Tidak peduli di sisi mana Anda berada, terkadang sulit untuk menemukan orang yang memenuhi syarat untuk pekerjaan tertentu. Dalam postingan ini, kita melihat model data untuk membantu perekrut dan departemen SDM tetap teratur selama proses perekrutan.
Sebagian besar dari kita telah terlibat dalam proses perekrutan - paling sering sebagai pelamar pekerjaan. Namun, kami juga dapat menemukan diri kami terlibat di sisi perekrutan, mungkin dengan menguji pengetahuan teknis pelamar. Proses perekrutan membutuhkan waktu tertentu, dan kelompok pelamar terus bertambah kecil saat kita semakin dekat dengan keputusan akhir. Hasilnya harus berupa pemilihan orang terbaik untuk pekerjaan itu.
Perekrutan itu sendiri cukup rumit, jadi kami akan membahas model data yang cukup komprehensif untuk mencakup semua aspek proses. Duduklah di kursi Anda dan nikmati artikel hari ini!
Cara Kerja Proses Rekrutmen
Sebagian besar proses rekrutmen adalah pengetahuan umum, tetapi kami akan membahas cara kerjanya sebelum beralih ke model data.
-
Mendeteksi kebutuhan
Hal ini mutlak harus dilakukan dalam proses rekrutmen; tidak akan ada proses jika manajemen tidak menyadari kebutuhan untuk merekrut karyawan baru. Kebutuhan itu dapat berupa hasil dari memulai perusahaan baru, pertumbuhan dalam perusahaan yang sudah ada, atau kepergian karyawan saat ini.
Kecuali jika perusahaan memiliki posisi yang ditentukan secara ketat (misalnya bank), tidak selalu mudah untuk menentukan kapan harus mempekerjakan karyawan baru. Berbicara dengan karyawan dan melihat banyak waktu lembur dapat memacu karyawan baru. Peraturan internal atau eksternal juga dapat mensyaratkan bahwa posisi tertentu hanya diberikan kepada orang-orang dengan keahlian khusus dan pengalaman kerja yang relevan (misalnya, reviser internal).
-
Menguraikan posisi dan keterampilan yang dibutuhkan
Untuk mendapatkan gambaran tentang langkah ini, pikirkan deskripsi pekerjaan yang ditulis dengan sangat baik. Ini berisi:
- Daftar semua tugas yang terkait dengan pekerjaan
- Kualifikasi pendidikan dan pengalaman kerja minimum
- Keterampilan khusus yang penting untuk fungsi pekerjaan
- Keterampilan tambahan atau pilihan
- Ringkasan tentang apa yang diharapkan pemberi kerja dari pelamar dan apa yang dapat diharapkan pelamar dari pekerjaan ini
- Kisaran gaji dan mungkin paket tunjangan
Informasi ini penting bagi perekrut dan pelamar. Tidak ada gunanya mengundang sepuluh pelamar ke proses seleksi jika tidak satupun dari mereka akan puas dengan tawaran keuangan. Dan semakin detail deskripsi pekerjaan, semakin mudah untuk menarik pelamar yang memenuhi syarat.
-
Menentukan siapa yang akan mengelola proses dan kapan setiap tugas harus dilakukan
Langkah selanjutnya adalah menentukan tanggal tertentu kapan setiap bagian dari proses akan terjadi. Juga, perusahaan dapat menugaskan karyawan untuk setiap langkah. Jika perusahaan memiliki departemen Sumber Daya Manusia, itu mungkin akan mengelola setiap bagian dari proses perekrutan, meskipun karyawan lain dapat menyumbangkan pengetahuan khusus mereka bila diperlukan (misalnya jika kita mempekerjakan seorang spesialis TI, manajer departemen TI harus menilai kandidat ' keterampilan teknis).
Jika tidak ada departemen SDM, kita dapat berharap bahwa personel manajemen akan bertanggung jawab atas proses tersebut. Di perusahaan kecil dan menengah, ini tidak hanya dibutuhkan, tetapi juga diinginkan.
