Dalam artikel ini, saya melanjutkan liputan solusi untuk tantangan penawaran dan permintaan yang menarik dari Peter Larsson. Sekali lagi terima kasih kepada Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, dan Peter Larsson, yang telah mengirimkan solusi Anda.
Bulan lalu saya membahas solusi berdasarkan persimpangan interval, menggunakan tes persimpangan interval berbasis predikat klasik. Saya akan menyebut solusi itu sebagai persimpangan klasik . Pendekatan simpang interval klasik menghasilkan denah dengan skala kuadrat (N^2). Saya menunjukkan kinerjanya yang buruk terhadap input sampel mulai dari 100K hingga 400K baris. Butuh solusi 931 detik untuk menyelesaikan input 400K-baris! Bulan ini saya akan mulai dengan mengingatkan Anda secara singkat tentang solusi bulan lalu dan mengapa skala dan kinerjanya sangat buruk. Saya kemudian akan memperkenalkan pendekatan berdasarkan revisi tes persimpangan interval. Pendekatan ini digunakan oleh Luca, Kamil, dan mungkin juga Daniel, dan memungkinkan solusi dengan kinerja dan skala yang jauh lebih baik. Saya akan menyebut solusi itu sebagai persimpangan yang direvisi .
Masalah Dengan Uji Persimpangan Klasik
Mari kita mulai dengan pengingat cepat tentang solusi bulan lalu.
Saya menggunakan indeks berikut pada tabel input dbo.Auctions untuk mendukung penghitungan total berjalan yang menghasilkan interval permintaan dan penawaran:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Kode berikut memiliki solusi lengkap yang menerapkan pendekatan persimpangan interval klasik:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; Kode ini dimulai dengan menghitung interval permintaan dan penawaran dan menuliskannya ke tabel sementara yang disebut #Demand dan #Supply. Kode kemudian membuat