Hampir setiap masalah kinerja terkait kolom terkomputasi yang saya temui selama bertahun-tahun memiliki satu (atau lebih) akar penyebab berikut:
- Batasan implementasi
- Kurangnya dukungan model biaya di pengoptimal kueri
- Perluasan definisi kolom yang dihitung sebelum pengoptimalan dimulai
Contoh batasan implementasi tidak dapat membuat indeks yang difilter pada kolom yang dihitung (bahkan ketika bertahan). Tidak banyak yang bisa kita lakukan tentang kategori masalah ini; kita harus menggunakan solusi sementara menunggu penyempurnaan produk tiba.
Kurangnya pengoptimal dukungan model biaya berarti SQL Server menetapkan biaya tetap kecil untuk perhitungan skalar, terlepas dari kompleksitas atau implementasi. Akibatnya, server sering memutuskan untuk menghitung ulang nilai kolom terkomputasi yang disimpan alih-alih membaca nilai yang dipertahankan atau diindeks secara langsung. Ini sangat menyakitkan ketika ekspresi yang dihitung mahal, misalnya ketika melibatkan pemanggilan fungsi skalar yang ditentukan pengguna.
Masalah seputar perluasan definisi sedikit lebih terlibat, dan memiliki efek yang luas.
Masalah Ekspansi Kolom Terhitung
SQL Server biasanya memperluas kolom yang dihitung ke dalam definisi dasarnya selama fase pengikatan normalisasi kueri. Ini adalah fase yang sangat awal dalam proses kompilasi kueri, jauh sebelum keputusan pemilihan rencana dibuat (termasuk rencana sepele).
Secara teori, melakukan ekspansi awal mungkin memungkinkan pengoptimalan yang seharusnya terlewatkan. Misalnya, pengoptimal mungkin dapat menerapkan penyederhanaan yang diberikan informasi lain dalam kueri dan metadata (mis. Ini adalah jenis penalaran yang sama yang mengarah pada perluasan definisi tampilan (kecuali NOEXPAND petunjuk digunakan).
Kemudian dalam proses kompilasi (tetapi bahkan sebelum rencana sepele telah dipertimbangkan), pengoptimal terlihat mencocokkan kembali ekspresi ke kolom komputasi yang dipertahankan atau diindeks. Masalahnya adalah bahwa aktivitas pengoptimal sementara itu mungkin telah mengubah ekspresi yang diperluas sehingga pencocokan kembali tidak mungkin lagi.
Ketika ini terjadi, rencana eksekusi akhir tampak seolah-olah pengoptimal telah melewatkan peluang "jelas" untuk menggunakan kolom komputasi yang dipertahankan atau diindeks. Ada beberapa detail dalam rencana eksekusi yang dapat membantu menentukan penyebabnya, menjadikannya masalah yang berpotensi membuat frustrasi untuk di-debug dan diperbaiki.
Mencocokkan Ekspresi dengan Kolom yang Dihitung
Perlu dijelaskan secara khusus bahwa ada dua proses terpisah di sini:
- Perluasan awal kolom yang dihitung; dan
- Kemudian upaya mencocokkan ekspresi ke kolom yang dihitung.
Khususnya, perhatikan bahwa ekspresi kueri apa pun dapat dicocokkan dengan kolom terkomputasi yang sesuai di kemudian hari, bukan hanya ekspresi yang muncul dari perluasan kolom terkomputasi.
Pencocokan ekspresi kolom yang dihitung dapat mengaktifkan peningkatan rencana bahkan ketika teks kueri asli tidak dapat dimodifikasi. Misalnya, membuat kolom yang dihitung untuk mencocokkan ekspresi kueri yang diketahui memungkinkan pengoptimal menggunakan statistik dan indeks yang terkait dengan kolom yang dihitung. Fitur ini secara konseptual mirip dengan pencocokan tampilan terindeks di Edisi Perusahaan. Pencocokan kolom yang dihitung berfungsi di semua edisi.
Dari sudut pandang praktis, pengalaman saya sendiri adalah bahwa mencocokkan ekspresi kueri umum dengan kolom yang dihitung memang dapat menguntungkan kinerja, efisiensi, dan stabilitas rencana eksekusi. Di sisi lain, saya jarang (jika pernah) menemukan ekspansi kolom yang dihitung bermanfaat. Tampaknya tidak pernah menghasilkan pengoptimalan yang berguna.