-
Mengeposkan pekerjaan
Sekarang kami siap untuk memposting deskripsi pekerjaan di situs kami, di papan pekerjaan atau agregator, atau di surat kabar. Postingan pekerjaan harus berisi poin-poin yang tercantum di Langkah 2. Ini akan membantu calon potensial memutuskan apakah mereka ingin melamar posisi tersebut. Sangat penting untuk membuat deskripsi pekerjaan akurat; kita semua telah membuang waktu untuk mewawancarai pekerjaan yang tidak sesuai dengan deskripsi atau harapan kita.
-
Memilih, menguji, dan mewawancarai kandidat
Setelah periode aplikasi berakhir, pelamar dengan keahlian dan pengalaman yang paling relevan akan diundang ke tahap evaluasi awal (biasanya wawancara atau tes). Pelamar lain akan diberitahu bahwa mereka belum dipilih untuk pekerjaan itu. Perusahaan besar harus mengundang kandidat dalam jumlah minimum yang telah ditentukan sebelumnya untuk evaluasi awal. Ini menghemat waktu bagi pelamar dan perusahaan.
Perusahaan kecil dan menengah dapat memutuskan untuk melanjutkan proses sampai mereka menemukan yang paling cocok. Dalam kasus seperti itu, periode aplikasi akan tetap terbuka sampai kandidat yang tepat ditemukan dan semua tanggal lainnya akan ditentukan selama proses tersebut.
Proses wawancara dan pengujian akan bervariasi menurut ukuran dan organisasi perusahaan. Di perusahaan besar dengan departemen SDM, kemungkinan akan ada serangkaian tes untuk memeriksa keterampilan kerja pelamar. Tes lain dapat mengukur sifat psikologis dan kepribadian untuk menentukan kecocokan pelamar-pekerjaan, kecocokan pelamar-perusahaan, atau bahkan kewarasan pelamar.
Tes ini biasanya akan dibagi menjadi beberapa langkah, dan setiap langkah akan mengurangi jumlah pelamar.
-
Wawancara terakhir
Langkah ini mungkin akan menjadi wawancara dari beberapa pelamar teratas. Ini adalah langkah paling penting dalam proses karena pelamar dapat berbicara sendiri, menunjukkan kompetensi dan kepribadian mereka, dan menentukan apakah perusahaan dan posisi akan cocok untuk mereka. Setelah langkah ini, pelamar terbaik akan menerima penawaran. Jika mereka menerima, proses rekrutmen untuk posisi itu selesai. Jika pelamar menolak tawaran pekerjaan, perusahaan akan membuat tawaran untuk pilihan mereka berikutnya.
-
Apakah ada perbedaan dalam proses rekrutmen untuk usaha kecil, menengah, dan besar? Bagaimana kita akan menyelesaikannya dalam model kita?
Akan ada perbedaan tertentu dalam proses rekrutmen perusahaan kecil, menengah, dan besar. Plus, prosesnya akan bervariasi menurut posisi yang direkrut. Pikirkan betapa berbedanya keterampilan dan pengalaman yang dibutuhkan untuk manajer konten, ahli burung, dan kapten kapal pesiar. Beberapa pekerjaan akan memiliki lebih banyak tes dan wawancara, yang lain mungkin hanya memiliki sedikit. Tetapi pada akhirnya, semuanya bermuara pada jawaban yang benar dan peringkat pelamar.
Dalam model ini, saya akan memperlakukan semua tes dan wawancara dengan cara yang sama. Kami akan menyimpan jawaban setiap pelamar, menghubungkannya dengan pertanyaan yang relevan, dan menyimpan skor pelamar untuk setiap langkah proses.
-
Siapa yang dapat menggunakan model data ini?
Model ini sangat spesifik dan hanya boleh digunakan untuk proses rekrutmen. Tapi itu tidak terbatas pada departemen SDM; Anda juga dapat menggunakan model ini untuk menjalankan layanan rekrutmen profesional.
-
Model Data
Model data terdiri dari lima bidang subjek utama:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Saya akan menjelaskan setiap bidang subjek secara terpisah, dengan urutan yang sama.
