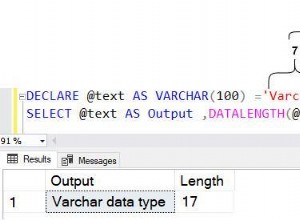
Keterlibatan penyetelan kinerja dapat berakhir dengan banyak putaran saat Anda mengerjakannya – semuanya tergantung pada apa yang muncul sebagai masalah dan apa yang dikatakan data kepada Anda. Beberapa hari itu mendarat di kueri tertentu, atau serangkaian kueri, yang dapat ditingkatkan dengan indeks - baik yang baru atau modifikasi pada indeks yang ada. Salah satu bagian penyetelan favorit saya adalah bekerja dengan indeks dan, ketika saya memikirkan tentang posting ini, saya tergoda untuk memberi label penyetelan indeks sebagai tugas yang “lebih mudah”… tetapi sebenarnya tidak.
Saya menganggap penyetelan indeks sebagai seni dan sains. Anda harus mencoba dan berpikir seperti pengoptimal, dan Anda harus memahami skema tabel dan kueri (atau kueri) yang Anda coba sesuaikan. Keduanya didorong oleh data dan dengan demikian masuk dalam kategori sains. Komponen seni ikut bermain saat Anda memikirkan lainnya indeks di atas meja, dan semua lainnya kueri yang melibatkan tabel yang dapat dipengaruhi oleh perubahan indeks.
Langkah 1 :Identifikasi kueri dan tinjau rencana
Ketika saya mengidentifikasi kueri yang dapat mengambil manfaat dari indeks, saya segera mendapatkan rencananya. Saya sering mendapatkan Paket Eksekusi dari cache paket atau Penyimpanan Kueri, dan kemudian menggunakan SSMS untuk mendapatkan Paket Eksekusi plus Statistik Run-Time (alias Paket Eksekusi Aktual). Sering kali, bentuk kedua rencana itu sama; tapi itu bukan jaminan, itulah sebabnya saya suka melihat keduanya.
Rencana tersebut mungkin memiliki rekomendasi indeks yang hilang, mungkin memiliki pemindaian indeks berkerumun (atau pemindaian tumpukan jika tidak ada indeks berkerumun), mungkin menggunakan indeks yang tidak berkerumun tetapi kemudian memiliki pencarian untuk mengambil kolom tambahan. Memperbaiki masing-masing masalah secara individual terdengar cukup mudah. Tambahkan saja indeks yang hilang, bukan? Jika ada pemindaian indeks berkerumun atau tumpukan, buat indeks yang saya perlukan untuk kueri dan selesai? Atau jika ada indeks yang digunakan tetapi masuk ke tabel untuk mendapatkan kolom tambahan, tambahkan saja kolom ke indeks itu?
Biasanya tidak semudah itu, dan meskipun mudah, saya masih menjalani proses yang saya uraikan di sini.
Langkah 2 :Tentukan tabel yang akan ditinjau
Sekarang setelah saya memiliki kueri, saya harus mencari tahu tabel apa yang tidak diindeks dengan benar. Selain meninjau rencana, saya juga mengaktifkan statistik IO dan TIME di SSMS. Ini mungkin kuno bagi saya, karena rencana eksekusi berisi lebih banyak informasi – termasuk durasi dan nomor IO per operator – dengan setiap rilis, tetapi saya menyukai statistik IO karena saya dapat dengan cepat melihat pembacaan untuk setiap tabel. Untuk kueri yang kompleks dengan beberapa gabungan, atau subkueri, atau CTE, atau tampilan bersarang, memahami di mana IO dan/atau waktu dihabiskan dalam kueri mendorong di mana saya menghabiskan waktu saya. Kapan pun memungkinkan dari titik ini, saya mengambil kueri yang lebih besar dan kompleks dan mengupasnya ke bagian yang menyebabkan masalah terbesar.
