Kembali pada bulan Maret, saya memulai serangkaian mitos kinerja yang meresap di SQL Server. Satu keyakinan yang saya temui dari waktu ke waktu adalah bahwa Anda dapat memperbesar kolom varchar atau nvarchar tanpa penalti.
Mari kita asumsikan Anda menyimpan alamat email. Dalam kehidupan sebelumnya, saya berurusan dengan ini sedikit – pada saat itu, RFC 3696 menyatakan bahwa alamat email bisa menjadi 320 karakter (64chars@255chars). RFC yang lebih baru, #5321, sekarang mengakui bahwa 254 karakter adalah alamat email terpanjang. Dan jika ada di antara Anda yang memiliki alamat sepanjang itu, mungkin sebaiknya kita mengobrol. :-)
Sekarang, apakah Anda menggunakan standar lama atau yang baru, Anda harus mendukung kemungkinan bahwa seseorang akan menggunakan semua karakter yang diizinkan. Yang berarti Anda harus menggunakan 254 atau 320 karakter. Tapi apa yang saya lihat orang lakukan tidak repot-repot meneliti standar sama sekali, dan hanya berasumsi bahwa mereka perlu mendukung 1.000 karakter, 4.000 karakter, atau bahkan lebih.
Jadi mari kita lihat apa yang terjadi ketika kita memiliki tabel dengan kolom alamat email dengan berbagai ukuran, tetapi menyimpan data yang sama persis:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Sekarang, mari buat 10.000 alamat email fiktif dari metadata sistem, dan isi keempat tabel dengan data yang sama:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Untuk memvalidasi bahwa setiap tabel berisi data yang sama persis:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Keempatnya menghasilkan 35 dan 77 untuk saya; jarak tempuh Anda mungkin berbeda. Mari kita juga memastikan bahwa keempat tabel menempati jumlah halaman yang sama pada disk:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Keempat kueri tersebut menghasilkan 89 halaman (sekali lagi, jarak tempuh Anda mungkin berbeda).
Sekarang, mari kita ambil kueri tipikal yang menghasilkan pemindaian indeks berkerumun:
SELECT id, email FROM dbo.Email_<size>;
Jika kita melihat hal-hal seperti durasi, pembacaan, dan perkiraan biaya, semuanya tampak sama:
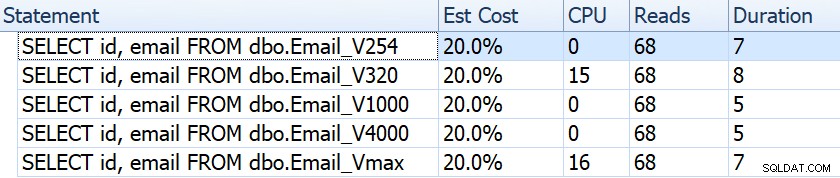
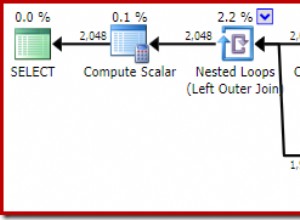
Ini mungkin membuat orang terbuai dengan asumsi yang salah bahwa tidak ada dampak kinerja sama sekali. Namun jika kita melihat sedikit lebih dekat, pada tooltip untuk pemindaian indeks berkerumun di setiap paket, kita melihat perbedaan yang mungkin berperan dalam kueri lain yang lebih rumit:

Dari sini kita melihat bahwa, semakin besar definisi kolom, semakin tinggi estimasi baris dan ukuran data. Dalam kueri sederhana ini, biaya I/O (0,0512731) sama di semua kueri, apa pun definisinya, karena pemindaian indeks berkerumun harus tetap membaca semua data.
Tetapi ada skenario lain di mana perkiraan ukuran baris dan total data ini akan berdampak:operasi yang memerlukan sumber daya tambahan, seperti pengurutan. Mari kita ambil kueri konyol ini yang tidak memiliki tujuan sebenarnya, selain memerlukan beberapa operasi pengurutan:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Kami menjalankan empat kueri ini dan kami melihat semua paket terlihat seperti ini:

Namun ikon peringatan pada operator SELECT hanya muncul pada tabel 4000/maks. Apa peringatannya? Ini adalah peringatan pemberian memori yang berlebihan, diperkenalkan di SQL Server 2016. Berikut adalah peringatan untuk varchar(4000):

Dan untuk varchar(maks):

Mari kita lihat lebih dekat dan lihat apa yang terjadi, setidaknya menurut sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Hasil:

Dalam skenario saya, durasi tidak dipengaruhi oleh perbedaan pemberian memori (kecuali untuk kasus maksimum), tetapi Anda dapat dengan jelas melihat perkembangan linier yang bertepatan dengan ukuran kolom yang dinyatakan. Yang dapat Anda gunakan untuk memperkirakan apa yang akan terjadi pada sistem dengan memori yang tidak mencukupi. Atau kueri yang lebih rumit terhadap kumpulan data yang jauh lebih besar. Atau konkurensi yang signifikan. Skenario mana pun dapat memerlukan tumpahan untuk memproses operasi penyortiran, dan akibatnya durasi hampir pasti akan terpengaruh.
Tapi dari mana hibah memori yang lebih besar ini berasal? Ingat, ini adalah kueri yang sama, terhadap data yang sama persis. Masalahnya adalah, untuk operasi tertentu, SQL Server harus memperhitungkan berapa banyak data *mungkin* dalam satu kolom. Itu tidak melakukan ini berdasarkan benar-benar membuat profil data, dan tidak dapat membuat asumsi apa pun berdasarkan nilai langkah histogram <=201. Sebagai gantinya, ia harus memperkirakan bahwa setiap baris memiliki nilai setengah dari ukuran kolom yang dinyatakan . Jadi untuk varchar(4000), diasumsikan setiap alamat email memiliki panjang 2.000 karakter.
Ketika tidak mungkin memiliki alamat email yang lebih panjang dari 254 atau 320 karakter, tidak ada untungnya dengan ukuran yang berlebihan, dan ada banyak kemungkinan kerugian. Meningkatkan ukuran kolom lebar variabel nanti jauh lebih mudah daripada menangani semua kerugian sekarang.
Tentu saja, kebesaran char atau nchar kolom dapat memiliki hukuman yang jauh lebih jelas.