indeks berkerumun di #Supply dengan EndSupply sebagai kunci utama untuk mendukung pengujian persimpangan sebaik mungkin. Terakhir, kode tersebut menggabungkan #Supply dan #Demand, mengidentifikasi perdagangan sebagai segmen yang tumpang tindih dari interval berpotongan, menggunakan predikat gabungan berikut berdasarkan uji persimpangan interval klasik:
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
Rencana untuk solusi ini ditunjukkan pada Gambar 1.
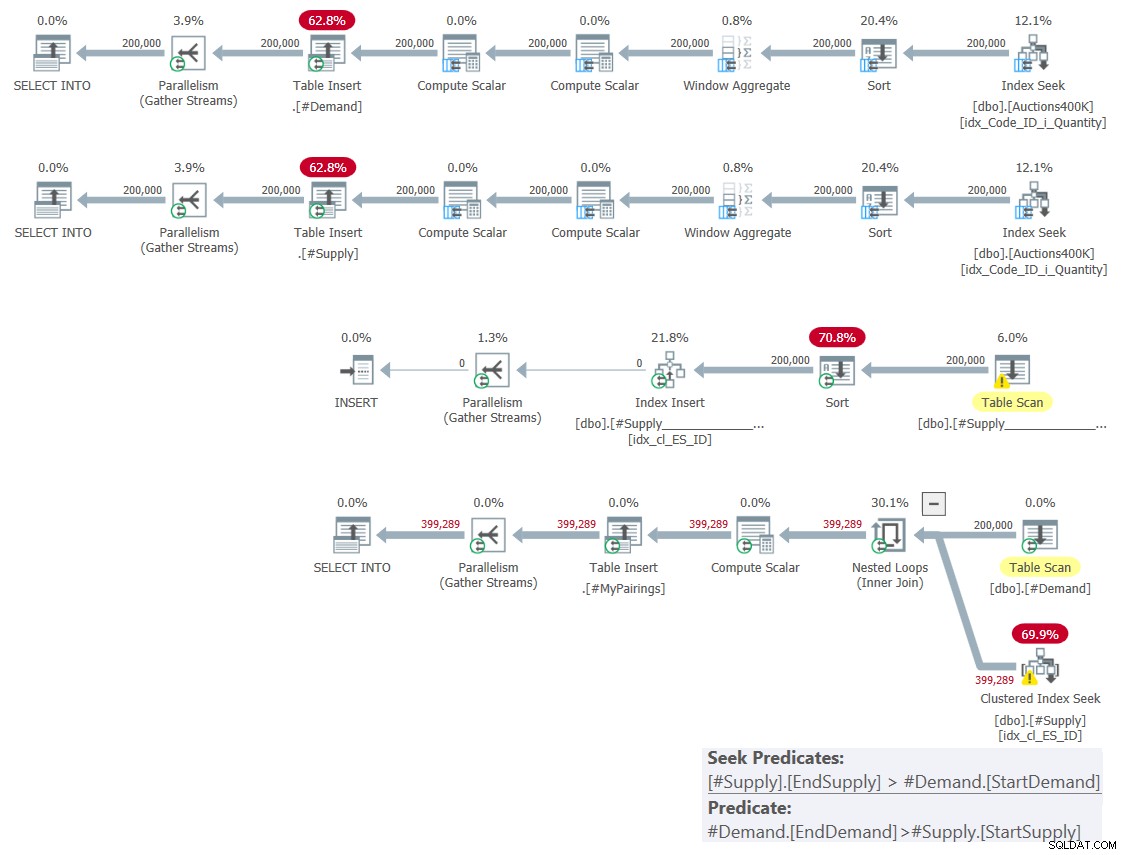 Gambar 1:Rencana kueri untuk solusi berdasarkan persimpangan klasik
Gambar 1:Rencana kueri untuk solusi berdasarkan persimpangan klasik
Seperti yang saya jelaskan bulan lalu, di antara dua predikat rentang yang terlibat, hanya satu yang dapat digunakan sebagai predikat pencarian sebagai bagian dari operasi pencarian indeks, sedangkan yang lain harus diterapkan sebagai predikat residual. Anda dapat dengan jelas melihat ini dalam rencana untuk kueri terakhir pada Gambar 1. Itu sebabnya saya hanya repot-repot membuat satu indeks di salah satu tabel. Saya juga memaksa penggunaan pencarian di indeks yang saya buat menggunakan petunjuk FORCESEEK. Jika tidak, pengoptimal dapat mengabaikan indeks itu dan membuatnya sendiri menggunakan operator Index Spool.
Paket ini memiliki kompleksitas kuadrat karena per baris di satu sisi—#Permintaan dalam kasus kami—pencarian indeks harus mengakses rata-rata setengah baris di sisi lain—#Penawaran dalam kasus kami—berdasarkan predikat pencarian, dan mengidentifikasi pertandingan final dengan menerapkan predikat residual.
Jika masih belum jelas bagi Anda mengapa rencana ini memiliki kompleksitas kuadrat, mungkin penggambaran visual dari pekerjaan tersebut dapat membantu, seperti yang ditunjukkan pada Gambar 2.