Penggunaan Kolom yang Dihitung
Kolom terhitung yang tidak keduanya bertahan atau diindeks memiliki kegunaan yang valid. Misalnya, mereka dapat mendukung statistik otomatis jika kolomnya deterministik dan presisi (tidak ada elemen floating point). Mereka juga dapat digunakan untuk menghemat ruang penyimpanan (dengan mengorbankan sedikit penggunaan prosesor runtime ekstra). Sebagai contoh terakhir, mereka dapat memberikan cara yang rapi untuk memastikan bahwa perhitungan sederhana selalu dilakukan dengan benar, daripada selalu ditulis secara eksplisit dalam kueri.
Bertahan kolom yang dihitung ditambahkan ke produk secara khusus untuk memungkinkan indeks dibangun di atas kolom deterministik tetapi "tidak tepat" (titik mengambang). Dalam pengalaman saya, penggunaan yang dimaksudkan ini relatif jarang. Mungkin ini hanya karena saya tidak terlalu sering menemukan data floating point.
Di samping indeks floating point, kolom bertahan cukup umum. Sampai batas tertentu, ini mungkin karena pengguna yang tidak berpengalaman berasumsi bahwa kolom yang dihitung harus selalu dipertahankan sebelum dapat diindeks. Pengguna yang lebih berpengalaman dapat menggunakan kolom bertahan hanya karena mereka telah menemukan bahwa kinerja cenderung lebih baik seperti itu.
Diindeks kolom yang dihitung (bertahan atau tidak) dapat digunakan untuk menyediakan pemesanan dan metode akses yang efisien. Akan berguna untuk menyimpan nilai yang dihitung dalam indeks tanpa juga mempertahankannya di tabel dasar. Sama halnya, kolom terhitung yang sesuai juga dapat dimasukkan dalam indeks daripada menjadi kolom kunci.
Kinerja Buruk
Penyebab utama kinerja yang buruk adalah kegagalan sederhana untuk menggunakan nilai kolom terindeks atau tetap seperti yang diharapkan. Saya telah kehilangan hitungan jumlah pertanyaan yang saya miliki selama bertahun-tahun menanyakan mengapa pengoptimal akan memilih rencana eksekusi yang buruk ketika ada rencana yang jelas lebih baik menggunakan kolom yang dihitung atau tetap ada.
Penyebab pasti dalam setiap kasus bervariasi, tetapi hampir selalu merupakan keputusan berbasis biaya yang salah (karena skalar ditetapkan dengan biaya tetap yang rendah); atau kegagalan untuk mencocokkan ekspresi yang diperluas kembali ke kolom atau indeks yang dihitung tetap ada.
Kegagalan match-back sangat menarik bagi saya, karena sering kali melibatkan interaksi kompleks dengan fitur engine ortogonal. Sama seringnya, kegagalan untuk "mencocokkan kembali" meninggalkan ekspresi (bukan kolom) di posisi di pohon kueri internal yang mencegah aturan pengoptimalan penting agar tidak cocok. Dalam kedua kasus tersebut, hasilnya sama:rencana eksekusi yang kurang optimal.
Sekarang, saya pikir adil untuk mengatakan bahwa orang pada umumnya mengindeks atau mempertahankan kolom yang dihitung dengan harapan kuat bahwa nilai yang disimpan benar-benar akan digunakan. Ini bisa sangat mengejutkan melihat SQL Server menghitung ulang ekspresi yang mendasarinya setiap kali, sambil mengabaikan nilai tersimpan yang sengaja disediakan. Orang tidak selalu sangat tertarik pada interaksi internal dan kekurangan model biaya yang mengarah pada hasil yang tidak diinginkan. Meskipun ada solusi, ini membutuhkan waktu, keterampilan, dan upaya untuk menemukan dan mengujinya.
Singkatnya:banyak orang lebih memilih SQL Server untuk menggunakan nilai yang dipertahankan atau diindeks. Selalu.
Opsi Baru
Secara historis, tidak ada cara untuk memaksa SQL Server untuk selalu menggunakan nilai yang disimpan (tidak setara dengan NOEXPAND petunjuk untuk tampilan). Ada beberapa keadaan di mana panduan rencana akan bekerja, tetapi tidak selalu memungkinkan untuk menghasilkan bentuk rencana yang diperlukan di tempat pertama, dan tidak semua elemen dan posisi rencana dapat dipaksakan (misalnya, memfilter dan menghitung skalar).
