Penghapusan dan pencegahan fragmentasi indeks telah lama menjadi bagian dari operasi pemeliharaan database normal, tidak hanya di SQL Server, tetapi di banyak platform. Fragmentasi indeks memengaruhi kinerja karena banyak alasan, dan kebanyakan orang berbicara tentang efek blok kecil acak I/O yang dapat terjadi secara fisik pada penyimpanan berbasis disk sebagai sesuatu yang harus dihindari. Kekhawatiran umum seputar fragmentasi indeks adalah bahwa hal itu memengaruhi kinerja pemindaian melalui pembatasan ukuran I/O baca-depan. Ini didasarkan pada pemahaman yang terbatas tentang masalah yang disebabkan oleh fragmentasi indeks sehingga beberapa orang mulai mengedarkan gagasan bahwa fragmentasi indeks tidak masalah dengan perangkat Solid State Storage (SSD) dan bahwa Anda dapat mengabaikan fragmentasi indeks ke depan.
Namun, tidak demikian karena beberapa alasan. Artikel ini akan menjelaskan dan menunjukkan salah satu alasan tersebut:bahwa fragmentasi indeks dapat berdampak buruk pada pilihan rencana eksekusi untuk kueri. Hal ini terjadi karena fragmentasi indeks umumnya menyebabkan indeks memiliki lebih banyak halaman (halaman tambahan ini berasal dari pembagian halaman operasi, seperti yang dijelaskan dalam posting ini di situs ini), dan penggunaan indeks itu dianggap memiliki biaya lebih tinggi oleh pengoptimal kueri SQL Server.
Mari kita lihat contohnya.