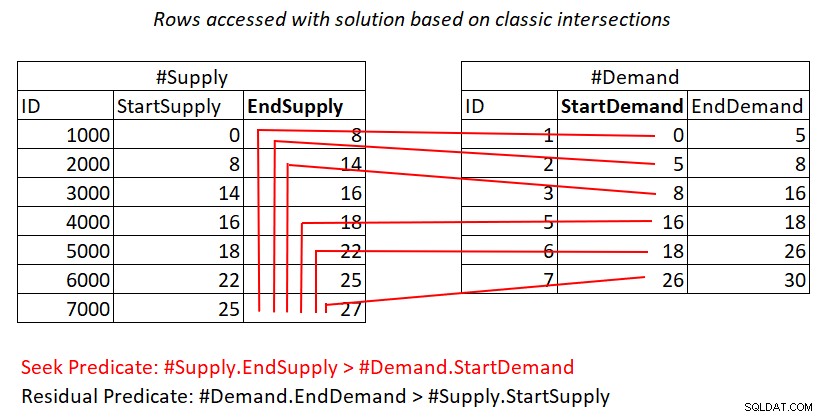 Gambar 2:Ilustrasi pekerjaan dengan solusi berdasarkan persimpangan klasik
Gambar 2:Ilustrasi pekerjaan dengan solusi berdasarkan persimpangan klasik
Ilustrasi ini mewakili pekerjaan yang dilakukan oleh Penggabungan Nested Loops dalam rencana untuk kueri terakhir. Tumpukan #Demand adalah input luar dari gabungan dan indeks berkerumun pada #Supply (dengan EndSupply sebagai kunci utama) adalah input dalam. Garis merah mewakili aktivitas pencarian indeks yang dilakukan per baris di #Permintaan dalam indeks pada #Supply dan baris yang mereka akses sebagai bagian dari pemindaian rentang di daun indeks. Menuju nilai StartDemand yang sangat rendah di #Demand, pemindaian rentang perlu mengakses hampir semua baris di #Supply. Menuju nilai StartDemand yang sangat tinggi di #Demand, pemindaian rentang perlu mengakses hampir nol baris di #Supply. Rata-rata, pemindaian rentang perlu mengakses sekitar setengah baris di #Supply per baris dalam permintaan. Dengan baris permintaan D dan baris penawaran S, jumlah baris yang diakses adalah D + D*S/2. Itu di samping biaya pencarian yang membawa Anda ke baris yang cocok. Misalnya, saat mengisi dbo.Auctions dengan 200.000 baris permintaan dan 200.000 baris pasokan, ini berarti Penggabungan Nested Loops mengakses 200.000 baris permintaan + 200.000*200.000/2 baris pasokan, atau 200.000 + 200.000^2/2 =20.000.200.000 baris yang diakses. Ada banyak pemindaian ulang baris persediaan yang terjadi di sini!
Jika Anda ingin tetap berpegang pada ide persimpangan interval tetapi mendapatkan kinerja yang baik, Anda perlu menemukan cara untuk mengurangi jumlah pekerjaan yang dilakukan.
Dalam solusinya, Joe Obbish mengelompokkan interval berdasarkan panjang interval maksimum. Dengan cara ini dia dapat mengurangi jumlah baris yang diperlukan untuk menangani dan mengandalkan pemrosesan batch. Dia menggunakan tes persimpangan interval klasik sebagai filter terakhir. Solusi Joe bekerja dengan baik selama panjang interval maksimum tidak terlalu tinggi, tetapi runtime solusi meningkat seiring dengan bertambahnya panjang interval maksimum.
Jadi, apa lagi yang bisa kamu lakukan…?
Uji Persimpangan yang Direvisi
Luca, Kamil, dan mungkin Daniel (ada bagian yang tidak jelas tentang solusi yang dipostingnya karena pemformatan situs web, jadi saya harus menebaknya) menggunakan uji perpotongan interval yang direvisi yang memungkinkan pemanfaatan pengindeksan yang jauh lebih baik.
Tes persimpangan mereka adalah disjungsi dua predikat (predikat dipisahkan oleh operator OR):
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
Dalam bahasa Inggris, baik pembatas awal permintaan berpotongan dengan interval suplai secara inklusif dan eksklusif (termasuk awal dan tidak termasuk akhir); atau pembatas awal pasokan bersinggungan dengan interval permintaan, secara inklusif dan eksklusif. Untuk memisahkan kedua predikat (tidak memiliki kasus yang tumpang tindih) namun tetap lengkap dalam mencakup semua kasus, Anda dapat menyimpan operator =hanya di satu atau yang lain, misalnya:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
Tes persimpangan interval yang direvisi ini cukup mendalam. Setiap predikat berpotensi dapat menggunakan indeks secara efisien. Pertimbangkan predikat 1
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Dengan asumsi Anda membuat indeks penutup pada #Demand dengan StartDemand sebagai kunci utama, Anda berpotensi mendapatkan Nested Loops bergabung dengan menerapkan pekerjaan yang diilustrasikan pada Gambar 3.
