[ Bagian 1 | Bagian 2 | Bagian 3 | Bagian 4 ]
Di bagian 3 seri ini, saya menunjukkan dua solusi untuk menghindari pelebaran IDENTITY kolom – kolom yang hanya memberi Anda waktu, dan kolom lain yang mengabaikan IDENTITY sama sekali. Yang pertama mencegah Anda dari harus berurusan dengan dependensi eksternal seperti kunci asing, tetapi yang terakhir masih tidak mengatasi masalah itu. Dalam posting ini, saya ingin merinci pendekatan yang akan saya ambil jika saya benar-benar perlu pindah ke bigint , diperlukan untuk meminimalkan waktu henti, dan memiliki banyak waktu untuk perencanaan.
Karena semua pemblokir potensial dan kebutuhan untuk gangguan minimal, pendekatan ini mungkin terlihat sedikit rumit, dan hanya akan menjadi lebih rumit jika fitur eksotis tambahan digunakan (misalnya, partisi, OLTP Dalam Memori, atau replikasi) .
Pada tingkat yang sangat tinggi, pendekatannya adalah membuat satu set tabel bayangan, di mana semua sisipan diarahkan ke salinan tabel yang baru (dengan tipe data yang lebih besar), dan keberadaan dua set tabel sama transparannya. mungkin untuk aplikasi dan penggunanya.
Pada tingkat yang lebih terperinci, rangkaian langkah-langkahnya adalah sebagai berikut:
- Buat salinan bayangan tabel, dengan tipe data yang tepat.
- Ubah prosedur tersimpan (atau kode ad hoc) untuk menggunakan parameter bigint. (Ini mungkin memerlukan modifikasi di luar daftar parameter, seperti variabel lokal, tabel temp, dll., tetapi ini tidak terjadi di sini.)
- Ganti nama tabel lama, dan buat tampilan dengan nama yang menyatukan tabel lama dan baru.
- Tampilan tersebut akan memiliki alih-alih pemicu untuk mengarahkan operasi DML dengan benar ke tabel yang sesuai, sehingga data tetap dapat dimodifikasi selama migrasi.
- Ini juga mengharuskan SCHEMABINDING untuk dihapus dari tampilan yang diindeks, tampilan yang ada untuk memiliki gabungan antara tabel baru dan lama, dan prosedur yang mengandalkan SCOPE_IDENTITY() untuk dimodifikasi.
- Migrasikan data lama ke tabel baru dalam beberapa bagian.
- Bersihkan, terdiri dari:
- Menghapus tampilan sementara (yang akan menghilangkan pemicu BUKAN).
- Mengganti nama tabel baru kembali ke nama aslinya.
- Memperbaiki prosedur tersimpan untuk kembali ke SCOPE_IDENTITY().
- Menghapus tabel lama yang sekarang kosong.
- Mengembalikan SCHEMABINDING pada tampilan yang diindeks dan membuat kembali indeks yang dikelompokkan.
Anda mungkin dapat menghindari banyak tampilan dan pemicu jika Anda dapat mengontrol semua akses data melalui prosedur tersimpan, tetapi karena skenario itu jarang terjadi (dan tidak mungkin dipercaya 100%), saya akan menunjukkan rute yang lebih sulit.
Skema Awal
Dalam upaya untuk menjaga pendekatan ini sesederhana mungkin, sambil tetap menangani banyak pemblokir yang saya sebutkan sebelumnya dalam seri ini, mari kita asumsikan kita memiliki skema ini:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Jadi tabel personalia sederhana, dengan kolom IDENTITAS berkerumun, indeks tidak berkerumun, kolom yang dihitung berdasarkan kolom IDENTITAS, tampilan yang diindeks, dan tabel SDM/dirt terpisah yang memiliki kunci asing kembali ke tabel personalia (I saya tidak selalu mendorong desain itu, hanya menggunakannya untuk contoh ini). Ini semua adalah hal yang membuat masalah ini lebih rumit daripada jika kita memiliki tabel yang berdiri sendiri dan independen.
Dengan skema itu, kami mungkin memiliki beberapa prosedur tersimpan yang melakukan hal-hal seperti CRUD. Ini lebih untuk kepentingan dokumentasi daripada apa pun; Saya akan membuat perubahan pada skema yang mendasarinya sehingga mengubah prosedur ini harus minimal. Ini untuk mensimulasikan fakta bahwa mengubah SQL ad hoc dari aplikasi Anda mungkin tidak dapat dilakukan, dan mungkin tidak diperlukan (well, selama Anda tidak menggunakan ORM yang dapat mendeteksi tabel vs. tampilan).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Sekarang, mari tambahkan 5 baris data ke tabel aslinya:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Langkah 1 – tabel baru
Di sini kita akan membuat sepasang tabel baru, mencerminkan aslinya kecuali untuk tipe data kolom EmployeeID, seed awal untuk kolom IDENTITY, dan sufiks sementara pada nama:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Langkah 2 – perbaiki parameter prosedur
Prosedur di sini (dan kemungkinan kode ad hoc Anda, kecuali jika sudah menggunakan tipe bilangan bulat yang lebih besar) akan memerlukan perubahan yang sangat kecil sehingga di masa mendatang mereka akan dapat menerima nilai EmployeeID di luar batas atas bilangan bulat. Meskipun Anda dapat berargumen bahwa jika Anda akan mengubah prosedur ini, Anda cukup mengarahkannya ke tabel baru, saya mencoba membuat kasus bahwa Anda dapat mencapai tujuan akhir dengan * minimal * intrusi ke dalam yang ada, permanen kode.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Langkah 3 – tampilan dan pemicu
Sayangnya, ini tidak *semua* bisa dilakukan secara diam-diam. Kami dapat melakukan sebagian besar operasi secara paralel dan tanpa memengaruhi penggunaan bersamaan, tetapi karena SCHEMABINDING, tampilan yang diindeks harus diubah dan indeks kemudian dibuat ulang.
