keberadaan kunci asing). Namun, mengakui bahwa itu tidak selalu mungkin, saya juga ingin menguji metode ini:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
Perhatikan bahwa tidak satu pun dari solusi ini yang benar-benar menjamin urutan acak, terutama jika tabel angka acak memiliki indeks lain (seperti indeks unik pada kolom Nilai). Tidak ada cara untuk menentukan urutan DELETE menggunakan TOP; dari dokumentasi:
Jadi, jika Anda ingin menjamin pemesanan acak, Anda bisa melakukan sesuatu seperti ini:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Pertimbangan lain di sini adalah, untuk pengujian ini, tabel Pelanggan memiliki kunci utama yang dikelompokkan pada kolom ID Pelanggan; ini pasti akan menyebabkan pemisahan halaman saat Anda memasukkan nilai acak. Di dunia nyata, jika Anda memiliki persyaratan ini, Anda mungkin akan berakhir mengelompok di kolom yang berbeda.
Perhatikan bahwa saya juga mengabaikan transaksi dan penanganan kesalahan di sini, tetapi ini juga harus menjadi pertimbangan untuk kode produksi.
Pengujian Kinerja
Untuk menggambar beberapa perbandingan kinerja yang realistis, saya membuat lima prosedur tersimpan, yang mewakili skenario berikut (menguji kecepatan, distribusi, dan frekuensi tabrakan dari metode acak yang berbeda, serta kecepatan menggunakan tabel angka acak yang telah ditentukan sebelumnya):
- Pembuatan waktu proses menggunakan
CHECKSUM(NEWID()) - Pembuatan waktu proses menggunakan
CRYPT_GEN_RANDOM() - Pembuatan waktu proses menggunakan
RAND() - Tabel angka yang telah ditentukan sebelumnya dengan variabel tabel
- Tabel angka standar dengan sisipan langsung
Mereka menggunakan tabel logging untuk melacak durasi dan jumlah tabrakan:
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