Bagian 1:Pekerjaan
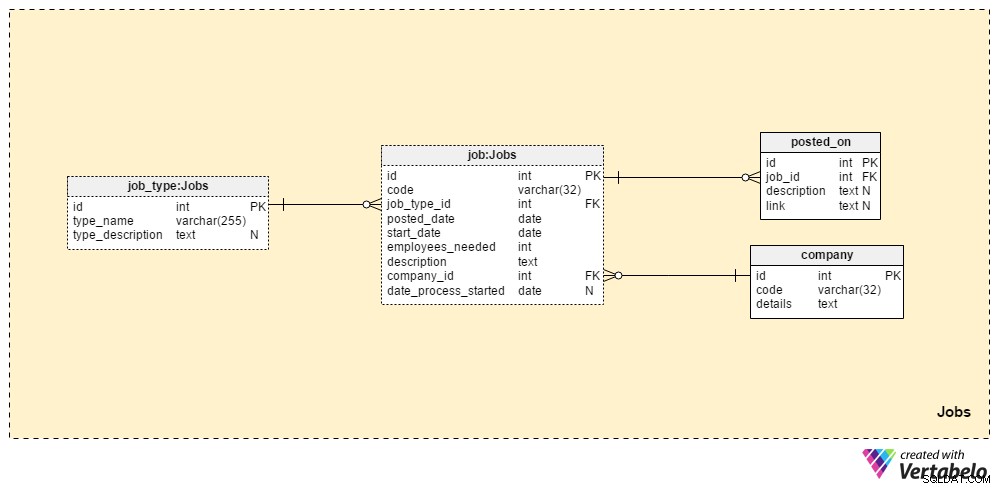
Jobs bagian akan menyimpan semua detail untuk semua posisi yang pernah kami posting. Dua tabel kamus, company tabel dan job_type tabel, adalah bagian dari pengaturan awal. Dua tabel yang tersisa, job dan posted_on , berisi data "nyata" yang terkait dengan lowongan pekerjaan.
job_type kamus berisi daftar jenis pekerjaan yang berbeda dan UNIK. Kita dapat mengharapkan nilai seperti “administrator database senior” atau “jurnalis IT” untuk disimpan di type_name atribut. type_description atribut dapat menyimpan deskripsi pekerjaan yang lebih rinci.
company kamus berisi daftar semua perusahaan tempat kami bekerja. Jika kami mempekerjakan karyawan hanya untuk perusahaan kami, kamus ini hanya akan memuat nama perusahaan kami. Jika kami adalah agen perekrutan, itu akan menyimpan nama setiap perusahaan yang mempekerjakan kami.
Daftar setiap posisi pekerjaan yang pernah kami posting disimpan di tabel "pekerjaan". Atribut dalam tabel ini adalah:
code– ID UNIK internal kami digunakan untuk menunjukkan pekerjaan.job_type_id– Merujuk pada jenis pekerjaan terkait.posted_date– Tanggal saat posisi pekerjaan ini diposting.start_date– Tanggal mulai yang diharapkan (hari kerja pertama) untuk pekerjaan itu.employees_needed– Jumlah karyawan yang ingin kami rekrut selama proses rekrutmen ini. Sebagian besar ini akan memiliki nilai "1", tetapi dalam beberapa kasus - mis. saat memulai perusahaan baru atau mendirikan departemen baru – kami dapat mengharapkan nilai yang lebih besar.description– Penjelasan rinci tentang posisi itu. Ini adalah tempat di mana kami akan mencantumkan semua keterampilan kerja yang dibutuhkan, disukai, dan diinginkan.company_id– Referensi ID perusahaan yang mempekerjakan kami. Jika kami adalah agen perekrutan, ini akan merujuk pada nama bisnis yang disimpan dicompanymeja. Jika tidak, itu akan menjadi ID perusahaan kami sendiri.date_process_started– Tanggal dimulainya proses rekrutmen. Ini bisa menjadi NULL jika kita perlu menentukan langkah dan tindakan di masa mendatang terkait pekerjaan ini.
