Definisi sederhana dari median adalah:
Median adalah nilai tengah dalam daftar angka yang diurutkanUntuk sedikit menyempurnakannya, kita dapat menemukan median dari daftar angka menggunakan prosedur berikut:
- Urutkan angka (dalam urutan menaik atau menurun, tidak masalah yang mana).
- Angka tengah (berdasarkan posisi) dalam daftar yang diurutkan adalah median.
- Jika ada dua angka "sama tengah", median adalah rata-rata dari dua nilai tengah.
Aaron Bertrand sebelumnya telah menguji kinerja beberapa cara untuk menghitung median di SQL Server:
- Apa cara tercepat untuk menghitung median?
- Pendekatan terbaik untuk median yang dikelompokkan
Rob Farley baru-baru ini menambahkan pendekatan lain yang ditujukan untuk instalasi pra-2012:
- Median sebelum SQL 2012
Artikel ini memperkenalkan metode baru menggunakan kursor dinamis.
Metode OFFSET-FETCH 2012
Kita akan mulai dengan melihat implementasi berkinerja terbaik, yang dibuat oleh Peter Larsson. Ini menggunakan OFFSET SQL Server 2012 ekstensi ke ORDER BY klausa untuk secara efisien menemukan satu atau dua baris tengah yang diperlukan untuk menghitung median.
OFFSET Median Tunggal
Artikel pertama Aaron menguji komputasi satu median lebih dari sepuluh juta tabel baris:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Solusi Peter Larsson menggunakan OFFSET ekstensinya adalah:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Kode di atas mengkodekan hasil penghitungan baris dalam tabel. Semua metode yang diuji untuk menghitung median membutuhkan hitungan ini untuk menghitung nomor baris median, jadi ini adalah biaya konstan. Meninggalkan operasi penghitungan baris di luar pengaturan waktu akan menghindari satu kemungkinan sumber variasi.
Rencana eksekusi untuk OFFSET solusi ditunjukkan di bawah ini:

Operator Top dengan cepat melewati baris yang tidak perlu, melewati hanya satu atau dua baris yang diperlukan untuk menghitung median ke Stream Aggregate. Saat dijalankan dengan cache hangat dan kumpulan rencana eksekusi disetel, kueri ini berjalan selama 910 md rata-rata di laptop saya. Ini adalah mesin dengan prosesor Intel i7 740QM yang berjalan pada 1,73 GHz dengan Turbo dinonaktifkan (untuk konsistensi).
Median Pengelompokan OFFSET
Artikel kedua Aaron menguji kinerja penghitungan median per grup, menggunakan tabel Penjualan sejuta baris dengan sepuluh ribu entri untuk masing-masing dari seratus staf penjualan:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Sekali lagi, solusi berkinerja terbaik menggunakan OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Bagian penting dari rencana eksekusi ditunjukkan di bawah ini:

Baris atas rencana berkaitan dengan menemukan jumlah baris grup untuk setiap staf penjualan. Baris bawah menggunakan elemen rencana yang sama yang terlihat untuk solusi median grup tunggal untuk menghitung median untuk setiap staf penjualan. Saat dijalankan dengan cache hangat dan rencana eksekusi dimatikan, kueri ini dijalankan dalam 320 md rata-rata di laptop saya.
Menggunakan Kursor Dinamis
Mungkin tampak gila untuk berpikir tentang menggunakan kursor untuk menghitung median. Kursor transaksi SQL memiliki reputasi (kebanyakan memang layak) karena lambat dan tidak efisien. Juga sering dianggap bahwa kursor dinamis adalah jenis kursor terburuk. Poin-poin ini valid dalam beberapa keadaan, tetapi tidak selalu.
Kursor Transact SQL terbatas untuk memproses satu baris pada satu waktu, sehingga memang bisa lambat jika banyak baris perlu diambil dan diproses. Namun, tidak demikian halnya dengan perhitungan median:yang perlu kita lakukan hanyalah mencari dan mengambil satu atau dua nilai tengah secara efisien . Kursor dinamis sangat cocok untuk tugas ini seperti yang akan kita lihat nanti.
Kursor Dinamis Median Tunggal
Solusi kursor dinamis untuk perhitungan median tunggal terdiri dari langkah-langkah berikut:
- Buat kursor dinamis yang dapat digulir di atas daftar item yang diurutkan.
- Menghitung posisi baris median pertama.
- Reposisi kursor menggunakan
FETCH RELATIVE. - Tentukan apakah baris kedua diperlukan untuk menghitung median.
- Jika tidak, segera kembalikan nilai median tunggal.
- Jika tidak, ambil nilai kedua menggunakan
FETCH NEXT. - Hitung rata-rata dari dua nilai dan kembalikan.