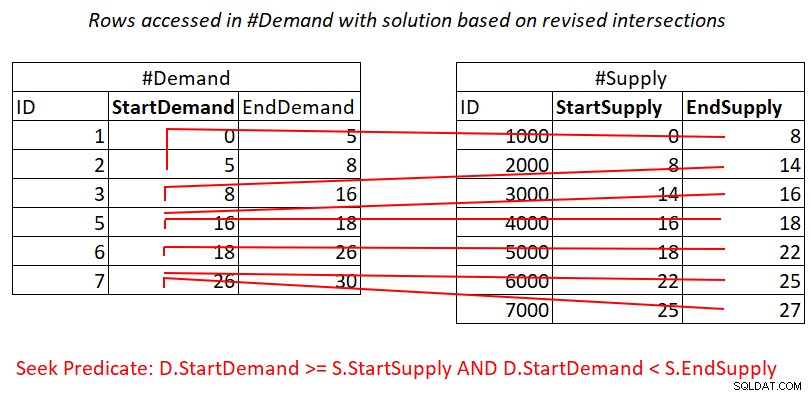
Gambar 3:Ilustrasi kerja teoritis yang diperlukan untuk memproses predikat 1
Ya, Anda masih membayar untuk pencarian di indeks #Demand per baris di #Supply, tetapi rentang pemindaian di akses daun indeks hampir memisahkan subset baris. Tidak ada pemindaian ulang baris!
Situasinya mirip dengan predikat 2:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Dengan asumsi Anda membuat indeks penutup di #Supply dengan StartSupply sebagai kunci utama, Anda berpotensi dapat bergabung dengan Nested Loops menerapkan pekerjaan yang diilustrasikan pada Gambar 4.
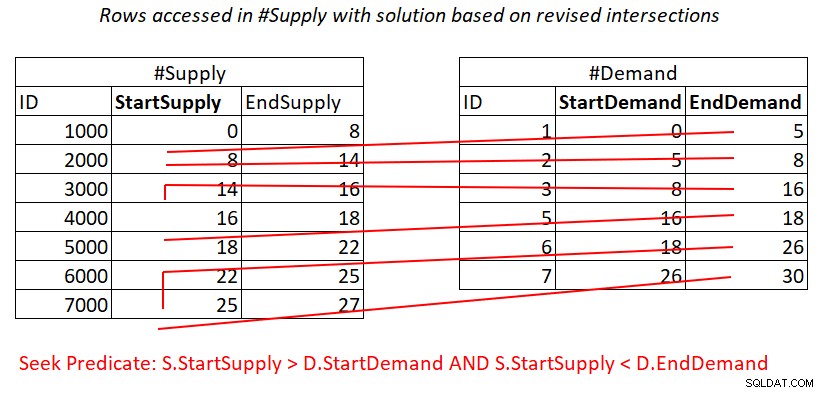
Gambar 4:Ilustrasi kerja teoritis yang diperlukan untuk memproses predikat 2
Juga, di sini Anda membayar untuk pencarian di indeks #Supply per baris di #Demand, dan kemudian rentang memindai di akses daun indeks subset baris yang hampir terputus-putus. Sekali lagi, tidak ada pemindaian ulang baris!
Dengan asumsi baris permintaan D dan baris penawaran S, pekerjaan dapat digambarkan sebagai:
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
Jadi kemungkinan besar, bagian terbesar dari biaya di sini adalah biaya I/O yang terkait dengan pencarian. Tetapi bagian dari pekerjaan ini memiliki penskalaan linier dibandingkan dengan penskalaan kuadrat dari kueri persimpangan interval klasik.
Tentu saja, Anda perlu mempertimbangkan biaya awal pembuatan indeks pada tabel sementara, yang memiliki n log n penskalaan karena penyortiran yang terlibat, tetapi Anda membayar bagian ini sebagai bagian awal dari kedua solusi.