Misalnya, jika ada kueri yang bergabung ke 10 tabel dan memiliki dua subkueri, paket (bersama dengan IO dan informasi durasi) membantu saya mengidentifikasi di mana masalahnya. Kemudian saya akan mengeluarkan bagian kueri itu – tabel yang bermasalah dan mungkin beberapa lainnya yang bergabung – dan fokus pada hal itu. Terkadang itu hanya sub-kueri, jadi saya mulai dari sana.
Langkah 3 :Lihat indeks yang ada
Dengan kueri (atau bagian dari kueri) yang ditentukan, maka saya fokus pada indeks yang ada untuk tabel yang terlibat. Untuk langkah ini, saya mengandalkan sp_helpindex versi Kimberly. Saya lebih suka versinya daripada sp_helpindex standar karena itu juga mencantumkan kolom TERMASUK dan definisi filter (jika ada). Bergantung pada jumlah indeks yang muncul untuk tabel, saya akan sering menyalin ini dan menempelkannya ke Excel, lalu memesan berdasarkan kunci indeks dan kemudian kolom yang disertakan. Ini memungkinkan saya menemukan redundansi dengan cepat.
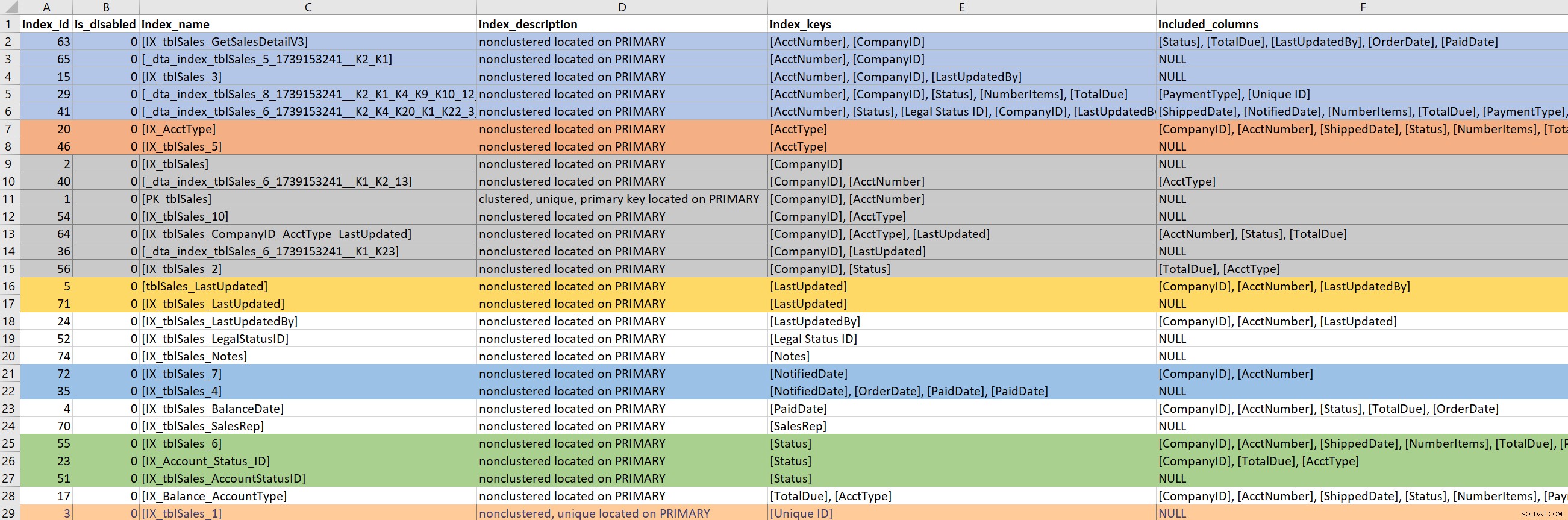
Berdasarkan contoh output di atas, ada tujuh indeks yang dimulai dengan CompanyID, lima yang dimulai dengan AcctNumber, dan beberapa potensi redundansi lainnya. Meskipun tampaknya ideal untuk hanya memiliki satu indeks yang mengarah pada kolom tertentu (mis. CompanyID), untuk beberapa pola kueri yang tidak cukup.
