Dalam artikel sebelumnya, kami mempelajari persyaratan indeks SQL Server dan pertimbangan performa. Dalam hal kinerja database, penyetelan kinerja tidak diragukan lagi, salah satu fungsi yang paling penting dan kompleks. Ini terdiri dari banyak area berbeda seperti pengoptimalan kueri SQL, penyetelan indeks, dan penyetelan sumber daya sistem, yang semuanya perlu dilakukan dengan benar agar berhasil mengambil data dengan cepat.
Ada beberapa area penting yang perlu dipertimbangkan ketika menyangkut indeks SQL Server, karena indeks tersebut dapat berdampak signifikan pada upaya penyetelan kinerja Anda dan kinerja basis data secara keseluruhan. Berikut adalah beberapa detail tentang masing-masing dan peran penting yang mereka mainkan.
praktik terbaik indeks SQL Server
1. Pahami bagaimana desain database memengaruhi indeks SQL Server
Persyaratan pengindeksan bervariasi antara database pemrosesan transaksi online (OLTP) dan pemrosesan analitik online (OLAP).
Dalam database OLTP, pengguna sering melakukan operasi baca-tulis, memasukkan data baru dan memodifikasi data yang ada. Mereka menggunakan kueri bahasa manipulasi data (Sisipkan, Perbarui, Hapus) bersama dengan pernyataan Pilih untuk pengambilan dan modifikasi data. Untuk database OLTP, yang terbaik adalah membuat indeks pada kolom Selected dari sebuah tabel. Beberapa indeks mungkin memiliki dampak kinerja negatif dan memberi tekanan pada sumber daya sistem. Sebagai gantinya, disarankan untuk membuat jumlah indeks minimum yang dapat memenuhi persyaratan pengindeksan Anda. Di database OLAP di sisi lain, Anda menggunakan sebagian besar pernyataan Select untuk mengambil data untuk tujuan analitis lebih lanjut. Dalam hal ini, Anda dapat menambahkan lebih banyak indeks dengan beberapa kolom kunci per indeks. Anda juga dapat memanfaatkan indeks columnstore untuk pengambilan data yang lebih cepat dalam kueri gudang data
2. Buat indeks untuk kebutuhan beban kerja Anda
Saat membuat tabel baru di database Anda, jangan hanya menambahkan indeks secara membabi buta. Terkadang, developer menempatkan satu indeks berkerumun dan beberapa indeks yang tidak berkerumun di dalamnya tanpa mencari kueri yang menggunakan indeks tersebut. Mungkin ada indeks yang tidak memenuhi persyaratan pengoptimal kueri; oleh karena itu, Anda harus menganalisis beban kerja dan kueri SQL dengan benar (prosedur tersimpan, fungsi, tampilan, dan kueri ad-hoc). Anda dapat menangkap beban kerja menggunakan profiler SQL, peristiwa yang diperluas, dan tampilan manajemen dinamis, lalu membuat indeks untuk mengoptimalkan kueri intensif sumber daya.
3. Buat indeks untuk kueri yang paling banyak digunakan dan paling sering digunakan
Penting untuk mengelompokkan beban kerja untuk kueri yang paling sering digunakan di sistem Anda. Dengan membuat indeks terbaik untuk kueri ini, ini akan mengurangi beban sistem Anda.
4. Terapkan praktik terbaik kolom kunci indeks SQL Server
Karena Anda dapat memiliki beberapa kolom dalam sebuah tabel, berikut adalah beberapa pertimbangan untuk kolom kunci indeks.
- Kolom dengan teks, gambar, ntext, varchar(max), nvarchar(max) dan varbinary(max) tidak dapat digunakan dalam kolom kunci indeks.
- Direkomendasikan untuk menggunakan tipe data integer di kolom kunci indeks. Ini memiliki kebutuhan ruang yang rendah dan bekerja secara efisien. Karena itu, Anda ingin membuat kolom kunci utama, biasanya pada tipe data integer.
- Anda hanya dapat menggunakan tipe data XML dalam indeks XML.
- Anda harus mempertimbangkan untuk membuat kunci utama untuk kolom dengan nilai unik. Jika tabel tidak memiliki kolom nilai unik, Anda dapat menentukan kolom identitas untuk tipe data integer. Kunci utama juga membuat indeks berkerumun untuk distribusi baris.