Mari kita coba dan praktikkan teori ini. Mari kita mulai dengan mengisi tabel sementara #Demand dan #supply dengan interval permintaan dan penawaran (sama seperti persimpangan interval klasik) dan membuat indeks pendukung:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); Rencana untuk mengisi tabel sementara dan membuat indeks ditunjukkan pada Gambar 5.
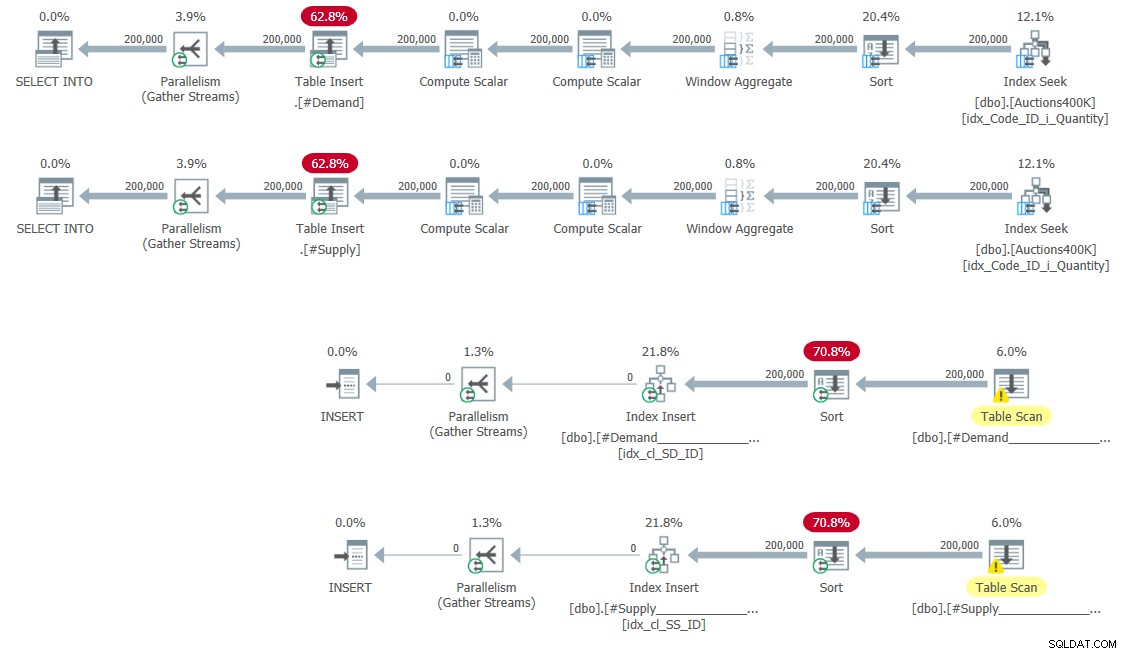
Gambar 5:Rencana kueri untuk mengisi tabel temp dan membuat indeks
Tidak ada kejutan di sini.
Sekarang ke pertanyaan terakhir. Anda mungkin tergoda untuk menggunakan satu kueri dengan disjungsi dua predikat yang disebutkan di atas, seperti:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); Rencana untuk kueri ini ditunjukkan pada Gambar 6.
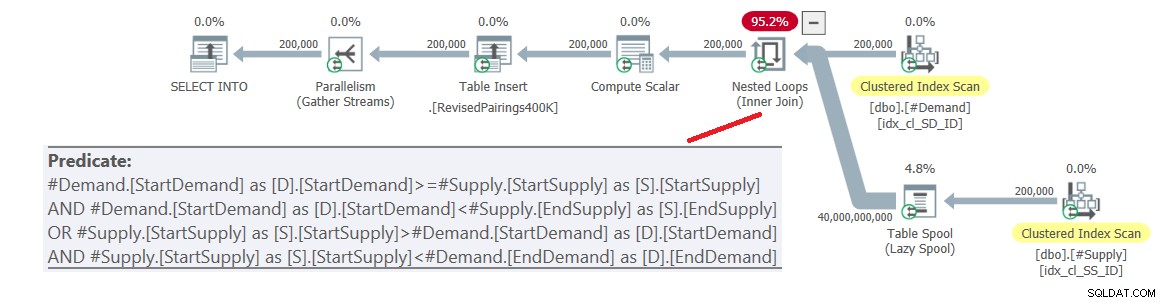
Gambar 6:Rencana kueri untuk kueri akhir menggunakan persimpangan yang direvisi tes, coba 1
Masalahnya adalah pengoptimal tidak tahu cara memecah logika ini menjadi dua aktivitas terpisah, masing-masing menangani predikat berbeda dan memanfaatkan indeks masing-masing secara efisien. Jadi, itu berakhir dengan produk kartesius penuh dari kedua sisi, menerapkan semua predikat sebagai predikat residual. Dengan 200.000 baris permintaan dan 200.000 baris pasokan, gabungan memproses 40.000.000.000 baris.