Tabel terakhir di area subjek ini adalah posted_on meja. Untuk setiap job_id , kami akan menyimpan link ke pos pekerjaan dan description terkait . Kami dapat menggunakan data ini untuk mempelajari di mana pelamar menemukan lowongan pekerjaan kami.
Bagian 2:Pelamar, Perekrut, dan Dokumen
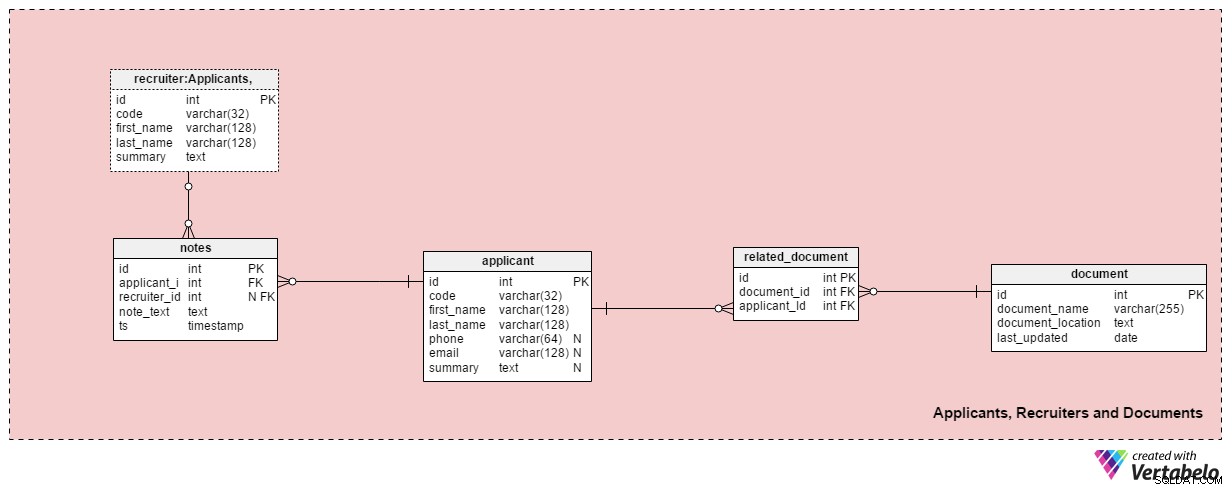
Area subjek ini berisi semua tabel yang diperlukan untuk menyimpan informasi tentang perekrut, pelamar, dan dokumen terkait mereka.
applicant tabel mencantumkan semua pelamar yang pernah kami hubungi. Setiap pelamar secara UNIK didefinisikan dalam sistem kami dengan "kode". Selain itu, kami akan menyimpan nama depan dan belakang setiap pelamar, phone nomor, email alamat, dan summary . Tabel ini dapat disesuaikan untuk kebutuhan tertentu, mis. menambahkan nomor telepon, email, atau alamat fisik tambahan.
Kami akan menghubungkan pelamar dengan dokumen yang tersedia. Daftar semua dokumen yang tersedia (CV atau resume, gelar atau diploma, transkrip, sertifikasi, dll.) disimpan di document meja. Untuk setiap dokumen, kami akan menyimpan namanya di sistem, lokasinya, dan waktu pembaruan terbaru.
Kami akan menghubungkan pelamar dengan dokumen menggunakan related_document meja. Ini hanya menampung dua kunci asing, yang membentuk document_id – applicant_id Pasangan UNIK.
recruiter tabel mencantumkan karyawan yang dapat ditugaskan ke lamaran pekerjaan atau yang memasukkan catatan terkait pelamar. Setiap perekrut secara UNIK ditentukan oleh code-nya . Kami hanya akan menyimpan detail dasar seperti first_name , last_name dan summary perekrut .