- Anda dapat mempertimbangkan kolom dengan nilai Unique dan Not NULL sebagai kandidat kunci indeks yang berguna.
- Anda harus membuat indeks berdasarkan predikat dalam klausa Where. Misalnya, Anda dapat mempertimbangkan kolom yang digunakan dalam klausa Where, SQL join, like, order by, group by predicates, dan seterusnya.
- Anda harus menggabungkan tabel dengan cara yang mengurangi jumlah baris untuk sisa kueri. Ini akan membantu pengoptimal kueri menyiapkan rencana eksekusi dengan sumber daya sistem minimum.
- Jika Anda menggunakan beberapa kolom untuk kunci indeks, penting juga untuk mempertimbangkan posisinya dalam kunci indeks.
- Anda juga harus mempertimbangkan untuk menggunakan kolom yang disertakan dalam indeks Anda.
5. Analisis distribusi data kolom indeks SQL Server Anda
Anda harus memeriksa distribusi data di kolom kunci indeks SQL Server. Kolom dengan nilai yang tidak unik dapat menyebabkan penundaan dalam pengambilan data dan mengakibatkan transaksi yang berjalan lama. Anda dapat menganalisis distribusi data menggunakan histogram dalam statistik.
6. Gunakan urutan pengurutan data
Anda juga harus mempertimbangkan persyaratan penyortiran data dalam kueri dan indeks Anda. Secara default, SQL Server mengurutkan data dalam urutan menaik dalam indeks. Misalkan Anda membuat indeks dalam urutan menaik, tetapi kueri Anda menggunakan klausa Order By untuk mengurutkan data dalam urutan menurun.
Misalnya, lihat rencana eksekusi aktual dari kueri berikut.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
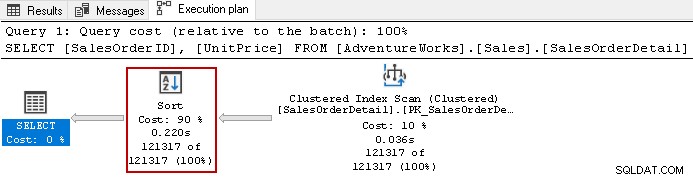
Ini menggunakan operator sortir yang mahal dengan biaya keseluruhan 90% dalam kueri ini. Kami memutuskan untuk membangun indeks non-cluster di [UnitPrice] dan [SalesOrderID]. Ini menggunakan urutan pengurutan default untuk kedua kolom dalam indeks.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Kami menjalankan kembali pernyataan Select dan pengoptimal kueri masih menggunakan operator sortir. Itu dapat menggunakan indeks non-cluster tetapi mengurutkan data untuk menyiapkan hasilnya.
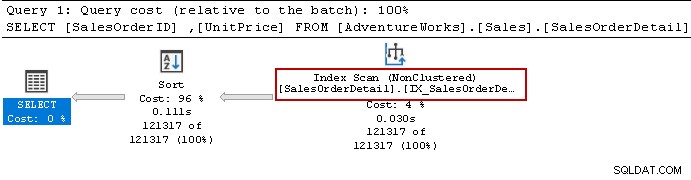
Mari buat ulang indeks menggunakan kueri berikut. Kali ini ia mengurutkan data dalam urutan menurun untuk [Unitprice] dalam definisi indeks.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
Itu tidak memerlukan operator pengurutan apa pun sekarang karena indeks memenuhi persyaratan kueri.
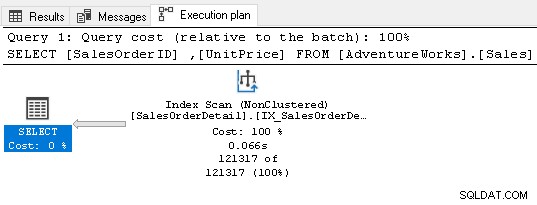
7. Gunakan kunci asing untuk indeks SQL Server Anda
Anda harus membuat indeks pada kolom kunci asing. Disarankan untuk membuat indeks berkerumun pada kunci asing untuk meningkatkan kinerja kueri.
8. Perhatikan pertimbangan penyimpanan indeks SQL Server
Penyimpanan indeks juga merupakan aspek yang berguna untuk dipertimbangkan. SQL Server membuat semua indeks pada filegroup yang sama dari tabel. Anda dapat mempertimbangkan filegroup terpisah untuk indeks dan memisahkan file fisik pada disk terpisah. Ini akan meningkatkan kinerja dan throughput IO.
