Kunci utama dan kunci asing adalah karakteristik mendasar dari database relasional, seperti yang awalnya dicatat dalam makalah E.F. Codd, “A Relational Model of Data for Large Shared Data Banks”, yang diterbitkan pada tahun 1970. Kutipan yang sering diulang adalah, "Kunci, kunci keseluruhan, dan hanya kuncinya, jadi bantu aku Codd."
Latar Belakang :Kunci Utama
Kunci utama adalah batasan dalam SQL Server, yang bertindak untuk mengidentifikasi secara unik setiap baris dalam tabel. Kunci dapat didefinisikan sebagai kolom non-NULL tunggal, atau kombinasi kolom non-NULL yang menghasilkan nilai unik, dan digunakan untuk menegakkan integritas entitas untuk tabel. Sebuah tabel hanya dapat memiliki satu kunci utama, dan ketika batasan kunci utama ditentukan untuk sebuah tabel, indeks unik dibuat. Indeks tersebut akan menjadi indeks berkerumun secara default, kecuali ditentukan sebagai indeks yang tidak berkerumun saat batasan kunci utama ditentukan.
Pertimbangkan Sales.SalesOrderHeader tabel di AdventureWorks2012 basis data. Tabel ini menyimpan informasi dasar tentang pesanan penjualan, termasuk tanggal pesanan dan ID pelanggan, dan setiap penjualan diidentifikasi secara unik oleh SalesOrderID , yang merupakan kunci utama untuk tabel. Setiap kali baris baru ditambahkan ke tabel, batasan kunci utama (bernama PK_SalesOrderHeader_SalesOrderID ) dicentang untuk memastikan bahwa tidak ada baris yang sudah ada dengan nilai yang sama untuk SalesOrderID .
Kunci Asing
Terpisah dari kunci utama, tetapi sangat terkait, adalah kunci asing. Kunci asing adalah kolom atau kombinasi kolom yang sama dengan kunci utama, tetapi dalam tabel yang berbeda. Kunci asing digunakan untuk mendefinisikan hubungan dan menegakkan integritas antara dua tabel.
Untuk terus menggunakan contoh di atas, SalesOrderID kolom ada sebagai kunci asing di Sales.SalesOrderDetail tabel, tempat informasi tambahan tentang penjualan disimpan, seperti ID produk dan harga. Saat penjualan baru ditambahkan ke SalesOrderHeader tabel, tidak perlu menambahkan baris untuk penjualan tersebut ke SalesOrderDetail tabel Namun, saat menambahkan baris ke SalesOrderDetail tabel, baris yang sesuai untuk SalesOrderID harus ada di SalesOrderHeader tabel.
Sebaliknya, saat menghapus data, baris untuk SalesOrderID tertentu dapat dihapus kapan saja dari SalesOrderDetail tabel, tetapi agar baris dihapus dari SalesOrderHeader tabel, baris terkait dari SalesOrderDetail perlu dihapus terlebih dahulu.
Tidak seperti batasan kunci utama, ketika batasan kunci asing ditentukan untuk tabel, indeks tidak dibuat secara default oleh SQL Server. Namun, tidak jarang pengembang dan administrator database menambahkannya secara manual. Kunci asing dapat menjadi bagian dari kunci primer komposit untuk tabel, dalam hal ini indeks berkerumun akan ada dengan kunci asing sebagai bagian dari kunci pengelompokan. Alternatifnya, kueri mungkin memerlukan indeks yang menyertakan kunci asing dan satu atau beberapa kolom tambahan dalam tabel, sehingga indeks yang tidak dikelompokkan akan dibuat untuk mendukung kueri tersebut. Lebih lanjut, indeks pada kunci asing dapat memberikan manfaat kinerja untuk gabungan tabel yang melibatkan kunci utama dan kunci asing, dan indeks tersebut dapat memengaruhi kinerja saat nilai kunci utama diperbarui, atau jika baris dihapus.
