Tugas Kesenjangan dan Pulau adalah tantangan kueri klasik di mana Anda perlu mengidentifikasi rentang nilai yang hilang dan rentang nilai yang ada secara berurutan. Urutan sering didasarkan pada beberapa tanggal, atau nilai tanggal dan waktu, yang biasanya muncul dalam interval reguler, tetapi beberapa entri hilang. Tugas celah mencari periode yang hilang dan tugas pulau mencari periode yang ada. Saya membahas banyak solusi untuk kesenjangan dan tugas pulau di buku dan artikel saya di masa lalu. Baru-baru ini saya dihadapkan dengan tantangan pulau khusus baru oleh teman saya, Adam Machanic, dan menyelesaikannya membutuhkan sedikit kreativitas. Dalam artikel ini saya menyajikan tantangan dan solusi yang saya temukan.
Tantangan
Dalam database Anda, Anda melacak layanan yang didukung perusahaan Anda dalam tabel yang disebut CompanyServices, dan setiap layanan biasanya melaporkan sekitar satu menit bahwa layanan tersebut online dalam tabel yang disebut EventLog. Kode berikut membuat tabel ini dan mengisinya dengan kumpulan kecil data sampel:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
Tabel EventLog saat ini diisi dengan data berikut:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Tugas pulau khusus adalah mengidentifikasi periode ketersediaan (dilayani, waktu mulai, waktu berakhir). Satu hal yang menarik adalah bahwa tidak ada jaminan bahwa suatu layanan akan melaporkan bahwa itu online tepat setiap menit; Anda seharusnya mentolerir interval hingga, katakanlah, 66 detik dari entri log sebelumnya dan masih menganggapnya sebagai bagian dari periode ketersediaan yang sama (pulau). Lebih dari 66 detik, entri log baru memulai periode ketersediaan baru. Jadi, untuk data sampel input di atas, solusi Anda seharusnya mengembalikan kumpulan hasil berikut (tidak harus dalam urutan ini):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Perhatikan, misalnya, bagaimana entri log 5 memulai pulau baru karena interval dari entri log sebelumnya adalah 120 detik (> 66), sedangkan entri log 6 tidak memulai pulau baru karena interval dari entri sebelumnya adalah 62 detik ( <=66). Tangkapan lainnya adalah bahwa Adam ingin solusinya kompatibel dengan lingkungan pra-SQL Server 2012, yang menjadikannya tantangan yang jauh lebih sulit, karena Anda tidak dapat menggunakan fungsi agregat jendela dengan bingkai untuk menghitung total yang berjalan dan mengimbangi fungsi jendela seperti LAG dan LEAD.Seperti biasa, saya sarankan untuk mencoba memecahkan tantangan sendiri sebelum melihat solusi saya. Gunakan kumpulan kecil data sampel untuk memeriksa validitas solusi Anda. Gunakan kode berikut untuk mengisi tabel Anda dengan kumpulan besar data sampel (500 layanan, ~10 juta entri log untuk menguji kinerja solusi Anda):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Output yang akan saya berikan untuk langkah-langkah solusi saya akan mengasumsikan kumpulan kecil data sampel, dan angka kinerja yang akan saya berikan akan mengasumsikan kumpulan besar.
Semua solusi yang akan saya sajikan mendapat manfaat dari indeks berikut:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Semoga berhasil!
Solusi 1 untuk SQL Server 2012+
Sebelum saya membahas solusi yang kompatibel dengan lingkungan pra-SQL Server 2012, saya akan membahas solusi yang membutuhkan minimal SQL Server 2012. Saya akan menyebutnya Solusi 1.
Langkah pertama dalam penyelesaiannya adalah menghitung flag yang disebut isstart yaitu 0 jika event tidak memulai pulau baru, dan 1 sebaliknya. Hal ini dapat dicapai dengan menggunakan fungsi LAG untuk mendapatkan waktu log dari peristiwa sebelumnya dan memeriksa apakah perbedaan waktu dalam detik antara peristiwa sebelumnya dan saat ini kurang dari atau sama dengan jarak yang diizinkan. Berikut kode yang mengimplementasikan langkah ini:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Kode ini menghasilkan output berikut:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Selanjutnya, total berjalan sederhana dari flag isstart menghasilkan pengidentifikasi pulau (saya akan menyebutnya grp). Berikut kode yang mengimplementasikan langkah ini:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Kode ini menghasilkan output berikut:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Terakhir, Anda mengelompokkan baris berdasarkan ID layanan dan pengidentifikasi pulau dan mengembalikan waktu log minimum dan maksimum sebagai waktu mulai dan waktu berakhir setiap pulau. Inilah solusi lengkapnya:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
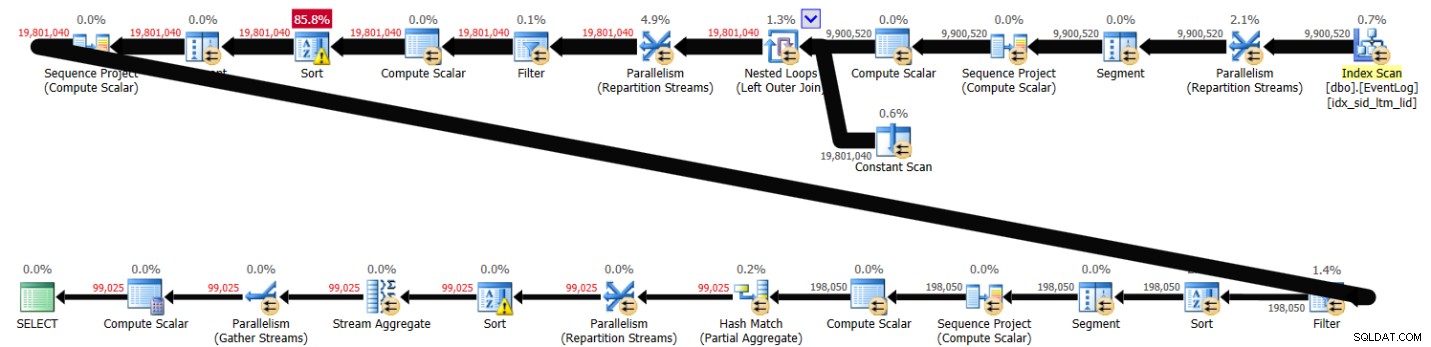
GROUP BY serviceid, grp; Solusi ini membutuhkan waktu 41 detik untuk diselesaikan di sistem saya, dan menghasilkan rencana yang ditunjukkan pada Gambar 1.
