Semua posting saya tahun ini adalah tentang reaksi spontan untuk menunggu statistik, tetapi dalam posting ini saya menyimpang dari tema itu untuk berbicara tentang beruang bug tertentu saya:penghitung kinerja harapan hidup halaman (yang akan saya sebut PLE ).
Apa Artinya PLE?
Ada berbagai macam pernyataan yang salah tentang harapan hidup halaman di Internet, dan yang paling mengerikan adalah pernyataan yang menyebutkan bahwa nilai 300 adalah ambang batas yang harus Anda khawatirkan.
Untuk memahami mengapa pernyataan ini sangat menyesatkan, Anda perlu memahami apa sebenarnya PLE itu.
Definisi PLE adalah waktu yang diharapkan, dalam detik, bahwa halaman file data yang dibaca ke dalam buffer pool (cache dalam memori dari halaman file data) akan tetap berada di memori sebelum didorong keluar dari memori untuk memberikan ruang bagi data yang berbeda. halaman berkas. Cara lain untuk memikirkan PLE adalah ukuran seketika dari tekanan pada buffer pool untuk membuat ruang kosong untuk halaman yang sedang dibaca dari disk. Untuk kedua definisi ini, angka yang lebih tinggi lebih baik.
Berapa Ambang Batas PLE yang Baik?
PLE 300 berarti seluruh buffer pool Anda di-flush secara efektif dan dibaca ulang setiap lima menit. Ketika panduan ambang batas untuk PLE 300 pertama kali diberikan oleh Microsoft, sekitar tahun 2005/2006, angka tersebut mungkin lebih masuk akal karena jumlah rata-rata memori pada server jauh lebih rendah.
Saat ini, di mana server secara rutin memiliki 64GB, 128GB, dan jumlah memori yang lebih tinggi, memiliki kira-kira sebanyak itu data yang dibaca dari disk setiap lima menit kemungkinan akan menjadi penyebab masalah kinerja yang melumpuhkan
Pada kenyataannya, pada saat PLE melayang pada atau di bawah 300, server Anda sudah dalam kesulitan. Anda akan mulai khawatir, jauh sebelum PLE serendah itu.
Jadi, berapa ambang batas yang digunakan saat Anda harus khawatir?
Nah, itu saja intinya. Saya tidak bisa memberi Anda ambang batas, karena angka itu akan bervariasi untuk setiap orang. Jika Anda benar-benar ingin menggunakan nomor, rekan saya Jonathan Kehayias membuat formula:
(Memori kumpulan buffer dalam GB / 4) x 300Bahkan nomor itu agak berubah-ubah, dan jarak tempuh Anda akan bervariasi.
Saya tidak suka merekomendasikan nomor apa pun. Saran saya adalah agar Anda mengukur PLE Anda ketika kinerja berada pada tingkat yang diinginkan – itu ambang batas yang Anda gunakan.
Jadi, apakah Anda mulai khawatir begitu PLE turun di bawah ambang batas itu? Tidak. Anda mulai khawatir saat PLE turun di bawah ambang batas tersebut dan tetap di bawah ambang batas tersebut, atau jika turun drastis dan Anda tidak tahu mengapa.
Ini karena ada beberapa operasi yang akan menyebabkan penurunan PLE (mis. menjalankan DBCC CHECKDB atau pembangunan kembali indeks terkadang dapat melakukannya) dan tidak perlu dikhawatirkan. Tetapi jika Anda melihat penurunan PLE yang besar dan Anda tidak tahu apa penyebabnya, saat itulah Anda harus khawatir.
Anda mungkin bertanya-tanya bagaimana DBCC CHECKDB dapat menyebabkan penurunan PLE ketika tidak menguntungkan dan berusaha keras untuk menghindari pembilasan kumpulan buffer dengan data yang digunakannya (lihat posting blog ini untuk penjelasannya). Itu karena pemberian memori eksekusi kueri untuk DBCC CHECKDB salah dihitung oleh Pengoptimal Kueri dan dapat menyebabkan pengurangan besar dalam ukuran kumpulan buffer (memori untuk hibah dicuri dari kumpulan buffer) dan akibatnya penurunan PLE.
Bagaimana Anda Memantau PLE?
Ini adalah bagian yang sulit. Kebanyakan orang akan langsung membuka Buffer Manager kinerja objek di PerfMon dan pantau Page life expectancy menangkal. Apakah ini pendekatan yang tepat? Kemungkinan besar tidak.
Saya akan mengatakan bahwa sebagian besar server di luar sana saat ini menggunakan arsitektur NUMA, dan ini memiliki efek mendalam pada cara Anda memantau PLE.
Ketika NUMA terlibat, kumpulan buffer dibagi menjadi node buffer, dengan satu node buffer per node NUMA yang dapat 'dilihat' oleh SQL Server. Setiap node buffer melacak PLE secara terpisah dan Buffer Manager:Page life expectancy counter adalah rata-rata dari buffer node PLEs. Jika Anda hanya memantau keseluruhan buffer pool PLE, maka tekanan pada salah satu node buffer dapat ditutupi oleh rata-rata (saya membahas ini dalam posting blog di sini).