Hal pertama yang perlu kita lakukan adalah membangun database pengujian dan kumpulan data yang sesuai untuk digunakan untuk memeriksa bagaimana fragmentasi indeks dapat memengaruhi pilihan rencana kueri di SQL Server. Skrip berikut akan membuat database dengan dua tabel dengan data yang identik, satu sangat terfragmentasi dan satu terfragmentasi minimal.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Setelah membangun kembali indeks, kita dapat melihat tingkat fragmentasi dengan kueri berikut:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Hasil:

Di sini kita dapat melihat bahwa GuidHighFragmentation tabel 99% terfragmentasi dan menggunakan ruang halaman 31% lebih banyak daripada GuidLowFragmentation tabel dalam database, meskipun mereka memiliki 7.000.000 baris data yang sama. Jika kami melakukan kueri agregasi dasar terhadap setiap tabel dan membandingkan rencana eksekusi pada instalasi default (dengan opsi dan nilai konfigurasi default) SQL Server menggunakan SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


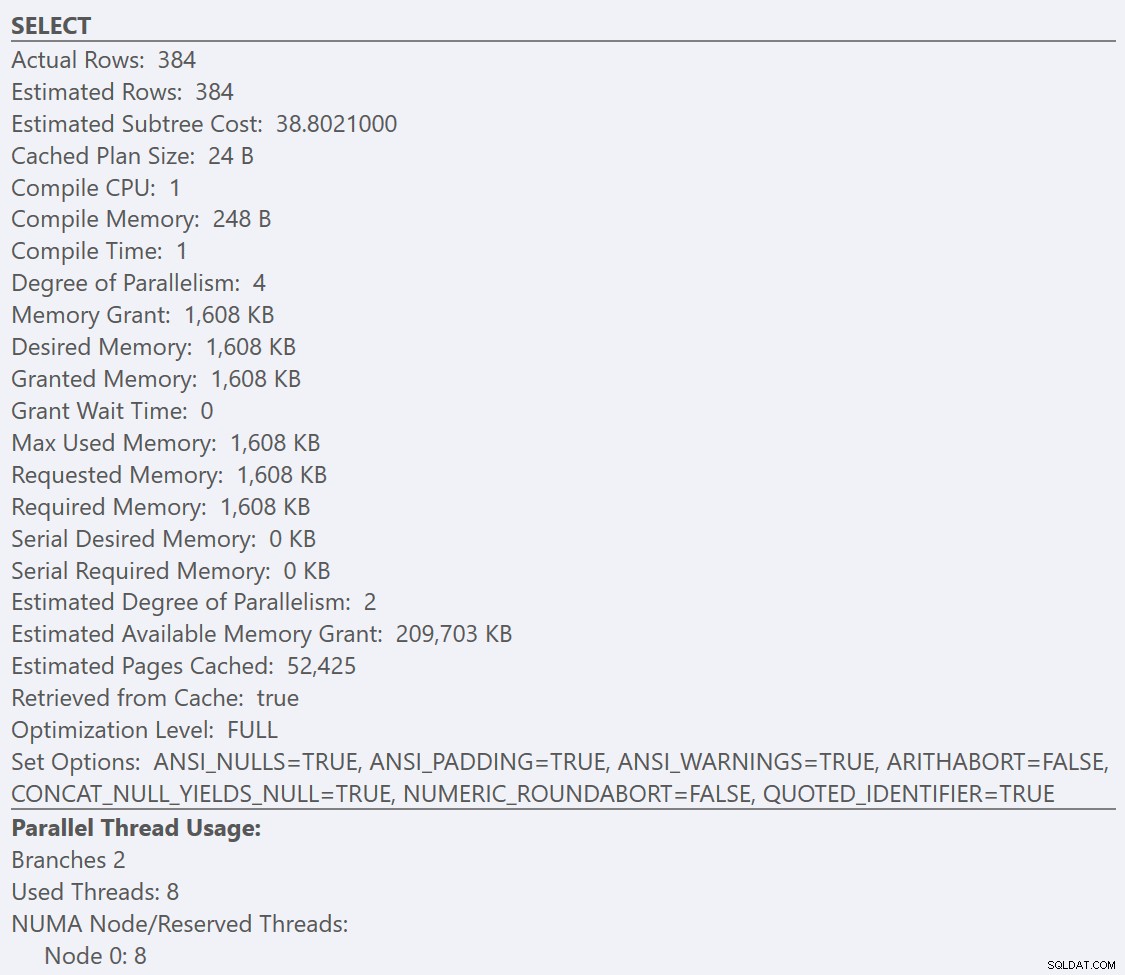

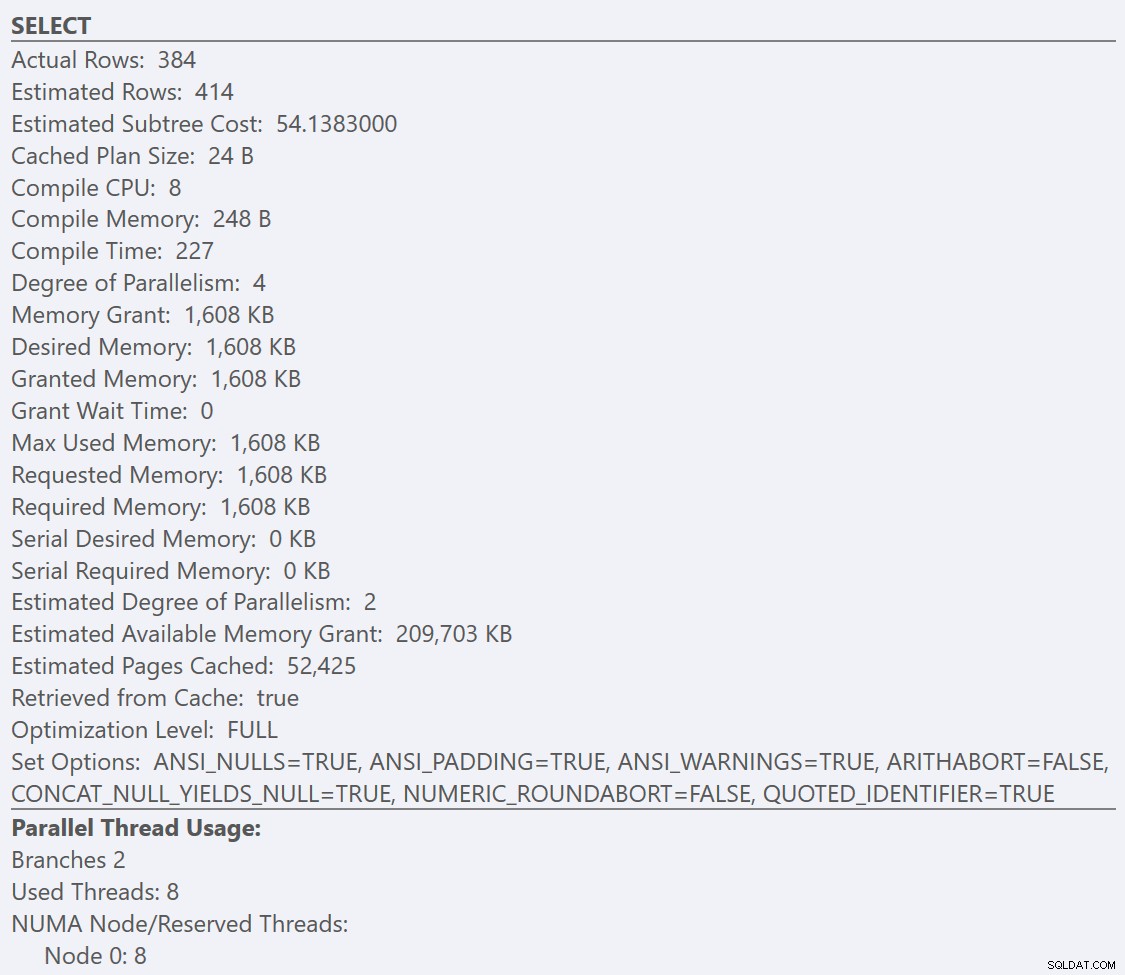
Jika kita melihat tooltips dari SELECT operator untuk setiap paket, paket untuk GuidLowFragmentation tabel memiliki biaya kueri 38,80 (baris ketiga turun dari atas tooltip) versus biaya kueri 54,14 untuk paket paket GuidHighFragmentation.
Di bawah konfigurasi default untuk SQL Server, kedua kueri ini akhirnya menghasilkan rencana eksekusi paralel karena perkiraan biaya kueri lebih tinggi dari 'ambang biaya untuk paralelisme' opsi sp_configure default 5. Ini karena pengoptimal kueri pertama-tama menghasilkan serial plan (yang hanya dapat dieksekusi oleh satu utas) saat menyusun rencana untuk kueri. Jika perkiraan biaya paket serial tersebut melebihi nilai 'ambang biaya untuk paralelisme' yang dikonfigurasi, maka paket paralel akan dibuat dan di-cache sebagai gantinya.