Masih belum ada solusi yang rapi dan terdokumentasi sepenuhnya, tetapi pembaruan terbaru untuk SQL Server 2016 telah memberikan pendekatan baru yang menarik. Ini berlaku untuk instans SQL Server 2016 yang ditambal dengan setidaknya Pembaruan Kumulatif 2 untuk SQL Server 2016 SP1 atau Pembaruan Kumulatif 4 untuk SQL Server 2016 RTM.
Pemutakhiran yang relevan didokumentasikan di:MEMPERBAIKI:Tidak dapat membangun kembali partisi online untuk tabel yang berisi kolom partisi yang dihitung di SQL Server 2016
Seperti yang sering terjadi dengan dokumentasi dukungan, ini tidak mengatakan dengan tepat apa yang telah diubah di mesin untuk mengatasi masalah tersebut. Ini tentu tidak terlihat terlalu relevan dengan keprihatinan kami saat ini, dilihat dari judul dan deskripsinya. Namun demikian, perbaikan ini memperkenalkan tanda pelacakan baru yang didukung 176 , yang diperiksa dalam metode kode yang disebut FDontExpandPersistedCC . Seperti yang disarankan oleh nama metode, hal ini mencegah kolom komputasi yang dipertahankan agar tidak diperluas.
Ada tiga peringatan penting untuk ini:
- Kolom yang dihitung harus bertahan . Bahkan jika diindeks, kolom juga harus dipertahankan.
- Pencocokan kembali dari ekspresi kueri umum ke kolom yang dihitung tetap dinonaktifkan .
- Dokumentasi tidak menjelaskan fungsi tanda jejak, dan tidak meresepkannya untuk penggunaan lain. Jika Anda memilih untuk menggunakan tanda pelacakan 176 untuk mencegah perluasan kolom terkomputasi yang bertahan, maka risiko Anda ditanggung sendiri.
Tanda jejak ini efektif sebagai –T start-up pilihan, baik di lingkup global dan sesi menggunakan DBCC TRACEON , dan per kueri dengan OPTION (QUERYTRACEON) .
Contoh
Ini adalah versi pertanyaan yang disederhanakan (berdasarkan masalah dunia nyata) yang saya jawab di Database Administrators Stack Exchange beberapa tahun yang lalu. Definisi tabel mencakup kolom yang dihitung tetap:
CREATE TABLE dbo.T( ID integer IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D date NULL, Computed AS + '-' + B + '-' + C PERSISTED, CONSTRAINT PK_T_ID PRIMARY KEY CLUSTERED (ID),);GOINSERT dbo.T WITH (TABLOCKX) (A, B, C, D)SELECT A =STR(SV.number % 10, 2 ), B =STR(SV.number % 20, 2), C =STR(SV.number % 30, 2), D =DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())FROM master.dbo.spt_values SEBAGAI SVWHERE SV.[type] =N'P';
Kueri di bawah ini mengembalikan semua baris dari tabel dalam urutan tertentu, sementara juga mengembalikan nilai kolom D berikutnya dalam urutan yang sama:
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER OLEH T2.D ASC )FROM dbo.T AS T1ORDER OLEH T1.Computed, T1.D;
Indeks penutup yang jelas untuk mendukung pemesanan dan pencarian akhir di sub-kueri adalah:
BUAT INDEKS NONCLUSTERED UNIK IX_T_Computed_D_IDON dbo.T (Dihitung, D, ID);
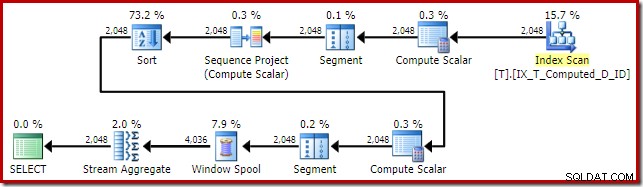
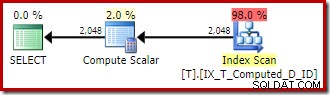
Rencana eksekusi yang disampaikan oleh pengoptimal mengejutkan dan mengecewakan:
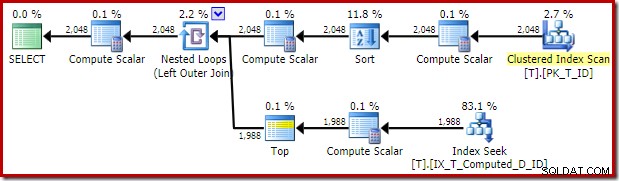
Pencarian Indeks di bagian dalam Gabung Loop Bersarang tampaknya baik-baik saja. Namun, pemindaian dan pengurutan indeks berkerumun pada input luar tidak terduga. Kami berharap untuk melihat pemindaian berurutan dari indeks nonclustered kami yang mencakup.