Trik mendalam yang digunakan oleh Luca, Kamil, dan mungkin Daniel adalah memecah logika menjadi dua pertanyaan, menyatukan hasil mereka. Di situlah penggunaan dua predikat yang terpisah menjadi penting! Anda dapat menggunakan operator UNION ALL alih-alih UNION, menghindari biaya yang tidak perlu untuk mencari duplikat. Inilah kueri yang menerapkan pendekatan ini:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Rencana untuk kueri ini ditunjukkan pada Gambar 7.
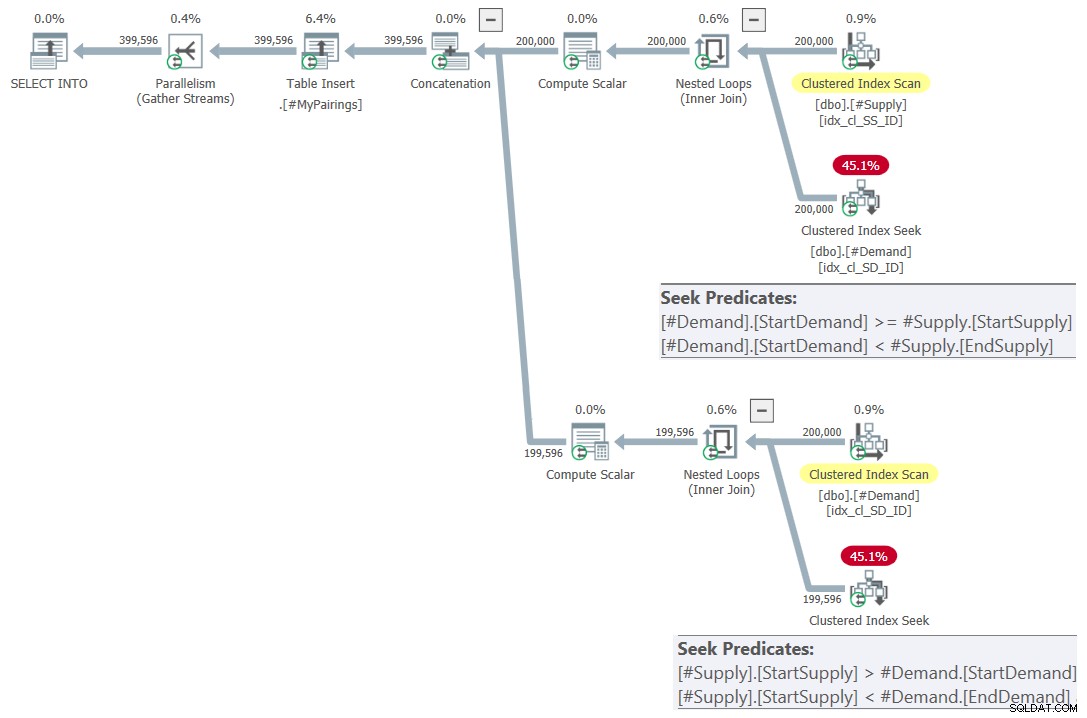
Gambar 7:Rencana kueri untuk kueri akhir menggunakan persimpangan yang direvisi tes, coba 2
Ini hanya indah! bukan? Dan karena sangat indah, inilah seluruh solusi dari awal, termasuk pembuatan tabel sementara, pengindeksan, dan kueri terakhir:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Seperti yang disebutkan sebelumnya, saya akan merujuk ke solusi ini sebagai persimpangan yang direvisi .