Namun, bagaimana jika opsi sp_configure 'ambang biaya untuk paralelisme' tidak disetel ke default 5 dan disetel lebih tinggi? Ini adalah praktik terbaik (dan yang benar) untuk meningkatkan opsi ini dari default rendah 5 ke mana saja dari 25 menjadi 50 (atau bahkan jauh lebih tinggi) untuk mencegah kueri kecil menimbulkan overhead tambahan untuk menjadi paralel.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Setelah mengikuti panduan praktik terbaik dan meningkatkan 'ambang biaya untuk paralelisme' menjadi 50, menjalankan kembali kueri menghasilkan rencana eksekusi yang sama untuk GuidHighFragmentation tabel, tetapi GuidLowFragmentation biaya serial kueri, 44,68, sekarang di bawah nilai 'ambang biaya untuk paralelisme' (ingat perkiraan biaya paralelnya adalah 38,80), jadi kami mendapatkan rencana eksekusi serial:
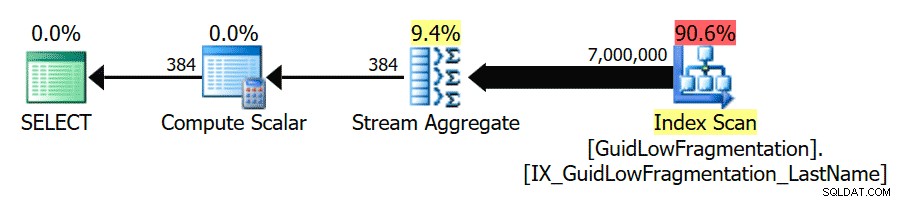
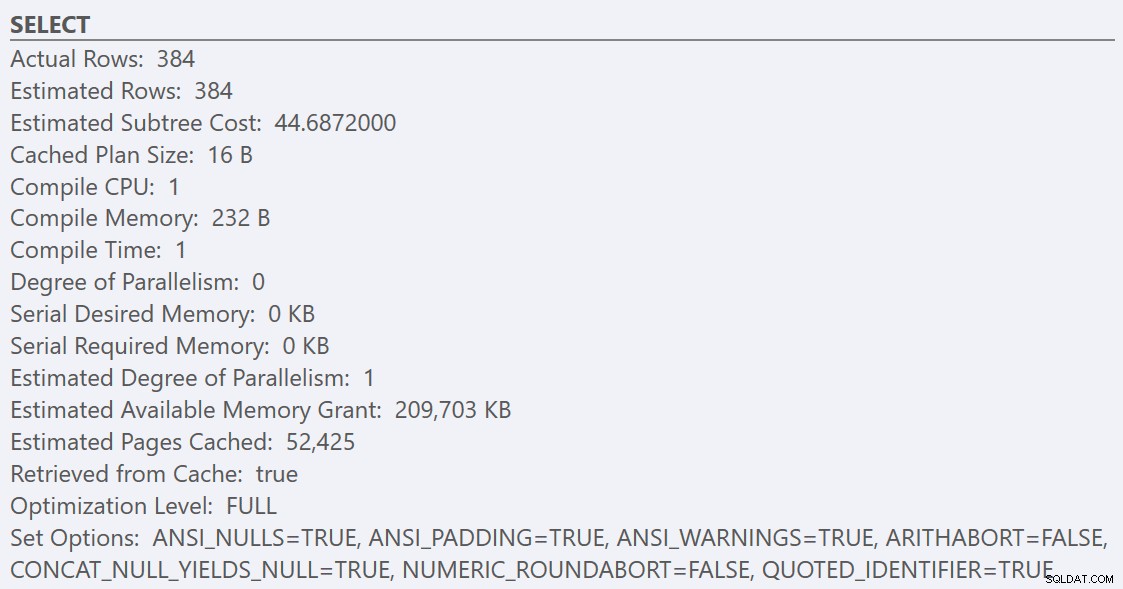
Ruang halaman tambahan di GuidHighFragmentation indeks berkerumun menjaga biaya di atas pengaturan praktik terbaik untuk 'ambang biaya untuk paralelisme' dan menghasilkan rencana paralel.
Sekarang bayangkan bahwa ini adalah sistem di mana Anda mengikuti panduan praktik terbaik dan awalnya mengonfigurasi 'ambang biaya untuk paralelisme' dengan nilai 50. Kemudian Anda mengikuti saran yang salah untuk mengabaikan fragmentasi indeks sama sekali.
Alih-alih ini menjadi kueri dasar, ini lebih kompleks, tetapi jika itu juga dieksekusi sangat sering di sistem Anda, dan sebagai akibat dari fragmentasi indeks, jumlah halaman memberi tip biaya ke paket paralel, itu akan menggunakan lebih banyak CPU dan berdampak pada kinerja beban kerja secara keseluruhan sebagai hasilnya.