Kami dapat memaksa pengoptimal untuk menggunakan indeks nonclustered dengan petunjuk tabel:
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER OLEH T2.D ASC )FROM dbo.T AS T1 WITH (INDEX(IX_T_Computed_D_ID)) -- Baru!ORDER OLEH T1.Computed, T1.D;
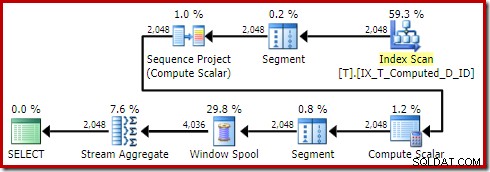
Rencana eksekusi yang dihasilkan adalah:
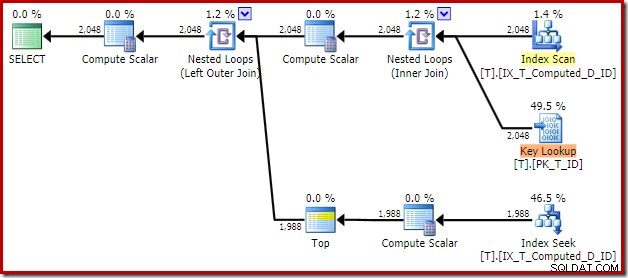
Memindai indeks nonclustered menghapus Sortir, tetapi menambahkan Pencarian Kunci! Pencarian dalam paket baru ini mengejutkan, mengingat indeks kami pasti mencakup semua kolom yang dibutuhkan oleh kueri.
Melihat properti dari operator Pencarian Kunci:
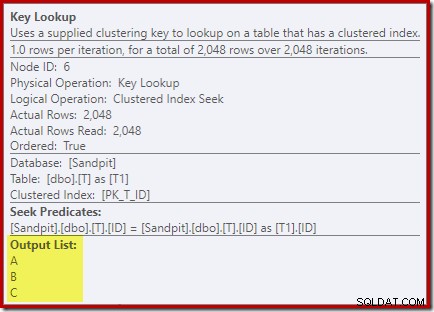
Untuk beberapa alasan, pengoptimal telah memutuskan bahwa tiga kolom yang tidak disebutkan dalam kueri perlu diambil dari tabel dasar (karena tidak ada dalam indeks nonclustered kami berdasarkan desain).
Melihat-lihat rencana eksekusi, kami menemukan bahwa kolom pencarian diperlukan oleh sisi dalam. Pencarian Indeks:

Bagian pertama dari predikat pencarian ini sesuai dengan korelasi T2.Computed = T1.Computed dalam kueri asli. Pengoptimal telah memperluas definisi kedua kolom yang dihitung, tetapi hanya berhasil mencocokkan kembali ke kolom komputasi yang dipertahankan dan diindeks untuk alias sisi dalam T1 . Meninggalkan T2 referensi yang diperluas telah menghasilkan sisi luar gabungan yang perlu menyediakan kolom tabel dasar (A , B , dan C ) diperlukan untuk menghitung ekspresi tersebut untuk setiap baris.
Seperti yang kadang-kadang terjadi, dimungkinkan untuk menulis ulang kueri ini sehingga masalahnya hilang (satu opsi ditampilkan dalam jawaban lama saya untuk pertanyaan Stack Exchange). Menggunakan SQL Server 2016, kami juga dapat mencoba melacak bendera 176 untuk mencegah kolom yang dihitung diperluas:
SELECT T1.ID, T1.Computed, T1.D, NextD =( SELECT TOP (1) t2.D FROM dbo.T AS T2 WHERE T2.Computed =T1.Computed AND T2.D> T1.D ORDER OLEH T2.D ASC )FROM dbo.T AS T1ORDER OLEH T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Baru!