Kode untuk prosedur berikut (klik untuk menampilkan/menyembunyikan):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO Dan untuk menguji ini, saya akan menjalankan setiap prosedur tersimpan 1.000.000 kali:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
Tidak mengherankan, metode yang menggunakan tabel angka acak yang telah ditentukan membutuhkan waktu sedikit lebih lama *di awal pengujian*, karena mereka harus melakukan I/O baca dan tulis setiap saat. Ingatlah bahwa angka-angka ini dalam mikrodetik , berikut adalah durasi rata-rata untuk setiap prosedur, pada interval yang berbeda sepanjang proses (rata-rata selama 10.000 eksekusi pertama, 10.000 eksekusi tengah, 10.000 eksekusi terakhir, dan 1.000 eksekusi terakhir):
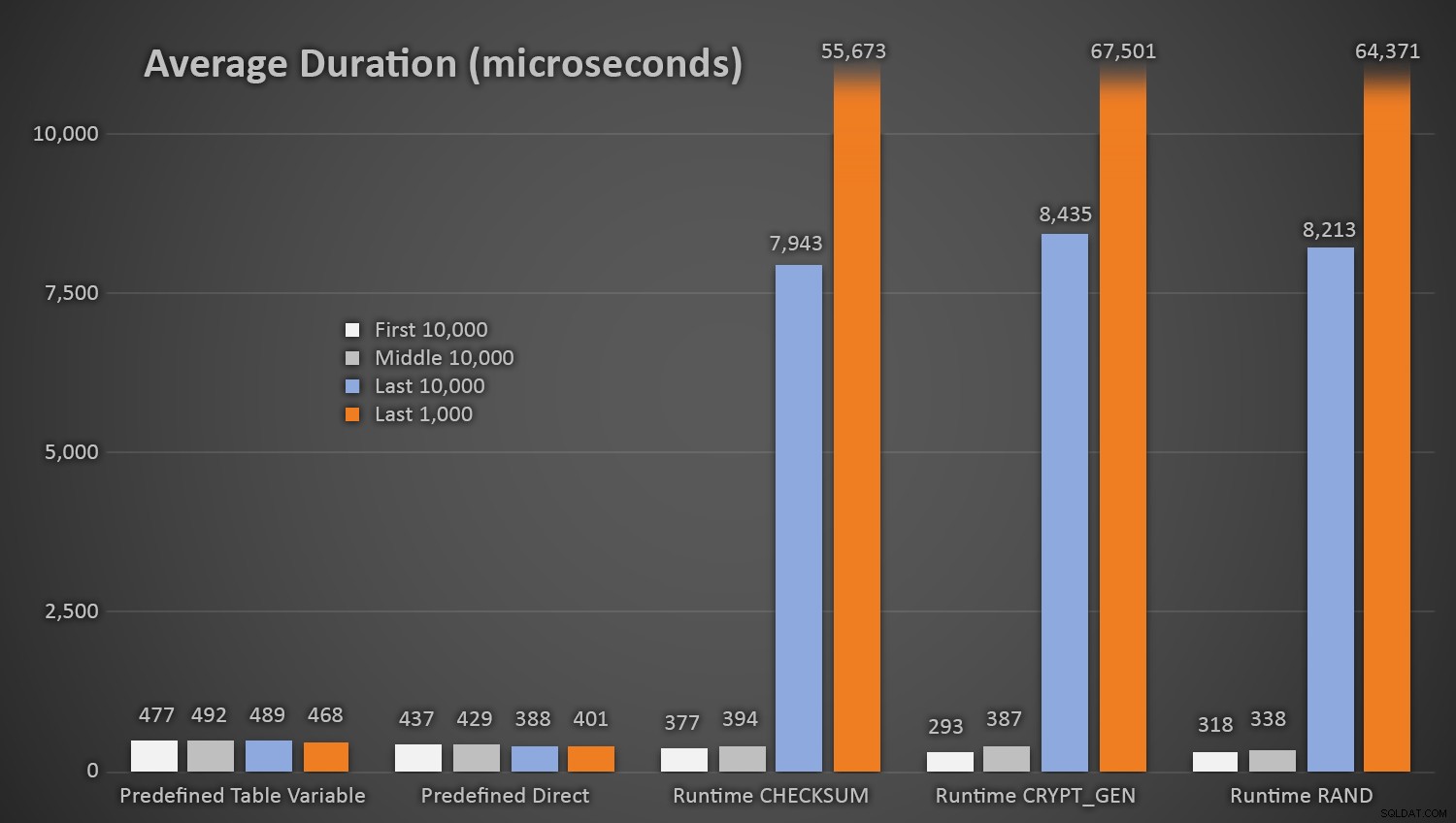
Durasi rata-rata (dalam mikrodetik) dari pembangkitan acak menggunakan pendekatan yang berbeda
Ini bekerja dengan baik untuk semua metode ketika ada beberapa baris di tabel Pelanggan, tetapi karena tabel semakin besar, biaya pemeriksaan nomor acak baru terhadap data yang ada menggunakan metode runtime meningkat secara substansial, baik karena peningkatan I /O dan juga karena jumlah tabrakan meningkat (memaksa Anda untuk mencoba dan mencoba lagi). Bandingkan durasi rata-rata saat dalam rentang jumlah tabrakan berikut (dan ingat bahwa pola ini hanya memengaruhi metode runtime):
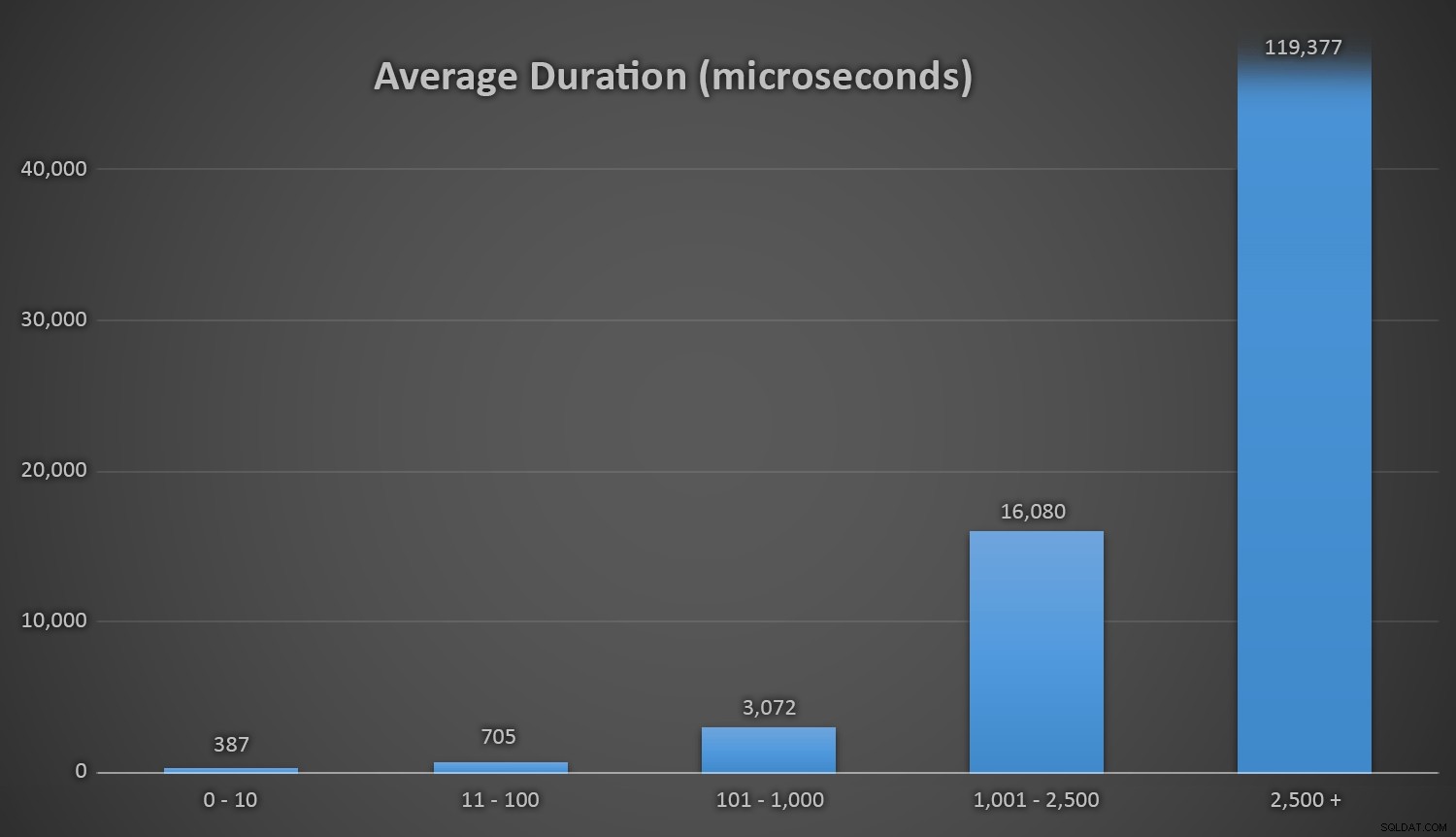
Durasi rata-rata (dalam mikrodetik) selama rentang tumbukan yang berbeda
Saya berharap ada cara sederhana untuk membuat grafik durasi terhadap jumlah tabrakan. Saya akan meninggalkan Anda dengan berita gembira ini:pada tiga sisipan terakhir, metode runtime berikut harus melakukan banyak upaya ini sebelum akhirnya menemukan ID unik terakhir yang mereka cari, dan ini adalah berapa lama waktu yang dibutuhkan:
| Jumlah tabrakan | Durasi (mikrodetik) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | baris ketiga hingga terakhir | 63.545 | 639,358 |