Solusi Kamil
Di antara solusi Luca, Kamil, dan Daniel, Kamil adalah yang tercepat. Inilah solusi lengkap Kamil:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); Seperti yang Anda lihat, ini sangat dekat dengan solusi persimpangan yang direvisi yang saya bahas.
Rencana query terakhir dalam solusi Kamil ditunjukkan pada Gambar 8.
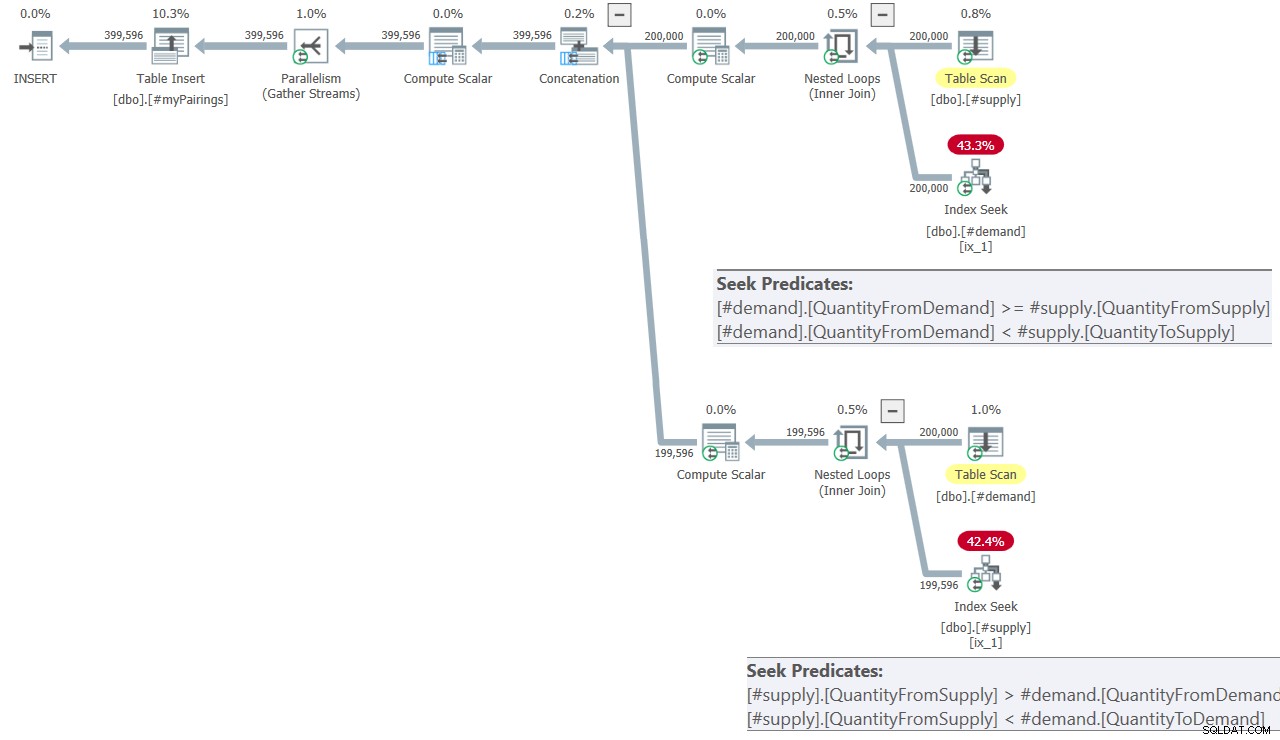
Gambar 8:Rencana kueri untuk kueri akhir dalam solusi Kamil
Rencananya terlihat sangat mirip dengan yang ditunjukkan sebelumnya pada Gambar 7.