Ini berlaku untuk objek lain yang menggunakan SCHEMABINDING dan merujuk salah satu tabel kami. Saya sarankan mengubahnya menjadi tampilan yang tidak diindeks di awal operasi, dan hanya membangun kembali indeks sekali setelah semua data dimigrasikan, daripada beberapa kali dalam proses (karena tabel akan diganti namanya beberapa kali). Sebenarnya yang akan saya lakukan adalah mengubah tampilan untuk menggabungkan tabel Karyawan versi baru dan lama selama proses berlangsung.
Satu hal lain yang perlu kita lakukan adalah mengubah prosedur tersimpan Employee_Add untuk menggunakan @@IDENTITY alih-alih SCOPE_IDENTITY(), untuk sementara. Ini karena pemicu BUKAN yang akan menangani pembaruan baru untuk "Karyawan" tidak akan memiliki visibilitas nilai SCOPE_IDENTITY(). Ini, tentu saja, mengasumsikan bahwa tabel tidak memiliki pemicu setelah yang akan memengaruhi @@IDENTITY. Semoga Anda dapat mengubah kueri ini di dalam prosedur tersimpan (di mana Anda cukup mengarahkan INSERT ke tabel baru), atau kode aplikasi Anda tidak perlu bergantung pada SCOPE_IDENTITY() sejak awal.
Kami akan melakukan ini di bawah SERIALIZABLE sehingga tidak ada transaksi yang mencoba menyelinap masuk saat objek sedang berubah. Ini adalah serangkaian operasi yang sebagian besar hanya metadata, jadi harus cepat.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Langkah 4 – Migrasikan data lama ke tabel baru
Kami akan memigrasikan data dalam potongan untuk meminimalkan dampak pada konkurensi dan log transaksi, meminjam teknik dasar dari posting lama saya, "Pecah operasi penghapusan besar menjadi beberapa bagian." Kami juga akan menjalankan kumpulan ini dalam SERIALIZABLE, yang berarti Anda harus berhati-hati dengan ukuran kumpulan, dan saya mengabaikan penanganan kesalahan untuk singkatnya.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Hasil:
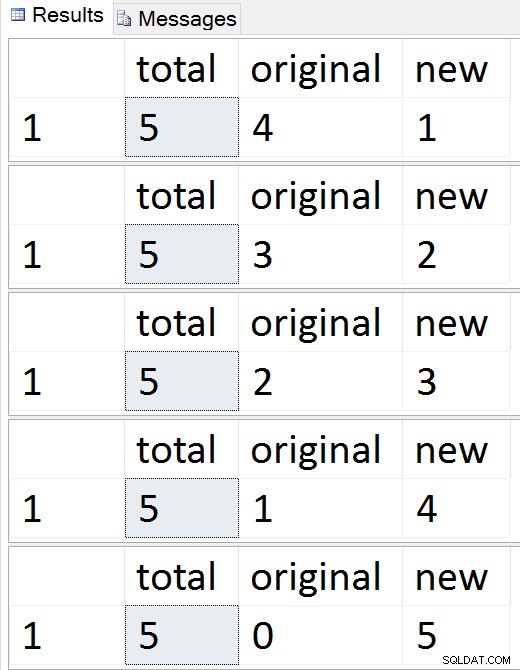 Lihat baris bermigrasi satu per satu
Lihat baris bermigrasi satu per satu
Kapan saja selama urutan itu, Anda dapat menguji sisipan, pembaruan, dan penghapusan, dan mereka harus ditangani dengan tepat. Setelah migrasi selesai, Anda dapat melanjutkan ke proses selanjutnya.
Langkah 5 – Bersihkan
Serangkaian langkah diperlukan untuk membersihkan objek yang dibuat sementara dan untuk memulihkan Karyawan / EmployeeFile sebagai warga kelas satu yang semestinya. Sebagian besar dari perintah ini hanyalah operasi metadata – dengan pengecualian membuat indeks berkerumun pada tampilan yang diindeks, semuanya harus instan.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO Pada titik ini, semuanya harus kembali ke operasi normal, meskipun Anda mungkin ingin mempertimbangkan aktivitas pemeliharaan umum setelah perubahan skema besar, seperti memperbarui statistik, membangun kembali indeks, atau menghapus rencana dari cache.
Kesimpulan
Ini adalah solusi yang cukup kompleks untuk apa yang seharusnya menjadi masalah sederhana. Saya berharap bahwa di beberapa titik SQL Server memungkinkan untuk melakukan hal-hal seperti menambah/menghapus properti IDENTITY, membangun kembali indeks dengan tipe data target baru, dan mengubah kolom di kedua sisi hubungan tanpa mengorbankan hubungan. Sementara itu, saya tertarik untuk mengetahui apakah solusi ini membantu Anda, atau jika Anda memiliki pendekatan yang berbeda.
Teriakan keras untuk James Lupolt (@jlupoltsql) karena membantu memeriksa kewarasan saya, dan mengujinya di salah satu tabel aslinya sendiri. (Itu berjalan dengan baik. Terima kasih James!)
—
[ Bagian 1 | Bagian 2 | Bagian 3 | Bagian 4 ]