Apa pekerjaanmu? Apakah Anda meningkatkan 'ambang biaya untuk paralelisme' sehingga kueri mempertahankan rencana eksekusi serial? Apakah Anda mengisyaratkan kueri dengan OPTION(MAXDOP 1) dan hanya memaksanya ke rencana eksekusi serial?
Ingatlah bahwa fragmentasi indeks kemungkinan tidak hanya memengaruhi satu tabel di database Anda, sekarang Anda mengabaikannya sepenuhnya; kemungkinan banyak indeks berkerumun dan tidak berkerumun terfragmentasi dan memiliki jumlah halaman yang lebih tinggi dari yang diperlukan, sehingga biaya banyak operasi I/O meningkat sebagai akibat dari fragmentasi indeks yang meluas, yang berpotensi menyebabkan banyak kueri yang tidak efisien rencana.
Ringkasan
Anda tidak bisa mengabaikan fragmentasi indeks sepenuhnya karena beberapa orang mungkin ingin Anda percaya. Di antara kerugian lain dari melakukan ini, akumulasi biaya eksekusi kueri akan menyusul Anda, dengan pergeseran rencana kueri karena pengoptimal kueri adalah pengoptimal berbasis biaya dan dengan demikian menganggap indeks yang terfragmentasi tersebut lebih mahal untuk digunakan.
Kueri dan skenario di sini jelas dibuat-buat, tetapi kami telah melihat perubahan rencana eksekusi yang disebabkan oleh fragmentasi dalam kehidupan nyata pada sistem klien.
Anda perlu memastikan bahwa Anda menangani fragmentasi indeks untuk indeks tersebut di mana fragmentasi menyebabkan masalah kinerja beban kerja, apa pun perangkat keras yang Anda gunakan.