Dalam AdventureWorks2012 database, ada satu tabel, SalesOrderDetail , dengan SalesOrderID sebagai kunci asing. Untuk SalesOrderDetail tabel, SalesOrderID dan SalesOrderDetailID bergabung untuk membentuk kunci utama, didukung oleh indeks berkerumun. Jika SalesOrderDetail tabel tidak memiliki indeks pada SalesOrderID kolom, lalu ketika baris dihapus dari SalesOrderHeader , SQL Server harus memverifikasi bahwa tidak ada baris untuk SalesOrderID yang sama nilai ada. Tanpa indeks yang berisi SalesOrderID kolom, SQL Server perlu melakukan pemindaian tabel lengkap SalesOrderDetail . Seperti yang dapat Anda bayangkan, semakin besar tabel yang direferensikan, semakin lama waktu yang dibutuhkan untuk menghapus.
Contoh
Kita dapat melihat ini dalam contoh berikut, yang menggunakan salinan tabel yang disebutkan di atas dari AdventureWorks2012 database yang telah diperluas menggunakan skrip yang dapat ditemukan di sini. Script dikembangkan oleh Jonathan Kehayias (blog | @SQLPoolBoy) dan membuat SalesOrderHeaderEnlarged tabel dengan 1.258.600 baris, dan SalesOrderDetailEnlarged tabel dengan 4.852.680 baris. Setelah skrip dijalankan, batasan kunci asing ditambahkan menggunakan pernyataan di bawah ini. Perhatikan bahwa batasan dibuat dengan ON DELETE CASCADE pilihan. Dengan opsi ini, ketika pembaruan atau penghapusan dikeluarkan terhadap SalesOrderHeaderEnlarged tabel, baris dalam tabel yang sesuai – dalam hal ini cukup SalesOrderDetailEnlarged – diperbarui atau dihapus.
Selain itu, indeks berkerumun default untuk SalesOrderDetailEnglarged dijatuhkan dan dibuat ulang hanya memiliki SalesOrderDetailID sebagai kunci utama, karena mewakili desain yang khas.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Dengan batasan kunci asing dan tanpa indeks pendukung, satu penghapusan dilakukan terhadap SalesOrderHeaderEnlarged tabel, yang mengakibatkan penghapusan satu baris dari SalesOrderHeaderEnlarged dan 72 baris dari SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Statistik IO dan informasi waktu menunjukkan hal berikut:
Waktu penguraian dan kompilasi SQL Server:Waktu CPU =8 md, waktu berlalu =8 md.
Tabel 'SalesOrderDetailEnlarged'. Hitungan pindai 1, pembacaan logis 50647, pembacaan fisik 8, pembacaan depan membaca 50667, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Meja Kerja'. Jumlah pemindaian 2, pembacaan logis 7, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.
Tabel 'SalesOrderHeaderEnlarged'. Hitungan pindai 0, pembacaan logis 15, pembacaan fisik 14, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
Waktu Eksekusi SQL Server:
Waktu CPU =1045 md, waktu yang berlalu =1898 md.
Menggunakan SQL Sentry Plan Explorer, rencana eksekusi menunjukkan pemindaian indeks berkerumun terhadap SalesOrderDetailEnlarged karena tidak ada indeks di SalesOrderID :
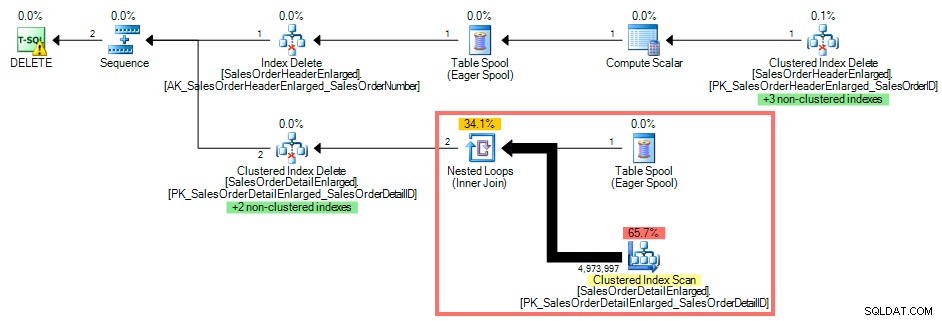
Paket Kueri Tanpa Indeks pada Kunci Asing
Indeks nonclustered untuk mendukung SalesOrderDetailEnlarged kemudian dibuat menggunakan pernyataan berikut:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Penghapusan lain dilakukan untuk SalesOrderID yang memengaruhi satu baris di SalesOrderHeaderEnlarged dan 72 baris di SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Statistik IO dan informasi waktu menunjukkan peningkatan dramatis:
Waktu penguraian dan kompilasi SQL Server:Waktu CPU =0 md, waktu berlalu =7 md.