Jadi jika server Anda menggunakan NUMA, Anda perlu memantau Buffer Node:Page life expectancy individu penghitung (akan ada satu objek kinerja Buffer Node untuk setiap NUMA node), jika tidak, Anda harus memantau Buffer Manager:Page life expectancy dengan baik. penghitung.
Lebih baik lagi adalah menggunakan alat pemantauan seperti SQL Sentry Performance Advisor, yang akan menampilkan penghitung ini sebagai bagian dari dasbor, dengan mempertimbangkan node NUMA di server, dan memungkinkan Anda mengonfigurasi peringatan dengan mudah.
Contoh Menggunakan Performance Advisor
Di bawah ini adalah bagian contoh tangkapan layar dari Performance Advisor untuk sistem dengan satu simpul NUMA:
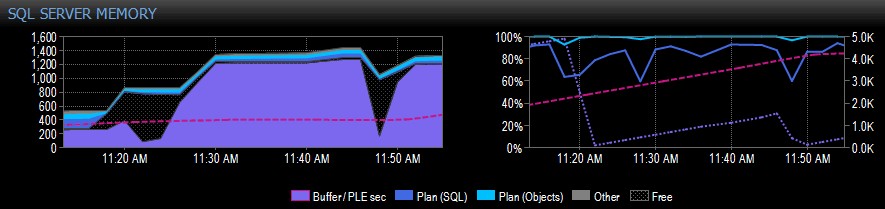
Di sisi kanan tangkapan, garis putus-putus merah muda adalah PLE antara pukul 10.30 dan sekitar 11.20 – terus naik hingga 5.000 atau lebih, angka yang sangat sehat. Tepat sebelum pukul 11.20 terjadi penurunan yang sangat besar, lalu mulai naik lagi hingga pukul 11.45, dan turun lagi.
Ini biasanya apa yang akan Anda lihat jika kumpulan buffer penuh, dengan semua halaman yang digunakan, dan kemudian kueri berjalan yang menyebabkan sejumlah besar data berbeda dibaca dari disk, menggantikan banyak dari apa yang sudah ada di memori dan menyebabkan penurunan tajam dalam PLE. Jika Anda tidak tahu apa yang menyebabkan hal seperti ini, Anda ingin menyelidikinya, seperti yang saya jelaskan lebih jauh.
Sebagai contoh kedua, tangkapan layar di bawah ini berasal dari salah satu klien DBA Jarak Jauh kami di mana server memiliki dua node NUMA (Anda dapat melihat bahwa ada dua garis PLE ungu), dan di mana kami menggunakan Performance Advisor secara ekstensif:

Di server klien ini, setiap pagi sekitar jam 5 pagi, pekerjaan pemeliharaan indeks dan pemeriksaan konsistensi dimulai yang menyebabkan PLE turun di kedua node buffer. Ini adalah perilaku yang diharapkan sehingga tidak perlu menyelidiki selama PLE naik lagi di siang hari.
Apa yang Dapat Anda Lakukan Tentang Menjatuhkan PLE?
Jika penyebab penurunan PLE tidak diketahui, Anda dapat melakukan beberapa hal:
- Jika masalah terjadi sekarang, selidiki kueri mana yang menyebabkan pembacaan dengan menggunakan
sys.dm_os_waiting_tasksDMV untuk melihat utas mana yang menunggu halaman dibaca dari disk (yaitu yang menungguPAGEIOLATCH_SH), lalu perbaiki kueri tersebut. - Jika masalah terjadi di masa lalu, lihat di sys.dm_exec_query_stats DMV untuk kueri dengan jumlah pembacaan fisik yang tinggi, atau gunakan alat pemantauan yang dapat memberi Anda informasi tersebut (misalnya tampilan SQL Top di Performance Advisor), dan lalu perbaiki kueri tersebut.
- Hubungkan penurunan PLE dengan tugas Agen terjadwal yang melakukan pemeliharaan database.
- Cari kueri dengan pemberian memori eksekusi kueri yang sangat besar menggunakan
sys.dm_exec_query_memory_grantsDMV, lalu perbaiki kueri tersebut.
Posting saya sebelumnya di sini menjelaskan lebih lanjut tentang #1 dan #2, dan skrip untuk menyelidiki waktu tunggu yang terjadi di server dan tautan ke rencana kueri mereka ada di sini.
"Perbaiki pertanyaan tersebut" berada di luar cakupan posting ini, jadi saya akan meninggalkannya untuk lain waktu atau sebagai latihan untuk pembaca ☺
Ringkasan
Jangan terjebak untuk memercayai ambang batas PLE yang direkomendasikan yang mungkin Anda baca secara online. Cara terbaik untuk bereaksi terhadap perubahan PLE adalah ketika PLE turun di bawah apa pun Anda tingkat kenyamanan dan tetap di sana – itulah indikasi masalah kinerja yang harus Anda selidiki.
Dalam artikel berikutnya dalam seri ini, saya akan membahas penyebab umum lain dari penyetelan performa spontan. Sampai saat itu, selamat memecahkan masalah!