Demikian pula, Anda dapat menggunakan partisi tabel untuk memisahkan data di beberapa disk dan grup file. Anda dapat mendesain indeks yang dipartisi untuk partisi tabel ini guna meningkatkan akses data secara bersamaan.
Pilihan lain adalah untuk mendefinisikan FILLFACTOR saat membuat atau membangun kembali sebuah indeks. FILLFACTOR mendefinisikan ruang kosong di halaman data simpul daun. Hal ini berguna untuk penyisipan data lebih lanjut. Jika data Anda statis dan tidak sering berubah, Anda dapat mempertimbangkan nilai FILLFACTOR yang tinggi. Di sisi lain, untuk data yang sering berubah, Anda dapat menyisakan cukup ruang untuk penyisipan data baru.
9. Temukan indeks yang hilang
Terkadang, Anda mendapatkan informasi tentang indeks SQL Server yang hilang dalam rencana eksekusi kueri. Anda juga dapat menjalankan tampilan manajemen dinamis untuk menemukan indeks yang hilang ini. Anda tidak boleh membabi buta membuat indeks ini. Ini hanyalah saran pengoptimal kueri, tetapi tidak mempertimbangkan indeks yang ada atau persyaratan beban kerja Anda. Ini mungkin juga menyertakan beberapa kolom dalam definisi indeks, jadi tinjau saran ini sebelum menerapkannya.
10. Selalu buat indeks berkerumun sebelum indeks yang tidak berkerumun
Sebagai pedoman umum, Anda harus membuat indeks berkerumun sebelum membangun indeks yang tidak berkerumun. Jika tabel tidak memiliki indeks, indeks non-cluster terdiri dari pengidentifikasi baris. Setelah Anda membuat indeks berkerumun, SQL Server perlu membangun kembali indeks yang tidak berkerumun ini sehingga indeks tersebut dapat menunjuk ke kunci indeks berkerumun alih-alih pengidentifikasi baris.
11. Memantau pemeliharaan indeks dan memperbarui statistik
Di bawah ini adalah beberapa area pemeliharaan yang harus dipantau terkait dengan indeks SQL Server.
- Hapus fragmentasi indeks :Anda harus meninjau fragmentasi internal dan eksternal secara berkala, terutama untuk tabel transaksi tinggi. Kueri Anda mungkin merespons dengan lambat bahkan jika Anda memiliki indeks yang tepat untuk beban kerja Anda. Indeks yang sangat terfragmentasi dapat menurunkan kinerja karena memerlukan IO tambahan. Anda dapat melakukan reorg atau membangun kembali indeks berdasarkan nilai fragmentasinya. Biasanya, Anda harus membangun kembali indeks jika memiliki fragmentasi lebih besar dari 30% dan mengatur ulang jika memiliki fragmentasi kurang dari 30%.
- Hapus indeks yang tidak digunakan: Anda harus selalu meninjau indeks yang tidak digunakan (idle) di database Anda karena pengoptimal kueri perlu mempertimbangkannya untuk setiap kueri. Indeks yang tidak digunakan juga menghabiskan penyimpanan dan meningkatkan biaya pemeliharaan.
- Perbarui statistik: Anda harus memperbarui statistik secara berkala bahkan jika Anda telah mengatur statistik pembaruan otomatis dalam konfigurasi database Anda. Pengoptimal kueri mungkin menyiapkan rencana eksekusi yang buruk jika statistik indeks tidak diperbarui. Anda dapat menjadwalkan tugas agen untuk memperbarui statistik SQL Server dengan pemindaian penuh setelah jam kerja.
Anda dapat merujuk ke Pemeliharaan indeks SQL untuk wawasan lebih lanjut tentang topik ini.
Menerapkan praktik terbaik indeks SQL Server
Meskipun, tidak selalu ada cara langsung untuk merancang indeks SQL Server yang optimal, menerapkan rekomendasi yang ditentukan dalam postingan ini akan membantu Anda menavigasi berbagai persyaratan pengindeksan yang akan Anda hadapi dengan setiap jenis database dan beban kerjanya. Praktik terbaik ini akan membantu mengoptimalkan indeks Anda untuk meningkatkan performa database dan memastikan proses penyesuaian performa yang lebih lancar.