Tabel 'SalesOrderDetailEnlarged'. Hitungan pindai 1, pembacaan logis 48, pembacaan fisik 13, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Meja Kerja'. Jumlah pemindaian 2, pembacaan logis 7, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.
Tabel 'SalesOrderHeaderEnlarged'. Hitungan pindai 0, pembacaan logis 15, pembacaan fisik 15, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
Waktu Eksekusi SQL Server:
Waktu CPU =0 md, waktu yang berlalu =27 md.
Dan rencana kueri menunjukkan pencarian indeks dari indeks nonclustered di SalesOrderID , seperti yang diharapkan:
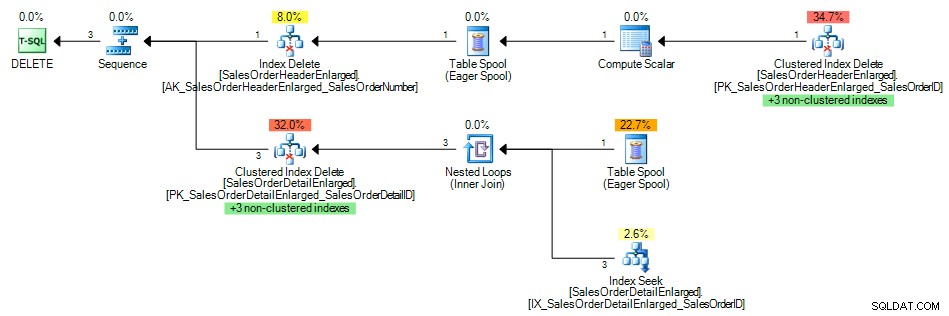
Rencana Kueri dengan Indeks pada Kunci Asing
Waktu eksekusi kueri turun dari 1898 md menjadi 27 md – pengurangan 98,58%, dan membaca untuk SalesOrderDetailEnlarged tabel menurun dari 50647 menjadi 48 – peningkatan 99,9%. Selain persentase, pertimbangkan I/O saja yang dihasilkan oleh penghapusan. SalesOrderDetailEnlarged tabel hanya 500 MB dalam contoh ini, dan untuk sistem dengan 256 GB memori yang tersedia, tabel yang menggunakan 500 MB dalam cache buffer sepertinya bukan situasi yang buruk. Tapi tabel 5 juta baris relatif kecil; kebanyakan sistem OLTP besar memiliki tabel dengan ratusan juta baris. Selain itu, tidak jarang beberapa referensi kunci asing ada untuk kunci utama, di mana penghapusan kunci utama memerlukan penghapusan dari beberapa tabel terkait. Dalam hal ini, dimungkinkan untuk melihat perpanjangan durasi penghapusan yang bukan hanya masalah kinerja, tetapi juga masalah pemblokiran, bergantung pada tingkat isolasi.
Kesimpulan
Umumnya disarankan untuk membuat indeks yang mengarah pada kolom kunci asing, untuk mendukung tidak hanya gabungan antara kunci utama dan kunci asing, tetapi juga pembaruan dan penghapusan. Perhatikan bahwa ini adalah rekomendasi umum, karena ada skenario kasus tepi di mana indeks tambahan pada kunci asing tidak digunakan karena ukuran tabel yang sangat kecil, dan pembaruan indeks tambahan sebenarnya berdampak negatif pada kinerja. Seperti halnya modifikasi skema, penambahan indeks harus diuji dan dipantau setelah implementasi. Penting untuk memastikan bahwa indeks tambahan menghasilkan efek yang diinginkan dan tidak berdampak negatif terhadap kinerja solusi. Perlu juga dicatat berapa banyak ruang tambahan yang dibutuhkan oleh indeks untuk kunci asing. Ini penting untuk dipertimbangkan sebelum membuat indeks, dan jika memang memberikan manfaat, harus dipertimbangkan untuk perencanaan kapasitas ke depan.