Ketika saya melihat indeks yang ada, sangat mudah untuk masuk ke lubang kelinci. Saya melihat output di atas dan segera mulai bertanya mengapa ada tujuh indeks yang dimulai dengan CompanyID, dan saya ingin tahu siapa yang membuatnya, dan mengapa, dan untuk kueri apa. Tapi… jika kueri bermasalah saya tidak menggunakan ID Perusahaan, apakah saya harus peduli? Ya… karena secara umum saya ada di sana untuk meningkatkan kinerja, dan jika itu berarti melihat indeks lain di atas meja di sepanjang jalan, maka biarlah. Tapi di sinilah mudahnya lupa waktu (dan tujuan sebenarnya).
Jika kueri saya yang bermasalah membutuhkan indeks yang mengarah pada PaidDate, saya hanya perlu berurusan dengan satu indeks yang ada. Jika kueri saya yang bermasalah membutuhkan indeks yang mengarah ke AcctNumber, itu menjadi rumit. Ketika indeks yang ada semacam mencakup kueri, dan saya ingin memperluas indeks (menambahkan lebih banyak kolom) atau mengkonsolidasikan (menggabungkan dua atau mungkin tiga indeks menjadi satu), maka saya harus menggali.
Langkah 4 :Statistik Penggunaan Indeks
Saya menemukan bahwa banyak orang tidak menangkap statistik penggunaan indeks secara berkelanjutan. Ini sangat disayangkan, karena menurut saya data tersebut berguna ketika memutuskan indeks mana yang akan disimpan, dan mana yang akan dijatuhkan atau digabungkan. Jika saya tidak memiliki statistik penggunaan historis, setidaknya saya memeriksa untuk melihat tampilan penggunaan saat ini (sejak layanan terakhir dimulai ulang):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
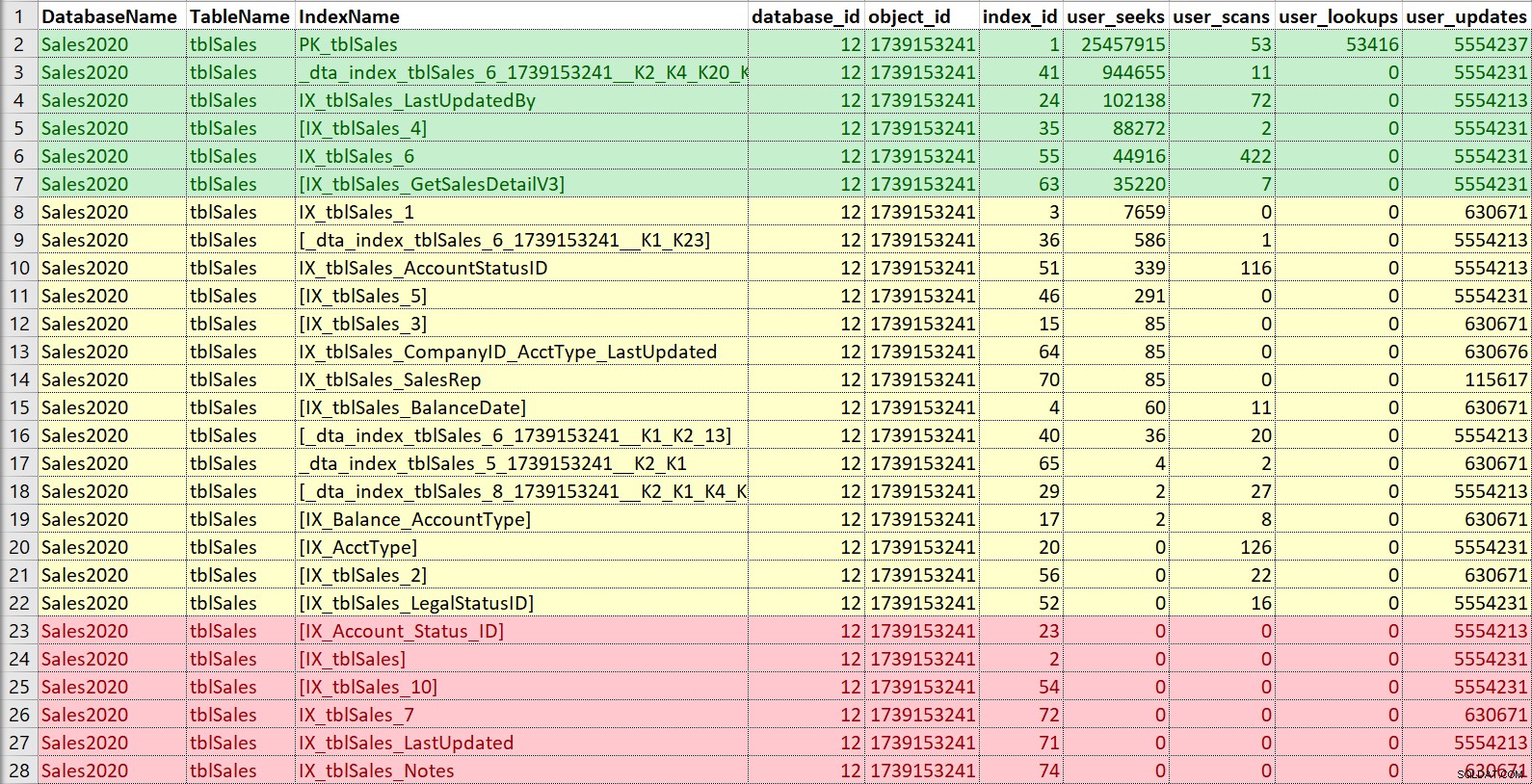