| baris ke-2 hingga terakhir | 164.807 | 1.605.695 | |
| Baris terakhir | 30.630 | 296.207 | |
| CRYPT_GEN_RANDOM() | baris ketiga hingga terakhir | 219.766 | 2.229.166 |
| baris ke-2 hingga terakhir | 255.463 | 2.681.468 | |
| Baris terakhir | 136.342 | 1.434.725 | |
| RAND() | baris ketiga hingga terakhir | 129.764 | 1.215.994 |
| baris ke-2 hingga terakhir | 220.195 | 2.088.992 | |
| Baris terakhir | 440.765 | 4,161,925 | |
Durasi berlebihan dan tabrakan di dekat akhir baris
Menarik untuk dicatat bahwa baris terakhir tidak selalu menghasilkan jumlah tabrakan tertinggi, jadi ini bisa menjadi masalah nyata jauh sebelum Anda menggunakan 999.000+ nilai.
Pertimbangan lain
Anda mungkin ingin mempertimbangkan untuk menyiapkan semacam peringatan atau pemberitahuan ketika tabel RandomNumbers mulai berada di bawah beberapa baris (pada titik mana Anda dapat mengisi ulang tabel dengan set baru dari 1,000.001 – 2.000.000, misalnya). Anda harus melakukan hal serupa jika Anda membuat angka acak dengan cepat – jika Anda mempertahankannya dalam kisaran 1 – 1.000.000, maka Anda harus mengubah kode untuk menghasilkan angka dari rentang yang berbeda setelah Anda ' telah menggunakan semua nilai itu.
Jika Anda menggunakan nomor acak pada metode runtime, maka Anda dapat menghindari situasi ini dengan terus-menerus mengubah ukuran kumpulan dari mana Anda menggambar nomor acak (yang juga harus menstabilkan dan secara drastis mengurangi jumlah tabrakan). Misalnya, alih-alih:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Anda dapat mendasarkan kumpulan pada jumlah baris yang sudah ada di tabel:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
Sekarang satu-satunya kekhawatiran Anda adalah ketika Anda mendekati batas atas untuk INT …
Catatan:Saya juga baru-baru ini menulis tip tentang ini di MSSQLTips.com.