Tabel terakhir di bidang subjek ini adalah notes meja. Di sinilah kami akan menyimpan semua catatan yang terkait dengan pemohon. Kami dapat menyimpan catatan seperti “Pemohon melewatkan rapat” atau “Pelamar berhasil pada wawancara pertama” . Untuk setiap catatan, kami akan menyimpan ID perekrut yang membuat catatan itu, ID pelamar terkait, note_text , dan stempel waktu saat catatan dibuat.
Bagian 3:Detail Pengujian
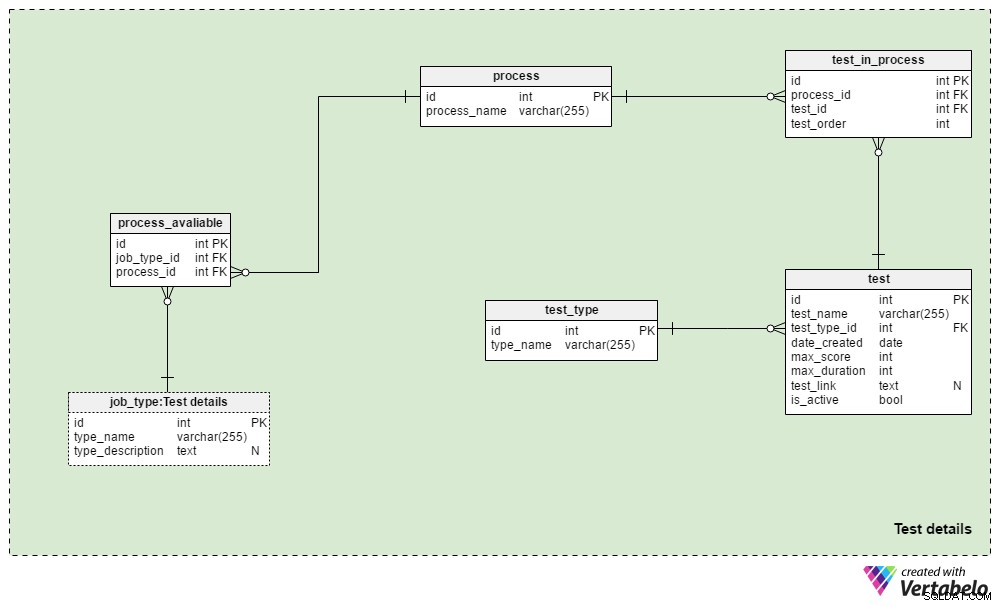
Test details area subjek berisi tabel yang digunakan untuk menentukan proses rekrutmen dan tes yang digunakan selama proses ini. Kami biasanya akan selalu menggunakan proses seleksi yang sama untuk jenis pekerjaan yang sama:perubahan hanya dilakukan jika diperlukan oleh keadaan bisnis. Kami dapat menggunakan beberapa proses berbeda untuk setiap jenis pekerjaan, dan kami hampir pasti akan menggunakan proses yang sama untuk jenis pekerjaan yang berbeda.
process table adalah kamus sederhana yang hanya berisi process_name UNIK atribut. Ini mencantumkan semua proses perekrutan yang pernah kami gunakan dan sedang kami gunakan.
Kami akan menghubungkan proses dengan jenis pekerjaan yang berbeda. Kami akan menyimpan hubungan ini di process_available meja. Satu-satunya atributnya adalah pasangan UNIK job_type_id – process_id . Ketika ada beberapa proses yang tersedia untuk suatu jenis pekerjaan, ini memungkinkan perekrut untuk memilih satu.
test_in_process tabel digunakan untuk menentukan urutan tes selama proses itu. Atribut dalam tabel ini adalah:
process_iddantest_id– Merujuk pada proses dan pengujian terkait.test_order– Nomor urut tes atau langkah dalam proses tersebut. Bersama denganprocess_id, ini membentuk kunci UNIK tabel. Kami hanya dapat memiliki satu langkah pada satu waktu selama proses.