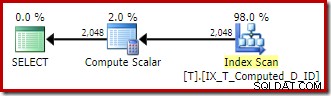
Rencana eksekusi sekarang jauh lebih baik:
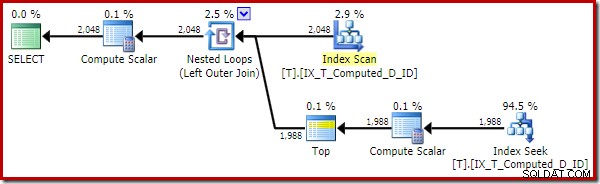
Rencana eksekusi ini hanya berisi referensi ke kolom yang dihitung. Skalar Hitung tidak berguna dan akan dibersihkan jika pengoptimal sedikit lebih rapi di sekitar rumah.
Poin penting adalah bahwa indeks optimal sekarang digunakan dengan benar, dan Pencarian Sort dan Kunci telah dihilangkan. Semua dengan mencegah SQL Server melakukan sesuatu yang tidak pernah kita duga sebelumnya (memperluas kolom komputasi yang bertahan dan terindeks).
Menggunakan LEAD
Pertanyaan Stack Exchange asli ditargetkan pada SQL Server 2008, di mana LEAD tidak tersedia. Mari kita coba mengekspresikan persyaratan pada SQL Server 2016 menggunakan sintaks yang lebih baru:
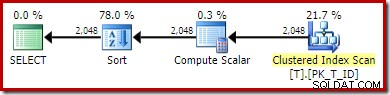
PILIH T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.Computed;Rencana eksekusi SQL Server 2016 adalah:
Bentuk denah ini cukup khas untuk fungsi jendela mode baris sederhana. Satu-satunya item yang tidak terduga adalah operator Sortir di tengah. Jika kumpulan data besar, Pengurutan ini dapat berdampak besar pada kinerja dan penggunaan memori.
Masalahnya, sekali lagi, adalah ekspansi kolom yang dihitung. Dalam hal ini, salah satu ekspresi yang diperluas berada di posisi yang mencegah logika pengoptimal normal menyederhanakan Sort away.
Mencoba kueri yang sama persis dengan tanda jejak 176:
PILIH T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );Menghasilkan rencana:
Sortir telah menghilang sebagaimana mestinya. Perhatikan juga bahwa kueri ini memenuhi syarat untuk rencana sepele, menghindari pengoptimalan berbasis biaya sama sekali.
Menonaktifkan Pencocokan Ekspresi Umum
Salah satu peringatan yang disebutkan sebelumnya adalah bahwa flag trace 176 juga menonaktifkan pencocokan dari ekspresi dalam kueri sumber ke kolom komputasi yang bertahan.
Untuk mengilustrasikannya, pertimbangkan versi kueri contoh berikut.
LEADperhitungan telah dihapus, dan referensi ke kolom yang dihitung diSELECTdanORDER BYklausa telah diganti dengan ekspresi yang mendasarinya. Jalankan dulu tanpa jejak flag 176:SELECT T1.ID, Computed =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C;Ekspresi dicocokkan dengan kolom komputasi yang bertahan, dan rencana eksekusi adalah pemindaian berurutan sederhana dari indeks nonclustered:
Compute Scalar di sana sekali lagi hanyalah sampah arsitektur yang tersisa.
Sekarang coba kueri yang sama dengan tanda jejak 176 diaktifkan:
SELECT T1.ID, Computed =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Baru!Rencana eksekusi baru adalah:
Pemindaian Indeks Nonclustered telah diganti dengan Pemindaian Indeks Clustered. Skalar Hitung mengevaluasi ekspresi, dan Urutkan diurutkan berdasarkan hasilnya. Kehilangan kemampuan untuk mencocokkan ekspresi ke kolom komputasi yang dipertahankan, pengoptimal tidak dapat menggunakan nilai yang dipertahankan, atau indeks nonclustered.
Perhatikan bahwa batasan pencocokan ekspresi hanya berlaku untuk bertahan kolom yang dihitung saat bendera pelacakan 176 aktif. Jika kita membuat kolom yang dihitung diindeks tetapi tidak dipertahankan, pencocokan ekspresi berfungsi dengan benar.
