Database relasional mewakili data organisasi dalam tabel yang menggunakan kolom dengan tipe data berbeda yang memungkinkan mereka menyimpan nilai yang valid. Pengembang dan DBA perlu mengetahui dan memahami tipe data yang sesuai untuk setiap kolom untuk kinerja kueri yang lebih baik.
Artikel ini akan membahas tipe data populer VARCHAR() dan NVARCHAR(), perbandingannya, dan ulasan kinerja di SQL Server.
VARCHAR [ ( n | maks ) ] dalam SQL
VARCHAR tipe data mewakili non-Unicode tipe data string panjang variabel. Anda dapat menyimpan huruf, angka, dan karakter khusus di dalamnya.
- N mewakili ukuran string dalam byte.
- Kolom tipe data VARCHAR menyimpan maksimal 8000 karakter Non-Unicode.
- Tipe data VARCHAR membutuhkan 1 byte per karakter. Jika Anda tidak secara eksplisit menentukan nilai untuk N, dibutuhkan penyimpanan 1 byte.
Catatan:Jangan bingung N dengan nilai yang mewakili jumlah karakter dalam string.
Kueri berikut mendefinisikan tipe data VARCHAR dengan 100 byte data.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Ini mengembalikan panjang sebagai 17 karena 1 byte per karakter, termasuk karakter spasi.
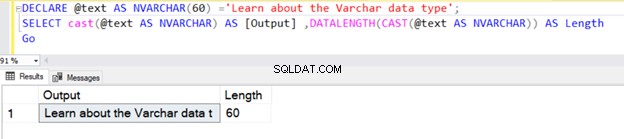
Kueri berikut mendefinisikan tipe data VARCHAR tanpa nilai N . Oleh karena itu, SQL Server menganggap nilai default sebagai 1 byte, seperti yang ditunjukkan di bawah ini.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
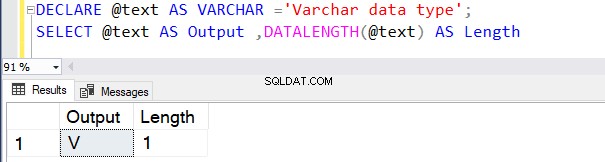
Kita juga dapat menggunakan VARCHAR menggunakan fungsi CAST atau CONVERT. Misalnya, dalam dua contoh di bawah ini, kami mendeklarasikan variabel dengan panjang 100 byte dan kemudian menggunakan operator CAST.
Kueri pertama mengembalikan panjangnya sebagai 30 karena kami tidak menentukan N dalam tipe data VARCHAR operator CAST. Panjang defaultnya adalah 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
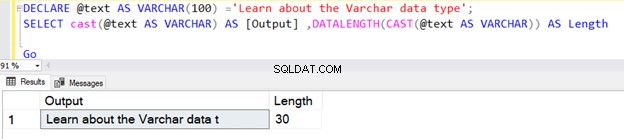
Namun, jika panjang string kurang dari 30, dibutuhkan ukuran string yang sebenarnya.

NVARCHAR [ ( n | maks ) ] dalam SQL
NVARCHAR tipe data untuk Unicode tipe data karakter dengan panjang variabel. Di sini, N mengacu pada Kumpulan Karakter Bahasa Nasional dan digunakan untuk mendefinisikan string Unicode. Anda dapat menyimpan karakter non-Unicode dan Unicode (Kanji Jepang, Hangul Korea, dll.).
- N mewakili ukuran string dalam byte.
- Dapat menyimpan maksimal 4000 karakter Unicode dan Non-Unicode.
- Tipe data VARCHAR membutuhkan 2 byte per karakter. Dibutuhkan penyimpanan 2 byte jika Anda tidak menentukan nilai apa pun untuk N.
Kueri berikut mendefinisikan tipe data VARCHAR dengan 100 byte data.