Perhatikan seberapa dekat daftar itu mencerminkan prosedur sederhana untuk menemukan median yang diberikan di awal artikel ini. Implementasi kode Transact SQL lengkap ditunjukkan di bawah ini:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
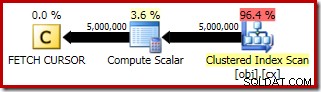
Rencana eksekusi untuk FETCH RELATIVE pernyataan menunjukkan kursor dinamis secara efisien memposisikan ulang ke baris pertama yang diperlukan untuk perhitungan median:
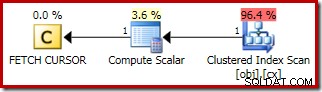
Paket untuk FETCH NEXT (hanya diperlukan jika ada baris tengah kedua, seperti dalam pengujian ini) adalah pengambilan baris tunggal dari posisi kursor yang disimpan:
Keuntungan menggunakan kursor dinamis di sini adalah:
- Ini menghindari melintasi seluruh set (membaca berhenti setelah baris median ditemukan); dan
- Tidak ada salinan data sementara yang dibuat di tempdb , seperti untuk kursor statis atau keyset.
Perhatikan bahwa kami tidak dapat menentukan FAST_FORWARD kursor di sini (menyerahkan pilihan paket seperti statis atau dinamis ke pengoptimal) karena kursor harus dapat digulir untuk mendukung FETCH RELATIVE . Dinamis adalah pilihan yang optimal di sini.
Saat dijalankan dengan cache hangat dan kumpulan rencana eksekusi disetel, kueri ini berjalan selama 930 md rata-rata pada mesin uji saya. Ini sedikit lebih lambat dari 910 md untuk OFFSET solusi, tetapi kursor dinamis secara signifikan lebih cepat daripada metode lain yang diuji Aaron dan Rob, dan tidak memerlukan SQL Server 2012 (atau lebih baru).
Saya tidak akan mengulangi pengujian metode pra-2012 lainnya di sini, tetapi sebagai contoh ukuran kesenjangan kinerja, solusi penomoran baris berikut membutuhkan waktu 1550 md rata-rata (70% lebih lambat):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Uji Kursor Dinamis Median Berkelompok
Sangat mudah untuk memperluas solusi kursor dinamis median tunggal untuk menghitung median yang dikelompokkan. Demi konsistensi, saya akan menggunakan kursor bersarang (ya, sungguh):
- Buka kursor statis di atas staf penjualan dan jumlah baris.
- Hitung median untuk setiap orang menggunakan kursor dinamis baru setiap kali.
- Simpan setiap hasil ke variabel tabel saat kita melanjutkan.
Kodenya ditunjukkan di bawah ini:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Kursor luar sengaja dibuat statis karena semua baris dalam kumpulan itu akan disentuh (juga, kursor dinamis tidak tersedia karena operasi pengelompokan dalam kueri yang mendasarinya). Tidak ada yang sangat baru atau menarik untuk dilihat dalam rencana eksekusi kali ini.
Yang menarik adalah performanya. Meskipun pembuatan dan dealokasi kursor dinamis dalam berulang kali, solusi ini bekerja dengan sangat baik pada kumpulan data pengujian. Dengan cache hangat dan rencana eksekusi dimatikan, skrip kursor selesai dalam 330 md rata-rata pada mesin uji saya. Sekali lagi ini sedikit lebih lambat dari 320 md direkam oleh OFFSET median yang dikelompokkan, tetapi ini mengalahkan solusi standar lain yang tercantum dalam artikel Aaron dan Rob dengan selisih yang besar.
Sekali lagi, sebagai contoh kesenjangan kinerja dengan metode non-2012 lainnya, solusi penomoran baris berikut berjalan untuk 485 md rata-rata di rig pengujian saya (50% lebih buruk):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Ringkasan Hasil
Dalam pengujian median tunggal, kursor dinamis berjalan selama 930 md versus 910 md untuk OFFSET metode.
Dalam pengujian median yang dikelompokkan, kursor bersarang berjalan selama 330 md versus 320 md untuk OFFSET .
Dalam kedua kasus, metode kursor secara signifikan lebih cepat daripada metode non-OFFSET lainnya metode. Jika Anda perlu menghitung median tunggal atau berkelompok pada instans pra-2012, kursor dinamis atau kursor bersarang benar-benar bisa menjadi pilihan yang optimal.
Kinerja Cache Dingin
Beberapa dari Anda mungkin bertanya-tanya tentang kinerja cache dingin. Menjalankan yang berikut ini sebelum setiap pengujian:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Ini adalah hasil untuk pengujian median tunggal:
OFFSET metode:940 md
Kursor dinamis:955 md
Untuk median yang dikelompokkan:
OFFSET metode:380 md
Kursor bertingkat:385 md
Pemikiran Akhir
Solusi kursor dinamis benar-benar jauh lebih cepat daripada non-OFFSET metode untuk median tunggal dan berkelompok, setidaknya dengan kumpulan data sampel ini. Saya sengaja memilih untuk menggunakan kembali data uji Aaron sehingga kumpulan data tidak sengaja condong ke arah kursor dinamis. Ada mungkin menjadi distribusi data lain yang kursor dinamisnya bukan pilihan yang baik. Namun demikian, ini menunjukkan bahwa masih ada saat-saat kursor dapat menjadi solusi yang cepat dan efisien untuk jenis masalah yang tepat. Bahkan kursor dinamis dan bersarang.
Pembaca bermata elang mungkin telah memperhatikan PAGLOCK petunjuk di OFFSET tes median berkelompok. Ini diperlukan untuk kinerja terbaik, untuk alasan yang akan saya bahas di artikel saya berikutnya. Tanpa itu, solusi 2012 benar-benar kehilangan kursor bersarang dengan margin yang layak (590 md versus 330 md ).