Untuk menghapus atribut persisten, kita harus menghapus indeks nonclustered terlebih dahulu. Setelah perubahan dibuat, kita dapat mengembalikan indeks (karena ekspresinya deterministik dan tepat):
DROP INDEX IX_T_Computed_D_ID PADA dbo.T;GOALTER TABLE dbo.TALTER COLUMN ComputedDROP PERSISTED;GOCREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Dihitung, D, ID);Pengoptimal sekarang tidak memiliki masalah dalam mencocokkan ekspresi kueri dengan kolom yang dihitung saat tanda pelacakan 176 aktif:
-- Kolom yang dihitung tidak lagi bertahan-- tetapi masih diindeks. TF 176 aktif.SELECT T1.ID, Computed =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);Rencana eksekusi kembali ke pemindaian indeks nonclustered yang optimal tanpa pengurutan:
Untuk meringkas:Trace flag 176 mencegah ekspansi kolom terkomputasi yang bertahan. Sebagai efek samping, ini juga mencegah pencocokan ekspresi kueri ke kolom yang dihitung saja.
Metadata skema hanya dimuat sekali, selama fase pengikatan. Bendera pelacakan 176 mencegah ekspansi sehingga definisi kolom yang dihitung tidak dimuat pada saat itu. Pencocokan ekspresi-ke-kolom selanjutnya tidak dapat bekerja tanpa definisi kolom yang dihitung untuk dicocokkan.
Pemuatan metadata awal membawa semua kolom, bukan hanya yang direferensikan dalam kueri (pengoptimalan itu dilakukan nanti). Ini membuat semua kolom yang dihitung tersedia untuk dicocokkan, yang umumnya merupakan hal yang baik. Sayangnya, jika salah satu kolom terhitung yang dimuat berisi fungsi skalar yang ditentukan pengguna, kehadirannya menonaktifkan paralelisme untuk keseluruhan kueri bahkan ketika kolom bermasalah tidak digunakan. Trace flag 176 dapat membantu dengan ini juga, jika kolom yang dimaksud tetap ada. Dengan tidak memuat definisi, fungsi skalar yang ditentukan pengguna tidak akan pernah ada, sehingga paralelisme tidak dinonaktifkan.
Pemikiran Akhir
Tampaknya bagi saya bahwa dunia SQL Server menjadi tempat yang lebih baik jika pengoptimal memperlakukan kolom yang dihitung atau diindeks lebih seperti kolom biasa. Di hampir semua kasus, ini akan lebih sesuai dengan harapan pengembang daripada pengaturan saat ini. Memperluas kolom yang dihitung ke dalam ekspresi dasarnya dan kemudian mencoba mencocokkannya kembali tidak sesukses dalam praktiknya seperti yang mungkin disarankan oleh teori.
Hingga SQL Server menyediakan dukungan khusus untuk mencegah ekspansi kolom terkomputasi yang dipertahankan atau diindeks, bendera pelacakan baru 176 adalah opsi yang menggoda untuk pengguna SQL Server 2016, meskipun tidak sempurna. Sangat disayangkan bahwa ini menonaktifkan pencocokan ekspresi umum sebagai efek samping. Ini juga memalukan bahwa kolom yang dihitung harus dipertahankan saat diindeks. Kemudian ada risiko menggunakan tanda pelacakan selain dari tujuan yang didokumentasikan untuk dipertimbangkan.
Adalah adil untuk mengatakan bahwa sebagian besar masalah dengan kueri kolom yang dihitung pada akhirnya dapat diselesaikan dengan cara lain, dengan waktu, tenaga, dan keahlian yang cukup. Di sisi lain, jejak bendera 176 tampaknya sering bekerja seperti sulap. Pilihannya, seperti yang mereka katakan, ada di tangan Anda.
Sebagai penutup, berikut adalah beberapa masalah kolom terkomputasi yang menarik yang mendapat manfaat dari trace flag 176:
- Indeks Kolom Terhitung Tidak Digunakan
- Kolom yang dihitung PERSISTED tidak digunakan dalam partisi fungsi windowing
- Kolom terkomputasi yang bertahan menyebabkan pemindaian
- Indeks Kolom Terhitung Tidak Digunakan dengan MAX tipe data
- Masalah kinerja yang parah dengan kolom dan gabungan yang dihitung tetap ada
- Mengapa SQL Server "Menghitung Skalar" ketika saya MEMILIH kolom yang dihitung terus-menerus?
- Kolom Dasar yang digunakan sebagai ganti kolom yang dihitung terus-menerus oleh mesin
- Kolom Terhitung dengan UDF menonaktifkan paralelisme untuk kueri pada kolom *lain*