Uji Kinerja
Ingatlah bahwa solusi persimpangan klasik membutuhkan waktu 931 detik untuk diselesaikan terhadap input dengan 400 ribu baris. Itu 15 menit! Ini jauh, jauh lebih buruk daripada solusi kursor, yang membutuhkan waktu sekitar 12 detik untuk menyelesaikan input yang sama. Gambar 9 memiliki angka kinerja termasuk solusi baru yang dibahas dalam artikel ini.
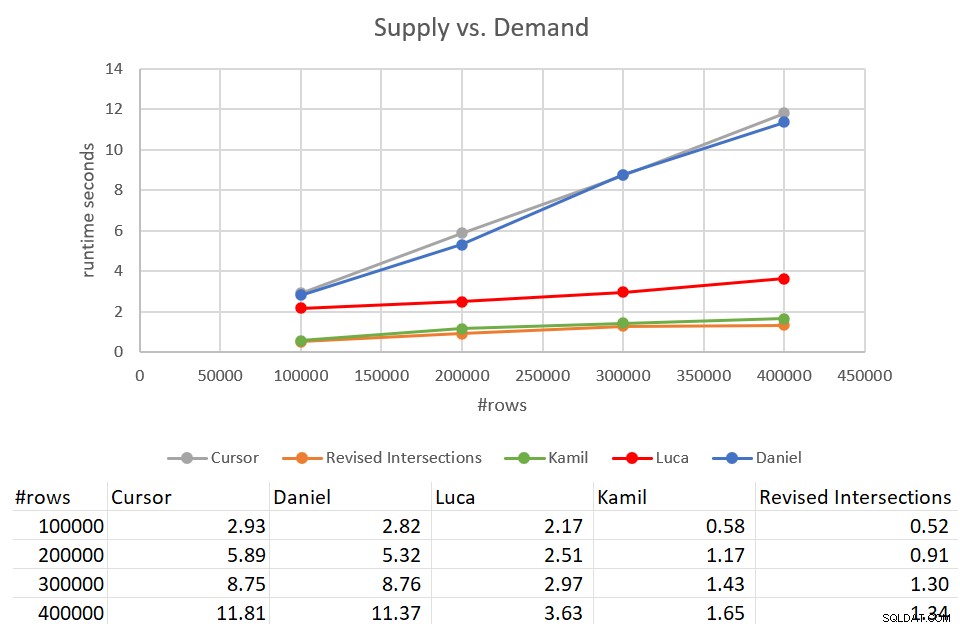
Gambar 9:Uji kinerja
Seperti yang Anda lihat, solusi Kamil dan solusi persimpangan yang direvisi serupa membutuhkan waktu sekitar 1,5 detik untuk menyelesaikan input 400K-baris. Itu peningkatan yang cukup baik dibandingkan dengan solusi berbasis kursor asli. Kelemahan utama dari solusi ini adalah biaya I/O. Dengan pencarian per baris, untuk input 400K-baris, solusi ini melakukan lebih dari 1,35 juta pembacaan. Namun, ini juga dapat dianggap sebagai biaya yang dapat diterima dengan baik mengingat waktu pengoperasian dan penskalaan yang Anda dapatkan.
Apa Selanjutnya?
Upaya pertama kami untuk memecahkan tantangan penawaran versus permintaan yang cocok mengandalkan uji persimpangan interval klasik dan mendapatkan rencana berkinerja buruk dengan penskalaan kuadrat. Jauh lebih buruk daripada solusi berbasis kursor. Berdasarkan wawasan dari Luca, Kamil, dan Daniel, menggunakan uji persimpangan interval yang direvisi, upaya kedua kami adalah peningkatan signifikan yang memanfaatkan pengindeksan secara efisien dan berkinerja lebih baik daripada solusi berbasis kursor. Namun, solusi ini melibatkan biaya I/O yang signifikan. Bulan depan saya akan terus mencari solusi tambahan.
[ Langsung ke:Tantangan asli | Solusi:Bagian 1 | Bagian 2 | Bagian 3]