Sekali lagi, saya ingin memasukkan ini ke dalam Excel, mengurutkan berdasarkan pencarian dan kemudian memindai, dan juga mencatat pembaruan. Untuk contoh ini, indeks yang berwarna merah adalah indeks tanpa pencarian, pemindaian, atau pencarian… hanya pembaruan. Itu adalah kandidat untuk dinonaktifkan dan berpotensi dijatuhkan, jika benar-benar tidak digunakan (sekali lagi, memiliki riwayat penggunaan akan membantu di sini). Indeks berwarna hijau pasti digunakan, saya ingin menyimpannya (meskipun mungkin dalam beberapa kasus mereka dapat diubah). Yang berwarna kuning… ada yang seperti digunakan, ada yang hampir tidak digunakan. Sekali lagi, sejarah akan membantu di sini, atau konteks dari orang lain — terkadang indeks mungkin penting untuk laporan atau proses yang tidak berjalan sepanjang waktu.
Jika saya hanya ingin mengubah atau menambahkan indeks baru, versus pembersihan dan konsolidasi yang sebenarnya, maka saya lebih memperhatikan indeks apa pun yang mirip dengan apa yang ingin saya tambahkan atau ubah. Namun, saya akan memastikan untuk menunjukkan informasi penggunaan kepada pelanggan dan, jika waktu memungkinkan, membantu dengan strategi pengindeksan keseluruhan untuk tabel.
Apa Selanjutnya?
Kami belum selesai! Ini adalah bagian 1 dari pendekatan saya untuk penyetelan indeks, dan angsuran saya berikutnya akan mencantumkan sisa langkah saya. Sementara itu, jika Anda tidak menangkap statistik penggunaan indeks, itu adalah sesuatu yang dapat Anda lakukan menggunakan kueri di atas, atau variasi lain. Saya akan merekomendasikan untuk menangkap statistik penggunaan untuk semua basis data pengguna, bukan hanya tabel dan basis data tertentu seperti yang telah saya lakukan di atas, jadi ubah predikatnya seperlunya. Dan akhirnya, sebagai bagian dari tugas terjadwal untuk memotret informasi itu ke tabel, jangan lupa langkah lain untuk membersihkan tabel setelah data ada di sana untuk sementara waktu (saya menyimpannya setidaknya selama enam bulan; beberapa orang mungkin mengatakan tahun diperlukan).