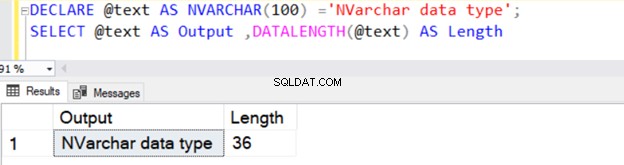
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Ini mengembalikan panjang string 36 karena NVARCHAR membutuhkan 2 byte per penyimpanan karakter.
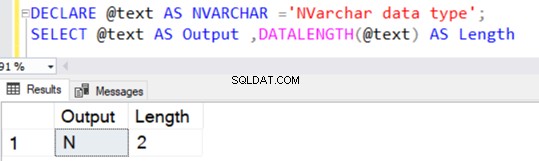
Mirip dengan tipe data VARCHAR, NVARCHAR juga memiliki nilai default 1 karakter (2 byte) tanpa menentukan nilai eksplisit untuk N.
Jika kita menerapkan konversi NVARCHAR menggunakan fungsi CAST atau CONVERT tanpa nilai eksplisit N, nilai defaultnya adalah 30 karakter, yaitu 60 byte.
Menyimpan Nilai Unicode dan Non-Unicode dalam Tipe Data VARCHAR
Misalkan kita memiliki tabel yang mencatat umpan balik pelanggan dari portal e-shopping. Untuk tujuan ini, kami memiliki tabel SQL dengan kueri berikut.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
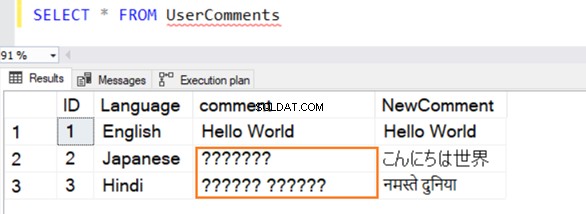
Kami memasukkan beberapa catatan sampel dalam tabel ini dalam bahasa Inggris, Jepang, dan Hindi. Tipe data untuk [Komentar] adalah VARCHAR dan [Komentar Baru] adalah NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
Kueri berhasil dijalankan, dan memberikan baris berikut saat memilih nilai darinya. Untuk baris 2 dan 3, tidak mengenali data jika tidak dalam bahasa Inggris.
Tipe Data VARCHAR dan NVARCHAR:Perbandingan Kinerja
Kita tidak boleh mencampur penggunaan tipe data VARCHAR dan NVARCHAR dalam predikat JOIN atau WHERE. Itu membatalkan indeks yang ada karena SQL Server memerlukan tipe data yang sama di kedua sisi GABUNG. SQL Server mencoba melakukan konversi implisit menggunakan fungsi CONVERT_IMPLICIT() jika terjadi ketidakcocokan.
SQL Server menggunakan prioritas tipe data untuk menentukan tipe data target. NVARCHAR memiliki prioritas lebih tinggi daripada tipe data VARCHAR. Oleh karena itu, selama konversi tipe data, SQL Server mengonversi nilai VARCHAR yang ada menjadi NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Sekarang, mari kita jalankan dua pernyataan SELECT yang mengambil record sesuai dengan tipe datanya.
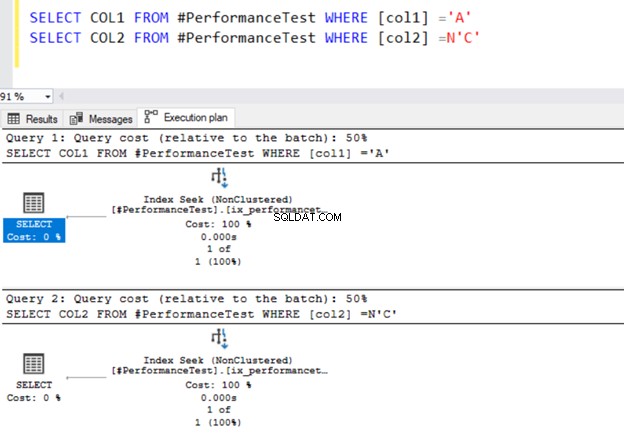
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Kedua kueri menggunakan Operator pencarian indeks dan indeks yang kita definisikan sebelumnya.