test tabel mencantumkan semua tes yang saat ini dan sebelumnya digunakan dalam proses rekrutmen. Kami juga akan memperlakukan ulasan CV dan wawancara sebagai ujian. Meskipun mereka tidak membutuhkan pertanyaan dan jawaban yang ditentukan, mereka adalah bagian dari evaluasi. Untuk setiap pengujian, kami akan menyimpan:
test_name– Penunjukan UNIK untuk setiap tes.test_type_id– Merujuk padatest_typekamus.date_created– Tanggal saat kami membuat pengujian ini di sistem kami.max_score– Skor maksimal yang dapat dicapai untuk tes ini. Nilai ini adalah jumlah dari semua jawaban yang benar pada tes ini atau nilai tertinggi yang dapat diberikan perekrut untuk CV atau wawancara.max_duration– Berapa lama (dalam menit) pelamar harus menyelesaikan tes.test_link– Berisi tautan ke lokasi pengujian. Nilai ini bisa menjadi NULL jika kita tidak menggunakan tes dalam prosesnya.is_active– Menunjukkan jika saat ini kita menggunakan tes ini.
Kami telah menyebutkan test_type kamus. Ini berisi semua nama tes UNIK berdasarkan format, mis. “Ulasan CV” , “tes keterampilan online” , "tes keterampilan kertas" dan “wawancara” .
Model ini tidak menyertakan struktur yang diperlukan untuk menyimpan pertanyaan dan jawaban tes. Sebaliknya, itu menyimpan tautan ke lokasi yang berisi informasi ini. Desain yang sama akan digunakan di Applications bidang studi.
Bagian 4:Aplikasi
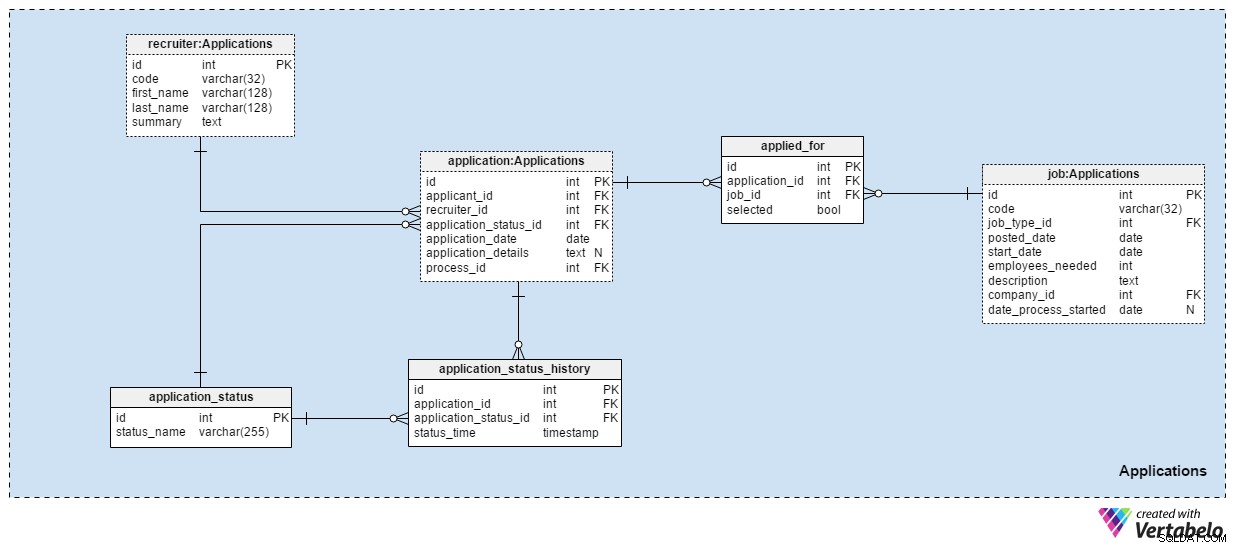
Applications area subjek mungkin yang paling penting dalam model data ini. Semua bidang studi lain yang disebutkan sejauh ini menjelaskan aplikasi. Yang ini menyimpan yang asli.