 Gambar 1:Rencanakan Solusi 1
Gambar 1:Rencanakan Solusi 1
Seperti yang Anda lihat, kedua fungsi jendela dihitung berdasarkan urutan indeks, tanpa perlu penyortiran eksplisit.
Jika Anda menggunakan SQL Server 2016 atau yang lebih baru, Anda dapat menggunakan trik yang saya bahas di sini untuk mengaktifkan operator Agregat Jendela mode batch dengan membuat indeks penyimpanan kolom terfilter kosong, seperti:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Solusi yang sama sekarang hanya membutuhkan 5 detik untuk diselesaikan di sistem saya, menghasilkan rencana yang ditunjukkan pada Gambar 2.
 Gambar 2:Rencanakan Solusi 1 menggunakan mode batch Operator Agregat Jendela
Gambar 2:Rencanakan Solusi 1 menggunakan mode batch Operator Agregat Jendela
Ini semua bagus, tetapi seperti yang disebutkan, Adam sedang mencari solusi yang dapat berjalan di lingkungan pra-2012.
Sebelum melanjutkan, pastikan Anda menghapus indeks columnstore untuk pembersihan:
DROP INDEX idx_cs ON dbo.EventLog;
Solusi 2 untuk lingkungan pra-SQL Server 2012
Sayangnya, sebelum SQL Server 2012, kami tidak memiliki dukungan untuk fungsi jendela offset seperti LAG, kami juga tidak memiliki dukungan untuk menghitung total yang berjalan dengan fungsi agregat jendela dengan bingkai. Ini berarti Anda harus bekerja lebih keras untuk menemukan solusi yang masuk akal.
Trik yang saya gunakan adalah mengubah setiap entri log menjadi interval buatan yang waktu mulainya adalah waktu log entri dan waktu berakhirnya adalah waktu log entri ditambah celah yang diizinkan. Anda kemudian dapat memperlakukan tugas tersebut sebagai tugas pengepakan interval klasik.
Langkah pertama dalam solusi menghitung pembatas interval buatan, dan nomor baris menandai posisi masing-masing jenis peristiwa (counteach). Berikut kode yang mengimplementasikan langkah ini:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Kode ini menghasilkan output berikut:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Langkah selanjutnya adalah memisahkan interval menjadi urutan kronologis dari peristiwa awal dan akhir, yang diidentifikasi sebagai jenis peristiwa 's' dan 'e', masing-masing. Perhatikan bahwa pemilihan huruf s dan e penting ('s' > 'e' ). Langkah ini menghitung nomor baris yang menandai urutan kronologis yang benar dari kedua jenis peristiwa, yang sekarang disisipkan (countboth). Jika satu interval berakhir tepat di tempat yang lain dimulai, dengan memposisikan acara awal sebelum acara akhir, Anda akan mengemasnya bersama-sama. Berikut kode yang mengimplementasikan langkah ini:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Kode ini menghasilkan output berikut:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Seperti yang disebutkan, counteach menandai posisi peristiwa hanya di antara peristiwa dari jenis yang sama, dan countboth menandai posisi peristiwa di antara gabungan, interleaved, peristiwa dari kedua jenis.