Sekarang, kami mengganti nilai tipe data untuk perbandingan dengan predikat WHERE. Kolom 1 memiliki tipe data VARCHAR, tetapi kami menetapkan N’A’ untuk meletakkannya sebagai tipe data NVARCHAR.
Demikian pula, col2 adalah tipe data NVARCHAR, dan kami menentukan nilai 'C' yang mengacu pada tipe data VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'Dalam rencana eksekusi aktual kueri, Anda mendapatkan pemindaian Indeks, dan pernyataan SELECT memiliki simbol peringatan.
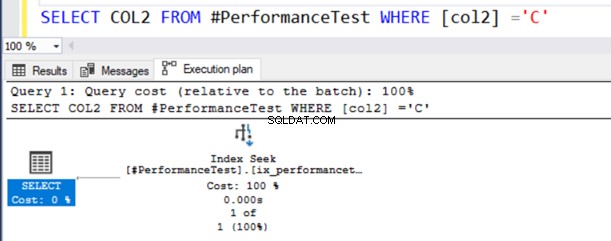
Kueri ini berfungsi dengan baik karena tipe data NVARCHAR() dapat memiliki nilai Unicode dan non-Unicode.
Sekarang, kueri kedua menggunakan pemindaian Indeks dan mengeluarkan simbol peringatan pada operator SELECT.
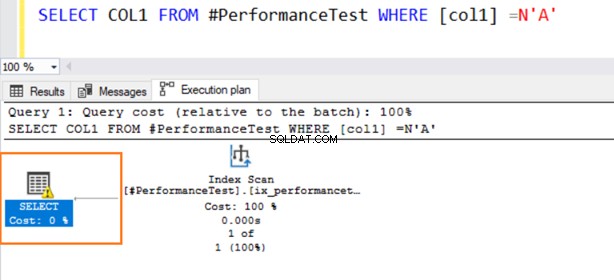
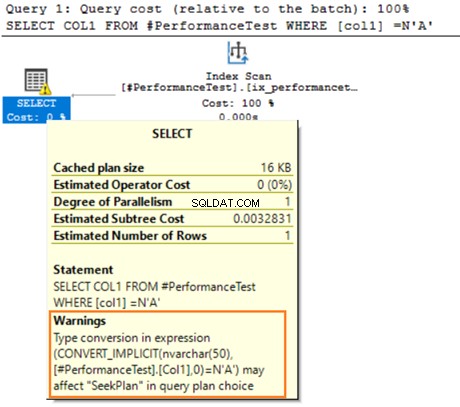
Arahkan mouse ke pernyataan SELECT yang mengeluarkan peringatan tentang konversi implisit. SQL Server tidak dapat menggunakan indeks yang ada dengan benar. Ini karena algoritma pengurutan data yang berbeda untuk tipe data VARCHAR dan NVARCHAR.
Jika tabel memiliki jutaan baris, SQL Server harus melakukan pekerjaan tambahan dan mengonversi data menggunakan konversi data secara implisit. Ini mungkin berdampak negatif pada kinerja kueri Anda. Oleh karena itu, Anda harus menghindari pencampuran dan pencocokan tipe data ini dalam mengoptimalkan kueri.
Kesimpulan
Anda harus meninjau persyaratan data Anda saat mendesain tabel database dan tipe data kolomnya dengan tepat. Biasanya, tipe data VARCHAR server sebagian besar kebutuhan data Anda. Namun, jika Anda perlu menyimpan tipe data Unicode dan non-Unicode dalam kolom, Anda dapat mempertimbangkan untuk menggunakan NVARCHAR. Namun, Anda harus meninjau implikasi kinerjanya, ukuran penyimpanannya sebelum membuat keputusan akhir.