Setiap aplikasi yang pernah kami terima dicatat dalam application meja. Untuk setiap aplikasi, kami akan menyimpan ID pelamar terkait, ID perekrut, dan referensi ke status aplikasi tersebut saat ini. Kami akan memperbarui status ini sekaligus membuat entri baru di application_status_history meja. application_date atribut digunakan untuk menyimpan tanggal yang relevan, sementara semua detail tambahan disimpan dalam format teks. process_id atribut menyimpan referensi ke proses yang dipilih untuk aplikasi itu.
Aplikasi akan berubah status seiring waktu. Daftar semua status aplikasi disimpan di application_status kamus. Satu-satunya atribut adalah status_name dan itu hanya dapat menyimpan nilai UNIK. Nilai yang diharapkan meliputi:"diterapkan" , "CV ditinjau" , "dipilih untuk ujian" , "ditolak setelah CV ditinjau" , "lulus ujian" , "diundang ke wawancara" dan "dihentikan oleh pemohon" .
Kami akan menyimpan semua status aplikasi di application_status_history meja. Tabel ini berisi referensi ke application tabel dan application_status kamus. Kami juga akan menyimpan status_time yang tepat ketika status ini ditetapkan ke aplikasi. application_id – status_time pair membentuk kunci UNIK tabel ini.
Dalam kebanyakan kasus, pelamar hanya akan melamar satu posisi dengan satu aplikasi. Ada kemungkinan pelamar akan melamar lebih dari satu posisi dan kami akan memilih peran yang paling cocok untuk mereka selama proses seleksi. Dalam applied_for tabel, kami akan menyimpan pasangan UNIK application_id – job_id . Kami juga akan mencatat apakah pemohon yang terkait dengan aplikasi tersebut selected untuk posisi itu. Kita dapat mengharapkan bahwa semua selected nilai akan disetel ke “False” di awal proses seleksi dan kami hanya akan memperbarui satu per setiap posisi pekerjaan menjadi “Benar” .
Bagian 5:Tes Aplikasi
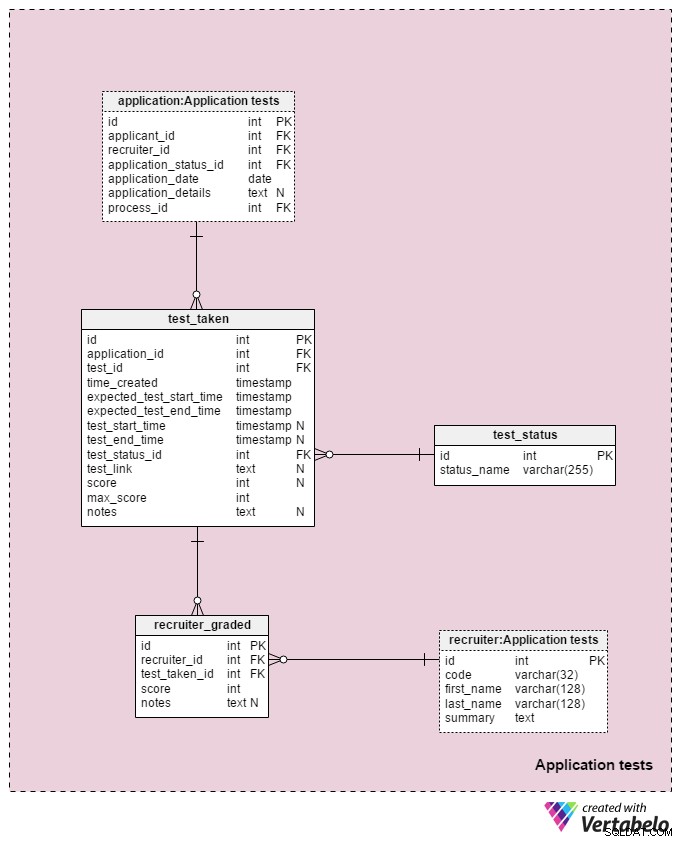
Area subjek terakhir dalam model kami akan digunakan untuk menyimpan hasil dari setiap tes yang diambil selama proses seleksi. Dua tabel yang digunakan dalam bidang subjek ini adalah salinan dari bidang subjek lain:application dan recruiter . Mereka digunakan di sini untuk menyederhanakan model.