Keajaiban itu kemudian ditangani oleh langkah berikutnya—menghitung jumlah interval aktif setelah setiap peristiwa berdasarkan penghitungan dan penghitungan keduanya. Jumlah interval aktif adalah jumlah kejadian awal yang terjadi sejauh ini dikurangi jumlah kejadian akhir yang terjadi sejauh ini. Untuk acara awal, counteach memberi tahu Anda berapa banyak acara awal yang terjadi sejauh ini, dan Anda dapat mengetahui berapa banyak yang berakhir sejauh ini dengan mengurangkan counteach dari countboth. Jadi, ekspresi lengkap yang memberi tahu Anda berapa banyak interval yang aktif adalah:
counteach - (countboth - counteach)
Untuk acara akhir, counteach memberi tahu Anda berapa banyak peristiwa akhir yang terjadi sejauh ini, dan Anda dapat mengetahui berapa banyak yang dimulai sejauh ini dengan mengurangkan counteach dari countboth. Jadi, ekspresi lengkap yang memberi tahu Anda berapa banyak interval yang aktif adalah:
(countboth - counteach) - counteach
Dengan menggunakan ekspresi CASE berikut, Anda menghitung kolom hitung berdasarkan jenis peristiwa:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Pada langkah yang sama, Anda hanya memfilter peristiwa yang mewakili awal dan akhir interval yang dikemas. Awal interval kemas memiliki tipe 's' dan countactive 1. Ujung interval kemas memiliki tipe 'e' dan countactive 0.
Setelah memfilter, Anda memiliki pasangan acara awal-akhir dari interval yang dikemas, tetapi setiap pasangan dibagi menjadi dua baris—satu untuk acara awal dan satu lagi untuk acara akhir. Oleh karena itu, langkah yang sama menghitung pengenal pasangan dengan menggunakan nomor baris, dengan rumus (nomor baris – 1) / 2 + 1.
Berikut kode yang mengimplementasikan langkah ini:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Kode ini menghasilkan output berikut:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Langkah terakhir memutar pasangan peristiwa menjadi satu baris per interval, dan mengurangi celah yang diizinkan dari waktu akhir untuk membuat ulang waktu peristiwa yang benar. Berikut kode solusi lengkapnya:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
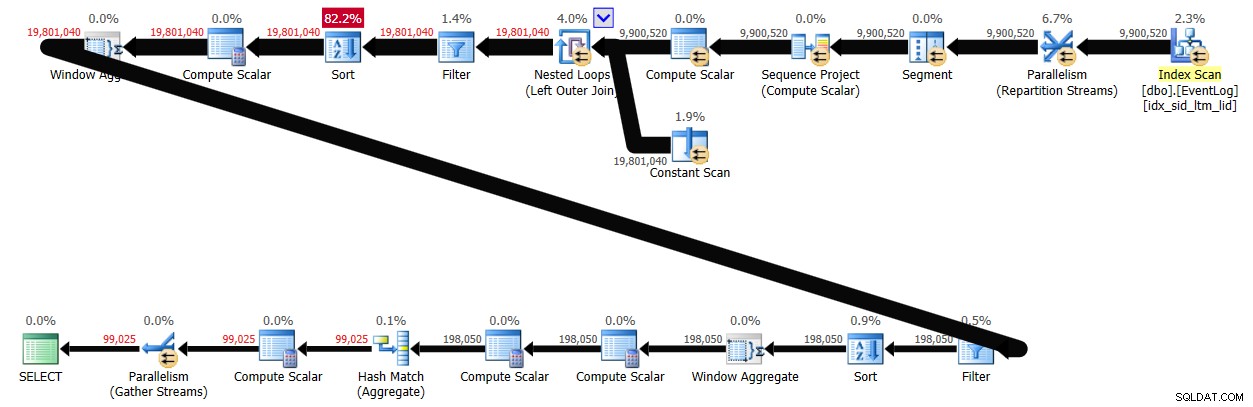
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Solusi ini membutuhkan waktu 43 detik untuk diselesaikan di sistem saya dan menghasilkan rencana yang ditunjukkan pada Gambar 3.
 Gambar 3:Rencanakan Solusi 2
Gambar 3:Rencanakan Solusi 2
Seperti yang Anda lihat, penghitungan nomor baris pertama dihitung berdasarkan urutan indeks, tetapi dua berikutnya melibatkan penyortiran eksplisit. Namun, performanya tidak terlalu buruk mengingat ada sekitar 10.000.000 baris yang terlibat.
Meskipun poin tentang solusi ini adalah menggunakan lingkungan pra-SQL Server 2012, hanya untuk bersenang-senang, saya menguji kinerjanya setelah membuat indeks columnstore yang difilter untuk melihat bagaimana hasilnya dengan pemrosesan batch diaktifkan:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Dengan mengaktifkan pemrosesan batch, solusi ini membutuhkan waktu 29 detik untuk diselesaikan di sistem saya, menghasilkan rencana yang ditunjukkan pada Gambar 4.
Kesimpulan
Wajar jika semakin terbatas lingkungan Anda, semakin menantang untuk menyelesaikan tugas kueri. Tantangan Kepulauan khusus Adam jauh lebih mudah diselesaikan pada versi SQL Server yang lebih baru daripada yang lebih lama. Tapi kemudian Anda memaksakan diri untuk menggunakan teknik yang lebih kreatif. Jadi sebagai latihan, untuk meningkatkan keterampilan kueri Anda, Anda dapat mengatasi tantangan yang sudah Anda kenal, tetapi dengan sengaja menerapkan batasan tertentu. Anda tidak pernah tahu ide menarik seperti apa yang mungkin Anda temukan!