Semua detail yang terkait dengan setiap tes disimpan di test_taken meja. Tabel ini juga memuat semua langkah lain dalam proses yang dapat dinilai, seperti tinjauan CV. Atribut dalam tabel ini adalah:
application_id– Merujukapplicationmeja. Ini berkaitan dengan ujian dengan pelamar yang mengikuti ujian itu.test_id– Merujuk padatestkatalog. Kami juga dapat mereferensikantest_in_processtabel di sini, yang akan memberi kami informasi lebih lanjut tentang tes yang diambil. Saya memutuskan untuk tidak melakukannya karena struktur ini memberi kami lebih banyak fleksibilitas. (Misalnya jika kami ingin mengizinkan pelamar mengikuti tes dua kali atau di luar waktu biasanya).time_created– Waktu sebenarnya kami memasukkan tes ini ke dalam sistem kami.expected_test_start_timedanexpected_test_end_time– Waktu mulai dan berakhir, seperti yang didiskusikan dengan pemohon. Kami dapat mengubah nilai ini jika pelamar atau perekrut perlu menunda tes.test_start_timedantest_end_time–Waktu mulai dan berakhir sebenarnya untuk tes. Ini akan berisi nilai NULL saat tes dibuat; nilai akan diperbarui saat pelamar memulai dan mengakhiri tes ini.test_status_id– Merujuktest_statuskamus.test_link– Tautan ke tes dengan jawaban pelamar. Ini akan diperbarui ketika pelamar mengirimkan tes.score– Skor pelamar pada tes itu. Ini ditentukan secara manual oleh perekrut (misalnya untuk tinjauan CV) atau secara otomatis (jumlah dari semua skor item tes). Itu juga bisa menyimpan nilai NULL untuk tes yang tidak dinilai atau dinilai pada beberapa skala yang telah ditentukan. Plus, tes yang dijadwalkan tetapi belum selesai dapat memiliki nilai NULL.max_score– Skor maksimum tes yang dapat dicapai. Ini sama dengan nilai yang disimpan dalamtest.”max_scoreatribut. Saya ingin mempertahankan nilai itu karena perekrut dapat mengubah tes saat sedang diberikan dan oleh karena itu mengubah skor maksimum yang dapat dicapai.notes– Catatan atau komentar tambahan apa pun yang dimasukkan oleh perekrut terkait tes khusus tersebut.
Kombinasi dari test_id – application_id – expected_test_start_time atribut membentuk kunci UNIK dari tabel ini. Sebelum menambahkan sesi tes baru, kami masih harus memeriksa interval tes yang tumpang tindih untuk pelamar terkait dan semua perekrut terkait.
test_status kamus berisi daftar setiap status_name UNIK yang dapat ditugaskan untuk tes. Beberapa nilai yang diharapkan meliputi:"belum dimulai" , "sedang berlangsung" , "berhasil diselesaikan" , "tidak berhasil diselesaikan" , "ditunda" , "dibatalkan" dan "pemohon dibatalkan" .
Tabel terakhir dalam model kita adalah recruiter_graded tabel, yang menyimpan semua nilai yang diberikan perekrut saat menilai setiap tes. Oleh karena itu, kami akan menyimpan referensi ke recruiter dan test_taken tabel. Kami juga akan menyimpan score dicapai serta notes . Informasi ini sangat penting, terutama saat kita menilai tes secara manual (yaitu untuk ulasan CV dan wawancara).
Hari ini kita telah membahas model data yang dapat mencakup hampir semua situasi dalam proses seleksi dan rekrutmen – termasuk pengecualian yang tidak umum.
Sebagian besar dari kita memiliki beberapa keahlian dengan topik ini. Silakan bagikan pengalaman Anda saat Anda berperan sebagai perekrut atau di sisi lain meja. Apakah model ini mencakup situasi yang Anda hadapi? Jika tidak, perubahan apa yang akan Anda usulkan?